
[機器學習]基於OpenCV實現最簡單的數字識別
http://blog.csdn.net/jinzhuojun/article/details/8579416
本文將基於OpenCV實現簡單的數字識別。這裡以遊戲Angry Birds為例,通過以下幾個主要步驟對其中右上角的分數部分進行自動識別。
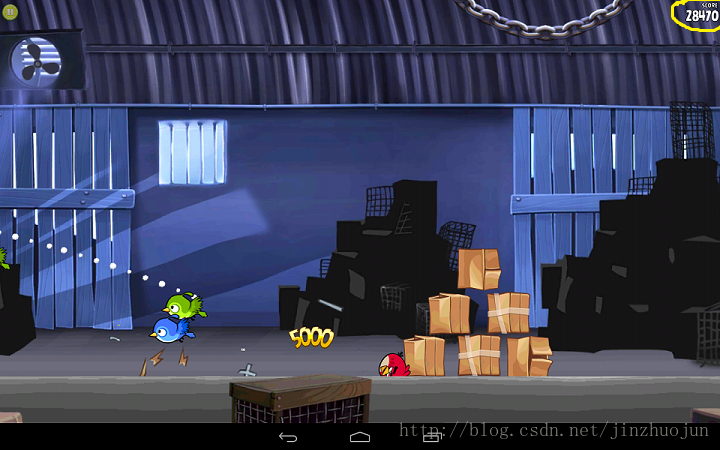
1. 學習分類器
根據訓練樣本,選取模型訓練產生數字分類器。這裡的樣本可以是通用的數字樣本庫(如NIST等),也可以是針對應用場景而製作的專門訓練樣本。前者優在泛化性,後者強在準確率,當然常用做法是將這兩者結合,即在通用數字庫基礎上做修改。另外這裡由於模式並不複雜,計算量也不大,所以不對樣本進行特徵提取,對原始樣本作簡單變換後直接作為訓練樣本。
具體地,首先是生成訓練樣本矩陣,一般樣本是以二維矩陣的方式存在檔案當中,現在要將它們讀出來,進行適當的預處理,然後生成OpenCV能理解的資料結構。
- train_X = cvCreateMat(sample_num * class_num, size * size, CV_32FC1);
- train_Y = cvCreateMat(sample_num * class_num, 1, CV_32FC1);
- for(i = 0; i < class_num; i++){
- for(j = 0; j < sample_num; j++){
- src_image = cvLoadImage(file,0);
- pimage = preprocessing(src_image, size, size);
- ...
- cvGetRow(train_X, &row, i * sample_num + j);
- row_vec = cvReshape(&data, &mathdr, 0, 1);
- cvCopy(row_vec, &row, NULL);
- ...
- cvGetRow(train_Y, &row, i * sample_num + j);
- cvSet(&row, cvRealScalar(i));
- }
- }
訓練樣本中的數字位置形態各異,因此讀入時需要進行規整化。主要方法是先找到數字的邊界框,然後以寬和高中大的一邊為基準進行縮放和拉伸,從而使得其可以佔滿整個表示單個樣本的矩陣。
- IplImage preprocessing(IplImage* img, int w, int h){
- ...
- bb = findBoundingBox(img);
- cvGetSubRect(img, &data, cvRect(bb.x, bb.y, bb.width, bb.height));
- size = (bb.width > bb.height) ? bb.width : bb.height;
- res = cvCreateImage(cvSize(size, size), 8, 1);
- x = floor((float)(size - bb.width) / 2.0f);
- y = floor((float)(size - bb.height) / 2.0f);
- cvGetSubRect(res, &subdata, cvRect((int)x, (int)y, bb.width, bb.height));
- cvCopy(&data, &subdata, NULL);
- ret = cvCreateImage(cvSize(w, h), 8, 1);
- cvResize(res, ret, CV_INTER_NN);
- return *ret;
- }
假設單個樣本可表示為0/1矩陣,那findBoundingBox()只要從x和y方向分別掃描最大最小的非0值就可以了。 訓練樣本準備好後,在OpenCV中建立相應的分類器非常方便。這裡用的是KNN,當然除了KNN外還有其它很多封裝好的分類器(如NN, SVM等)。
- knn = new CvKNearest(train_X, train_Y, 0, false, K);
2. 影象預處理
前面通過學習產生了分類器,但我們輸入影象中的數字並不能直接作為測試輸入。影象中的數字筆畫有時並不規整,還可能相互重疊。因為本文例子為了簡化用的是螢幕截圖,所以位置形變校正,色彩亮度校正等等都省去了,但仍需要一些簡單處理。下面先對輸入影象進行一把簡單的預處理,主要目的是將數字之間兩兩分開。方法很簡單,首先將影象轉成二值圖,然後腐蝕一把,數字之間就分離得比較開了,這樣便於我們下一步分割和識別。這樣做還有個好處,就是把其餘的噪聲也順帶去掉了。
- cvtColor(input, out_img, CV_BGR2GRAY);
- threshold(out_img, out_img, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY);
- ...
- erode(out_img, out_img, elem);
結果:
3. 影象分割
接下來,就可以對影象進行分割了。由於我們的分類器只能對數字一個一個地識別,所以首先要把每個數字分割出來。基本思想是先用findContours()函式把基本輪廓找出來,然後通過簡單驗證以確認是否為數字的輪廓。對於那些通過驗證的輪廓,接下去會用boundingRect()找出它們的包圍盒。
- vector< vector< Point> > contours;
- findContours(contour_img, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
- vector<vector<Point> >::iterator it = contours.begin();
- while (it!=contours.end()) {
- RotatedRect rect = minAreaRect(Mat(*it));
- if(verifyRect(rect)){
- ++it; // A valid rectangle found
- } else {
- it= contours.erase(it);
- }
- }
- ...
- vector<Rect> boundRect(contours.size());
- for (int i = 0; i < contours.size(); ++i) {
- Scalar color = Scalar(200, 200, 200);
- boundRect[i] = boundingRect(Mat(contours[i]));
- rectangle(out_img, boundRect[i].tl(), boundRect[i].br(), color, 0.2, 8, 0);
- CvRect roi = CvRect(boundRect[i]);
- IplImage orig = out_img;
- IplImage *res = cvCreateImage(cvSize(roi.width, roi.height), orig.depth, orig.nChannels);
- cvSetImageROI(&orig, roi);
- cvCopy(&orig, res);
- cvResetImageROI(&orig);
- IplImage *bininv_img;
- bininv_img = cvCreateImage(cvSize(128, 128), IPL_DEPTH_8U, 1);
- cvResize(res, bininv_img);
- cvThreshold(bininv_img, bininv_img, 100, 255, CV_THRESH_BINARY_INV);
- int ret = do_ocr(bininv_img);
- res_elem elem;
- elem.num = ret;
- elem.xpos = boundRect[i].tl().x;
- res_vec.push_back(elem);
- ...
- }
結果:

4. 應用分類器
分割完後就可以應用我們前面訓練好的分類器對分割結果進行識別了。當然,如果感覺結果不滿意,可以將分類錯誤的樣本加上正確的標籤後放入訓練樣本重新生成分類器,使得分類器能夠有更好的識別率。上一步中的do_ocr()函式就是利用先前訓練好的分類器識別單個數字。注意訓練樣本進行過怎麼樣的預處理,這裡也一樣要做。
- int do_ocr(IplImage *img)
- {
- ...
- pimage = preprocessing(img, size, size);
- ...
- cvGetSubRect(pimage, &data, cvRect(0, 0, size, size));
- CvMat mathdr, *vec;
- vec = cvReshape(&data, &mathdr, 0, 1);
- ret = knn->find_nearest(vec, K, 0, 0, nearest, 0);
- return (int)ret;
- }
5. 後期處理
因為分割影象時查詢數字輪廓並不保證是按順序來的,所以這兒要將識別結果按分割時輸出的包圍盒位置資訊進行排序,最後將它們轉換成數字輸出。
- sort(res_vec.begin(), res_vec.end(), sort_func);
- int j, num = 0;
- for (j = 0; j < res_vec.size(); ++j) {
- num = num * 10 + res_vec[j].num;
- }
- char resbuf[256];
- sprintf(resbuf, "%d", num);
- putText(show_img, resbuf, Point(OUTPUT_X, OUTPUT_Y), FONT_HERSHEY_SIMPLEX, 0.8, Scalar(0, 255, 0), 2);
- imshow("show", show_img);
結果:

相關推薦
[機器學習]基於OpenCV實現最簡單的數字識別
http://blog.csdn.net/jinzhuojun/article/details/8579416 本文將基於OpenCV實現簡單的數字識別。這裡以遊戲Angry Birds為例,通過以下幾個主要步驟對其中右上角的分數部分進行自動識別。 1. 學習分類器 根據
Java基於opencv實現圖像數字識別(一)
binary oid ring 是把 sca pre 內存 還需要 自己 Java基於opencv實現圖像數字識別(一) 最近分到了一個任務,要做數字識別,我分配到的任務是把數字一個個的分開;當時一臉懵逼,直接百度java如何分割圖片中的數字,然後就百度到了用Buffere
Java基於opencv實現圖像數字識別(二)—基本流程
數字 都是 模型 PE 設計 category 理解 兩種 ace Java基於opencv實現圖像數字識別(二)—基本流程 做一個項目之前呢,我們應該有一個總體把握,或者是進度條;來一步步的督促著我們來完成這個項目,在我們正式開始前呢,我們先討論下流程。 我做的主要是表格
機器學習---用python實現最小二乘線性回歸並用隨機梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
lin python get stat linspace oms mach 實現 all 在《機器學習---線性回歸(Machine Learning Linear Regression)》一文中,我們主要介紹了最小二乘線性回歸模型以及簡單地介紹了梯度下降法。現在,讓我們來
機器學習實戰——KNN演算法手寫數字識別
資料來源 我們的文字是形如這樣的,每個數字都有很多txt檔案,TXT裡面是01數字,表示手寫數字的灰度圖。 現在我們要用knn演算法實現數字識別。 資料處理 每個txt檔案都是32*32的0,1矩陣,如果要使用knn,那麼還得考慮行列關係,如果能把它拉開,只有一行,就可以不必考慮數字
基於opencv的手寫數字識別(MFC,HOG,SVM)
因為本程式是提取HOG特徵,使用SVM進行分類的,所以大概瞭解下HOG的一些知識,其中我覺得怎麼計算影象HOG特徵的維度會對程式瞭解有幫助 關於HOG,我們可以參考: http://gz-ricky.blogbus.com/logs/85326
機器學習實戰例項之手寫數字識別(KNN、python3)
from numpy import * from os import listdir import operator def img2Vector(filename): returnVecter = zeros((1,1024)) fr = open(fil
python tensorflow 基於cnn實現手寫數字識別
感覺剛才的程式碼不夠給力,所以再儲存一份基於cnn的手寫數字自識別的程式碼 # -*- coding: utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist
機器學習-實戰-入門-MNIST手寫數字識別
作者:橘子派 宣告:版權所有,轉載請註明出處,謝謝。 實驗環境: Windows10 Sublime Anaconda 1.6.0 Python3.6 程式碼功能包括: 一.ubyte資料集轉
基於OpenCV的數碼管數字識別
利用OpenCV可實現工業儀表裝置的讀數識別。儀表一般可分為兩:數字式儀表和指標式儀表,本博文主要介紹一下數字式儀表識別的關鍵技術。下圖是用軟體模擬的數碼管圖片,本文識別的也就是圖中的數字。 一、影象定位 在實際的應用場景中,拍攝到的儀表區域很有可能會包含多
100天搞定機器學習|day39 Tensorflow Keras手寫數字識別
提示:建議先看day36-38的內容 TensorFlow™ 是一個採用資料流圖(data flow graphs),用於數值計算的開源軟體庫。節點(Nodes)在圖中表示數學操作,圖中的線(edges)則表示在節點間相互聯絡的多維資料陣列,即張量(tensor)。它靈活的架構讓你可以在多種平臺上展開計算,
100行代碼實現最簡單的基於FFMPEG+SDL的視頻播放器(SDL1.x)【轉】
工程 全屏 升級版 gin avcodec ive 系列文章 相同 hello 轉自:http://blog.csdn.net/leixiaohua1020/article/details/8652605 版權聲明:本文為博主原創文章,未經博主允許不得轉載。
ML:從0到1 機器學習演算法思路實現全部過程最強攻略
ML:從0到1 機器學習演算法思路實現全部過程最強攻略 設計思路 相關文章 ML之FE:結合Kaggle比賽的某一案例細究Feature Engineering思路框架ML之FE:Feature Engineering——資料型別之預處
機器學習--k-近鄰演算法(kNN)實現手寫數字識別
這裡的手寫數字以0,1的形式儲存在文字檔案中,大小是32x32.目錄trainingDigits有1934個樣本。0-9每個數字大約有200個樣本,命名規則如下: 下劃線前的數字代表是樣本0-9的
【機器學習筆記】基於k-近鄰演算法的數字識別
更多詳細內容參考《機器學習實戰》 k-近鄰演算法簡介 簡單的說,k-近鄰演算法採用測量不同特徵值之間的距離方法進行分類。它的工作原理是:存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每個資料與所屬分類的對應關係。輸入沒
100行程式碼實現最簡單的基於FFMPEG+SDL的視訊播放器(SDL1.x)
=====================================================最簡單的基於FFmpeg的視訊播放器系列文章列表:=====================================================簡介FFMPEG
機器學習實戰——python實現簡單的樸素貝葉斯分類器
基礎公式 貝葉斯定理:P(A|B) = P(B|A)*P(A)/P(B) 假設B1,B2…Bn彼此獨立,則有:P(B1xB2x…xBn|A) = P(B1|A)xP(B2|A)x…xP(Bn|A) 資料(虛構) A1 A2 A3 A4 A5 B
曲線擬合的最小二乘法(基於OpenCV實現)
在科學實驗資料處理中,往往要根據一組給定的實驗資料,求出自變數x與因變數y的函式關係,這是為待定引數,由於觀測資料總有誤差,且待定引數ai的數量比給定資料點的數量少(即n<m),因此它不同於插值問題.這類問題不要求通過點,而只要求在給定點上的誤差的平方和最小.當時,即
各種機器學習方法(線性迴歸、支援向量機、決策樹、樸素貝葉斯、KNN演算法、邏輯迴歸)實現手寫數字識別並用準確率、召回率、F1進行評估
本文轉自:http://blog.csdn.net/net_wolf_007/article/details/51794254 前面兩章對資料進行了簡單的特徵提取及線性迴歸分析。識別率已經達到了85%, 完成了數字識別的第一步:資料探測。 這一章要做的就各
Objective-C學習筆記(四)——OC實現最簡單的數學運算
本篇帖子會實現使用OC的最簡單的加減乘除運算,學習的知識點包括變數定義,運算方法,格式化輸出等概念。主要學習基本的語法,其實和C語言的語法還是比較類似的。具體程式碼只要寫在main方法中就行了。詳細程式碼如下:#import <Foundation/Foun