
MySQL的JOIN(一):用法
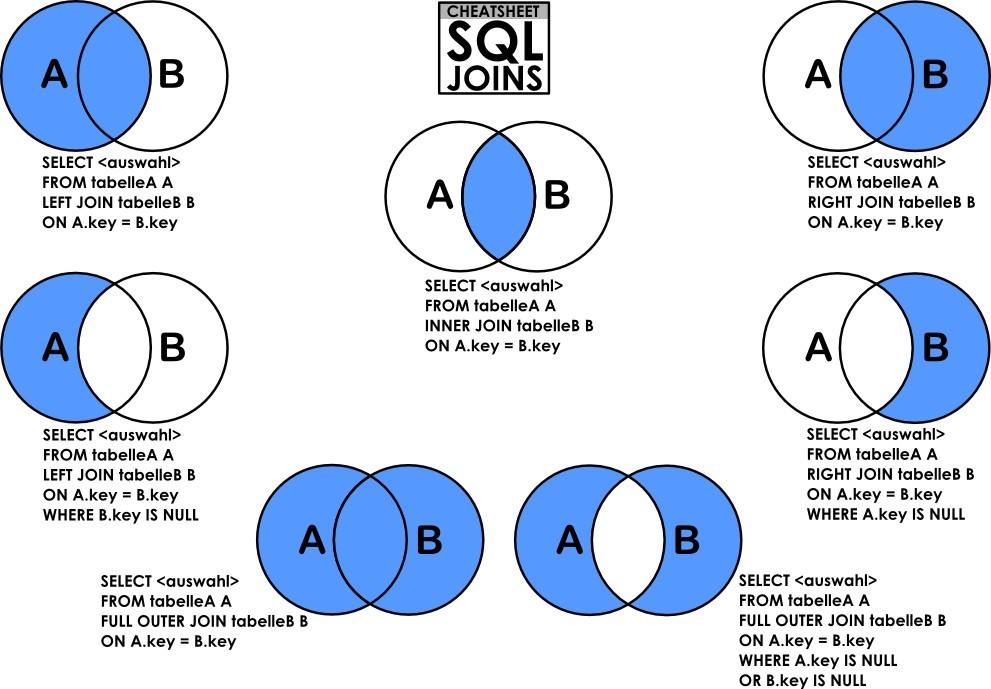
JOIN的含義就如英文單詞“join”一樣,連線兩張表,大致分為內連線,外連線,右連線,左連線,自然連線。這裡描述先甩出一張用爛了的圖,然後插入測試資料。


CREATE TABLE t_blog( id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR(50), typeId INT ); SELECT * FROM t_blog; +----+-------+--------+ | id | title | typeId | +----+-------+--------+View Code| 1 | aaa | 1 | | 2 | bbb | 2 | | 3 | ccc | 3 | | 4 | ddd | 4 | | 5 | eee | 4 | | 6 | fff | 3 | | 7 | ggg | 2 | | 8 | hhh | NULL | | 9 | iii | NULL | | 10 | jjj | NULL | +----+-------+--------+-- 部落格的類別 CREATE TABLE t_type( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) ); SELECT * FROM t_type; +----+------------+ | id | name | +----+------------+ | 1 | C++ | | 2 | C | | 3 | Java | | 4 | C# || 5 | Javascript | +----+------------+
笛卡爾積:CROSS JOIN
要理解各種JOIN首先要理解笛卡爾積。笛卡爾積就是將A表的每一條記錄與B表的每一條記錄強行拼在一起。所以,如果A表有n條記錄,B表有m條記錄,笛卡爾積產生的結果就會產生n*m條記錄。下面的例子,t_blog有10條記錄,t_type有5條記錄,所有他們倆的笛卡爾積有50條記錄。有五種產生笛卡爾積的方式如下。
SELECT * FROM t_blog CROSS JOIN t_type; SELECT * FROM t_blog INNER JOIN t_type; SELECT * FROM t_blog,t_type; SELECT * FROM t_blog NATURE JOIN t_type; select * from t_blog NATURA join t_type; +----+-------+--------+----+------------+ | id | title | typeId | id | name | +----+-------+--------+----+------------+ | 1 | aaa | 1 | 1 | C++ | | 1 | aaa | 1 | 2 | C | | 1 | aaa | 1 | 3 | Java | | 1 | aaa | 1 | 4 | C# | | 1 | aaa | 1 | 5 | Javascript | | 2 | bbb | 2 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 2 | bbb | 2 | 3 | Java | | 2 | bbb | 2 | 4 | C# | | 2 | bbb | 2 | 5 | Javascript | | 3 | ccc | 3 | 1 | C++ | | 3 | ccc | 3 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 3 | ccc | 3 | 4 | C# | | 3 | ccc | 3 | 5 | Javascript | | 4 | ddd | 4 | 1 | C++ | | 4 | ddd | 4 | 2 | C | | 4 | ddd | 4 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 4 | ddd | 4 | 5 | Javascript | | 5 | eee | 4 | 1 | C++ | | 5 | eee | 4 | 2 | C | | 5 | eee | 4 | 3 | Java | | 5 | eee | 4 | 4 | C# | | 5 | eee | 4 | 5 | Javascript | | 6 | fff | 3 | 1 | C++ | | 6 | fff | 3 | 2 | C | | 6 | fff | 3 | 3 | Java | | 6 | fff | 3 | 4 | C# | | 6 | fff | 3 | 5 | Javascript | | 7 | ggg | 2 | 1 | C++ | | 7 | ggg | 2 | 2 | C | | 7 | ggg | 2 | 3 | Java | | 7 | ggg | 2 | 4 | C# | | 7 | ggg | 2 | 5 | Javascript | | 8 | hhh | NULL | 1 | C++ | | 8 | hhh | NULL | 2 | C | | 8 | hhh | NULL | 3 | Java | | 8 | hhh | NULL | 4 | C# | | 8 | hhh | NULL | 5 | Javascript | | 9 | iii | NULL | 1 | C++ | | 9 | iii | NULL | 2 | C | | 9 | iii | NULL | 3 | Java | | 9 | iii | NULL | 4 | C# | | 9 | iii | NULL | 5 | Javascript | | 10 | jjj | NULL | 1 | C++ | | 10 | jjj | NULL | 2 | C | | 10 | jjj | NULL | 3 | Java | | 10 | jjj | NULL | 4 | C# | | 10 | jjj | NULL | 5 | Javascript | +----+-------+--------+----+------------+View Code
內連線:INNER JOIN
內連線INNER JOIN是最常用的連線操作。從數學的角度講就是求兩個表的交集,從笛卡爾積的角度講就是從笛卡爾積中挑出ON子句條件成立的記錄。有INNER JOIN,WHERE(等值連線),STRAIGHT_JOIN,JOIN(省略INNER)四種寫法。至於哪種好我會在MySQL的JOIN(二):優化講述。示例如下。
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId=t_type.id; SELECT * FROM t_blog,t_type WHERE t_blog.typeId=t_type.id; SELECT * FROM t_blog STRAIGHT_JOIN t_type ON t_blog.typeId=t_type.id; --注意STRIGHT_JOIN有個下劃線 SELECT * FROM t_blog JOIN t_type ON t_blog.typeId=t_type.id;+----+-------+--------+----+------+ | id | title | typeId | id | name | +----+-------+--------+----+------+ | 1 | aaa | 1 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 7 | ggg | 2 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 6 | fff | 3 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 5 | eee | 4 | 4 | C# | +----+-------+--------+----+------+
左連線:LEFT JOIN
左連線LEFT JOIN的含義就是求兩個表的交集外加左表剩下的資料。依舊從笛卡爾積的角度講,就是先從笛卡爾積中挑出ON子句條件成立的記錄,然後加上左表中剩餘的記錄(見最後三條)。
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id;
+----+-------+--------+------+------+ | id | title | typeId | id | name | +----+-------+--------+------+------+ | 1 | aaa | 1 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 7 | ggg | 2 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 6 | fff | 3 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 5 | eee | 4 | 4 | C# | | 8 | hhh | NULL | NULL | NULL | | 9 | iii | NULL | NULL | NULL | | 10 | jjj | NULL | NULL | NULL | +----+-------+--------+------+------+
右連線:RIGHT JOIN
同理右連線RIGHT JOIN就是求兩個表的交集外加右表剩下的資料。再次從笛卡爾積的角度描述,右連線就是從笛卡爾積中挑出ON子句條件成立的記錄,然後加上右表中剩餘的記錄(見最後一條)。
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+----+------------+ | id | title | typeId | id | name | +------+-------+--------+----+------------+ | 1 | aaa | 1 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 5 | eee | 4 | 4 | C# | | 6 | fff | 3 | 3 | Java | | 7 | ggg | 2 | 2 | C | | NULL | NULL | NULL | 5 | Javascript | +------+-------+--------+----+------------+
外連線:OUTER JOIN
外連線就是求兩個集合的並集。從笛卡爾積的角度講就是從笛卡爾積中挑出ON子句條件成立的記錄,然後加上左表中剩餘的記錄,最後加上右表中剩餘的記錄。另外MySQL不支援OUTER JOIN,但是我們可以對左連線和右連線的結果做UNION操作來實現。
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id UNION SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+------+------------+ | id | title | typeId | id | name | +------+-------+--------+------+------------+ | 1 | aaa | 1 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 7 | ggg | 2 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 6 | fff | 3 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 5 | eee | 4 | 4 | C# | | 8 | hhh | NULL | NULL | NULL | | 9 | iii | NULL | NULL | NULL | | 10 | jjj | NULL | NULL | NULL | | NULL | NULL | NULL | 5 | Javascript | +------+-------+--------+------+------------+
USING子句
MySQL中連線SQL語句中,ON子句的語法格式為:table1.column_name = table2.column_name。當模式設計對聯接表的列採用了相同的命名樣式時,就可以使用 USING 語法來簡化 ON 語法,格式為:USING(column_name)。
所以,USING的功能相當於ON,區別在於USING指定一個屬性名用於連線兩個表,而ON指定一個條件。另外,SELECT *時,USING會去除USING指定的列,而ON不會。例項如下。
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId =t_type.id; +----+-------+--------+----+------+ | id | title | typeId | id | name | +----+-------+--------+----+------+ | 1 | aaa | 1 | 1 | C++ | | 2 | bbb | 2 | 2 | C | | 7 | ggg | 2 | 2 | C | | 3 | ccc | 3 | 3 | Java | | 6 | fff | 3 | 3 | Java | | 4 | ddd | 4 | 4 | C# | | 5 | eee | 4 | 4 | C# | +----+-------+--------+----+------+
SELECT * FROM t_blog INNER JOIN t_type USING(typeId); ERROR 1054 (42S22): Unknown column 'typeId' in 'from clause' SELECT * FROM t_blog INNER JOIN t_type USING(id); -- 應為t_blog的typeId與t_type的id不同名,無法用Using,這裡用id代替下。 +----+-------+--------+------------+ | id | title | typeId | name | +----+-------+--------+------------+ | 1 | aaa | 1 | C++ | | 2 | bbb | 2 | C | | 3 | ccc | 3 | Java | | 4 | ddd | 4 | C# | | 5 | eee | 4 | Javascript | +----+-------+--------+------------+
自然連線:NATURE JOIN
自然連線就是USING子句的簡化版,它找出兩個表中相同的列作為連線條件進行連線。有左自然連線,右自然連線和普通自然連線之分。在t_blog和t_type示例中,兩個表相同的列是id,所以會拿id作為連線條件。
另外千萬分清下面三條語句的區別 。
自然連線:SELECT * FROM t_blog NATURAL JOIN t_type;
笛卡爾積:SELECT * FROM t_blog NATURA JOIN t_type;
笛卡爾積:SELECT * FROM t_blog NATURE JOIN t_type;
SELECT * FROM t_blog NATURAL JOIN t_type; SELECT t_blog.id,title,typeId,t_type.name FROM t_blog,t_type WHERE t_blog.id=t_type.id; SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type ON t_blog.id=t_type.id; SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type USING(id); +----+-------+--------+------------+ | id | title | typeId | name相關推薦
MySQL的JOIN(一):用法
JOIN的含義就如英文單詞“join”一樣,連線兩張表,大致分為內連線,外連線,右連線,左連線,自然連線。這裡描述先甩出一張用爛了的圖,然後插入測試資料。 CREATE TABLE t_blog( id INT PRIMARY KEY AUTO_INCREMENT,
一站式學習Wireshark(一):Wireshark基本用法
11g 實現 alt href ascii 根據 無線網絡 完成 analyze 按照國際慣例,從最基本的說起。 抓取報文: 下載和安裝好Wireshark之後,啟動Wireshark並且在接口列表中選擇接口名,然後開始在此接口上抓包。例如,如果想要在無線網絡上抓取流量
jQuery -- 光陰似箭(一):初見 jQuery -- 基本用法,語法,選擇器
jQuery -- 知識點回顧篇(一):初見jQuery -- 基本用法,語法,選擇器 1. 使用方法 jQuery 庫位於一個 JavaScript 檔案中,其中包含了所有的 jQuery 函式。 網頁需要使用到 jQuery 時,需要先在網頁中引入 jQuery 的 js檔案。
pytorch學習(一):torch.nn.utils.rnn.pack_padded_sequence()的用法
torch.nn.utils.rnn.pack_padded_sequence()的用法: targets = pack_padded_sequence(captions, lengths, batch_first=True)[0] 輸入的caption是長度不同的句子 返
python裝飾器用法(一):計算一個函式執行所需要的時間
import time from functools import wraps def time_this_function(func): #作為裝飾器使用,返回函式執行需要花費的時間
Java監聽器的用法(一):內部類監聽器
當在處理按鈕等監聽事件時,需要註冊監聽器,監聽器的位置不同,角色就不同,訪問的區域就不同。 內部類是在另一個類中宣告的,包含內部類的類叫做外嵌類 內部類和外嵌類的關係: 1.內部類的外嵌類的成員變
【深入Java基礎】HashMap高階用法(一):排序
HashMap高階用法(一):排序 根據key排序 HashMap是無序的,我們可以根據key進行升序或降序。 1.利用List和Collections來實現排序 先獲取HashMap的keySet,然後將keySet放入List,在由Collectio
Scala 的那些奇怪的符號 (一):“:” 作用及用法
Scala的語法很多,有些人認為過於繁瑣,有些人卻認為正是因為繁瑣,所以才讓這門語言嚴謹和強大。 例如在翻閱Scala資料或者檢視Scala原始碼的時候,經常會看到“<:”和“>:”,這是什麼鬼?下面我就來探討一下這兩個符號的用法: “<:
Burp Suite詳細基本用法(一):Proxy、Target模組
Burp Suite可以說是Web安全工具中的瑞士軍刀,打算寫幾篇Blog以一個小白的角度去學習Burp Suite(簡稱BP),會詳細地說一下的用法,說明一下每一個部分是什麼功能,主要通過圖的備註來說明各個按鈕是什麼功能。有什麼錯誤也希望走過路過的大佬們指出,
工作流引擎Oozie(一):workflow
觸發 line last ssa pig oozie apt cnblogs 定時任務 1. Oozie簡介 Yahoo開發工作流引擎Oozie(馭象者),用於管理Hadoop任務(支持MapReduce、Spark、Pig、Hive),把這些任務以DAG(有向無環圖)方式
Spring 事務配置實戰(一):過濾無需事務處理的查詢之類操作
log pla ssi pan spl tail gif aop img <tx:advice id="txAdvice" transaction-manager="transactionManager"> <tx:attributes
【SSH之旅】一步步學習Hibernate框架(一):關於持久化
stc localhost 對象 schema hbm.xml java let pass [] 在不引用不論什麽框架下,我們會通過平庸的代碼不停的對數據庫進行操作,產生了非常多冗余的可是又有規律的底層代碼,這樣頻繁的操作數據庫和大量的底層代碼的反復
CS231n(一):基礎知識
深度學習 highlight 自己 元組 .py [0 upper bsp python 給自己新挖個坑:開始刷cs231n深度學習。 看了一下導言的pdf,差缺補漏。 s = "hello" print s.capitalize() # 首字母大寫; prints "
Javascript基礎簡單匯總(一):元素獲取
問題 元素節點 all push 傳說 length [] nbsp 文檔 在頁面腳本中,如果要對頁面元素進行操作,那麽我們就要獲取到這個元素 那麽在獲取元素之前首先得要了解什麽是DOM(document object model) 在DOM,元素是以節點的形式表示的,每
elastic-job詳解(一):數據分片
count 任務 不同的 應該 center shc 偶數 int ext 數據分片的目的在於把一個任務分散到不同的機器上運行,既可以解決單機計算能力上限的問題,也能降低部分任務失敗對整體系統的影響。elastic-job並不直接提供數據處理的功能,框架只會將分片項分配至各
中國mooc北京理工大學機器學習第二周(一):分類
kmeans 方法 輸入 nump arr mod 理工大學 each orm 一、K近鄰方法(KNeighborsClassifier) 使用方法同kmeans方法,先構造分類器,再進行擬合。區別是Kmeans聚類是無監督學習,KNN是監督學習,因此需要劃分出訓練集和測試
在Python中用Request庫模擬登錄(一):字幕庫(無加密,無驗證碼)
用戶名 com color 了無 1-1 value img requests log 如此簡單(不安全)的登錄表單已經不多見了。字幕庫的登錄表單如下所示,其中省去了無關緊要的內容: 1 <form class="login-form" action="/User/
Maven項目搭建(一):Maven初體驗
測試類 java平臺 存在 ack 做的 rar cli maven2 試用 今天給大家介紹一個項目管理和綜合工具:Maven。 Maven: maven讀作 [‘meivin],本意是指可以被信任的領域專家,致力於傳播知識(來自於http://en.wikip
方便大家學習的Node.js教程(一):理解Node.js
圖形 -1 iter pri attribute set run 相對 mage 理解Node.js 為了理解Node.js是如何工作的,首先你需要理解一些使得Javascript適用於服務器端開發的關鍵特性。Javascript是一門簡單而又靈活的語言,這種靈
Nginx實用教程(一):啟動、停止、重載配置
style 負載 繼續 local con doc lin 配置文件的修改 tex Nginx是一個功能強大的web服務器和負載均衡軟件,由俄羅斯人開發。Nginx包括一個master進程和數個worker進程,master進程用於讀取、解析配置文件和管理worker進程,