【ML--05】第五課 如何做特徵工程和特徵選擇
阿新 • • 發佈:2019-01-12
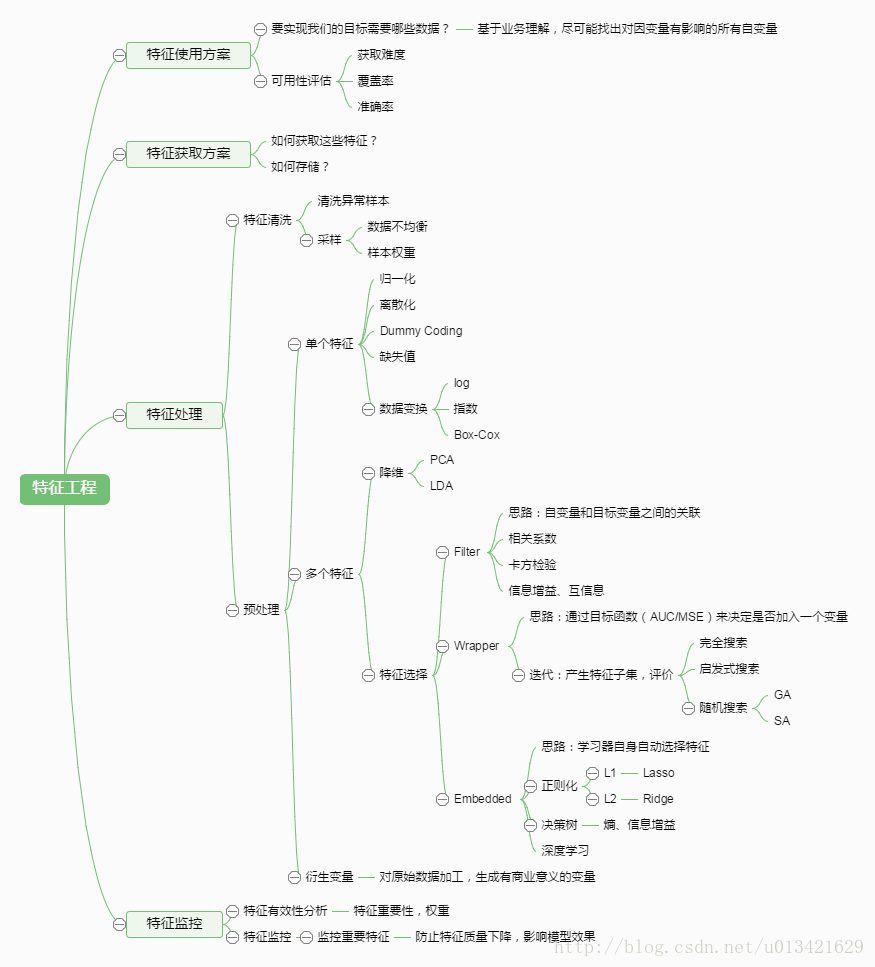
一、如何做特徵工程?
1.排序特徵:基於7W原始資料,對數值特徵排序,得到1045維排序特徵
2. 離散特徵:將排序特徵區間化(等值區間化、等量區間化),比如採用等量區間化為1-10,得到1045維離散特徵
3. 計數特徵:統計每一行中,離散特徵1-10的個數,得到10維計數特徵
4. 類別特徵編碼:將93維類別特徵用one-hot編碼
5. 交叉特徵:特徵之間兩兩融合,x+y、x-y、x*y、x^2+y^2等,由於時間複雜度較高,暫時跳過
二、如何做特徵選擇?
多維特徵一方面可能會導致維數災難,另一方面很容易導致過擬合,因此需要做降維處理,常見的降維方法有奇異值分解SVD, PCA( PCA 提假設資料呈高斯分佈),t-SNE(計算複雜度很高)。
除了降維,特徵選擇的方法很多:最大資訊係數(MIC)、皮爾森相關係數(衡量變數間的線性相關性)、正則化方法(L1,L2)、基於模型的特徵排序方法。比較高效的是最後一種方法,即基於學習模型的特徵排序方法,這種方法有一個好處:模型學習的過程和特徵選擇的過程是同時進行的,因此我們採用這種方法。
基於決策樹的演算法(如 random forest,boosted tree)在模型訓練完成後可以輸出特徵的重要性,我們用 xgboost 來做特徵選擇,xgboost 是 boosted tree 的一種實現,效率和精度都很高,在各類資料探勘競賽中被廣泛使用。