
How to Visualize Your Recurrent Neural Network with Attention in Keras
Now for the interesting part: the decoder. For any given character at position t in the sequence, our decoder accepts the encoded sequence h=(h1,...,hT) as well as the previous hidden state st-1(shared within the decoder cell) and character yt-1. Our decoder layer will output y=(y1,...,yT)(the characters in the standardized date). Our overall architecture is summarized in Figure 7.
Equations
As shown in Figure 6, the decoder is quite complicated. So let’s break it down into the steps executed by the decoder cell when trying to predict character t.In the following equations, the capital letter variables represent trainable parameters (Note that I have dropped the bias terms for brevity.)
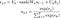
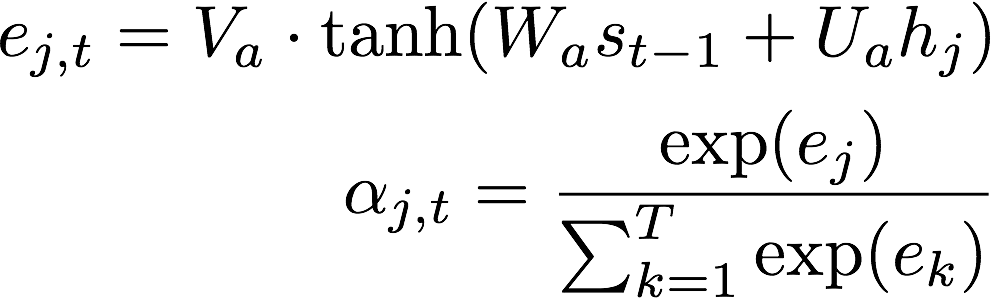
- Calculate the attention probabilities
α=(α1,…,αT)based on the encoded sequence and the internal hidden state of the decoder cell,st-1. These are shown in Equation 1 and Equation 2.
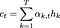

2. Calculate the context vector which is the weighted sum of the encoded sequence with the attention probabilities. Intuitively, this vector summarizes the importance of the different encoded characters in predicting the t-th character.

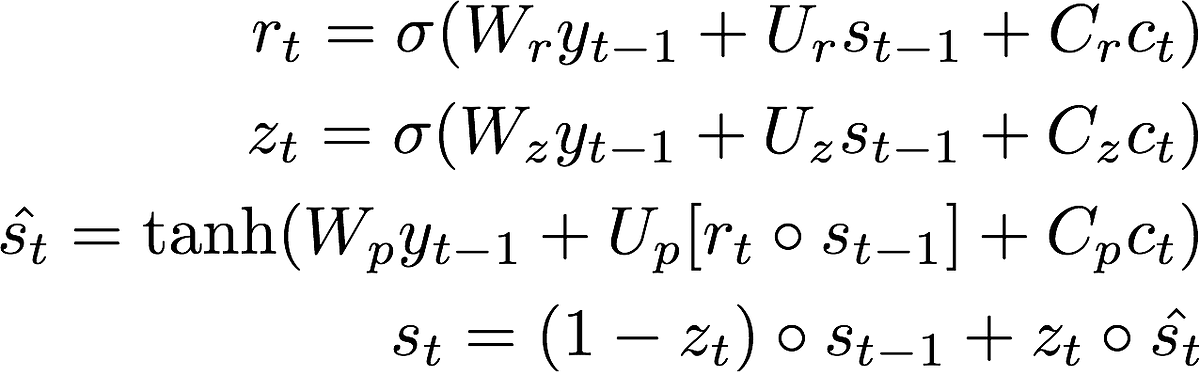
3. We then update our hidden state. If you are familiar with the equations of an LSTM cell, these might be ring a bell as the reset gate, r, update gate, z, and the proposal state. We use the reset gate to control how much information from the previous hidden state st-1is used to create a proposal hidden state. The update gate controls how we much of the proposal we use in the new hidden state st. (Confused? See step by step walk through of LSTM equations)
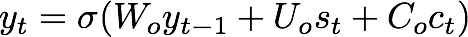
4. Calculate the t-th character using a simple one layer neural network using the context, hidden state, and previous character. This is a modification from the paper which uses a maxout layer. Since we are trying to keep things as simple as possible this works fine!
Equations 1–8 are applied for every character in the encoded sequence to produce a decoded sequence y which represents the probability of a translated character at each position.
Code
Our custom layer is implemented in . This part is somewhat complicated in particular because of the manipulations we need to make for vectorized operations acting on the complete encoded sequence. It will make more sense when you think about it. I promise it will become easier the more you look at the equations and the code simultaneously.
A minimal custom Keras layer has to implement a few methods: __init__, compute_ouput_shape, build and call. For completeness, we also implement get_config which allows you to load the model back into memory easily. In addition to these, a Keras recurrent layer implements a step method that will hold all the computations of our cell.
First let us break down boiler-plate layer code:
__init__is what is called when the Layer is first instantiated. It sets functions that will eventually initialize the weights, regularizers, and constraints. Since the output of our layer is a sequence, we hard codeself.return_sequences=True.buildis called when we runModel.compile(…). Since our model is quite complicated, you can see there are a ton of weights to initialize here. The callself.add_weightautomatically handles initializing the weights and setting them as trainable within the model. Weights with the subscriptaare used to calculate the context vector (step 1 and 2). Weights with the subscriptr,z,pwill calculate the new hidden states from step 3. Finally, weights with the subscriptowill calculate the output of the layer.- Some convenience functions are implemented as well: (a)
compute_output_shapewill calculate output shapes for any given input; (b)get_configlet’s us load the model using just a saved file (once we are done training)
Now for the cell logic:
- By default, each execution of the cell only has information from the previous time step. Since we need to access the entire encoded sequence within the cell, we need to save it somewhere. Therefore, we make a simple modification in
call. The only way I could find to do this was to set the sequence being fed into the cell asself.xso that we can access it later:
Now we need to think vectorized: The _time_distributed_dense function calculates the last term of Equation 1 for all the elements of the encoded sequence.
- We now walk through the most important part of the code, that is in
stepwhich executes the cell logic. Recall thatstepis applied to every element of the input sequence.
In this cell we want to access the previous character ytm and hidden state stm which is obtained from states in line 4.
Think vectorized: we manipulate stm to repeat it for the number of characters we have in our input sequence.
On lines 11–18 we implement a version of equation 1 that does the calculations on all the characters in the sequence at once.
In lines 24–28 we have implemented Equation 2 in the vectorized form for the whole sequence. We use repeat to allow us to divide every time step by the respective sums.
To calculate the context vector, we need to keep in mind that self.x_seq and at have a “batch dimension” and therefore we need to use batch_dot to avoid doing the multiplication over that dimension. The squeeze operation just removes left-over dimensions. This is done in lines 33–37.
The next few lines of code are a more straightforward implementation of equations 4 –8.
Now we think a bit ahead: We would like to calculate those fancy attention maps in Figure 1. To do this, we need a “toggle” that returns the attention probabilities at.
Training
Data
Any good learning problem should have training data. In this case, it’s easy enough thanks to the Faker library which can generate fake dates with ease. I also use the Babel library to generate dates in different languages and formats as inspired by rasmusbergpalm/normalization. The script will generate some fake data and I won’t bore you with the details but invite you to poke around or to make it better.
The script also generates a vocabulary that will convert characters into integers so that the neural network can understand it. Also included is a script in to read and prepare data for the neural network to consume.
Model
This simple model with a bidirectional LSTM and the decoder we wrote above is implemented in . You can run it using where I have set some default arguments (Readme has more information). I’d recommend training on a machine with a GPU as it can be prohibitively slow on a CPU-only machine.
If you want to skip the training part, I have provided some weights in
Visualization
Now the easy part. For the visualizer implemented in , we need to load the weights in twice: Once with the predictive model, and the other to obtain the probabilities. Since we implemented the model architecture in models/NMT.py we can simply call the function twice:
from models.NMT import simpleNMT
predictive_model = simpleNMT(...)
predictive_model.load_weights(..., return_probabilities=False)
probability_model = simpleNMT(..., return_probabilities=True)
probability_model.load_weights(...)
To simply use the implemented visualizer, you can type:
python visualizer.py -h
to see available command line arguments.
Example visualizations
Let us now examine the attentions we generated from probability_model. The predictive_model above returns the translated date that you see on the y-axis. On the x-axis is our input date. The map shows us which input characters (on the x-axis) were used in the prediction of the output character on the y-axis. The brighter the white, the more weight that character had. Here are some I thought were quite interesting.
A correct example which doesn’t pay attention to unnecessary information like days of the week:
相關推薦
How to Visualize Your Recurrent Neural Network with Attention in Keras
Now for the interesting part: the decoder. For any given character at position t in the sequence, our decoder accepts the encoded sequence h=(h1,...,hT) as
How to build your own Neural Network from scratch in Python
How to build your own Neural Network from scratch in PythonA beginner’s guide to understanding the inner workings of Deep LearningMotivation: As part of my
How to Create a Simple Neural Network in Python
Neural networks (NN), also called artificial neural networks (ANN) are a subset of learning algorithms within the machine learning field that are loosely b
How to build your own ubuntu image with docker?
一. Build a ubuntu image and install sshd 1. Pull ubuntu docker pull ubuntu:14.04 2. Create Dockerfile FROM ubuntu:14.04 #updat
How to structure your project and manage static resources in React Native
How to structure your project and manage static resources in React NativeReact and React Native are just frameworks, and they do not dictate how we should
How to train your Neural Networks in parallel with Keras and Apache Spark
Apache Spark on IBM Watson StudioNow, we will finally train our Keras model using the experimental Keras2DML API. To be able to execute the following code,
論文《Chinese Poetry Generation with Recurrent Neural Network》閱讀筆記
code employ 是個 best rec AS Coding ack ase 這篇文章是論文‘Chinese Poetry Generation with Recurrent Neural Network’的閱讀筆記,這篇論文2014年發表在EMNLP。 ABSTRA
轉載 -- How To Optimize Your Site With GZIP Compression
// 下面這篇文章講的非常不錯,看完了 https://betterexplained.com/articles/how-to-optimize-your-site-with-gzip-compression/ // Content-Encoding, 定義 fr
轉載 -- How To Optimize Your Site With HTTP Caching
https://betterexplained.com/articles/how-to-optimize-your-site-with-http-caching/ // Caching Tutorial for Web Authors and Webmasters // 下面
Recurrent Neural Network for Text Classification with Multi-Task Learning
引言 Pengfei Liu等人在2016年的IJCAI上發表的論文,論文提到已存在的網路都是針對單一任務進行訓練,但是這種模型都存在問題,即缺少標註資料,當然這是任何機器學習任務都面臨的問題。 為了應對資料量少,常用的方法是使用一個無監督的預訓練模型,比如詞向量,實驗中也取得了不錯
How to make your iOS apps more secure with SSL pinning
swift 和 obj-c 完成 ssl 的寫法如下: We can start by instantiating an NSURLSession object with the default session configuration. Swift self.urlSession = NSURLSes
Routing in React Native apps and how to configure your project with React
Tab Navigator implements a type of navigation that exists in native iOS for many years already. Recently, Android added it to its Material design patterns
How to use Paperspace to train your Deep Neural Networks
First, you have to sign up for the service. One tip here: students of the fast.ai course get a promo code, which is worth $15. That’s up to about 30 hours
Tech Talk: How to Power Your Databases to the Next Level with AI
In this talk on databases powered by artificial intelligence, we will describe its design and implementation. Hint: we use unsupervis
論文:用RNN書寫及識別漢字, Drawing and Recognizing Chinese Characters with Recurrent Neural Network
論文地址:用RNN書寫及識別漢字 摘要 目前識別漢字的通常方法是使用CNN模型,而識別線上(online)漢字時,CNN需要將線上手寫軌跡轉換成像影象一樣的表示。文章提出RNN框架,結合LSTM和GRU。包括識別模型和生成模型(即自動生成手寫體漢字),基於端到端,直接處理序列結構,不
How to Visualize Time Series Residual Forecast Errors with Python
Tweet Share Share Google Plus Forecast errors on time series regression problems are called resi
How to Get Your First Data Science Job: Interview with Michael Galarnyk
Knowing data science is great, but getting a job at it can be quite a challenge. Today I have a special guest and he is going to reveal the secret you
<轉>How to Encourage Your Child's Interest in Science and Tech
sim challenge table nic options https fun developed advice How to Encourage Your Child‘s Interest in Science and Tech This week’s Ask-A-D
How To run OAI eNB (No S1) with USRP X310(1)
end analyze cep tel linu lin mod str reat How To run OAI eNB (No S1) with USRP X310 1.Things need to be done 1.1 Install Ubun
How to choose your OS
嘗試 情況下 不必要 工具 情況 效率 linux系統 安裝 linux 我最開始使用電腦時用的是Windows系統。 後來聽說有一個叫作Linux的系統,是開源免費的,而且工作效率還高,所以對它很感興趣,以至於還有點反感Windows,為此還瘋狂的安裝各種Li