
ElasticSearch 中文同義詞實現
1:elasticserach.yml 最後一行新增如下內容(該檔案位於elasticsearch-x.x.x/config目錄下):
index.analysis.analyzer.default.type: ik
2:在elasticsearch-x.x.x/config目錄下新建同義詞檔案synonyms.txt。
其中,synonyms.txt 編碼格式為’utf-8’,內容建議為空。
3:建立索引
curl -XPUT localhost:9200/test -d'
{
"settings": {
"index": {
"analysis": {
"analyzer" 4:建立對映
curl -X PUT localhost:9200/test/haizhi/_mapping -d '{
"haizhi": {
"properties": {
"title": {
"include_in_all": true,
"analyzer": "jt_cn",
"term_vector": "with_positions_offsets",
"boost": 8,
"store": true,
"type": "string"
}
}
}
}'5:插入資料
curl -XPUT localhost:9200/test/haizhi/1 -d '{
"title": "番茄"
}'
curl -XPUT localhost:9200/test/haizhi/2 -d '{
"title": "西紅柿"
}'
curl -XPUT localhost:9200/test/haizhi/3 -d '{
"title": "我是西紅柿"
}'
curl -XPUT localhost:9200/test/haizhi/4 -d '{
"title": "我是番茄"
}'
curl -XPUT localhost:9200/test/haizhi/5 -d '{
"title": "土豆"
}'
curl -XPUT localhost:9200/test/haizhi/6 -d '{
"title": "aa"
}'6:查詢1
curl -XPOST 'localhost:9200/test/haizhi/_search?pretty' -d '
{
"query": {
"match_phrase": {
"title": {
"query": "西紅柿",
"analyzer": "jt_cn"
}
}
},
"highlight": {
"pre_tags": [
"<tag1>",
"<tag2>"
],
"post_tags": [
"</tag1>",
"</tag2>"
],
"fields": {
"title": {}
}
}
}'- 結果如下

7:查詢2
我們知道“西紅柿”和“番茄”是同義詞,我們在同義詞詞典(synonyms.txt)中新增如下內容,並重啟ES,再用第6步的查詢。
#Example:
西紅柿, 番茄- 結果如下,成功匹配同義詞

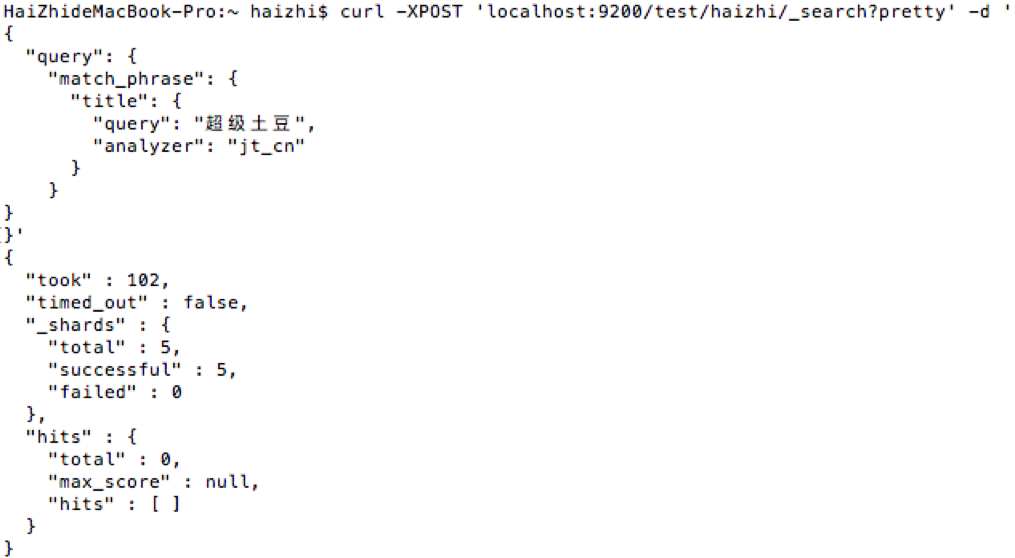
8:查詢3
修改同義詞詞典(synonyms.txt)為如下內容,重啟ES。
#Example:
西紅柿, 番茄
超級土豆, 土豆查詢如下:
curl -XPOST 'localhost:9200/test/haizhi/_search?pretty' -d '
{
"query": {
"match_phrase": {
"title": {
"query": "超級土豆",
"analyzer": "jt_cn"
}
}
}
}'- 結果如下,查不到結果
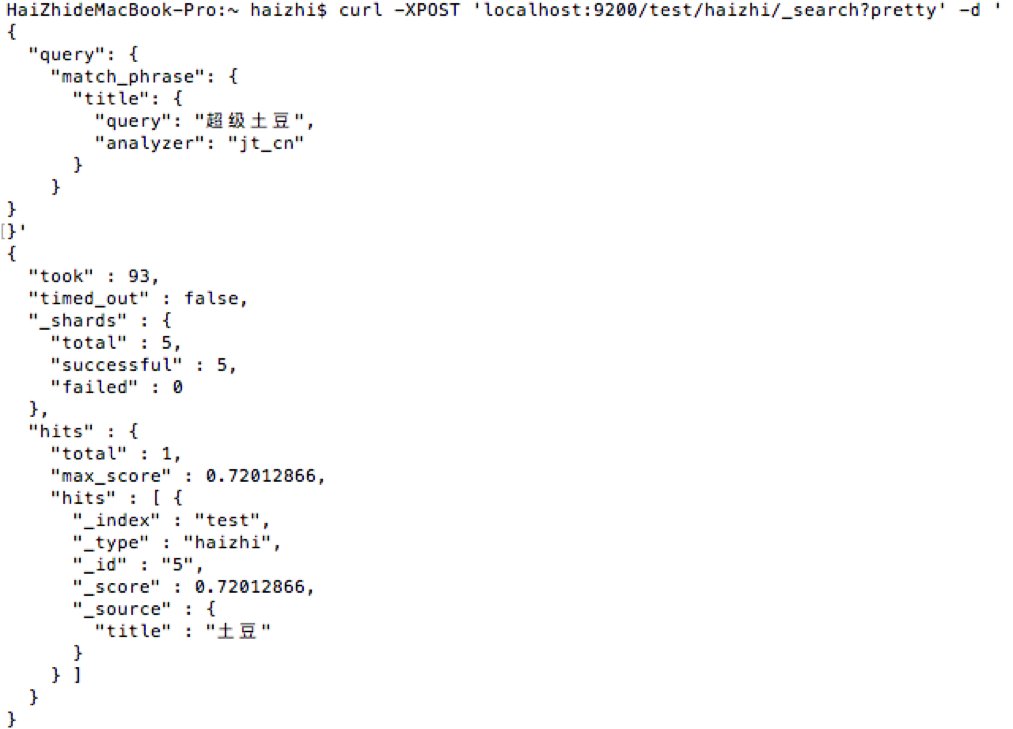
9:查詢4
在{plugins}/elasticsearch-analysis-ik-*/config/custom/mydict.dic詞典中新加“超級土豆”一詞,並且重啟ES。
- 結果如下,成功用“超級土豆”搜尋到“土豆”一詞
10:小結
- 同義詞字典或是IK使用者自定義詞典更新,必須每次重啟elasticsearch才有效。
- 同義詞詞對是必須能被完成切分的詞語。
比如在synonyms.txt 檔案中增加同義詞對: ‘超級土豆’ – ‘土豆’ 。但在實際的搜尋中用“超級土豆”是搜不到“土豆”的。因為“超級土豆”會被切分為多個詞語。必須在{plugins}/elasticsearch-analysis-ik-*/config/custom/mydict.dic詞典中新加“超級土豆”一詞,才能用“超級土豆”一詞搜出“土豆”。
相關推薦
ElasticSearch 中文同義詞實現
1:elasticserach.yml 最後一行新增如下內容(該檔案位於elasticsearch-x.x.x/config目錄下): index.analysis.analyzer.default.type: ik 2:在elasticsearch-x
Lucene實現自定義中文同義詞分詞器
----------------------------------------------------------lucene的分詞_中文分詞介紹---------------------------------------------------------- Paod
lucene+ikanalyzer實現中文同義詞搜尋
lucene實現索引的建立與檢索;ikanalyzer實現對中文的分詞;光到這裡已經能夠實現中文的檢索了,但是光這樣還不夠,很多專案中的檢索,應該還能夠對同義詞進行處理,比如索引庫中有“計算機”,“電腦”這樣的詞條,搜尋“筆記本”應該也能把“計算機”,“電腦”這樣的詞條匹配
elasticsearch中文分詞+全文搜索
分詞器 。。 中文 search img 版本 下載地址 源碼包 -i 安裝ik中文分詞器 我在百度上搜索了下,大多介紹的都是用maven打包下載下來的源碼,這種方法也行,但是不夠方便,為什麽這麽說? 首先需要安裝maven吧?其次需要下載源碼吧?最後需要打包吧? 我
Elasticsearch 配置同義詞
一起 索引 pan provide path 轉化 eabi token pos 配置近義詞 近義詞組件已經是elasticsearch自帶的了,所以不需要額外安裝插件,但是想要讓近義詞和IK一起使用,就需要配置自己的分析器了。 首先創建近義詞文檔 在co
Elasticsearch+logstash+kibana實現日誌分析(實驗)
elasticsearch logstash kibana Elasticsearch+logstash+kibana實現日誌分析(實驗)一、前言 Elastic Stack(舊稱ELK Stack),是一種能夠從任意數據源抽取數據,並實時對數據進行搜索、分析和可視化展現的數據分析框架。(h
elasticsearch 中文分詞(elasticsearch-analysis-ik)安裝
star 最好 好玩的 failed dex source 在線 3.0 github elasticsearch 中文分詞(elasticsearch-analysis-ik)安裝 下載最新的發布版本 https://github.com/medcl/elasticsea
單行中文如何實現兩端對齊
text-align: justify可以實現英文的兩端對齊,但是它有兩個缺陷: 只對多行文字有效,並且多行文字的最後一行無效 IE瀏覽器下只對英文有效 對於問題1,可以用 text-align-last: justify 解決,我自己測試在I
第9講 9. ElasticSearch中文分詞smartcn
1,安裝中文外掛,參考文件:http://www.cruiseloveashley.com/news/?7917.html2,測試分詞效果,/_analyze/路徑, analyzer為key,smartcn為value,見參考文件:http://www.cruiseloveashley.com/n
Elasticsearch 中文分詞器IK
1、安裝說明 https://github.com/medcl/elasticsearch-analysis-ik 2、release版本 https://github.com/medcl/elasticsearch-analysis-ik/releases 3、安裝外掛 bin/elasti
elasticsearch使用bulk實現批量操作
本篇文章提供ES原生批量操作語法及使用bulk批量操作文件。文章依舊提供語法,具體實現大家根據語法,在對應處進行替換即可 一、原生批量獲取文件 1、獲取指定文件值(1) 語法: GET /_mget { “doc
elasticsearch 中文分詞器 elasticsearch-analysis-ik
一、IK分詞器安裝 2、在 elasticsearch-5.4.0/plugins/ 目錄下新建名為 ik 的資料夾,拷貝elasticsearch-analysis-ik-5.4.0目錄下所有的檔案到 elasticsearch-5.4.0/plugins/ik/ 目
Elasticsearch中文分詞研究
一、ES分析器簡介ES是一個實時搜尋與資料分析引擎,為了完成搜尋功能,必須對原始資料進行分析、拆解,以建立索引,從而實現搜尋功能;ES對資料分析、拆解過程如下:首先,將一塊文字分成適合於倒排索引的獨立的 詞條;之後,將這些詞條統一化為標準格式以提高它們的“可搜尋性”,或者 r
Elasticsearch 6.5 實現冷熱資料分離
一、安裝Elasticsearch叢集web管理工具Cerebro 1.1 下載 https://github.com/lmenezes/cerebro/releases [[email protected] software]# wget https://g
大資料求索(10): 解決ElasticSearch中文搜尋無結果------ik分詞器的安裝與使用
大資料求索(10): 解決ElasticSearch中文搜尋無結果-----IK中文分詞器的安裝與使用 問題所在 在中文情況下,ES預設分詞器會將漢字切分為一個一個的漢字,所以當搜尋詞語的時候,會發現無法找到結果。 解決辦法 有很多其他的分詞器外掛可以替代,這裡使用最常用
義大利語翻譯成中文怎樣實現
隨著現在語言專業的人數不斷增多,生活中關於語言翻譯的問題也不斷頻繁的出現在大家的視野中,那如果我們碰到了義大利語翻譯的問題我們應該怎樣實現對其的翻譯呢?下面小編就來給大家分享一下吧。步驟一:我們要先將需要進行翻譯的義大利短句在電腦上準備好,這樣在進行翻譯的時候,就可以直接進行使用了。步驟二:準備好需要進行翻譯
意大利語翻譯成中文怎樣實現
sha .com size 按鈕 電腦 小夥伴 ref process color 隨著現在語言專業的人數不斷增多,生活中關於語言翻譯的問題也不斷頻繁的出現在大家的視野中,那如果我們碰到了意大利語翻譯的問題我們應該怎樣實現對其的翻譯呢?下面小編就來給大家分享一下吧。步驟一:
大資料學習[15]:elasticsearch之同義詞
[ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "來自",
Elasticsearch IK 同義詞
同義詞配置 step 1 elasticserach.yml 最後一行新增: index.analysis.analyzer.default.type: ik step 2 在elas
ElasticSearch基於Java實現員工資訊的增刪改查
員工資訊 姓名 年齡 職位 國家 入職日期 薪水 1、maven依賴 org.elasticsearch.client transport 5.2.2 org.apache.logging.log4j log4j-api 2.7 org.apache.logging.log4j lo