
【筆記】Python字元編碼
一、字元編碼(文字的編碼指的是字元如何使用位元組來表示組織方式)
1、ASCII
英文字母大小寫,特殊字元,數字,早期ASCII 字元編碼規定使用單位元組中低位的7個位元去編碼所有的字元(\x80以下),ASCII 擴充字符集利用了後128個字元。
2、Unicode(”\u”表示Unicode編碼)
Unicode 標準使用十六進位制數字表示(UCS-2和UCS-4),UCS-4用4個位元組(實際上只用了31位,最高位必須為0)。侷限性:對於一個位元組可以表示的字元用2個位元組浪費空間。
3、UTF-8/UTF-16
UTF-8作為 Unicode 一種實現方式,變長的字元編碼,一個字元最少用8位去表示(UTF-16同理)。
英文字元–1位元組,歐文字元–2位元組,中文–3位元組,生僻漢字4-6位元組
4、GBK/GB2312/ANSI
GB2312中國人設計的雙位元組編碼,後在GB2312的基礎上建立了GBK 編碼,GBK 收錄了27484個漢字相容 ASCII 編碼,對於英文字元用1個位元組來表示,漢字用兩個位元組來標識。
不同的國家和地區制定了不同的標準,由此產生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的編碼標準。這些使用多個位元組來代表一個字元的各種漢字延伸編碼方式,稱為 ANSI 編碼。在簡體中文Windows作業系統中ANSI 編碼代表 GBK 編碼,不同 ANSI 編碼之間互不相容,當資訊在國際間交流時,無法將屬於兩種語言的文字,儲存在同一段 ANSI 編碼的文字中【百度百科】。
二、編碼、解碼
編碼的過程是將字元轉換成位元組流,解碼的過程是將位元組流解析為字元
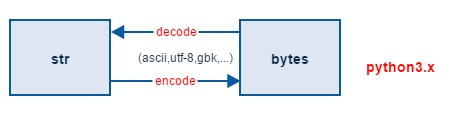
在計算機記憶體中統一使用Unicode編碼,用記事本編輯的時候,從檔案讀取的UTF-8字元被轉換為Unicode字元到記憶體裡,編輯完成後,儲存的時候再把Unicode轉換為UTF-8儲存到檔案。【出處】

# Python 3.6預設編碼 # Python 3中字串型別是str,在記憶體中以Unicode表示一個字元對應若干個位元組。 # 如果要在網路上傳輸,或者儲存到磁碟上就需要把str變為以位元組為單位的bytes。 In [1]: import sys In [2]: sys.getdefaultencoding() Out[2]: 'utf-8' # 中文編碼的範圍超過了ASCII編碼的範圍,含有中文的str可以用UTF-8編碼為bytes # utf-8和gb系列的編碼是完全不相容的,要想互相轉換必須要通過Unicode作為媒介 In [3]: '中文'.encode('utf-8') Out[4]: b'\xe4\xb8\xad\xe6\x96\x87' In [4]: '中文'.encode('gb2312') Out[4]: b'\xd6\xd0\xce\xc4'
標註:str和bytes的互相轉換應首選UTF-8編碼
原始碼有用到非ascii字元,-*- coding: utf-8 -*- (顯式指定指令碼字元編碼)即告訴Python直譯器按照UTF-8編碼讀取原始碼(解釋指令碼檔案時使用的編碼格式),但不代表.py原始檔自身為UTF-8編碼,應在儲存時做選擇。
Ex1、
# 將含中文的Py原始檔儲存為ANSI格式
#-*- coding: utf-8 -*-
print("中文')
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
#Py2不顯示指定utf-8編碼
SyntaxError: Non-ASCII character '\xe4' in file 1125.py on line 1
三、直譯器字元編碼
Python3 預設的直譯器字元編碼是 utf-8
Python2 在 Windows 平臺上,預設是使用 gbk 對字元進行 decode 輸出
# Py2.7
# -*- coding: utf-8 -*-
import sys
print('中文')
print('中文'.decode('utf-8'))
# 涓枃 中文
print('\xe4\xb8\xad\xe6\x96\x87')
print('\xd6\xd0\xce\xc4')
print('\xd6\xd0\xce\xc4'.decode('gbk'))
# 涓枃 中文 中文
************************
# 經編碼解碼格式不一致出現亂碼例項
>>> a="中文"
>>> a
'\xe4\xb8\xad\xe6\x96\x87'
>>> b = a.decode("utf-8")
>>> b
u'\u4e2d\u6587'
>>> c = b.encode("gbk")
>>> c
'\xd6\xd0\xce\xc4'
>>> print c
אτ
>>> print b
中文
補充:
1、Python2字串缺陷
Python2預設編碼ASCII,有兩種型別字串:str 和 unicode。
使用 ASCII 碼作為預設編碼方式,對中文處理很不友好。
把字串的牽強地分為 unicode 和 str 兩種型別,誤導開發者

# 修改Py2的預設編碼
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
>>> a = "測試"
>>> b = a.decode('GBK')
# 判斷字串否為Unicode
>>> isinstance(b,unicode)
True
>>> a
'\xe6\xb5\x8b\xe8\xaf\x95'
>>> b
u'\u5a34\u5b2d\u762f'
>>> b.decode("GBK")
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2:
# Python2對一個unicode物件執行解碼進行的隱式編碼 b.encode('ascii').decode('GBK')
# str 型別與 unicode 型別的字串混合使用時,str 型別的字串會隱式地將 str 轉換成 unicode字串
s.decode(“utf-8”, “ignore”) 忽略其中有異常的編碼,僅顯示有效的編碼
s.decode(“utf-8”, “replace”) 替換其中異常的編碼,這個相對來可能一眼就知道那些字元編碼出問題
2、Python3的改進
預設支援 unicode 字符集,文字字元和二進位制資料區分得更清晰分別用 str 和 bytes 表示
文字字元全部用 str 型別表示,str 能表示 Unicode 字符集中所有字元,
而二進位制位元組資料用一種全新的資料型別用 bytes 來表示【出處】b’字串’表示bytes物件
- bytes 型別提供的操作和 str 一樣,支援分片、索引、基本數值運算等操作
- str 物件擁有encode方法 bytes物件擁有decode方法,預設用 UTF-8轉換。
- 從 bytes 到另一 bytes 必須先 decode 後才能 encode。
3、小結
"""
py3 中消除了py2中位元組碼和字串混亂的定義
str 就是字串 bytes 才是位元組碼
在 py2 中 str 是位元組碼 unicode 才是字串
"""
py3 py2
位元組碼 bytes str
字串 str unicode
Python2 指令碼帶有中文字元時需要在指令碼開頭宣告能支援中文的指令碼檔案編碼;
Python2 中對同一個字串的 encode 和 decode 編碼格式需要保持一致;
Python3,bytes是位元組流bytes物件,字串是字串str物件。
Py3下獲得中文的Unicode編碼
>>> "中文".encode("unicode-escape")
b'\\u4e2d\\u6587'
相關推薦
【筆記】Python字元編碼
一、字元編碼(文字的編碼指的是字元如何使用位元組來表示組織方式) 1、ASCII 英文字母大小寫,特殊字元,數字,早期ASCII 字元編碼規定使用單位元組中低位的7個位元去編碼所有的字元(\x80以下),ASCII 擴充字符集利用了後128個字元。 2、Unic
【轉】python基礎-編碼與解碼
什麽 浪費 2.x sys 拼接 aced tro lte bytes 【轉自:https://www.cnblogs.com/OldJack/p/6658779.html】 一、什麽是編碼 編碼是指信息從一種形式或格式轉換為另一種形式或格式的過程。 在計算機中,編碼,簡而
【筆記】python
strip() 字符串 while raw bre col ring 空白 try 輸入輸出 python的輸入是野生字符串,所以要自己轉類型 strip去掉左右兩端的空白符,返回str slipt把字符串按空白符拆開,返回[str] map把list裏面的值映射
【筆記】Python集成開發環境——Pycharm
error out products 註意 bsp win enc ava isa 使用好的開發環境將有效提高編程效率,在Python使用上我是小白,所以特意請教了從事語言處理的成同學,告知我,推薦使用Pycharm和IntelliJ。 目前學習Python,那就先找個Py
【面試】Python字元切割,replace+split
string = 'i am a chinese boy,but she is a japanese girl,she is russia girl.please tell me that how do i choice?' \ 'and can we happyniess?can we ha
【筆記】Python資料型別和序列
基本資料型別 1)除法/和除法//的區別 除法/,對於整數除法而言,會取整,而對於小樹除法則會得到小數。 除法//表示取整除,只返回商的整數部分,無論是對於整數還是小數除法,都只會得到整數部分。 2)decimal的運算 from decimal impo
【筆記】python+selenium 一個簡單的自動化指令碼
環境 python 3.6.1 firefox 63.0.1 selenium 3.141.0 注:geckodriver與firefox版本要相對應 否則會出現一些模組引用錯誤 from selenium import webdriver from t
【筆記】Python基礎二
一,變數 變數作用是記錄狀態 1,變數基本型別 字串 數字 列表 元組 字典 2,可變不可變 1),可變:修改變數的值,id值不變。列表,字典 2),不可變:新建立變數後需要開闢新記憶體地址。字串,數字,元組 3,訪問順序 1),順序:字串,列表,元組 2),對映:字典 3),直接
【筆記】Python基礎三
一,檔案操作 1,檔案處理流程 1)開啟檔案,獲得檔案控制代碼(open函式提供)並賦值 2)通過控制代碼對檔案進行操作 3)關閉控制代碼 f = open('陳粒',encoding='utf-8')#open函式會先檢索系統的編碼gbk,檔案存的是UTF-8編碼,這樣會出現亂碼
【筆記】Python基礎四
一,迭代器協議和for迴圈工作機制 (一),迭代器協議 1,迭代器協議:物件必須提供一個next方法,執行該方法要麼返回迭代中的下一項,要麼就引起一個stopiteration異常,以終止迭代(只能往後走,不能往前退) 2,可迭代物件:實現了迭代器協議的物件(如何實現,物件內嵌一個__iter__()方
【筆記】Python基礎五
python基礎 嵌套 from 目標 定義 timer 增加 合格 高階函數 一,什麽是裝飾器 本質就是函數,功能是為其他函數添加附加功能 原則: 1,不修改被修飾函數的源代碼 2,不修改被修飾函數的調用方式 例子: import time def timmer(fu
【翻譯】Python PEP8編碼規範(中文版)
原文連結:http://legacy.python.org/dev/peps/pe
Python自動化開發課堂筆記【Day03】 - Python基礎(字符編碼使用,文件處理,函數)
賦值 創建 解釋器 使用 重復 closed 操作 邏輯 默認 字符編碼使用 1. 文本編輯器如何存取文件 文本編輯器相當一個運行在內存中的進程,所以文件內容在編輯未存儲時都是在內存中的,尚未存儲在硬盤之中,在沒有保存之前,所編輯的任何文本都只是一堆字符,沒有任何邏輯上的意
Python自動化開發課堂筆記【Day06】 - Python進階(類)
擴展性 程序 lex 類名 人物 優點 ini 參數 self. 類與對象 面向過程的程序設計: 優點:極大的降低了程序的復雜度 缺點:一套流水線或者流程就是用來解決一個問題,生產汽水的流水線無法生產汽車,即使能,也是得大改,改一個組件,牽一發而動全身面向對象的程序設計
Python開發【筆記】:進程
感覺 順序 至少 操作系統 打字 作業 都在 系統 簡單 序言 進程與線程概述: 很多同學都聽說過,現代操作系統比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任務”的操作系統。 什麽叫“多任務”呢?簡單地說,就是操作系統可以同時運行多個任
Python自動化開發課堂筆記【Day08】 - Python進階(面向對象的高級用法,網絡編程)
sta 自然 log 報錯 面向 read urn total 析構函數 面向對象的高級用法 1. __str__ 只要執行打印對象的操作,就會觸發該對象類中的__str__方法(也就是對象的綁定方法)它是一種默認的方法,默認的打印輸出為<__main__.Foo o
Python開發【筆記】:git&github 快速入門
精神 源代碼 公開 平臺 per 其中 http cvs tro github入門 簡介: 很多人都知道,Linus在1991年創建了開源的Linux,從此,Linux系統不斷發展,已經成為最大的服務器系統軟件了。 Linus雖然創建了Linux,但Linux的壯大
Python開發【筆記】:單線程下執行多個定時器
自動 代碼 python 線程 timer ont -s 大量 過多 單線程多定時器 前言:公司業務需求,實例當中大量需要啟動定時器的操作;大家都知道python中的定時器用的是threading.Timer,每當啟動一個定時器時,程序內部起了一個線程,定時器觸發執行結
【學習筆記】python爬取百度真實url
python 今天跑個腳本需要一堆測試的url,,,挨個找復制粘貼肯定不是程序員的風格,so,還是寫個腳本吧。 環境:python2.7 編輯器:sublime text 3 一、分析一下 首先非常感謝百度大佬的url分類非常整齊,都在一個
python網絡爬蟲與信息提取【筆記】
robots 請求 api python requests 中國 正則 網絡 正則表達式詳解 以下是‘’網絡爬蟲‘’課程(中國MOOC)學習筆記 【萬能的b站】 核心思想: The Website is the API 課程大綱: 一、Requests與robots.txt