資料結構與演算法學習筆記—— 散列表
阿新 • • 發佈:2019-01-12
什麼是散列表:
散列表用的是陣列支援按照下標隨機訪問資料的特性,所以散列表其實就是陣列的一種擴充套件,由陣列演化而來。可以說,如果沒有陣列,就沒有散列表。
原理:
散列表用的就是陣列支援按照下標隨機訪問的時候,時間複雜度是0(1)的特性。我們通過雜湊函式把元素的鍵值對映為下標,然後將資料儲存在陣列中對應下標的位置。當我們按照鍵值查詢元素時,我們用同樣的雜湊函式,將鍵值轉化陣列標標,從對應的陣列下標的位置取資料。
雜湊函式的設計要求:
雜湊函式計算得到的雜湊值是一個非負整數;.
如果key1 = key2,那hash(key1) == hash(key2);
如果key1 != key2,那hash(key1) != hash(key2),
雜湊函式的設計不能太複雜,雜湊函式生成值要儘可能隨機並且均勻分佈
如果不符合3 那麼就出現了雜湊衝突,雜湊衝突是無法避免的
解決雜湊衝突的方法有兩種:
開放定址法(open addressing)和連結串列法(chaining)
開放定址法:如果出現了雜湊衝突,我們就重新探測一個空閒位置,將其插入。
裝在因子: 散列表中一定比例的空閒槽位。公式: 散列表的裝載因子 = 填入表中的元素個數 / 散列表的長度
裝載因子越大,說明空閒位置越少,衝突越多,散列表的效能會下降。
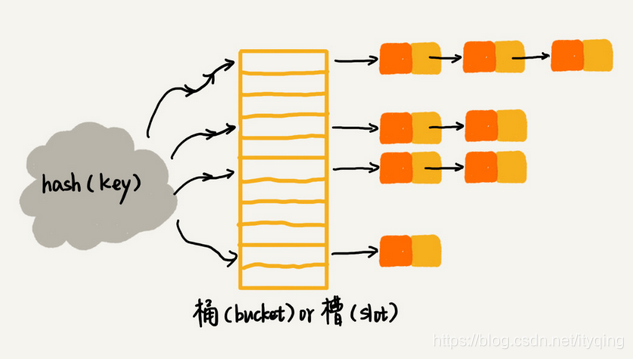
連結串列法:
連結串列法是一種更加常用的雜湊衝突解決辦法,相比開放定址法,它要簡單很多。我們來看這個圖,在散列表中,每個"桶(bucket) "或者"槽(slot) "會對應一條連結串列,所有雜湊值相同的元素我們都放到相同槽位對應的連結串列中。