
Keras TensorFlow教程:如何從零開發一個複雜深度學習模型
Keras 是提供一些高可用的 Python API ,能幫助你快速的構建和訓練自己的深度學習模型,它的後端是 TensorFlow 或者 Theano 。本文假設你已經熟悉了 TensorFlow 和卷積神經網路,如果,你還沒有熟悉,那麼可以先看看這個10分鐘入門 TensorFlow 教程和卷積神經網路教程,然後再回來閱讀這個文章。
在這個教程中,我們將學習以下幾個方面:
- 為什麼選擇 Keras?為什麼 Keras 被認為是深度學習的未來?
- 在Ubuntu上面一步一步安裝Keras。
- Keras TensorFlow教程:Keras基礎知識。
- 瞭解 Keras 序列模型
4.1 實際例子講解線性迴歸問題 - 使用 Keras 儲存和回覆預訓練的模型
- Keras API
6.1 使用Keras API開發VGG卷積神經網路
6.2 使用Keras API構建並執行SqueezeNet卷積神經網路
1. 為什麼選擇Keras?
Keras 是 Google 的一位工程師 François Chollet 開發的一個框架,可以幫助你在 Theano 上面進行快速原型開發。後來,這被擴充套件為 TensorFlow 也可以作為後端。並且最近,TensorFlow決定將其作為 contrib 檔案中的一部分進行提供。
Keras 被認為是構建神經網路的未來,以下是一些它流行的原因:
-
輕量級和快速開發:Keras 的目的是在消除樣板程式碼。幾行 Keras 程式碼就能比原生的 TensorFlow 程式碼實現更多的功能。你也可以很輕鬆的實現 CNN 和 RNN,並且讓它們執行在 CPU 或者 GPU 上面。
-
框架的“贏者”:Keras 是一個API,執行在別的深度學習框架上面。這個框架可以是 TensorFlow 或者 Theano。Microsoft 也計劃讓 CNTK 作為 Keras 的一個後端。目前,神經網路框架世界是非常分散的,並且發展非常快。具體,你可以看看 Karpathy 的這個推文:
-
想象一下,我們每年都要去學習一個新的框架,這是多麼的痛苦。到目前為止,TensorFlow 似乎成為了一種潮流,並且越來越多的框架開始為 Keras 提供支援,它可能會成為一種標準。
目前,Keras 是成長最快的一種深度學習框架。因為可以使用不同的深度學習框架作為後端,這也使得它成為了流行的一個很大的原因。你可以設想這樣一個場景,如果你閱讀到了一篇很有趣的論文,並且你想在你自己的資料集上面測試這個模型。讓我們再次假設,你對TensorFlow 非常熟悉,但是對Theano瞭解的非常少。那麼,你必須使用TensorFlow 對這個論文進行復現,但是這個週期是非常長的。但是,如果現在程式碼是採用Keras寫的,那麼你只要將後端修改為TensorFlow就可以使用程式碼了。這將是對社群發展的一個巨大的推動作用。
2. 怎麼安裝Keras,並且把TensorFlow作為後端
a) 依賴安裝
安裝 h5py,用於模型的儲存和載入:
pip install h5py
還有一些依賴包也要安裝。
pip install numpy scipy
pip install pillow
如果你還沒有安裝TensorFlow,那麼你可以按照這個教程先去安裝TensorFlow。一旦,你安裝完成了 TensorFlow,你只需要使用 pip 很容易的安裝 Keras。
sudo pip install keras
使用以下命令來檢視 Keras 版本。
>>> import keras
Using TensorFlow backend.
>>> keras.__version__
'2.0.4'
一旦,Keras 被安裝完成,你需要去修改後端檔案,也就是去確定,你需要 TensorFlow 作為後端,還是 Theano 作為後端,修改的配置檔案位於 ~/.keras/keras.json 。具體配置如下:
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
請注意,引數 image_data_format 是 channels_last ,也就是說這個後端是 TensorFlow。因為,在TensorFlow中影象的儲存方式是[height, width, channels],但是在Theano中是完全不同的,也就是 [channels, height, width]。因此,如果你沒有正確的設定這個引數,那麼你模型的中間結果將是非常奇怪的。對於Theano來說,這個引數就是channels_first。
那麼,至此你已經準備好了,使用Keras來構建模型,並且把TensorFlow作為後端。
3. Keras基礎知識
在Keras中主要的資料結構是 model ,該結構定義了一個完整的圖。你可以向已經存在的圖中加入任何的網路結構。
import keras
Keras 有兩種不同的建模方式:
-
Sequential models:這種方法用於實現一些簡單的模型。你只需要向一些存在的模型中新增層就行了。
-
Functional API:Keras的API是非常強大的,你可以利用這些API來構造更加複雜的模型,比如多輸出模型,有向無環圖等等。
在本文的下一節中,我們將學習Keras的Sequential models 和 Functional API的理論和例項。
4. Keras Sequential models
在這一部分中,我將來介紹Keras Sequential models的理論。我將快速的解釋它是如何工作的,還會利用具體程式碼來解釋。之後,我們將解決一個簡單的線性迴歸問題,你可以在閱讀的同時執行程式碼,來加深印象。
以下程式碼是如何開始匯入和構建序列模型。
from keras.models import Sequential
models = Sequential()
接下來我們可以向模型中新增 Dense(full connected layer),Activation,Conv2D,MaxPooling2D函式
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropout
model.add(Conv2D(64, (3,3), activation='relu', input_shape = (100,100,32)))
# This ads a Convolutional layer with 64 filters of size 3 * 3 to the graph
以下是如何將一些最流行的圖層新增到網路中。我已經在卷積神經網路教程中寫了很多關於圖層的描述。
1. 卷積層
這裡我們使用一個卷積層,64個卷積核,維度是33的,之後採用 relu 啟用函式進行啟用,輸入資料的維度是 `100100*32`。注意,如果是第一個卷積層,那麼必須加上輸入資料的維度,後面幾個這個引數可以省略。
model.add(Conv2D(64, (3,3), activation='relu', input_shape = (100,100,32)))
2. MaxPooling 層
指定圖層的型別,並且指定赤的大小,然後自動完成赤化操作,酷斃了!
model.add(MaxPooling2D(pool_size=(2,2)))
3. 全連線層
這個層在 Keras 中稱為被稱之為 Dense 層,我們只需要設定輸出層的維度,然後Keras就會幫助我們自動完成了。
model.add(Dense(256, activation='relu'))
4. Dropout
model.add(Dropout(0.5))
5. 扁平層
model.add(Flatten())
資料輸入
網路的第一層需要讀入訓練資料。因此我們需要去制定輸入資料的維度。因此,input_shape引數被用於制定輸入資料的維度大小。
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(224, 224, 3)))
在這個例子中,資料輸入的第一層是一個卷積層,輸入資料的大小是 224*224*3 。
以上操作就幫助你利用序列模型構建了一個模型。接下來,讓我們學習最重要的一個部分。一旦你指定了一個網路架構,你還需要指定優化器和損失函式。我們在Keras中使用compile函式來達到這個功能。比如,在下面的程式碼中,我們使用rmsprop 來作為優化器,binary_crossentropy 來作為損失函式值。
model.compile(loss='binary_crossentropy', optimizer='rmsprop')
如果你想要使用隨機梯度下降,那麼你需要選擇合適的初始值和超引數:
from keras.optimizers import SGD
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
現在,我們已經構建完了模型。接下來,讓我們向模型中輸入資料,在Keras中是通過 fit 函式來實現的。你也可以在該函式中指定 batch_size 和 epochs 來訓練。
model.fit(x_train, y_train, batch_size = 32, epochs = 10, validation_data(x_val, y_val))
最後,我們使用 evaluate 函式來測試模型的效能
score = model.evaluate(x_test, y_test, batch_size = 32)
這些就是使用序列模型在Keras中構建神經網路的具體操作步驟。現在,我們來構建一個簡單的線性迴歸模型。
4.1 實際例子講解線性迴歸問題
問題陳述
線上性迴歸問題中,你可以得到很多的資料點,然後你需要使用一條直線去擬合這些離散點。在這個例子中,我們建立了100個離散點,然後用一條直線去擬合它們。
a) 建立訓練資料
TrainX 的資料範圍是 -1 到 1,TrainY 與 TrainX 的關係是3倍,並且我們加入了一些噪聲點。
import keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
trX = np.linspace(-1, 1, 101)
trY = 3 * trX + np.random.randn(*trX.shape) * 0.33
b) 構建模型
首先我們需要構建一個序列模型。我們需要的只是一個簡單的連結,因此我們只需要使用一個 Dense 層就夠了,然後用線性函式進行啟用。
model = Sequential()
model.add(Dense(input_dim=1, output_dim=1, init='uniform', activation='linear'))
下面的程式碼將設定輸入資料 x,權重 w 和偏置項 b。然我們來看看具體的初始化工作。如下:
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))
## Linear regression model is initialized with weight w: -0.03, b: 0.00
現在,我們可以l利用自己構造的資料 trX 和 trY 來訓練這個線性模型,其中 trY 是 trX 的3倍。因此,權重 w 的值應該是 3。
我們使用簡單的梯度下降來作
為優化器,均方誤差(MSE)作為損失值。如下:
model.compile(optimizer='sgd', loss='mse')
最後,我們使用 fit 函式來輸入資料。
model.fit(trX, trY, nb_epoch=200, verbose=1)
在經過訓練之後,我們再次列印權重:
weights = model.layers[0].get_weights()
w_final = weights[0][0][0]
b_final = weights[1][0]
print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final))
##Linear regression model is trained to have weight w: 2.94, b: 0.08
正如你所看到的,在執行 200 輪之後,現在權重非常接近於 3。你可以將執行的輪數修改為區間 [100, 300] 之間,然後觀察輸出結構有什麼變化。現在,你已經學會了利用很少的程式碼來構建一個線性迴歸模型,如果要構建一個相同的模型,在 TensorFlow 中需要用到更多的程式碼。
5. 使用 Keras 儲存和回覆預訓練的模型
HDF5 二進位制格式
一旦你利用Keras完成了訓練,你可以將你的網路儲存在HDF5裡面。當然,你需要先安裝 h5py。HDF5 格式非常適合儲存大量的數字收,並從 numpy 處理這些資料。比如,我們可以輕鬆的將儲存在磁碟上的多TB資料集進行切片,就好像他們是真正的 numpy 陣列一樣。你還可以將多個數據集儲存在單個檔案中,遍歷他們或者檢視 .shape 和 .dtype 屬性。
如果你需要信心,那麼告訴你,NASA也在使用 HDF5 進行資料儲存。h5py 是python對HDF5 C API 的封裝。幾乎你可以用C在HDF5上面進行的任何操作都可以用python在h5py上面操作。
儲存權重
如果你要儲存訓練好的權重,那麼你可以直接使用 save_weights 函式。
model.save_weights("my_model.h5")
載入預訓練權重
如果你想要載入以前訓練好的模型,那麼你可以使用 load_weights 函式。
model.load_weights('my_model_weights.h5')
6. Keras API
如果對於簡單的模型和問題,那麼序列模型是非常好的方式。但是如果你要構建一個現實世界中複雜的網路,那麼你就需要知道一些功能性的API,在很多流行的神經網路中,我們都有一個最小的網路結構,完整的模型是根據這些最小的模型進行疊加完成的。這些基礎的API可以讓你一層一層的構建模型。因此,你只需要很少的程式碼就可以來構建一個完整的複雜神經網路。
讓我們來看看它是如何工作的。首先,你需要匯入一些包。
from keras.models import Model
現在,你需要去指定輸入資料,而不是在順序模型中,在最後的 fit 函式中輸入資料。這是序列模型和這些功能性的API之間最顯著的區別之一。我們使用 input() 函式來申明一個 1*28*28 的張量。
from keras.layers import Input
## First, define the vision modules
digit_input = Input(shape=(1, 28, 28))
現在,讓我們來利用API設計一個卷積層,我們需要指定要在在哪個層使用卷積網路,具體程式碼這樣操作:
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
out = Flatten()(x)
最後,我們對於指定的輸入和輸出資料來構建一個模型。
vision_model = Model(digit_input, out)
當然,我們還需要指定損失函式,優化器等等。但這些和我們在序列模型中的操作一樣,你可以使用 fit 函式和 compile函式來進行操作。
接下來,讓我們來構建一個vgg-16模型,這是一個很大很“老”的模型,但是由於它的簡潔性,它是一個很好的學習模型。
6.1 使用Keras API開發VGG卷積神經網路
VGG:
VGG卷積神經網路是牛津大學在2014年提出來的模型。當這個模型被提出時,由於它的簡潔性和實用性,馬上成為了當時最流行的卷積神經網路模型。它在影象分類和目標檢測任務中都表現出非常好的結果。在2014年的ILSVRC比賽中,VGG 在Top-5中取得了92.3%的正確率。 該模型有一些變種,其中最受歡迎的當然是 vgg-16,這是一個擁有16層的模型。你可以看到它需要維度是 224*224*3 的輸入資料。
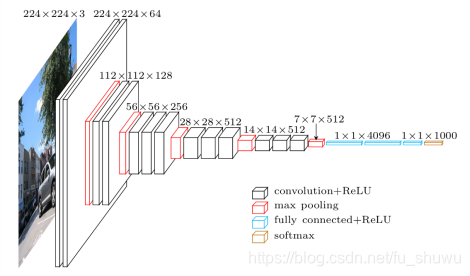
Vgg 16 architecture
讓我們來寫一個獨立的函式來完整實現這個模型。
img_input = Input(shape=input_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
-
我們可以將這個完整的模型,命名為 vgg16.py。
在這個例子中,我們來執行 imageNet 資料集中的某一些資料來進行測試。具體程式碼如下:
model = applications.VGG16(weights='imagenet') img = image.load_img('cat.jpeg', target_size=(224, 224)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) for results in decode_predictions(preds): for result in results: print('Probability %0.2f%% => [%s]' % (100*result[2], result[1]))
-
正如你在圖中看到的,模型會對圖片中的物體進行一個識別預測。
我們通過API構建了一個VGG模型,但是由於VGG是一個很簡單的模型,所以並沒有完全將API的能力開發出來。接下來,我們通過構建一個 SqueezeNet模型,來展示API的真正能力。
6.2 使用Keras API構建並執行SqueezeNet卷積神經網路
SequeezeNet 是一個非常了不起的網路架構,它的顯著點不在於對正確性有多少的提高,而是減少了計算量。當SequeezeNet的正確性和AlexNet接近時,但是ImageNet上面的預訓練模型的儲存量小於5 MB,這對於在現實世界中使用CNN是非常有利的。SqueezeNet模型引入了一個 Fire模型,它由交替的 Squeeze 和 Expand 模組組成。
SqueezeNet fire module
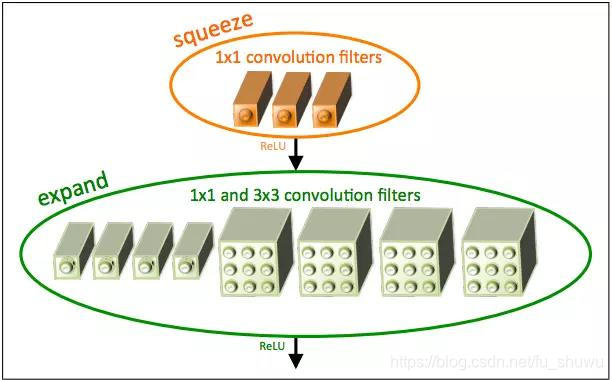
現在,我們對 fire 模型進行多次複製,從而來構建完整的網路模型,具體如下:
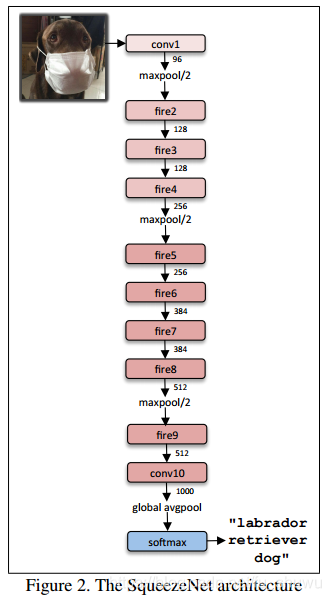
-
為了去構建這個網路,我們將利用API的功能首先來構建一個單獨的 fire 模組。
-
# Squeeze part of fire module with 1 * 1 convolutions, followed by Relu x = Convolution2D(squeeze, (1, 1), padding='valid', name='fire2/squeeze1x1')(x) x = Activation('relu', name='fire2/relu_squeeze1x1')(x) #Expand part has two portions, left uses 1 * 1 convolutions and is called expand1x1 left = Convolution2D(expand, (1, 1), padding='valid', name='fire2/expand1x1')(x) left = Activation('relu', name='fire2/relu_expand1x1')(left) #Right part uses 3 * 3 convolutions and is called expand3x3, both of these are follow#ed by Relu layer, Note that both receive x as input as designed. right = Convolution2D(expand, (3, 3), padding='same', name='fire2/expand3x3')(x) right = Activation('relu', name='fire2/relu_expand3x3')(right) # Final output of Fire Module is concatenation of left and right. x = concatenate([left, right], axis=3, name='fire2/concat')為了重用這些程式碼,我們可以將它們轉換成一個函式:
-
sq1x1 = "squeeze1x1" exp1x1 = "expand1x1" exp3x3 = "expand3x3" relu = "relu_" WEIGHTS_PATH = "https://github.com/rcmalli/keras-squeezenet/releases/download/v1.0/squeezenet_weights_tf_dim_ordering_tf_kernels.h5" - 模組化處理
- 現在,我們可以利用我們構建好的單獨的 fire 模組,來構建完整的模型。
-
sq1x1 = "squeeze1x1" exp1x1 = "expand1x1" exp3x3 = "expand3x3" relu = "relu_" def fire_module(x, fire_id, squeeze=16, expand=64): s_id = 'fire' + str(fire_id) + '/' x = Convolution2D(squeeze, (1, 1), padding='valid', name=s_id + sq1x1)(x) x = Activation('relu', name=s_id + relu + sq1x1)(x) left = Convolution2D(expand, (1, 1), padding='valid', name=s_id + exp1x1)(x) left = Activation('relu', name=s_id + relu + exp1x1)(left) right = Convolution2D(expand, (3, 3), padding='same', name=s_id + exp3x3)(x) right = Activation('relu', name=s_id + relu + exp3x3)(right) x = concatenate([left, right], axis=3, name=s_id + 'concat') return x完整的網路模型我們放置在 squeezenet.py 檔案裡。我們應該先下載 imageNet 預訓練模型,然後在我們自己的資料集上面進行訓練和測試。下面的程式碼就是實現了這個功能:
-
import numpy as np from keras_squeezenet import SqueezeNet from keras.applications.imagenet_utils import preprocess_input, decode_predictions from keras.preprocessing import image model = SqueezeNet() img = image.load_img('pexels-photo-280207.jpeg', target_size=(227, 227)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) all_results = decode_predictions(preds) for results in all_results: for result in results: print('Probability %0.2f%% => [%s]' % (100*result[2], result[1]))
對於相同的一幅圖預測,我們可以得到如下的預測概率。
至此,我們的Keras TensorFlow教程就結束了。希望可以幫到你 :-)
作者:chen_h
連結:http://www.jianshu.com/p/20585e3b6d02
來源:簡書
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。