
Kafka叢集partitions/replicas預設分配解析
1. Kafka叢集partition replication預設自動分配分析
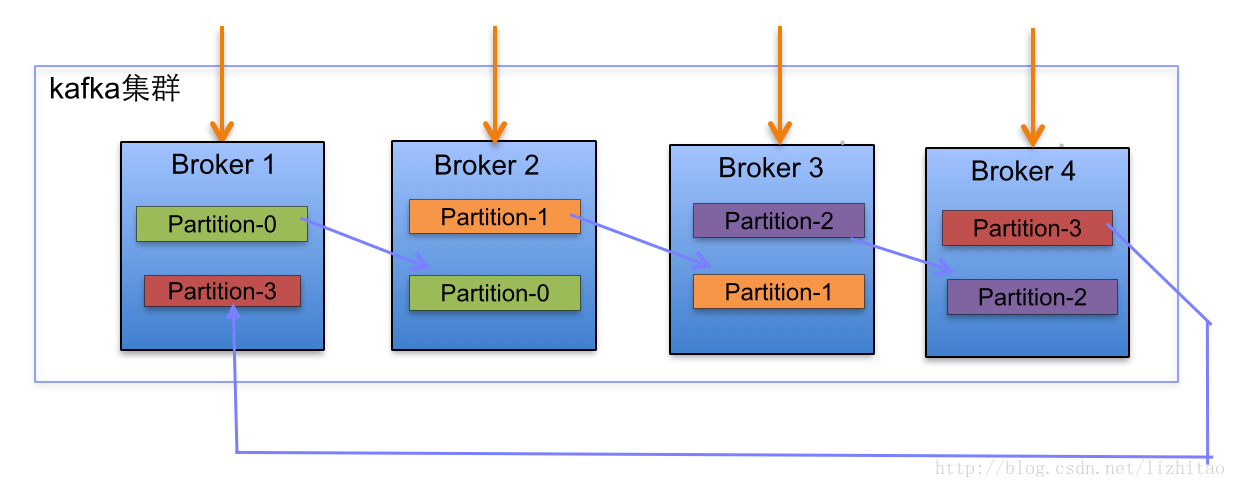
下面以一個Kafka叢集中4個Broker舉例,建立1個topic包含4個Partition,2 Replication;資料Producer流動如圖所示:
(1)
(2)當叢集中新增2節點,Partition增加到6個時分佈情況如下:
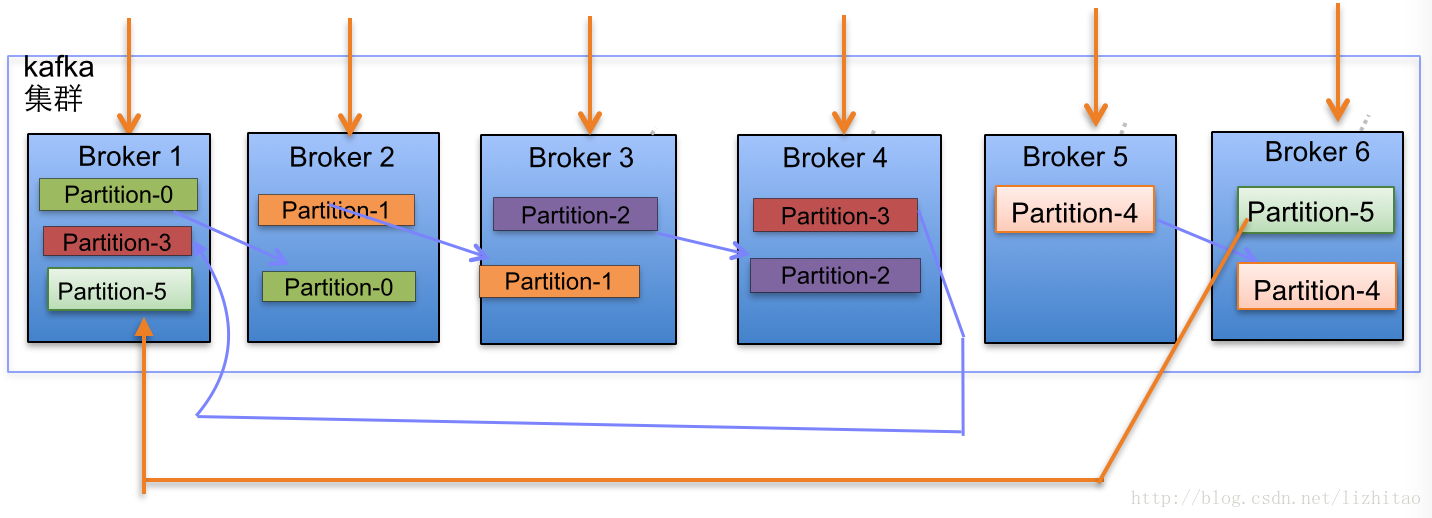
副本分配邏輯規則如下:
- 在Kafka叢集中,每個Broker都有均等分配Partition的Leader機會。
- 上述圖Broker Partition中,箭頭指向為副本,以Partition-0為例:broker1中parition-0為Leader,Broker2中Partition-0為副本。
- 上述圖種每個Broker(按照BrokerId有序)依次分配主Partition,下一個Broker為副本,如此迴圈迭代分配,多副本都遵循此規則。
- 將所有N Broker和待分配的i個Partition排序.
- 將第i個Partition分配到第(i mod n)個Broker上.
- 將第i個Partition的第j個副本分配到第((i + j) mod n)個Broker上.
相關推薦
Kafka叢集partitions/replicas預設分配解析
1. Kafka叢集partition replication預設自動分配分析 下面以一個Kafka叢集中4個Broker舉例,建立1個topic包含4個Partition,2 Replication
如何為Kafka叢集選擇合適的Topics/Partitions數量
這是許多kafka使用者經常會問到的一個問題。本文的目的是介紹與本問題相關的一些重要決策因素,並提供一些簡單的計算公式。 越多的分割槽可以提供更高的吞吐量 首先我們需要明白以下事實:在kafka中,單個patition是kafka並行操作的最小單元。在pro
如何為Kafka叢集選擇合適的Partitions數量
這是許多kafka使用者經常會問到的一個問題。本文的目的是介紹與本問題相關的一些重要決策因素,並提供一些簡單的計算公式。文章目錄 越多的分割槽可以提供更高的吞吐量 首先我們需要明白以下事實:在kafka中,單個patition是kafka並行操作的最小單元。在producer和broker端,向每一個
Kafka叢集內複製功能深入剖析
Kafka是一個分散式釋出訂閱訊息系統。由LinkedIn開發並已經在2011年7月成為apache頂級專案。kafka在LinkedIn, Twitte等許多公司都得到廣泛使用,主要用於:日誌聚合,訊息佇列,實時監控等。 0.8版本開始,kafka支援叢集內複製,從而提高可用性和系統穩定性,這篇文章主要概
Kafka叢集配置---Windows版
Kafka叢集配置---Windows版 Kafka是一種高吞吐量的分散式釋出訂閱的訊息佇列系統,Kafka對訊息進行儲存時是通過tipic進行分組的。今天我們僅實現Kafka叢集的配置。 前言 最近研究kafka,發現網上很多關於kafka的介紹都是基於Linux作業
centos7中kafka叢集環境搭建部署
一、前期準備 1、下載kafka安裝包 官方下載地址:http://kafka.apache.org/downloads.html kafka_2.11-2.0.0.tgz 2、準備好要安裝的叢集環境的目標機器(3檯安裝centos7系統) 3、將下載好的壓縮包
大資料學習之路94-kafka叢集安裝
解壓 Kafka 安裝包 修改配置檔案 config/server.properties vi server.properties broker.id=0 //為依次增長的:0、1、2、3、4,叢集中唯一id log.dirs=/kafkaData/logs // Kafka
kafka叢集安裝步驟
準備工作: 安裝好zookeeper叢集 一、上傳並解壓 1. cd /usr/kafka (沒有目錄的話自己建立) 2. rz 3. tar -zxvf kafka_2.12-1.1.0.tgz 二、2.修改配置檔案 /usr/kafka/kafka_2.12-1.
SpringCloud從入門到進階(三)——原始碼探究Eureka叢集之replicas的unavailable故障
內容 本節從原始碼的角度探討了Eureka控制檯中為何replicas(副本)顯示unavailable(不可用)的原因。在原始碼層級解讀了Eureka Server的replicas是如何解析,以及replica的狀態是如何判定。 版本 IDE:IDEA 2017.2.2 x64 JDK
安裝部署Kafka叢集
kafka是一個開源的分散式訊息訂閱系統(訊息中介軟體) 安裝過程 1.下載kafka_2.11-0.10.1.0.gz(ps:千萬不要下錯了,博主就是下到了src檔案上去了,kafka中的zookeeper起不起來) 2.上傳至/usr/local/src 3.解壓縮,並且移動到上級目錄 4.進入
Java架構-KafKa叢集安裝詳細步驟
最近在使用Spring Cloud進行分散式微服務搭建,順便對整合KafKa的方案做了一些總結,今天詳細介紹一下KafKa叢集安裝過程: 1.在根目錄建立kafka資料夾(service1、service2、service3都建立) [[email protected]
11月21日雲棲精選夜讀 | 20條關於Kafka叢集應對高吞吐量的避坑指南
Apache Kafka是一款流行的分散式資料流平臺,它已經廣泛地被諸如New Relic(資料智慧平臺)、Uber、Square(移動支付公司)等大型公司用來構建可擴充套件的、高吞吐量的、高可靠的實時資料流系統。 熱點熱議 20條關於Kafka叢集應對高吞吐量的避坑指南 作者:技術小能手
kafka叢集訊息格式之V0版本到V2版本的平滑過渡詳解-kafka 商業環境實戰
版權宣告:本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。版權宣告:禁止轉載,歡迎學習。QQ郵箱地址:[email protected],如有任何商業交流,可隨時聯絡。 1 Kafk
Linux系統下kafka叢集環境的搭建
1:搭建kafka叢集環境需要安裝JDK、Zookeeper叢集環境 JDK的安裝可以參考https://mp.csdn.net/postedit/84196901這篇部落格 Zookeeper叢集環境的安裝可以參考https://mp.csdn.net/postedit/84201320這
docker-compose安裝kafka叢集及管理監控工具
編寫docker-compose檔案配置zk 和kafka叢集 #vim kafka.yml version: '2'services: zoo1: image: zooke
Zookeeper叢集搭建和Kafka叢集的搭建
Zookeeper!!! 一、Zookeeper叢集搭建步驟 0)叢集規劃 在hadoop01、hadoop02和hadoop03三個節點上部署Zookeeper。 1)解壓安裝 (1)解壓zookeeper安裝包到/home/hadoop/insatll/目錄下 [[email
kafka叢集Controller競選與責任設計思路架構詳解-kafka 商業環境實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。期待加入IOT時代最具戰鬥力的團隊。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡。
kafka叢集Broker端基於Reactor模式請求處理流程深入剖析-kafka商業環境實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。期待加入IOT時代最具戰鬥力的團隊。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡。
kafka叢集Producer基本資料結構及工作流程深入剖析-kafka 商業環境實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。期待加入IOT時代最具戰鬥力的團隊。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡
kafka叢集基於永續性指標進行效能調優實踐-kafka 商業環境實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。期待加入IOT時代最具戰鬥力的團隊。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡