
gdb對dwarf除錯資訊的解析和使用
Dwarf除錯資訊Consumer——gdb
1 引言
前面介紹過dwarf除錯資訊格式,內容包括有哪些型別的除錯資訊,除錯資訊的存放格式、某些除錯資訊的編碼方法等。本文的內容主要除錯資訊是怎樣被解析使用的除錯資訊作為編譯器為了實現原始碼級別除錯生成的內容,其主要的consumer自然是gdb。下面介紹gdb中如何使用dwarf除錯資訊。
本文是一個基於原始碼debug過程的分析文件,內容比較細,偏筆記性質的。總結抽象工作做得不多。所以其中的內容以及一些流程圖都會比較細節。下面提供一個總結概括性的ppt文件點選開啟連結。
2 除錯資訊回顧
在介紹gdb如何讀取dwarf除錯資訊之前,我們先回顧一下有哪些除錯資訊,除錯資訊在elf檔案中的位置。
在使用gcc編譯程式的時候,加上-g引數,那麼最後生成的目標檔案中會有除錯資訊,除錯資訊格式使用dwarf2格式。使用readelf工具加上-S引數,可以檢視目標檔案中有哪些除錯資訊section,示例如圖2-1所示。
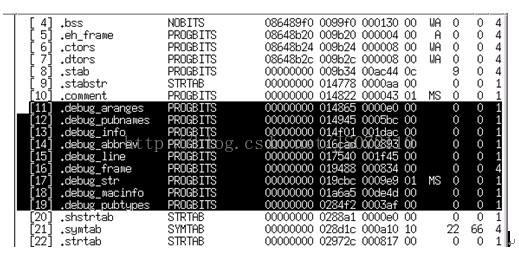
圖 2‑1 除錯資訊類別
可以看到.debug_*都是除錯資訊的section,每個section代表不同型別的除錯資訊,表2-1介紹不同型別除錯資訊。
表格2‑1除錯資訊型別說明
|
Section |
說明 |
|
.debug_info |
除錯資訊主要內容,各個DIE |
|
.debug_abbrev |
除錯資訊縮寫表,每個編譯單元對應一個縮寫表,每個縮寫表包含一系列的縮寫宣告,每個縮寫對應一個DIE |
|
.debug_line |
行號資訊 |
|
.debug_macinfo |
巨集資訊,編譯器-g3引數才會產生巨集資訊 |
|
.debug_aranges |
範圍表,每個編譯單元對應一個範圍範圍表,記錄了該編譯單元的某些ENTRY的text或者data的起始地址和長度,用於跨編譯單元的快速查詢 |
|
.debug_pubnames |
全域性符號查詢表,以編譯單元為單位,記錄了每個編譯單元的全域性符號的名稱 |
|
.debug_frame |
函式的堆疊資訊 |
|
.debug_str |
.debug_info中使用到的字串表 |
|
.debug_loc |
Location list |
3 Gdb使用除錯資訊
Gdb中實現原始碼級別除錯,主要實現名稱、位置的對映。而這些資訊在gdb內部通過symbol來記錄的。Symbols按照一定的關係組合在一起,形成symbol table。在gdb中有三類符號表。
表格3‑1 gdb中的符號表
|
說明 |
|
|
Minimal_symbol table |
該符號表通過分析elf檔案中的.symtab section得來,該section中記錄的是在elf檔案的連結過程中所必須的一些全域性的符號。該符號表在沒有-g引數的時候也會有。 |
|
Partial symboltable |
顧名思義,部分符號表,裡面記錄的是部分的符號的部分的資訊,在gdb讀入symbol file的時候會初步分析除錯資訊,建立這麼一張partial symbol table,它有兩個作用:1,滿足一部分的除錯需求;2,gdb可以根據partial symtab讀入full symtab。 |
|
Full symbol table |
完整符號表,裡面記錄的是完整的符號資訊,原始碼級別除錯實現的基礎。由於其資訊很多,佔的記憶體空間很大,所以gdb在一開始讀入symbol file的時候並不會產生這麼一個full symtab,而是在後續的除錯過程中,如果有需要完整符號表的地方,才會把該cu的full symtab讀入,這樣效率較高。 |
Gdb除錯主要依靠這三個符號表實現,minimal symtab比較簡單,也不屬於除錯資訊分析的範疇,本文不會對minimal symtab多加敘述。Partial symtab和full symtab的建立是根據除錯資訊完成的。下面gdb對除錯資訊的使用過程也是這麼兩張符號表的建立的過程。
3.1 Debug_info——PartialSymtab
3.1.1 Partial symtab簡介
在展開partial symbol相關的討論之前,我們先看看partialsymbol是什麼。
在gdb中使用structpartial_symbol,來描述一個partial symbol,其中包含的資訊如下表所示。
表格3‑2 struct partial_symbol
|
資料項 |
說明 |
|
Domain |
該symbol的型別:變數、函式、type、label等。 |
|
Address_class |
說明該符號的地址型別,即在什麼地方可以找到該符號:暫存器、arglist、local變數、typedef型別等。 |
|
Struct general_symbol_info |
所有型別符號的基礎資訊:name、value(是個union,取決於符號的型別)、在哪個section等。 |
Partial symbol以一定的規則組合在一起,形成partial symtab,gdb中以source file為單位,每個source file對應一個struct partial_symtab,一個objfile中的所有的partial_symtab組成一個連結串列。Partial symtab中只記錄該file中static型別的和global型別的一些符號。Struct partial_symtab的包含的資訊如下表所示。
表格3‑3 struct partial_symtab
|
資料項 |
說明 |
|
Struct partial_symtab *next |
Objfile的所有partial_symtab形成一個連結串列 |
|
Filename、fullname、dirname |
檔名、路徑等資訊 |
|
Struct objfile *objfile |
對應是哪個objfile |
|
Struct section_offsets |
Objfile的各個section的offset |
|
Textlow、 texthigh |
該file的地址範圍 |
|
Struct partial_symtab **dependencies |
該file依賴的檔案。依賴的意思是在讀入本file的symbol之前,要先將dependency的symbol先讀入。比如hello.c中include hello.h,那麼hello.h的dependency是hello.c,一個檔案可能有很多dependency。 |
|
Int global_offset, int n_gloabl_syms |
該檔案對應的全域性符號在objfile->global_psymbols中的偏移和個數 |
|
Int static_offst, int n_static_syms |
同上,不過是objfile->static_psymbols |
|
Struct symtab *symtab |
該file對應的full symtab |
|
Void(*read_symtab)(struct partial_symtab *) |
該函式指標用來根據該pst讀取full symtab |
|
Void *read_symtab_private |
上述函式建立full symtab需要用到的一些資料 |
|
Unsigned char readin |
標識該pst對應的symtab有沒有被讀入 |
3.1.2 Partial_symtab建立流程
本節介紹讀取除錯資訊,建立partialsymtab的流程。
gdb就可以根據此使用一些file_static和global的符號,進行一些基本的原始碼級別的除錯了。
該過程在gdb將symbol file新增進來的時候進行。不同的objfile格式,實現的函式不一樣。針對Elf檔案,具體呼叫函式elf_symfile_read()函式完成。該函式主要做了兩件事情:1,讀取objfile中.symtab、.dynsym(如果有的話)的符號,建立起minimal symtab;2,讀取分析除錯資訊,建立partial symtab。下面具體分析此流程,流程如下圖所示。
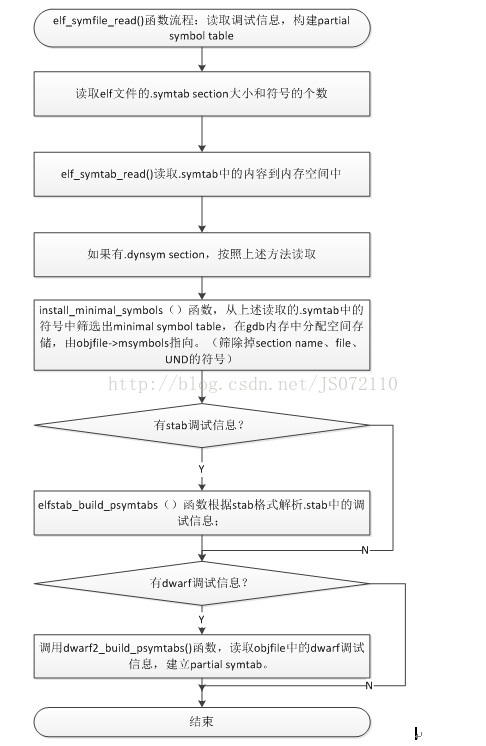
圖 3‑1 elf_symfile_read流程
從上述流程圖中我們看到會有stab除錯資訊的部分,這裡做一個說明。除錯資訊分為很多中有dwarf格式、stab格式等。除錯資訊在gcc將原始檔編譯成彙編檔案時會加入除錯資訊,而彙編器在將彙編檔案彙編成目標檔案。彙編器輸入的彙編檔案分為兩類:一類是gcc編譯生成的,裡面會含有除錯資訊;另一類是使用者hand-write彙編檔案,其中不帶除錯資訊。而彙編器也有除錯相關引數:-gstatbs和-gdwarf-2,分別用來為彙編檔案生成stabs格式和dwarf格式的除錯資訊。
本文的重點是介紹dwarf除錯資訊的讀取和解析,該過程在dwarf2_build_psymtabs()函式中完成,該函式的基本流程如圖2-3,
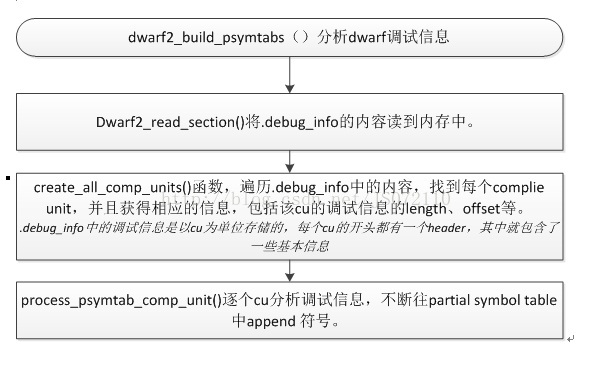
圖 3‑2 dwarf2_build_psymtabs函式流程
3.1.3 以cu為單位解析除錯資訊
Gdb中以cu為單位對除錯資訊進行分析,建立partial symtab,下面展開具體分析。
通過上述分析可知,首先會把.debug_info中的內容讀入到記憶體中,然後獲取每個cu的除錯資訊的header資訊,最後逐個cu來分析.debug_info中的內容,以append的方式建立起partial symbol table。對於dwarf除錯資訊分析的細節在函式process_psymtab_comp_unit()中,下面到這個函式中跟蹤分析
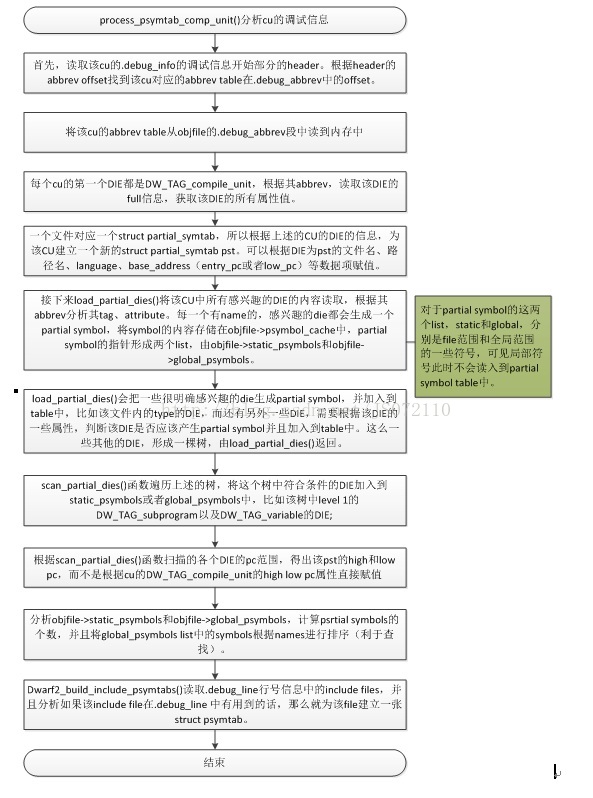
圖 3‑3 process_psymtab_comp_unit流程
通過對process_psymtab_comp_unit()的跟蹤分析,發現並不會把所有的DIE對應的符號都新增到partialsymbol table中。而是選取了一些file static和global的符號。流程分析中可以看出來,怎麼去讀取DIE中的資訊構建partial symbol的、選取哪些DIE、怎麼把symbol新增到list中,這個核心的過程都在load_partial_dies()函式中。接下來跟蹤分析這一過程,如圖所示。
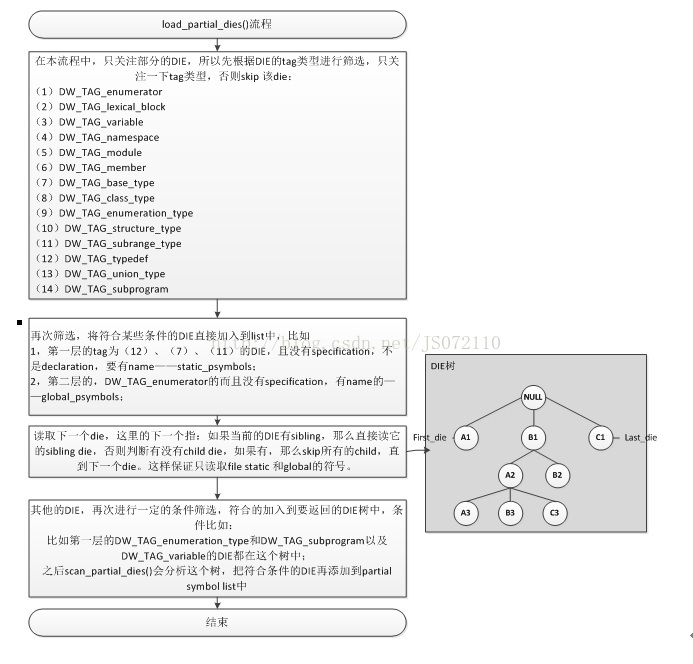
圖 3‑4 load_partial_dies()流程
至此,將該cu的main file的.debug_info中的所有DIE都分析完,選取了合適的加入到partial symbol table中。
但是我們知道,main file中可能include很多file,有header file,也可能是c file。Partial_symtab是一個sourcefile一個的。這裡,我們不是為所有的included file都建立一個partial_symtab,而是選取如果該cu行號資訊中,有用到該included file(該file中有函式定義),那麼就需要為該included file建立一個struct partial_symtab。。那該cu有哪些included files?這些included files有沒有在行號資訊中用到?這些通過怎樣分析得到呢?接下來就要分析.debug_line section的行號資訊了。process_psymtab_comp_unit()函式的最後一步呼叫dwarf2_build_include_psymtabs()完成這個工作。
在分析此函式之前,先簡單回顧一下.debug_line中行號資訊的格式。行號資訊是實現source-level debug的重要部分,完成目標地址和原始碼之間的對映關係。.debug_line中的行號資訊也是以cu為單位組織存放的,行號資訊理論上應該是一張很大的表,每個地址一個表項,記錄當前的行號、檔名、路徑名等資訊。但是為了儲存空間的問題,我們將行號資訊進行編碼,.debug_line中儲存的實際上是一系列的編碼過的opcode,每個cu的行號資訊叫做一個opcode program。每個cu的opcode program之前都會有一個header,這個header記錄了一些重要的資訊。比如,該cu的行號資訊的長度,header的長度,dwarf的版本,以及一些opcode相關的初始資訊。此處,我們需要關注的是header中還包含兩張表“The Directory Table”和“The File Name Table”。分別記錄了該編譯單元的include的路徑表和included file names表。
下面,跟蹤分析dwarf2_build_include_psymtabs()的具體流程,如所示。
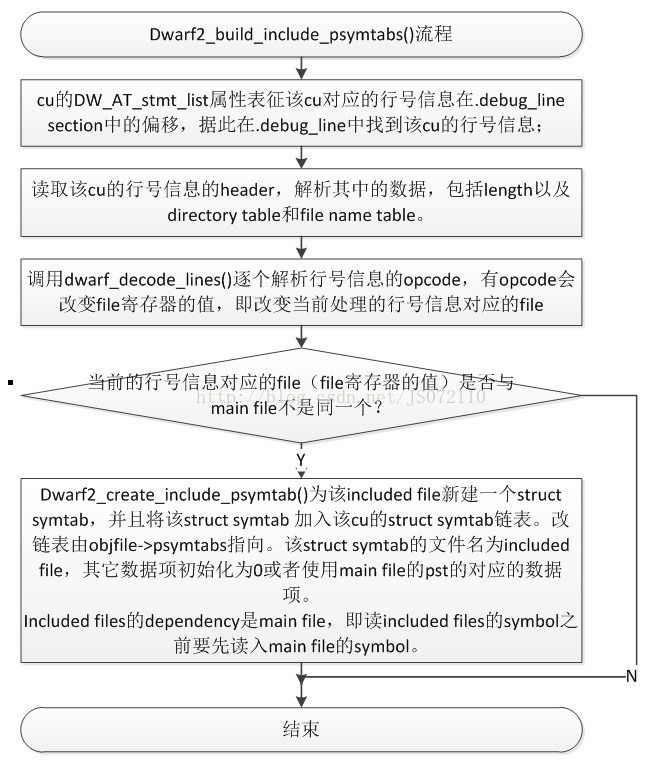
圖 3‑5 build include psymtab流程
每個source file一個structpartial_symtab,objfile中維護這麼一個鏈,included file依賴於其main file(dependency可以不止一個)。
至此,根據dwarf除錯資訊讀入partialsymbol table的工作已經完成,在接來下的除錯過程中如果需要更多的除錯資訊,可以根據當前的partial symbol table讀入full symbol table。可以根據對應struct partial_symtab的read_symtab()函式指標指向的函式完成full symtab的讀入,dwarf2_psymtab_to_symtab()函式。Read_symtab_private指標指向當讀入fullsymtab中需要的資料,struct dwarf2_per_cu_data。具體過程在3.2中介紹。
3.2 partial_symtab+dies——full_symtab
Gdb的source-leveldebugging的原理就是符號名、位置、值的處理,這些資訊都由symbol提供,gdb的除錯過程實質上是對符號的處理,而gdb中維護的symbol資訊是從除錯資訊中解析出來的。在3.1Section中介紹的partial symbol是提取部分除錯資訊獲得的,而除錯過程中需要更多的更完整的符號資訊時,我們就需要獲取full symbol table。Full symtab是partial symtab的擴充套件,符號的資訊更全,新增的符號也更多。同樣的,full symtab也是以source file為單位的。下面舉例介紹。
3.2.1 When is full_symtab needed?
Gdb除錯過程中最常見的操作是設定斷點,比如 “break main”,那麼我們需要知道字串main對應的symbol,進而知道該symbol的location,那麼我們就可以在這個位置placebreakpoint了。那麼我們現在已知的條件是:1,main字串、2,當前的pc、3,一堆待解析的除錯資訊,下面開始整個使用除錯資訊建立symbol的流程。

在本例中,分析的是dwarf和stabs除錯資訊格式混用的情況,彙編器對於使用者輸入的彙編檔案,使用stabs除錯資訊(至少有行號資訊)。第一個編譯單元是stabs的格式,而要查詢的main並不在該編譯單元中,所以需要global symbol查詢,然後根據psymtab_to_symtab(pst)讀入main符號所在cu的full symtab。
3.2.2 Full_symtab 建立流程
Psymtab_to_symtab(pst)是一個函式介面,根據不同格式的除錯資訊會呼叫不同的函式實現。Here,dwarf2_psymtab_to_symtab()函式來實現該過程。下面具體分析這個fullsymtab的讀入過程。
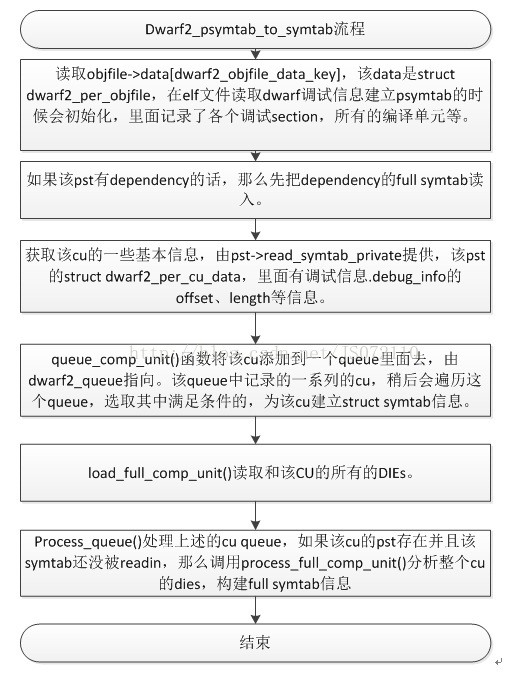
圖 3‑6 psymtab_to_symtab流程
簡要描述該流程就是:根據pst找到cu,讀取cu的所有的dies,根據讀入的dies構建該cu的full symtab。現在我們關注後兩步,怎麼讀取所有的dies,以及怎樣根據讀入的cu的dies構建好full symtab。
3.2.2.1 Full dies的讀入
首先,考察一下如何讀入這個cu的所有的dies,如圖所示
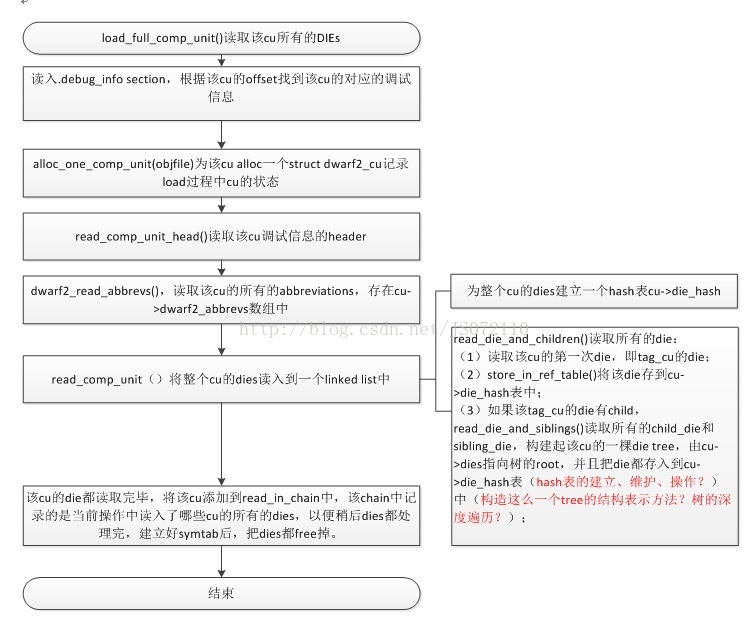
圖 3‑7 full除錯資訊dies的讀入
該部分的邏輯很簡答,就是根據die儲存的邏輯結構,把該cu的所有的die從.debug_info中讀出來,然後構建出這個一個die tree,儲存在記憶體中。
3.2.2.2 分析dies,構建full symtab
現在我們獲取了整個cu的所有的dies,那麼接下來分析這些除錯資訊,為該cu構建好full symtab。該部分工作由函式process_full_comp_unit()完成,該函式的流程如圖所示。
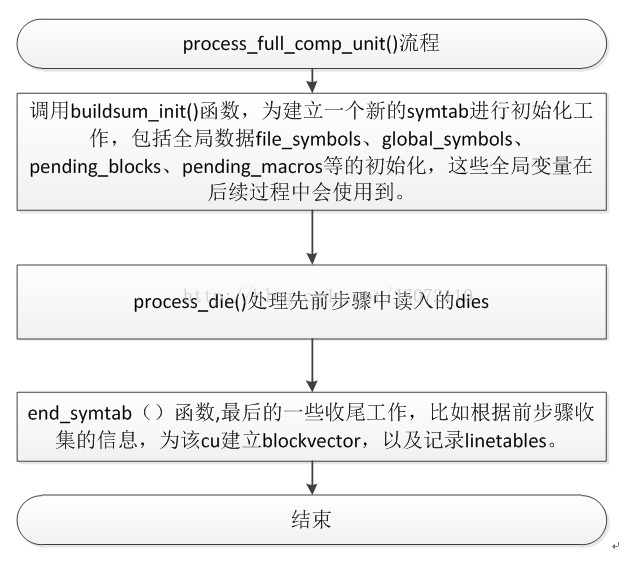
圖 3‑8分析dies流程
該流程包括三個步驟,一個是建立symtab之前的初始化工作,一個是對除錯資訊die的處理建立symtab,最後是一些善後工作。在初始化過程中看到的幾個全域性變數做一一說明,如下表所示。
表格3‑4 full_symtab構建相關全域性變數說明
|
變數名 |
說明 |
|
File_symbols |
是struct pending結構,用來記錄symbols Gdb中有三個list,分別是File_symbols、global_symbols、local_symbols,分別用來記錄file static、global和local的符號。在建立symtab的過程中cu->list_in_scope list指示當前符號要加入到哪個list中。 |
|
Global_symbols |
|
|
Local_symbols |
|
|
Pending_blocks |
該全域性變數指向一個連結串列,連結串列將整個cu的所有的scope block,通常一個函式對應一個block的連結串列。 |
|
Pending_macros |
全域性變數,struct marco_table記錄該cu的巨集資訊,包括用來儲存巨集資訊的空間、該cu的main_file,macro definition的table,以splay tree的方式儲存。該tree的節點的key是巨集的name,該tree的節點的value是該巨集的引數列表(如果是巨集函式的話)和該巨集的replacement。 |
該流程的核心是process_die(),該函式是一個switch函式體,針對不同TAG的die,採取不同的處理方式。先總體介紹一下對不同的die的處理函式。如下表所示。
表格3‑5 不同型別die的處理
|
Die型別 |
處理函式 |
說明 |
|
DW_TAG_compile_unit |
read_file_scope() |
該函式比較複雜,下面會具體介紹 |
|
DW_TAG_base_type,DW_TAG_subrange_type,DW_TAG_typedef |
new_symbol() |
是否要為該die生成一個symbol,並將該symbol新增到cu->list_in_scope list中。 |
|
DW_TAG_enumeration_type |
process_enumeration_scope() |
為enumerator的die建立symbol,並新增到相應的list中。 |
|
DW_TAG_subprogram DW_TAG_inlined_subroutine |
read_func_scope() |
●將該函式加入到cu的func list中,建立symbol,並且新增到相應的list中。 ●如果有DW_AT_frame_base,那麼解析該屬性,那麼呼叫dwarf2_symbol_mark_computed()函式,計算value,並且將該屬性的data、size等資訊放入struct symbol->aux_value中,並且初始化struct symbol->ops_computed=dwarf2_locexpr_funcs。 ●將cu->list_in_scope設定為local_symbols,將該函式的child_die()都呼叫process_die()進行處理,建立symbol,新增到cu->list_in_scope中去(對於inline 函式的abstract instance tree和concrete instance tree?)。 ●呼叫finish_block()函式,為該函式的建立一個block,並且將block新增到全域性變數pending_blocks指向的連結串列中。流程見圖 ●如果處理完了top-level function後,將cu->list_in_scope設定回file_symbols. |
|
DW_TAG_class_type,DW_TAG_interface_type,DW_TAG_structure_type,DW_TAG_union_type |
process_structure_scope() |
structure的member die不會被加入到symbol list中,為什麼? |
|
subroutine_type, set_type, array_type, pointer_type, ptr_to_member_type, reference_type, string_type |
無 |
process不進行任何操作,這些型別的DIE僅僅描述的是型別資訊,並不代表實際的object,所以不需要為他們建立一個symbol,並且新增到symbol list中。同樣的,也不需要處理它們的children。當process這些型別的variable的時候,可以根據需要在讀取variable的DW_AT_type的時候,呼叫read_type_die()函式讀取。 |
|
Default |
new_symbol() |
判斷是否要為該die生成一個symbol,並將該symbol新增到cu->list_in_scope list中。 |
下面是對DW_TAG_subprogramdie處理時,為function建立block的流程,該cu中的所有block會組成一個連結串列,由pending_blocks全域性變數指
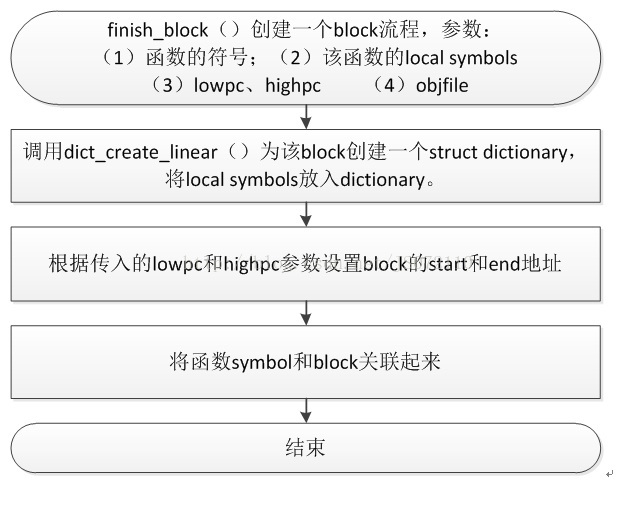
圖 3‑9 為function建立block
Process_die()函式用來處理引數指定的die及其child,首先處理的是tag_cu的die,然而該cu的所有的die都是tag_cu的die的children。所以在過程中會遞迴呼叫process_die()函式把該cu的其它的dies也處理掉。那麼我們檢視下對tag_cudie的處理函式read_file_scope()函式的流程。
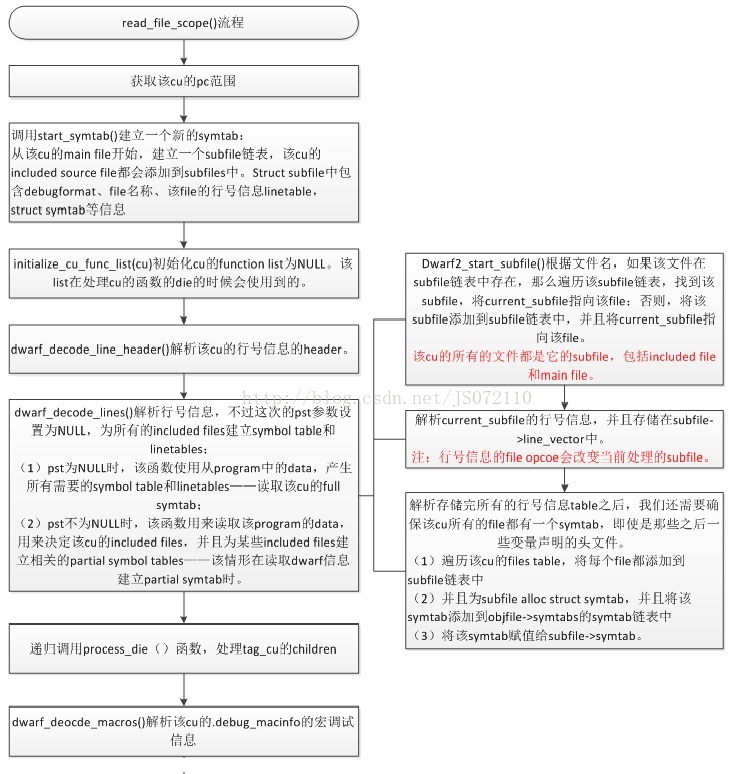
圖 3‑10 read_file_scope()流程
可以看到process_die()函式流程走完,該cu的所有的die都會被處理,這時候相應的symbol都已經建立並且記錄下來了,行號資訊也解析讀取了,巨集資訊也相應的解析了。至此除錯資訊的分析工作大部分已經完成。
上述流程圖中把symbols的建立以及行號資訊的分析詳細介紹了,下面單獨介紹一下巨集資訊的解析。巨集資訊放在.debug_macinfo section中,也是以cu為單位存放的,但是隻有一系列的entry,沒有為每個cu建立一個巨集資訊的header,在DW_TAG_complile_unit中會有DW_AT_macro_info屬性表徵該cu的巨集資訊在.debug_macinfo中的位元組偏移。巨集資訊的格式很簡單。
在開始分析巨集資訊的解析流程之前,我們先了解下gdb中幾個在巨集資訊解析中重要的資料結構,如下表所示。
表格3‑6 巨集資訊相關資料結構
|
資料結構 |
說明 |
|
struct macro_table |
該資料結構對應一個cu,用來描述該cu的macro_table,裡面包含cu的檔名,巨集的儲存樹等。 |
|
struct macro_definition |
一個巨集對應一個該資料結構,包括該巨集的name以及引數和replacement。 |
|
struct macro_source_file |
在巨集資訊描述中用來表徵一個檔案,包括main_file和included_file。包括檔名、對應的macro_table等資訊。特別說明下,該資料結構會表徵當前檔案的parent_file,以及在parent_file中被include的行號位置,以及該parent_file的下一個子file,即sibling。Plus,還會記錄該file的子files。 因為巨集資訊中,file的include的關係也是一個樹形關係。這樣使用該資料結構能夠很好的描述這樣一個關係。 |
資料結構背景介紹完成之後,下面開始巨集資訊的分析流程,如下圖所示,
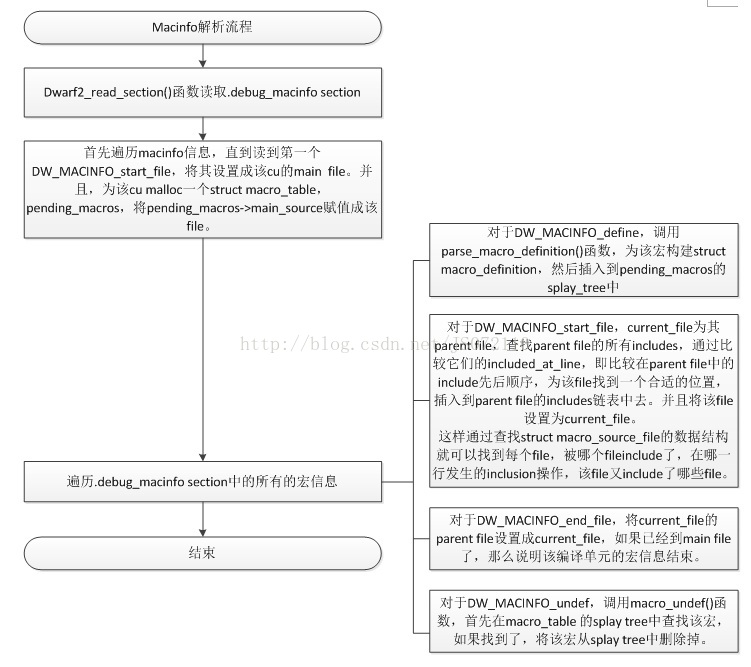
圖 3‑11 巨集資訊解析流程圖
巨集資訊的entry中無非就是四類操作,檔案的開始,檔案的結束,巨集的define,巨集的undefine。該cu的巨集資訊解析完成後,我們最後得到的是一個macro_table,裡面包含了巨集的splay tree,file的inclusion tree。該macro_table由全域性變數pending_macros指向。
Prcess_die()的流程至此結束,symtab建立的流程只剩下最後一步,symtab_end()來完成最後的一些資訊收集和掃尾工作。如下圖所示,

圖 3‑12 end_symtab()流程圖
至此該cu的full symtab就已經完全建立,為對該cu的除錯提供了完整的資訊。
相關推薦
gdb對dwarf除錯資訊的解析和使用
Dwarf除錯資訊Consumer——gdb 1 引言 前面介紹過dwarf除錯資訊格式,內容包括有哪些型別的除錯資訊,除錯資訊的存放格式、某些除錯資訊的編碼方法等。本文的內容主要除錯資訊是怎樣被解析使用的除錯資訊作為編譯器為了實現原始碼級別除錯生成的內容,其主
dwarf除錯資訊格式入門
https://www.cnblogs.com/zqingnn/archive/2011/01/05/1926384.html 一個程式的完成過程一般是編碼、編譯、執行的過程,當然這是一個理想的過程,所有的開發幾乎都不可能是一帆風順的,總會有些意想不到的錯誤,這時便需要除錯,良好的偵錯程式應該每
【手擼一個ORM】第六步、對象表達式解析和Select表達式解析
member ++ access over def 大於 () 表達式 cti 對象表達式用於解析 Expression<Func<Student, object>> expr = s => new { s.Id, s.Name } 這種形式的
除錯技巧:封裝printf列印除錯資訊和巨集定義開關
/* #define DEBUG */ #ifdef DEBUG #define DEBUG_ERR(format, ...) \ do{ \ printf("\r\n"); \ printf("FILE: "__FILE__", LINE: %
bochs和gdb聯合使用除錯程式_開始
0. 使用編譯gdb除錯支援的bochs 1. bochs的配置檔案新增: gdbstub: enabled=1, port=1234, text_base=0, data_base=0, bss_base=0;
什麼是閉包?關於閉包的工作原理、優缺點、使用場景和對頁面的影響解析
閉包(closure)是javascript的一大難點,也是它的特色。很多高階應用都要依靠閉包來實現。 1、變數作用域 要理解閉包,首先要理解javascript的特殊的變數作用域。 變數的作用域無非就兩種:全域性變數和區域性變數。 javascript語言的
探索 DWARF 除錯格式資訊
https://www.ibm.com/developerworks/cn/aix/library/au-dwarf-debug-format/index.html 簡介 DWARF(使用有屬性的記錄格式進行除錯 )是許多編譯程式和除錯程式所使用的一種除錯檔案格式,可以支援原始碼級的除錯。它
gdb除錯多程序和多執行緒命令
原文地址:http://blog.csdn.net/pbymw8iwm/article/details/7876797 1. 預設設定下,在除錯多程序程式時GDB只會除錯主程序。但是GDB(>V7.0)支援多程序的分別以及同時除錯,換句話說,GDB可以同時除錯多個程式
在gradle使用日誌資訊(如何使用日誌顯示堆疊和除錯資訊)
總問題:如何使用日誌顯示堆疊和除錯資訊 問題關鍵字:除錯資訊列印,堆疊列印 問題背景: 列印日誌 日誌的級別 操作:列印日誌 列印日誌 gradle -i task (i為日誌選項開關) 所有的日誌選項開關為 ( 這裡一般使用gradle -d 列印所
ReflectUitls類的編寫和對反射機制的解析
package com.mengdd.reflect; import java.lang.reflect.Constructor; import java.lang.reflect.Field; import java.lang.reflect.Member; import java.lang
Linux除錯工具strace和gdb常用命令小結-轉
最近在Linux環境下做C語言專案,由於是在一個原有專案基礎之上進行二次開發,而且專案工程龐大複雜,出現了不少問題,其中遇到最多、花費時間最長的問題就是著名的“段錯誤”(Segmentation Fault)。藉此機會系統學習了一下,這裡對Linux環境下的段錯誤做個小結,方便以後同類問題的排查與解決。 1
DOM4J對SOAP的返回資訊解析
用DOM4J的XML解析式拿不到節點的。所以網上利用DOM4J提供的VisitorSupport解決此問題。不廢話,直接看程式碼: package com.starhub.util; import org.dom4j.Document; import org.dom4j.
tomcat7和tomcat8 對 資源路徑的解析
在jsp中 我們需要引入靜態檔案 使用下面的方式 <%@include="/static/path.html"%> 在META-INF 的context.xml 檔案中配置別名 &
使用Item Loaders對Item資料進行提取和解析(整理)
1.當建立item物件(item=JobboleItem())的時候, 會去Item.py檔案中初始化對應的input/output_processor處理器2.當item中的處理器初始化完成, 回到bole.py爬蟲檔案中, 建立item_loader物件3.item_lo
Spring對註解(Annotation)處理原始碼分析2——解析和注入註解配置的資源
1.類內部的註解,如:@Autowire、@Value、@Required、@Resource以及EJB和WebSerivce相關的註解,是容器對Bean物件例項化和依賴注入時,通過容器中註冊的Bean後置處理器處理這些註解的。 2.Spring中處理註解的Bean後置處
gdb沒有除錯資訊
which has no line number information. No symbol “i” in current context. 這些提示資訊都是沒有除錯符號。 中文站點
GDB除錯資訊——No symbol "xxx" in current context
在使用GDB除錯C++時遇到過一些很奇怪的問題: 1.GDB斷點除錯可執行檔案或者Dumped Core檔案時,無法顯示原始碼 2.GDB可以顯示原始碼,但單步除錯或者列印區域性資訊時錯誤,顯示No symbol “xxx” in curren
gdb 除錯基礎操作和在qtcreator中使用gdb除錯
最近使用多執行緒,老是出現未知錯誤,比如程式死鎖,或者執行緒突然掛掉,由於是多執行緒程式設計,單純使用cout找不到出錯點,只有學好gdb除錯才能解決問題. 1.gdb除錯基礎操作 學習的知識點為新建Debug工程,進入gdb除錯,載入除錯程式,
談在Debug和Release模式下輸出除錯資訊 .
在除錯程式時,有時候設定斷點單步執行並不能查出問題的所在,比如程式可能在執行一段時間後死掉了,或者對於Release版本執行不正常等等原因吧,這時需要通過設定一些輸出資訊,來幫助定位錯誤發生的位置,這點非常有用。根據個人程式設計習慣,我通常都會在程式編寫過程中適當地加入一些輸出資訊。 1、輸出巨
對Vue中的MVVM原理解析和實現
對Vue中的MVVM原理解析和實現 首先你對Vue需要有一定的瞭解,知道MVVM。這樣才能更有助於你順利的完成下面原理的閱讀學習和編寫 下面由我阿巴阿巴的詳細走一遍Vue中MVVM原理的實現,這篇文章大家可以學習到: 1.Vue資料雙向繫結核心程式碼模組以及實現原理 2.訂閱者-釋出者模式是如