
當推薦系統遇上深度學習
原文:
Deep Learning Meets Recommendation Systems
Published by Wann-Jiun Ma at ** January 24, 2017
Contributed by Wann-Jiun Ma. He is currently attending the NYC Data Science Academy Online Data Science Bootcamp program. This post is based on his final capstone project and is finished in two weeks (part-time).
Introduction
幾乎每個人都喜歡花時間與家人和朋友一起觀看電影。 當我們坐在我們的沙發上選擇我們將要在接下來的兩個小時裡觀看的電影時,結果花費了20分鐘也找不到一個合適的電影,這樣的經歷真是太令人失望了 當我們需要選擇電影並且節省時間時,我們絕對需要計算機程式向我們推薦電影。顯然,電影推薦已經成為我們生活的重要組成部分。 據資料科學中心 Data Science Central 統計,儘管資料很難得到,但據很多知情人士估計,對於像亞馬遜和Netflix這樣的主要電子商務平臺,推薦系統可能會承擔多達10%至25%的增量收入。在這裡,我研究了電影推薦的一些基本推薦演算法,並嘗試將深度學習整合到我的電影推薦系統中。
電影是娛樂和視覺藝術相結合的絕佳例子。電影海報通常可以直接快速的將電影的情況傳遞給觀眾。根據 DesignMantic的說法,“任何電影的釋出和預先發布,他們的海報是引發炒作的主要因素,一半以上的人(即目標受眾)是基於電影海報決定是否預訂門票並觀看電影“。我們甚至可以通過檢視海報的排版來預測任何電影的氛圍場景(movie’s mood by just looking at the typography of is poster)。這聽起來有點像魔術,但絕對有可能通過檢視其海報來預測電影的流派。對於我自己,我只是看它的海報來決定是否看電影。例如,既然我不是漫畫電影的粉絲,所以每當我看到有卡通主題或顏色的電影海報,我知道這些電影不是我的選擇之內。這個決策過程非常簡單,不需要任何評論閱讀(不確定人們有時間閱讀評論)。因此,除了一些標準的電影推薦演算法之外,我還使用深度學習來處理電影海報,並嘗試尋找類似的電影給使用者推薦。目標是模仿人類的視覺能力,並通過觀看基於深度學習的電影海報來構建直觀的電影推薦者。這個專案的靈感來自Ethan Rosenthal的博文 Ethan Rosenthal’s blog posts ,我在他的博文中修改了他的程式碼,以適應這裡使用的演算法。
我們使用從MovieLens網站MovieLens 下載的電影資料集。 該資料集由1071個使用者應用於9,066部電影的100,000個評級和1,300個標籤應用程式組成。 資料集最近更新於10/2016。
Collaborative Filtering
大致來說,有三種類型的推薦系統(不包括簡單排名方法):
- 基於內容的推薦
- 協同過濾
- 混合模型
對於基於內容的推薦系統content-based recommendation ,這是一個迴歸問題,我們嘗試使用專案內容作為特徵進行使用者到專案的評分預測。另一方面,對於基於協同過濾的推薦系統 collaborative filtering ,我們通常不會提前知道特徵內容,並且通過使用不同使用者之間的相似性(使用者可以給出相同專案的相似評分)和專案之間的相似性(類似的電影可能會被使用者評分相似),我們會學習潛在的特徵,同時對使用者對商品的評分做出預測。另外,在學習了專案的特徵之後,我們可以根據以前的使用資訊來測量專案之間的相似度,並向用戶推薦最相似的專案。基於內容和協作過濾的建議是十多年前的最先進的技術。顯然,有許多不同的模型和演算法來提高預測效能。例如,對於我們預先沒有使用者到專案評級資訊的情況,我們可以使用所謂的隱性矩陣因式分解 implicit matrix factorization,並用一些偏好和置信度度量來替換使用者到專案的評級,例如使用者點選相應專案執行協作過濾的次數。此外,我們還可以結合基於內容的協同過濾方法,將內容用作“側面資訊”來提高預測效能。這種混合方法通常通過“學習排名”演算法”Learning to Rank”實現。
在這個專案中,我將重點放在基於協同過濾的方法上。首先,我將討論使用專案(使用者)相似度來進行使用者對專案的評估預測而無需迴歸,也可以根據專案的相似度進行推薦。然後,我將討論如何使用迴歸來學習潛在的特徵並同時做出建議。之後,我們將會看到如何在推薦系統中使用深度學習。
Item Similarity
對於基於協同過濾的推薦系統,第一個構建塊構建了每個行代表使用者的評分矩陣,每列對應於該使用者給予特定電影的平分。 我們建立我們的評分矩陣如下:
df = pd.read_csv('ratings.csv', sep=',')
df_id = pd.read_csv('links.csv', sep=',')
df = pd.merge(df, df_id, on=['movieId'])
rating_matrix = np.zeros((df.userId.unique().shape[0], max(df.movieId)))
for row in df.itertuples():
rating_matrix[row[1]-1, row[2]-1] = row[3]
rating_matrix = rating_matrix[:,:9000]其中“ratings.csv”包含使用者ID,電影ID,評分和時間資訊,“link.csv”包含電影ID,IMDB id和TMDB id。 我們結合這兩個表,因為每個電影需要IMDB id資訊才能從電影資料庫網站 The Movie Database使用其API獲取電影海報。 我們檢查我們的評分矩陣的稀疏度如下:
sparsity = float(len(ratings.nonzero()[0]))
sparsity /= (ratings.shape[0] * ratings.shape[1])
sparsity *= 100其中評分矩陣稀疏,只有非零項的1.40%。 現在,為了訓練和測試,我們將評級矩陣分成兩個較小的矩陣。 我們從評級矩陣中移除10個評級,並將它們放在測試集中。
train_matrix = rating_matrix.copy()
test_matrix = np.zeros(ratings_matrix.shape)
for i in xrange(rating_matrix.shape[0]):
rating_idx = np.random.choice(
rating_matrix[i, :].nonzero()[0],
size=10,
replace=True)
train_matrix[i, rating_idx] = 0.0
test_matrix[i, rating_idx] = rating_matrix[i, rating_idx]
where, s(u,v) *is just the cosine similarity measure between user *u and user v.
similarity_user = train_matrix.dot(train_matrix.T) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_user))])
similarity_user = ( similarity_user / (norms * norms.T) )
similarity_movie = train_matrix.T.dot(train_matrix) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_movie))])
similarity_movie = ( similarity_movie / (norms * norms.T) )使用使用者之間的相似性,我們能夠對每個使用者對電影的評分進行預測,並且還可以計算我們的使用者到電影評分預測的相應MSE。 通過考慮類似使用者給出的評級來進行預測。 特別是,我們可以根據以下公式進行使用者到電影的評分預測。
其中使用者u到電影i的預測是使用者v給予電影i的使用者u和v之間的相似度作為權重的等級的加權和(歸一化)。
from sklearn.metrics import mean_squared_error
prediction = similarity_user.dot(train_matrix) / np.array([np.abs(similarity_user).sum(axis=1)]).T
prediction = prediction[test_matrix.nonzero()].flatten()
test_vector = test_matrix[test_matrix.nonzero()].flatten()
mse = mean_squared_error(prediction, test_vector)
print 'MSE = ' + str(mse)我們的預測獲得的MSE是9.8252。 這個數字是什麼意思? 這是好還是壞的推薦? 通過檢視MSE得分來評估我們的預測效能不是非常直觀。 因此,我們通過直接檢視電影推薦來評估表現。 我們會查詢感興趣的電影,並要求我們的系統向我們推薦幾部電影。 首先要做的是獲取相應的電影海報,以便我們可以看到推薦的電影是什麼。 我們使用IMDB ID號碼從電影資料庫網站 The Movie Database使用其API獲取電影海報。
import requests
import json
from IPython.display import Image
from IPython.display import display
from IPython.display import HTML
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
idx_to_movie
k = 6
idx = 0
movies = [ idx_to_movie[x] for x in np.argsort(similarity_movie[idx,:])[:-k-1:-1] ]
movies = filter(lambda imdb: len(str(imdb)) == 6, movies)
n_display = 5
URL = [0]*n_display
IMDB = [0]*n_display
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
i += 1
images = ''
for i in range(n_display):
images += "<img style='width: 100px; margin: 0px; \
float: left; border: 1px solid black;' src='%s' />" \
% URL[i]
display(HTML(images)) 現在,這很有趣! 我們來看看我們的建議。 我們將顯示四個最相似的電影以及我們查詢的動作。 我們查詢的電影放在左邊,後面是四個推薦的電影。 我們來試試查詢“Heat”。

Heat是1995年的美國犯罪電影,由Robert De Niro,Al Pacino主演。 結果看起來不錯 離開拉斯維加斯可能不是一個很好的建議。 我猜是因為Nicolas Cage在電影“The ROCK”中,對於熱愛的觀眾來說,這是一個很好的推薦。 因此,它可能是使用相似矩陣與協同過濾的缺點之一。 我們來試試更多的例子。

看起來不錯,Toy Story 2絕對應該向喜歡Toy Story的觀眾推薦。 但是,Forrest Gump對我來說並沒有太大的意義。 顯然,湯姆·漢克斯(Tom Hanks)的聲音在玩具總動員電影中,所以推薦了阿甘。 請注意,只要檢視海報,就可以在玩具總動員和福雷斯特·甘普之間分辨出電影型別,情緒等差異,對吧? 當他看到海報假設每個孩子都喜歡玩具總動員時,孩子可能會忽略Forrest Gump。
Alternating and Stochastic Gradient Descent
在前面的討論中,我們簡單地計算使用者和專案的餘弦相似度,並使用這種相似性度量來預測使用者對專案的評分,並提出專案到專案的推薦。 我們現在把我們的問題作為一個迴歸問題。 我們為所有使用者引入所有電影和權重向量x的潛在特徵。 目標是簡單地將評分預測的MSE(L2規範正則化術語)最小化。
注意,現在權重向量和特徵向量都是決策變數。 顯然這並不是一個凸問題。 就目前來說,不用擔心這個非凸的問題的收斂性。 有很多方法來解決這個非凸優化問題。 一種方法是以交替的方式求解權重向量(使用者)和特徵向量(用於電影)。 當我們求解權重向量時,我們假定特徵向量是常數向量。 另一方面,當我們解決特徵向量時,我們假設權重向量是常數向量。 解決這個迴歸問題的另一種方法是組合權重向量和特徵向量的更新,並在相同的迭代中進行更新。 此外,可以實現隨機梯度下降以加速計算。 在這裡,我使用隨機梯度下降法來解決這個迴歸問題。 我的預測的MSE如下所示。
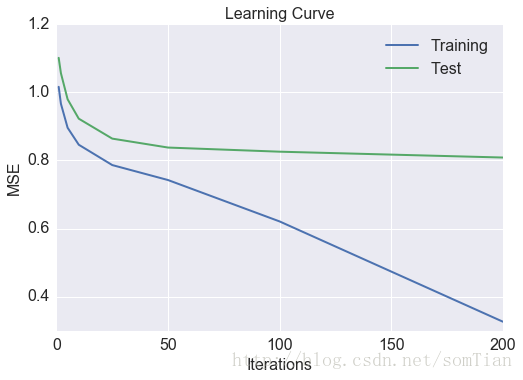
MSE比使用相似矩陣獲得的小得多。 當然,我們也可以使用網格搜尋和交叉驗證來調整我們的模型和演算法的引數。
再次,我們來看看我們的建議,通過查詢感興趣的電影。

看起來效果並不好,我不知道這四部電影是通過查詢熱推薦給我的。 他們看起來完全不匹配Heat。 他們看起來像浪漫/戲劇電影。 如果我發現一部類似於美國電影大片電影明星的電影,我想要觀看一場電視劇? 我覺得很好的MSE結果可能給我們一個非常糟糕的建議。
那麼讓我們來討論基於協同過濾的推薦系統的弱點。
- 協同過濾方法通過使用資料查詢類似的使用者和電影,這導致流行專案比不受歡迎的專案更容易被推薦。
- 由於沒有與這些電影相關的許多使用資料,協作過濾很難為使用者推薦任何新電影。
在接下來的討論中,我們將考慮採用不同的方法來解決協同過濾問題。 我們用深度的學習向用戶推薦電影。
Deep Learning
我們將在Keras中使用VGG16訓練我們的神經網路。 我們的資料集中沒有目標,我們只考慮第四到最後一層作為特徵向量。 我們使用此特徵向量來表徵我們的資料集中的每個電影。 在訓練我們的神經網路之前,有一些預處理步驟。訓練過程總結如下。
df_id = pd.read_csv('links.csv', sep=',')
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
total_movies = 9000
movies = [0]*total_movies
for i in range(len(movies)):
if i in idx_to_movie.keys() and len(str(idx_to_movie[i])) == 6:
movies[i] = (idx_to_movie[i])
movies = filter(lambda imdb: imdb != 0, movies)
total_movies = len(movies)
URL = [0]*total_movies
IMDB = [0]*total_movies
URL_IMDB = {"url":[],"imdb":[]}
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
if URL[i] != base_url+"":
URL_IMDB["url"].append(URL[i])
URL_IMDB["imdb"].append(IMDB[i])
i += 1
# URL = filter(lambda url: url != base_url+"", URL)
df = pd.DataFrame(data=URL_IMDB)
total_movies = len(df)
import urllib
poster_path = "/Users/wannjiun/Desktop/nycdsa/project_5_recommender/posters/"
for i in range(total_movies):
urllib.urlretrieve(df.url[i], poster_path + str(i) + ".jpg")
from keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image as kimage
image = [0]*total_movies
x = [0]*total_movies
for i in range(total_movies):
image[i] = kimage.load_img(poster_path + str(i) + ".jpg", target_size=(224, 224))
x[i] = kimage.img_to_array(image[i])
x[i] = np.expand_dims(x[i], axis=0)
x[i] = preprocess_input(x[i])
model = VGG16(include_top=False, weights='imagenet')
prediction = [0]*total_movies
matrix_res = np.zeros([total_movies,25088])
for i in range(total_movies):
prediction[i] = model.predict(x[i]).ravel()
matrix_res[i,:] = prediction[i]
similarity_deep = matrix_res.dot(matrix_res.T)
norms = np.array([np.sqrt(np.diagonal(similarity_deep))])
similarity_deep = similarity_deep / norms / norms.T 在程式碼中,我們首先從TMDB網站使用IMDB id的API獲取電影海報,然後我們向VGG16提供海報並訓練我們的神經網路,最後,我們使用VGG16學習的功能計算餘弦相似度。 在我們得到電影相似性之後,我們可以推薦類似的電影,使用最高的相似度。 請注意,VGG16學習的總共有25088個特徵,我們使用這些特徵來表示我們的資料集中的每個電影。
讓我們看看使用深度學習的推薦。

對Heat的推薦沒有愛情戲劇!這些海報肯定有一些共同的特點。 他們是深藍色,有人在海報等。再次,讓我們試一下Toy Story。

Forrest Gump沒有被推薦! 結果看起來不錯! 我非常喜歡這樣做,所以讓我們再來一些例子。

請注意,這些海報中有一到兩個人,非常冷的主題或風格。

這些海報想讓觀眾知道相應的電影是有趣的,響亮的,密集的,並且在他們中有很多的動作,所以海報的顏色和影象是非常強大的。

另一方面,這些海報想要向觀眾展示相應的電影是關於一個人的。

我們發現一些類似於功夫熊貓的電影。

這是一個非常有趣的一個。 我們確實發現了類似的怪物,也發現了Tom Cruse!

所有這些海報都有一個類似姿勢的女人。 等待! 是Shaq!?

我們成功地找到了蜘蛛俠!

這一個發現了類似排版的海報。
Conclusions
在推薦系統中有幾種使用深度學習的方法:
- 無監督的學習方法。
- 預測協同過濾產生的潛在特徵。
- 使用深度學習產生的功能作為輔助資訊。
電影海報有元素,引起觀眾興趣和興趣。在這個專案中,我們使用深度學習作為一種無監督的學習方法,並通過處理電影海報來學習電影的相似性。顯然,這只是在推薦系統中使用深度學習的第一步。有很多事情我們可以嘗試。例如,我們可以使用深度學習來預測協同過濾所產生的潛在特徵。 Spotify已經對類似的方法進行了音樂推薦。而不是影象處理,他們考慮使用深度學習來預測通過處理一首歌曲的聲音從協同過濾得到的潛在特徵。另一個可能的方法是使用深入學習的特徵作為輔助資訊來提高預測精度。
References:
– Andrew Ng, “Machine Learning,” Recommender Systems, 2016
– Aaron van den Oord, et al., “Deep content-based music recommendation,” NIPS, 2013
– Yifan Hu, et al., “Collaborative Filtering for Implicit Feedback Datasets,”
– Ste en Rendle, “BPR: Bayesian Personalized Ranking from Implicit Feedback,”
相關推薦
當推薦系統遇上深度學習
原文: Deep Learning Meets Recommendation Systems Published by Wann-Jiun Ma at ** January 24, 2017 Contributed by Wann-Jiun
推薦系統遇上深度學習
參考記錄: 推薦系統遇上深度學習(一)–FM模型理論和實踐: https://cloud.tencent.com/developer/article/1099532 推薦系統遇上深度學習(二)–FM模型理論和實踐: https://cloud.tencent.com
推薦系統遇上深度學習(十)--GBDT+LR融合方案實戰
寫在前面的話 GBDT和LR的融合在廣告點選率預估中算是發展比較早的演算法,為什麼會在這裡寫這麼一篇呢?本來想嘗試寫一下阿里的深度興趣網路(Deep Interest Network),發現阿里之前還有一個演算法MLR,然後去查詢相關的資料,裡面提及了樹模型也就是GBD
推薦系統遇上深度學習(二十二):DeepFM升級版XDeepFM模型強勢來襲!
今天我們要學習的模型是xDeepFM模型,論文地址為:https://arxiv.org/abs/1803.05170。文中包含我個人的一些理解,如有不對的地方,歡迎大家指正!廢話不多說,我們進入正題! 1、引言 對於預測性的系統來說,特徵工程起到了至關重要的作用。特徵工
推薦系統遇上深度學習(十)--GBDT+LR融合方案實戰--解決特徵組合問題
歡迎關注天善智慧,我們是專注於商業智慧BI,人工智慧AI,大資料分析與挖掘領域的垂直社群,學習,問答、求職一站式搞定! 對商業智慧BI、大資料分析挖掘、機器學習,python,R等資料領域感興趣的同學加微信:tsaiedu,並註明訊息來源,邀請你進入資料愛好者交
推薦系統遇上深度學習(十六)--詳解推薦系統中的常用評測指標
最近閱讀論文的過程中,發現推薦系統中的評價指標真的是五花八門,今天我們就來系統的總結一下,這些指標有的適用於二分類問題,有的適用於對推薦列表topk的評價。1、精確率、召回率、F1值我們首先來看一下混淆矩陣,對於二分類問題,真實的樣本標籤有兩類,我們學習器預測的類別有兩類,那麼根據二者的類別組合可以劃分為四組
推薦系統遇上深度學習(二)--FFM模型理論和實踐
全文共1979字,6張圖,預計閱讀時間12分鐘。FFM理論在CTR預估中,經常會遇到one-ho
推薦系統遇上深度學習(三)--DeepFM模型理論和實踐
1、背景特徵組合的挑戰對於一個基於CTR預估的推薦系統,最重要的是學習到使用者點選行為背後隱含的特徵組合。在不同的推薦場景中,低階組合特徵或者高階組合特徵可能都會對最終的CTR產生影響。之前介紹的因子分解機(Factorization Machines, FM)通過對於每一維特徵的隱變數內積來提取特徵組合。最
推薦系統遇上深度學習(一)--FM模型理論和實踐
全文共2503字,15張圖,預計閱讀時間15分鐘。FM背景在計算廣告和推薦系統中,CTR預估(c
推薦系統遇上深度學習(二十)--貝葉斯個性化排序(BPR)演算法原理及實戰
原創:石曉文 小小挖掘機 2018-06-29推薦系統遇上深度學習系列:排序推薦演算法大體上可以分為三類,第一類排序演算法類別是點對方法(Pointwise Approach),這類演算法將排序問題被轉化為分類、迴歸之類的問題,並使用現有分類、迴歸等方法進行實現。第二類排序演算法是成對
推薦系統遇上深度學習(十二)--推薦系統中的EE問題及基本Bandit演算法
1、推薦系統中的EE問題Exploration and Exploitation(EE問題,探索與開發)是計算廣告和推薦系統裡常見的一個問題,為什麼會有EE問題?簡單來說,是為了平衡推薦系統的準確性和多樣性。EE問題中的Exploitation就是:對使用者比較確定的興趣,當然要利用開採迎合,好比說已經掙到的
推薦系統遇上深度學習(十八)--探祕阿里之深度興趣網路(DIN)淺析及實現
阿里近幾年公開的推薦領域演算法有許多,既有傳統領域的探索如MLR演算法,還有深度學習領域的探索如entire -space multi-task model,Deep Interest Network等,同時跟清華大學合作展開了強化學習領域的探索,提出了MARDPG演算法。上一篇,我們介紹了MLR演算法,通過
推薦系統遇上深度學習(十九)--探祕阿里之完整空間多工模型ESSM
歡迎關注天善智慧,我們是專注於商業智慧BI,人工智慧AI,大資料分析與挖掘領域的垂直社群,學習,問答、求職一站式搞定! 對商業智慧BI、大資料分析挖掘、機器學習,python,R等資料領域感興趣的同學加微信:tsaiedu,並註明訊息來源,邀請你進入資料愛好者交流群,資料愛好者們都
推薦系統遇上深度學習(五)--Deep&Cross Network模型理論和實踐
1、原理Deep&Cross Network模型我們下面將簡稱DCN模型:一個DCN模型從嵌入和堆積層開始,接著是一個交叉網路和一個與之平行的深度網路,之後是最後的組合層,它結合了兩個網路的輸出。完整的網路模型如圖:嵌入和堆疊層我們考慮具有離散和連續特徵的輸入資料。在網路規模推薦系統中,如CTR預測,
推薦系統遇上深度學習(四)--多值離散特徵的embedding解決方案
1、背景在本系列第三篇文章中,在處理DeepFM資料時,由於每一個離散特徵只有一個取值,因此我們在處理的過程中,將原始資料處理成了兩個檔案,一個記錄特徵的索引,一個記錄了特徵的值,而每一列,則代表一個離散特徵。但假如,我們某一個離散特徵有多個取值呢?舉個例子來說,每個人喜歡的NBA球隊,有的人可能喜歡火箭和湖
推薦系統遇上深度學習(六)--PNN模型理論和實踐
全文共2621字,21張圖,預計閱讀時間15分鐘。原理PNN,全稱為Product-based
推薦系統遇上深度學習(十四)--強化學習與推薦系統的強強聯合
之前學習了強化學習的一些內容以及推薦系統的一些內容,二者能否聯絡起來呢!今天閱讀了一篇論文,題目叫《DRN: A Deep Reinforcement Learning Framework for News Recommendation》。該論文便是深度強化學習和推薦系統的一個結合,也算是提供了一個利用強化學
推薦系統遇上深度學習(五)--Deep&Cross Network模型理論和實踐
歡迎關注天善智慧,我們是專注於商業智慧BI,人工智慧AI,大資料分析與挖掘領域的垂直社群,學習,問答、求職一站式搞定! 對商業智慧BI、大資料分析挖掘、機器學習,python,R等資料領域感興趣的同學加微信:tsaiedu,並註明訊息來源,邀請你進入資料愛好者交流群,資料愛好者們都
推薦系統遇上深度學習(二十)-貝葉斯個性化排序演算法原理及實戰
排序推薦演算法大體上可以分為三類,第一類排序演算法類別是點對方法(Pointwise Approach),這類演算法將排序問題被轉化為分類、迴歸之類的問題,並使用現有分類、迴歸等方法進行實現。第二類排序演算法是成對方法(Pairwise Approach),在序列方法中
當小樣本遇上機器學習 few shot learning
https://blog.csdn.net/mao_feng/article/details/78939864 [1] G Koch, R Zemel, and R Salakhutdinov. Siamese neural networks for