
一次線上GC故障解決過程記錄
排查了三四個小時,終於解決了這個GC問題,記錄解決過程於此,希望對大家有所幫助。本文假定讀者已具備基本的GC常識和JVM調優知識,關於JVM調優工具使用可以檢視我在同一分類下的另一篇文章:
背景說明
發生問題的系統部署在Unix上,發生問題前已經跑了兩週多了。
其中我用到了Hadoop原始碼中的CountingBloomFilter,並將其修改成了執行緒安全的實現(詳情見:AdjustedCountingBloomFilter),主要利用了AtomicLong的CAS樂觀鎖,將long[]替換成了AtomicLong[]。這樣導致系統中有5個巨大的AtomicLong陣列(每個陣列大概佔50MB),每個陣列包含大量AtomicLong物件(所有AtomicLong物件佔據大概1.2G記憶體)。而且這些AtomicLong陣列的存活時間都至少為一天。
服務端已先於手機客戶端上線,客戶端本來計劃本週四上線(寫這篇文章時是週一),所以我還打算在接下來的幾天繼續觀察下系統的執行狀況,開啟的仍然是Debug級別日誌。
部分JVM引數摘抄如下(JVM引數配置在專案部署的tomcat伺服器的根目錄下的bin目錄下的setenv.sh中,可以通過ps -ef | grep xxx | grep -v grep檢視到):
-XX:PermSize=256M -XX:MaxPermSize=256M -Xms6000M -Xmx6000M -Xmn1500M -Xss256k -XX:ParallelGCThreads=8 -XX:+UseConcMarkSweepGC -XX: 可以看到持久代被設定為256M,堆記憶體被設定為6000M(-Xms和--Xmx設為相等避免了“堆震盪”,能在一定程度減少GC次數,但會增加平均每次GC消耗的時間),年輕代被設定為1500M。
-XX:+UseConcMarkSweepGC設定老年代使用CMS(Concurrent Mark-Sweep)收集器。 -XX:+UseParNewGC設定新生代使用並行收集器,-XX:ParallelGCThreads引數指定並行收集器工作執行緒數,在CPU核數小於等於8時一般推薦與CPU數目一致,但當CPU核數大於8時推薦設定為:3 + [(5*CPU_COUNT) / 8]。其他引數略去不提。
問題發現與解決過程
早上測試找到我說線上系統突然掛了,報訪問超時異常。
首先我第一反應是系統記憶體溢位或者程序被作業系統殺死了。用ps -ef | grep xxx | grep -v grep命令檢視程序還在。然後看tomcat的catlalina.out日誌和系統gc日誌,也未發現有記憶體溢位。
接下來用jstat -gcutil pid 1000看了下堆中各代的佔用情況和GC情況,發現了一個挺恐怖的現象:Eden區佔用77%多,S0佔用100%,Old和Perm區都有很大空間剩餘。
懷疑是新生代空間不足,但沒有確鑿證據,只好用jstack獲取執行緒Dump資訊,不看不知道,一看就發現了一個問題(沒有發現執行緒死鎖,這裡應該是“活鎖”問題):

從上面第一段可看到有一個Low Memory Detector系統內部執行緒(JVM啟動的監測和報告低記憶體的守護執行緒)一直佔著鎖0x00....00,而下面的C2 CompilerThread1、C2 CompilerThread0、Signal Dispatcher和Surrogate Locker執行緒都在等待這個鎖,導致整個JVM程序都hang住了。
在網上搜索一圈,發現大部分都建議調大堆記憶體,於是根據建議打算調大整個堆記憶體大小、調大新生代大小(-Xmn引數)、調大新生代中Survivor區佔的比例(-XX:SurvivorRatio引數)。並且由於存在AtomicLong陣列大物件,所以設定-XX:PretenureThreshold=10000000,即如果某個物件超過10M(單位為位元組,所以換算後為10M)則直接進入老年代,注意這個引數只在Serial收集器和ParNew收集器中有效。另外希望大量的長生命週期AtomicLong小物件能夠儘快進入老年代,避免老年代的AtomicLong陣列物件大量引用新生代的AtomicLong物件,我調小了-XX:MaxTenuringThreshold(這個引數的預設值為15),即現在年輕代中的物件至多能在年輕代中存活8代,如果超過8代還活著,即使那時年輕代記憶體足夠也會被Promote到老年代。有修改或增加的JVM GC引數如下:
-Xms9000M -Xmx9000M -Xmn1500M -XX:SurvivorRatio=6 -XX:MaxTenuringThreshold=8 -XX:PretenureSizeThreshold=10000000 重啟系統後用jstat -gcutil pid 1000命令發現一個更恐怖的現象,如下圖:Eden區記憶體持續快速增長,Survivor佔用依然很高,大概每兩分鐘就Young GC一次,並且每次Young GC後年老代記憶體佔用都會增加不少,這樣導致可以預測每三四個小時就會發生一次Full GC,這是很不合理的。
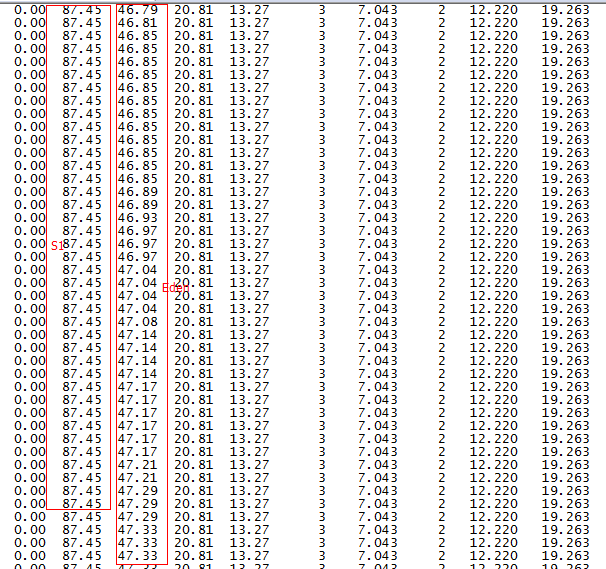
第二列是S1,佔用高達87.45%,第三列是Eden區記憶體佔用變化情況,可以看到增長非常快。
於是我用jmap -histo:live(注意jmap命令會觸發Full GC,併發訪問量較大的線上環境慎用)查看了下活物件,發現有一些Integer陣列和一些Character陣列佔用記憶體在持續增長,並且佔了大概好幾百M的記憶體,然後經過Young GC又下降,然後再次快速增長,再Young GC下降,周而復始。
至此,我推測可能是大量的Integer陣列物件和Character陣列物件基本佔滿了Survivor,導致在Eden滿了之後,新產生的Integer陣列物件和Character陣列物件不足以放入Survivor,然後物件被直接被Promote到了年老代,這種推測部分正確,它解釋了S1佔用那麼高的原因,但不能解釋上面的Eden區記憶體佔用持續上升。
於是繼續查看了下介面呼叫日誌,不看不知道,一看嚇一跳:日誌重新整理非常之快(99%是DEBUG日誌)。原來運營和測試在未通知我們服務端的情況下已經於昨天在某個渠道釋出了一個Android線上版本(難怪今天就暴露問題了),再看了下使用該系統的使用者已經有6400多個了,徹徹底底被他們坑了一把。這就能解釋為什麼上面有一個Integer陣列和Character陣列佔用記憶體持續增長了,原因就在於大量的系統介面呼叫觸發了大量DEBUG日誌重新整理,寫日誌對於線上系統是一個重量級操作,無論是對CPU佔用還是對記憶體佔用,所以高併發線上系統一定要記得調高日誌級別為INFO甚至ERROR。
於是修改log4j.properties中的日誌級別為INFO,然後用jmap -histo:live pid命令檢視活物件,發現Integer陣列物件和Character[]陣列物件明顯下降,並且佔用記憶體也由前面的幾百M降到幾M。
之後再用jstat -gcutil pid 1000查看了下GC情況,如下:

很明顯Survivor佔用沒這麼高了,最重要的Young GC後年老代記憶體佔用不會增加了,此處Eden區增長貌似還是挺快,因為此時使用者數比前面多了很多。至此出現的問題基本搞定,但還有待後續觀察。
總結
總的來說本系統中存在一個違背GC假設的東西,那就是在JVM堆中存在著海量生命週期較長的小物件(AtomicLong物件)。這無疑會給系統埋坑。
GC分代基本假設是:
JVM堆中存在的大部分物件都是短生命週期小物件。這也是為什麼Hotspot JVM的年輕代採用複製演算法的原因。
其他推薦一些非常不錯的GC方面的參考文章(前兩篇都來自《深入理解Java虛擬機器》一書,參考連結大部分是我今天查閱的資料,大家選擇性看就好):
相關推薦
一次線上GC故障解決過程記錄
排查了三四個小時,終於解決了這個GC問題,記錄解決過程於此,希望對大家有所幫助。本文假定讀者已具備基本的GC常識和JVM調優知識,關於JVM調優工具使用可以檢視我在同一分類下的另一篇文章: 背景說明 發生問題的系統部署在Unix上,發生問題前已經跑了兩週多
記一次線上gc調優的過程
aspect hash 接下來 JD lac abs rac 數據庫 %x 近期公司運營同學經常表示線上我們一個後臺管理系統運行特別慢,而且經常出現504超時的情況。對於這種情況我們本能的認為可能是代碼有性能問題,可能有死循環或者是數據庫調用次數過多導致接口運
記一次Oracle資料故障排除過程
前天在Oracle生產環境中,自己的儲存過程執行時間超過1小時,懷疑是其他job執行時間過長推遲了自己job執行時間,遂重新跑job,發現同測試環境的確不同,運行了25分鐘。 之後準備在測試環境中製造同數量級的資料進行分析,寫了大概如下的儲存過程, create or replace PROCEDU
一次python 記憶體洩漏解決過程
最近工作中慢慢開始用python協程相關的東西,所以用到了一些相關模組,如aiohttp, aiomysql, aioredis等,用的過程中也碰到的很多問題,這裡整理了一次記憶體洩漏的問題 通常我們寫python程式的時候也很少關注記憶體這個問題(當然可能我的能力還有待提升),可能寫c和c++的朋友會更多
[轉]一次 java heap space 解決過程
轉自:https://blog.csdn.net/esuom_gib/article/details/79942273 對個人有用的地方, 1.排查head 堆溢位的思路 http://itindex.net/detail/51440-java-%E5%86%85%E5%AD%98-%E
記一次線上問題的排查過程
問題描述 前不久運維在例行釋出線上CS系統的時候,發現在服務啟動的過程中,後臺一直在報如下錯誤,同時導致使用者頁面訪問異常 2017-10-10 18:28:51,077 [ERROR] org.springframework.amqp.rabbit.l
一次CMS GC問題排查過程(理解原理+讀懂GC日誌)
這個是之前處理過的一個線上問題,處理過程斷斷續續,經歷了兩週多的時間,中間各種嘗試,總結如下。這篇文章分三部分: 1、問題的場景和處理過程;2、GC的一些理論東西;3、看懂GC的日誌 先說一下問題吧 問題場景:線上機器在半夜會推送一個700M左右的資料,這個時候有個資料置換
Linux(2)---記錄一次線上服務 CPU 100%的排查過程
Linux(2)---記錄一次線上服務 CPU 100%的排查過程 當時產生CPU飆升接近100%的原因是因為專案中的websocket時時斷開又重連導致CPU飆升接近100% 。如何排查的呢 是通過日誌輸出錯誤資訊: 得知websocket時時重新 連線的資訊,然後找到原因 解決了。 當然這
一次JVM_OLD區佔用過高、頻繁Full GC的解決過程
最近,公司網站頻繁報警,JVM_OLD佔用過高,線上訪問超時嚴重,針對這個問題著實頭疼了一把,不過最終還是解決了,下面說下解決的過程。 1,首先 登到線上機器上去,top命令,檢視當前機器的負載,檢視當前哪個程序在消耗資源。 Shell 1
原創 記錄一次線上Mysql慢查詢問題排查過程
背景 前段時間收到運維反饋,線上Mysql資料庫凌晨時候出現慢查詢的報警,並把原始sql發了過來: --去除了業務含義的sql update test_user set a=1 where id=1; 表資料量200W左右,不是很大,而且是根據主鍵更新。 問題排查 排查Mysql資料庫 我看到sql後第一
記錄一次cacti中文亂碼解決經過
cacti中文支持 cacti中文亂碼 背景:公司一臺老機器,上面有個cacti。系統為centos5.X,有天手滑卸載了httpd,但yum源已經不支持centos5系列了,無奈百度上找了一個源內容如下:<span style="background-color: rgb(255, 102,
記錄一次線上處理5千萬數據轉換的經驗
cas tro 資源 小數 sql腳本 為我 可執行 前言 邏輯 前言:剛來新公司2個月就面臨了一次線上真實數據的轉換,這些數據異常重要,對我們公司來說就是客戶的資源,說白了就是客戶存在我們公司的錢,一旦處理失敗將會影響極大,可以想象一下你存銀行2萬元,第二天查詢卻一分錢沒
記錄一次郵件容災恢復過程
數據庫修改 Eseutil Exchange容災恢復 背景介紹 客戶目前使用的是Exchange Server 2013,兩前兩後,數據盤是存儲掛載過來的,郵件備份使用的是NBU,由於機房漏水,導致存儲服務器宕機。導致絕大部分數據丟失。 Exchange恢復過程 使用新存儲重新劃分磁盤,並使用N
記一次線上Java程序導致服務器CPU占用率過高的問題排除過程
tasks all lob jstat rip 進行 runable tails 分享圖片 https://blog.csdn.net/u013991521/article/details/52781423 1、故障現象 客服同事反饋平臺系統運行緩慢,網頁卡頓嚴重,多次重啟
dpdk-lvs的一次線上故障排查報告
本文記錄了dpdk-lvs叢集的一次線上故障排查過程,排查思路可供讀者參考。 上篇文章回顧: SOAR的IDE外掛——您的貼身DBA保鏢 背景 我們內部基於 dpdk 自研的高效能負載均衡器 dpdk-lvs 已經在多個機房部
一次linux啟動故障記錄
故障背景: 在2.6.32升級核心之後,出現多臺裝置啟動失敗,失敗的全部都是ssd作為系統盤的機器,bios引導之後,螢幕就黑了,沒有列印。 一開是以為是mbr損壞了,所以將啟動盤掛載到其他伺服器上,結果發現mbr和升級之前備份的mbr是一樣的,而且和升級後能正常啟動的mbr也是一樣的。
從一次線上故障思考 Java 問題定位思路
問題出現:現網CPU飆高,Full GC告警 CGI 服務釋出到現網後,現網機器出現了Full GC告警,同時CPU飆高99%。在優先恢復現網服務正常後,開始著手定位Full GC的問題。在現場只能夠抓到四個GC執行緒佔用了很高的CPU,無法抓到引發Full GC的執行緒。查看了服務故障期間的錯
spark2.2.0:記錄一次資料傾斜的解決(擴容join)!
前言: 資料傾斜,一個在大資料處理中很常見的名詞,經由前人總結,現已有不少資料傾斜的解決方案(而且會發現大資料的不同框架的資料傾斜解決思想是一致的,只是實現方法不同),本文重點記錄這次遇到spark處理資料中的傾斜問題。 老話: 菜雞一隻,本人會對文中的結論負責,如果有說錯的,還請各位批評指出
記一次Android系統下解決音訊UnderRun問題的過程
記一次Android系統下解決音訊UnderRun問題的過程 2017年01月04日 18:09:32 Qidi_Huang 閱讀數:4540 標籤: AndroidAudiounderrunxrun解決辦法 更多 個人分類: 嵌入
記錄一次Python下Tensorflow安裝過程,1.7帶GPU加速版本
最近由於論文需要,急需搭建Tensorflow環境,16年底當時Tensorflow版本號還沒有過1,我曾按照手冊搭建過CPU版本。目前,1.7算是比較新的版本了(也可以從原始碼編譯1.8版本的Tensorflow)。 安裝步驟: 不能急於求成,安裝任何東西前都應該先閱讀使用者手冊與FAQ,弄清軟體依賴與安裝