
Hadoop系列--Hadoop基本架構之MapReduce架構
1 MapReduce架構的元件組成
1.1 元件組成
Hadoop的MapReduce架構主要由以下幾個元件組成:Client、JobTracker、TaskTracker、Task。
1.2 MapReduce架構圖
如下圖所示。
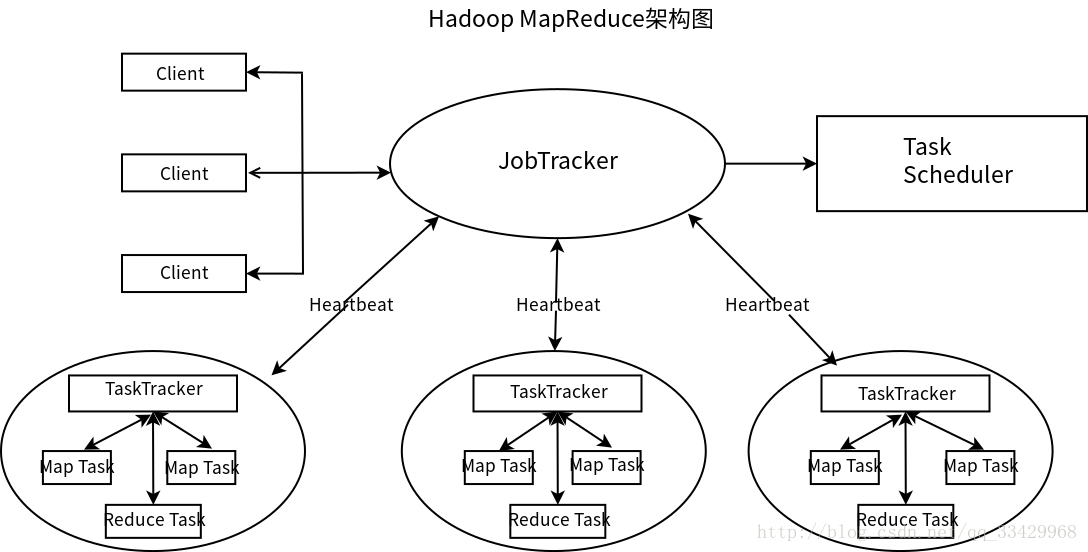
2 各元件詳解
1.Client
使用者編寫的MapReduce程式通過Client提交到JobTracker。
2.JobTracker
參照上圖。
JobTracker主要負責資源監控和作業排程。
JobTracker監控所有TaskTracker與作業的健康狀況;
同時,JobTracker會跟蹤任務的執行進度、資源使用量等資訊,並將這些資訊告訴排程器;
排程器在資源出現空閒時選擇合適的任務使用這些資源。另外,在Hadoop中,任務排程器是一個可插拔的模組,使用者可以根據自己的需要設計相應的排程器。
3.TaskTracker
參照上圖。
TaskTracker1通過Heartbeat將本節點上資源的使用情況和任務的執行進度彙報給JobTracker,2同時接收JobTracker傳送過來的命令並執行相應的操作,例如啟動或終止任務。
4.Task
參照上圖。
Task分為Map Task和Reduce Task兩種,均由TaskTracker啟動。
3 Map/Reduce執行流程詳解
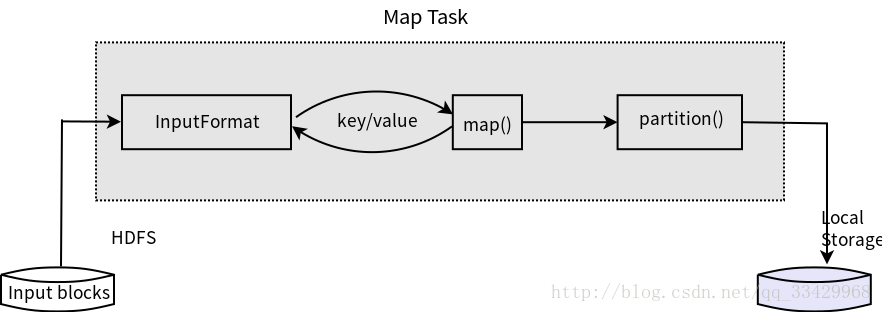
3.1 Map Task執行流程
如下圖所示。
1.Map Task先將對應的split迭代解析成一個個key/value對;
2.一次呼叫使用者定義的map()函式進行處理;
3.並將臨時結果存放到本地磁碟上,其中臨時資料被分成若干個partition,每個partition將被一個Reduce Task處理。
3.2 Reduce Task執行流程
如下圖所示。
1.從遠端節點上讀取Map Task中間結果,即為”Shuffle階段”;
2.按照key對key/value對進行排序,即為”Sort階段”;
3.以此讀取key/value,呼叫使用者的reduce()函式處理,並將最終結果存放到HDFS上,即為”Reduce階段”。

相關推薦
Hadoop系列--Hadoop基本架構之MapReduce架構
1 MapReduce架構的元件組成 1.1 元件組成 Hadoop的MapReduce架構主要由以下幾個元件組成:Client、JobTracker、TaskTracker、Task。
Hadoop 系列(一)基本概念
鍵值 報告 連接 soft 修復 生態圈 硬盤 不足 資源管理 Hadoop 系列(一)基本概念 一、Hadoop 簡介 Hadoop 是一個由 Apache 基金會所開發的分布式系統基礎架構,它可以使用戶在不了解分布式底層細節的情況下開發分布式程序,充分利用集群的威力進行
hadoop之MapReduce架構及Yarn環境搭建
MapReduce架構 基於hadoop2.0架構是運行於YARN環境的。 YARN環境-主從結構 整個yarn環境是MapReduce的執行環境 主節點Resource Manager 負責排程,是Resource Manager,給Node Manag
MySQL架構之MHA架構實戰
fault arc 獨立 支持 ignore llb ssh 啟動 pda 一、MHA原理 1、簡介: MHA(Master High Availability)目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司youshimaton(現就職於Face
軟件架構之分層架構理解
顯示 變化 設計 分離 領域 消息 對數 原則 數據格式 分層架構特定場景:分層架構是一種很常見的架構模式,它也叫N層架構。分層架構適用於一個集成不同功能的系統,當我們需要把很多不同的代碼集起來的時候,這種模式提供了最合理的結構。能讓我們的代碼有足夠的靈活性去應對需求改變。
雲時代架構之荔枝架構實踐與演進歷程
能夠 業務開發 垂直 有一個 導致 不能 之間 ech 項目 荔枝架構實踐與演進歷程 好的系統不是設計出來的,而是演進出來的。荔枝APP,致力於打造聲音處理平臺,幫助人們展現自己的聲音才華。荔枝集錄制、編輯、存儲、收聽、分享於一體,依托聲音底層技術積澱,具有聲音節目錄
深入理解大資料架構之——Lambda架構
目錄 傳統系統的問題 Lambda架構簡介 Lambda架構關鍵特性 資料系統的本質 Lambda的三層架構 Lambda架構元件選型 總結
Hadoop系列--Hadoop核心之MapReduce的原理
1 MapReduce核心原理 “分而治之,平行計算”是MapReduce的核心原理,其實也是大資料處理的中心思想。 1.1 分而治之 在MapReduce中,分而治之,就是, 一個任務分成多個小的子任務(map),並行執行後,
Hadoop系列-IPC之程式碼實現
RPC類是對Server、Client的具體化。在RPC類中規定,客戶程式發出請求呼叫時,引數型別必須是Invocation;從伺服器返回的值型別必須是ObjectWritable。為了加強理解,可以檢視測試類TestIPC。在那裡,規定的引數型別與返回值型別都是LongWritable。RPC類是對Serv
我是菜鳥:hadoop之mapreduce設計理念和基本架構
MapReduce 是一個分散式計算框架,由 程式設計模型 和執行時環境 2部分組成。 程式設計模型為使用者提供了非常易用的程式設計介面,使用者只需要像編寫序列程式那樣實現幾個簡單的函式即可以完成一個分散式程式。 而複雜的節點間通訊,節點實效,資料切分,都有
hadoop基礎之初識Hadoop MapReduce架構
沒有 bsp NPU 有一個 簡單 ont hdf image 運行 Hadoop的mapreduce是一個快速、高效、簡單用於編寫的並運行處理大數據程序並應用在大數據集群上的編程框架。它將復雜的、運行於大規模集群上的並行計算過程高度的抽象到兩個函數:map、reduce。
hadoop大數據平臺架構之DKhadoop詳解
優勢 基礎 可用 核心 技術 並行處理 項目 完整 簡化 hadoop大數據平臺架構之DKhadoop詳解大數據的時代已經來了,信息的爆炸式增長使得越來越多的行業面臨這大量數據需要存儲和分析的挑戰。Hadoop作為一個開源的分布式並行處理平臺,以其高拓展、高效率、高可靠等優
大資料Hadoop系列之Hadoop服務開機自啟動配置
1. 編寫執行指令碼 $ sudo cd /etc/init.d $ sudo vi hadoop #!/bin/bash #chkconfig:35 95 1 #description:script to start/stop hadoop su - hadoop
Hadoop系列(三):hadoop基本測試
下面是對hadoop的一些基本測試示例 Hadoop自帶測試類簡單使用 這個測試類名叫做 hadoop-mapreduce-client-jobclient.jar,位置在 hadoop/share/hadoop/mapreduce/ 目錄下 不帶任何引數可以獲取這個jar的幫助資訊 $ yar
android影象處理系列之五--給圖片新增邊框(中)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
android影象處理系列之六--給圖片新增邊框(下)-圖片疊加
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
android影象處理系列之四--給圖片新增邊框(上)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
hadoop系列之linux系統模板的製作
CentOS7_64 位作業系統模板搭建 說明:鑑於平時使用虛擬機器做各種測試的頻率非常高,難免有很多重複工作。這裡以 CentOS-7-x86_64-Minimal-1804 安裝為基礎安裝了虛擬機器,然後再做了如下配置與安裝。將該虛擬機器做成模板,可以直接拷
Hadoop系列之hadoop環境搭建本地模式
1.1 Hadoop環境搭建 Hadoop 的環境可以有多種方式,比如本地模式(standalone)、偽分散式、完全分散式以及 HA 模式。參考: 1.1.1Hadoop安裝包 核心配置檔案 Hadoop 主要有四個核心配置檔案,
hadoop系列之偽分散式環境搭建及測試驗證
Hadoop2.x 偽分散式環境搭建及測試驗證 作者:Dennis 日期:2018-08-09 前置條件: Linux 虛擬機器一臺,版本為 CentOS 7.4,假設 IP 地址為 192.168.159.181,並修改如下: 修改/etc/hostname 的