
Spark流程式設計指引(五)-----------------------------DStreams上的轉換操作
與RDDs類似,轉換操作允許對來自輸入DStreams的資料進行修改。DStreams支援許多在通常Spark RDD上的轉換操作。下面是一些常見的:
| 轉換 | 含義 |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a functionfunc. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on whichfunc |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream andotherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a functionfunc (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function.Note: By default, this uses Spark's default number of parallel tasks (2 for local
mode, and in cluster mode the number is determined by the config propertyspark.default.parallelism) to do the grouping. You can pass an optionalnumTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
我們現在看一些值得討論的轉換操作:
UpdateStateByKey操作
UpdateStateByKey操作允許你保持任意的狀態,同時用持續不斷地新資訊更新它。為了使用它,你需要做2步:
1.定義狀態--狀態可以是任意資料型別。
2.定義狀態更新函式--定義一個函式,如何用先前的狀態和輸入流中的新值來更新狀態。
我們現在用一個例子來說明。你想要保持一個來自文字資料流的每個單詞的執行計數。這裡,執行計數就是狀態,它是一個整型。我這樣定義更新函式:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}val runningCounts = pairs.updateStateByKey[Int](updateFunction _)這個函式將在每個單詞上呼叫,其中newValues引數是一個包含1的序列(來自(word,1)鍵值對),runningCount是前一次的計數。關於這個例子的Scala全部程式碼,可以檢視StatefulNetworkWordCount.scala.
注意:使用updateStateByKey需要配置一個checkpoint目錄。
Transform操作
Transform操作允許任意RDD-to-RDD型別的函式被應用在一個DStream上。通過它可以在DStream上使用任何沒有在DStream API中暴露的任意RDD操作。比如,將DStream的每批資料加入另一個數據集的功能在DStream API中沒有直接暴躁。但是,我們可以很容易地通過transform做到這一點。Transform使很多強大的功能變為可能。再比如,你想實時地清理加入到輸入DStream中的垃圾郵件資訊,並過濾它們。val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
})事實上,你還可以在transform方法中應用機器學習和圖計算演算法。
Window操作
Spark流還提供了視窗計算操作,它允許你在一個滑動視窗的資料應用轉換操作。如下圖所示:
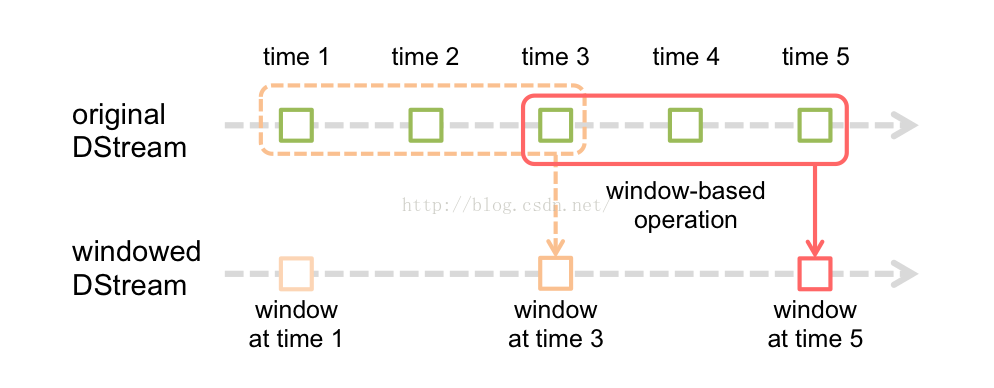
如上圖所示 ,視窗在源DStream上滑動的每個時間點,在視窗中的RDDs被組合和計算用來產生出基於Window Dstream的RDDs.在這個例子中,操作被應用在最近三個時間單元中的資料,被劃分成了2個時間段。每個視窗操作需要指定兩個引數:
1.視窗長度:視窗的持續時間(圖中是3個時間單元)
2.滑動區間:視窗操作應用的區間(圖中是2個區間)
這兩個引數必須是源DStream批次間隔的倍數(圖中的批次間隔為1)
下面用一個例子來描述。我們仍拿前面章節中計算單詞數的例子舉例。我們現在要統計過去30s內每個單詞的個數,每10s統計一次。我們需要在過去30s的(word,1)的DStream變數pairs上使用reduceByKey操作.要做到這些,需要使用操作reduceByKeyAndWindow
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))下面是一些常用的Window操作,所有操作都用到了上面所說的兩個引數:
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval usingfunc. The function should be associative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce functionfunc over batches in a sliding window.
Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config propertyspark.default.parallelism) to do the grouping. You can pass an optionalnumTasks
argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength,slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enter the sliding window,
and "inverse reducing" the old data that leave the window. An example would be that of "adding" and "subtracting" counts of keys as the window slides. However, it is applicable to only "invertible reduce functions", that is, those reduce functions which have
a corresponding "inverse reduce" function (taken as parameter invFunc. Like inreduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that [checkpointing](#checkpointing) must be enabled for
using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like inreduceByKeyAndWindow, the number of reduce tasks is configurable through an optional
argument. |
Join操作
最後,我們關注一下怎樣容易地執行不同型別的Join操作。
Stream-stream joins
Stream可以很容易地加入到其它Stream中:
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)leftOuterJoin,rightOuterJoin,
fullOuterJoin。
更進一步,將流的每個視窗聯合通常更加有用。這也很簡單:
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)Stream-dataset joins
在前面DStream.transform中已經介紹過。這裡是另外一個例子:
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }相關推薦
Spark流程式設計指引(五)-----------------------------DStreams上的轉換操作
與RDDs類似,轉換操作允許對來自輸入DStreams的資料進行修改。DStreams支援許多在通常Spark RDD上的轉換操作。下面是一些常見的: 轉換 含義 map(func) Return a new DStream by passing each element
Spark流程式設計指引(四)---------------------------DStreams基本模型,輸入DStreams和接收者
離散流(DStreams) 離散流或者稱為DStreams是Spark流程式設計提供的基本抽象。它代表了持續的資料流,從一個數據源接收到的資料流或者是在一個輸入流上應用轉變操作處理後的資料流。 在內部實現上,DStream代表了一系列連續的RDDs.RDDs是Spark對不
Java程式設計思想(五)—— 初始化與清理
一、用構造器確保初始化 C++引入了構造器的概念,這是一個在建立物件時被自動呼叫的特殊方法。Java中也採用了構造器,並額外提供了“垃圾回收器”,對於不再使用的記憶體資源,垃圾回收器會自動將其釋放。 &n
Java程式設計思想(五)第18章-Java IO系統
目錄: 1 File類 File(檔案)類這個名字有一定的誤導性;我們可能會認為它指代的是檔案,實際上卻並非如此。它既能代表一個特定檔案的名稱,又能代表一個目錄下的一組檔案的名稱。實際上,FilePath(檔案路徑)對這個類來說是更好的名字。 如果它指的
Java網路程式設計入門(五)之TCP程式設計——複用Socket連線
如何複用Socket連線? 在前面的示例中,客戶端中建立了一次連線,只發送一次資料就關閉了,這就相當於撥打電話時,電話打通了只對話一次就關閉了,其實更加常用的應該是撥通一次電話以後多次對話,這就是複用客戶端連線。 那 麼如何實現建立一次連線,進行多次資料交換呢?其實很簡單
資料結構程式設計回顧(五)交通諮詢系統設計
題目五:交通諮詢系統設計 設計要求:設計一個諮詢交通系統,能讓旅客諮詢從任一個 城市到另一個城市之間的最短路徑(里程)、最低費用或者 最少時間等問題。對於不同的諮詢要求,可以輸入城市間路 程、所需時間或者所需費用。 設計分3 個部分: 1、 建立交通網路圖的儲存結構; 2、 解決單源最短路徑問題;
網路程式設計 筆記(五) 回聲伺服器/客戶端
準備工作 1、執行平臺Mac 2、編輯器Xcode 3、語言C 建立工程 1、Xcode建立新的工程 - File->new->Project->os X->Command Line Tool, 後面就是設定工程名了
《Python高階程式設計》(五)元類
元類 定義 類與物件 使用type建立類 編寫元類 type建立類和class建立類的比較 對元類理解 使用元類 何時使用元類 定義 物件例項化原理:物件例項化過程中會呼叫_
音視訊開發——音訊流解碼播放(五)
iOS音視訊開發相關文章: 在iOS中,Core Audio提供的一套軟體介面來處理音訊,支援錄音、播放、聲音效果、格式轉換、檔案流解析等。現在常用的場景是網路傳輸過來的音訊流播放,在Core Audio中,可以使用Audio Queue或者OpenAL實現。
Spark流程式設計指引(三)-------------------------------------初始化StreamingContext
基本概念 接下來,我們在上一節例子的基礎上,來闡述Spark Streaming的基本知識。 連結 和Spark類似,Spark Streaming也包含在maven的中央倉庫中。為了寫基於Spark Streaming的程式,你需要為你的SBT或Maven工程分別新增以
Spark Streaming程式設計指南(三)
DStreams轉換(Transformation) 和RDD類似,轉換中允許輸入DStream中的資料被修改。DStream支援很多Spark RDD上的轉換。常用的轉換如下。 轉換 含義 map(func) 將源DS
Linux下的socket程式設計實踐(五)設定套接字I/O超時的方案
(一)使用alarm 函式設定超時 #include <unistd.h> unsigned int
c# 程式設計學習(五)
使用複合賦值和迴圈語句 使用 while 語句,可在條件為 true 的前提下重複執行一
Spark SQL原始碼解析(五)SparkPlan準備和執行階段
Spark SQL原理解析前言: [Spark SQL原始碼剖析(一)SQL解析框架Catalyst流程概述](https://www.cnblogs.com/listenfwind/p/12724381.html) [Spark SQL原始碼解析(二)Antlr4解析Sql並生成樹](https://w
Python入門篇(五)之文件操作和字符編碼
Python 文件操作和字符編碼 1、文件操作 1、文件操作流程: 打開文件,得到文件句柄並賦值給一個變量===> file = open("yesterday",encoding="utf-8") 通過句柄對文件進行操作 關閉文件 ==> file.close() 1.2、打開文件的
TestNG(五)常用元素的操作
新聞 輸入框 package ava 最好 div https set 標簽 原則先定位元素,然後對元素進行操作。 一、點擊操作 //用name方法查找元素WebElement keyfind = driver.findElement(By.name("tj_trnews"
輕量ORM-SqlRepoEx (五) 存儲過程操作
字串 RoCE and ade new read value 查詢 idata .Net平臺下兼容.NET Standard 2.0,一個實現以Lambda表達式轉轉換標準SQL語句,使用強類型操作數據的輕量級ORM工具,在減少魔法字串同時,通過靈活的Lambda表達式組
elasticsearch(五)java 使用批量操作bulk及注意事項
1,BulkRequest物件可以用來在一次請求中,執行多個索引、更新或刪除操作 且允許在一次請求中進行不同的操作,即一次請求中索引、更新、刪除操作可以同時存在 BulkRequest bulkRequest = new BulkRequest(); bulk
selenium模組(五):元素互動操作
點選、清空 from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By #按照什麼方式查詢,By.ID,By.
Spring Boot 最佳實踐(五)Spring Data JPA 操作 MySQL 8
一、Spring Data JPA 介紹 JPA(Java Persistence API)Java持久化API,是 Java 持久化的標準規範,Hibernate是持久化規範的技術實現,而Spring Data JPA是在 Hibernate 基礎上封裝的一款框架