
從快取行出發理解volatile變數、偽共享False sharing、disruptor
volatile關鍵字
當變數被某個執行緒A修改值之後,其它執行緒比如B若讀取此變數的話,立刻可以看到原來執行緒A修改後的值
注:普通變數與volatile變數的區別是volatile的特殊規則保證了新值能立即同步到主記憶體,以及每次使用前可以立即從記憶體重新整理,即一個執行緒修改了某個變數的值,其它執行緒讀取的話肯定能看到新的值;
普通變數:
寫命中:當處理器將運算元寫回到一個記憶體快取的區域時,它首先會檢查這個快取的記憶體地址是否在快取行中,如果不存在一個有效的快取行,則處理器將這個運算元寫回到快取,而不是寫回到記憶體,這個操作被稱為寫命中。
|
術語 |
英文單詞 |
描述 |
|
共享變數 |
在多個執行緒之間能夠被共享的變數被稱為共享變數。共享變數包括所有的例項變數,靜態變數和陣列元素。他們都被存放在堆記憶體中,Volatile只作用於共享變數。 |
|
|
記憶體屏障 |
Memory Barriers |
是一組處理器指令,用於實現對記憶體操作的順序限制。 備註: In the Java Memory Model a volatile field has a store barrier inserted after a write to it and a load barrier inserted before a read of it. |
|
緩衝行 |
Cache line |
快取中可以分配的最小儲存單位。處理器填寫快取線時會載入整個快取線,需要使用多個主記憶體讀週期。 |
|
原子操作 |
Atomic operations |
不可中斷的一個或一系列操作。 |
|
快取行填充 |
cache line fill |
當處理器識別到從記憶體中讀取運算元是可快取的,處理器讀取整個快取行到適當的快取(L1,L2,L3的或所有) |
|
快取命中 |
cache hit |
如果進行快取記憶體行填充操作的記憶體位置仍然是下次處理器訪問的地址時,處理器從快取中讀取運算元,而不是從記憶體。 |
|
寫命中 |
write hit |
當處理器將運算元寫回到一個記憶體快取的區域時,它首先會檢查這個快取的記憶體地址是否在快取行中,如果不存在一個有效的快取行,則處理器將這個運算元寫回到快取,而不是寫回到記憶體,這個操作被稱為寫命中。 |
|
寫缺失 |
write misses the cache |
一個有效的快取行被寫入到不存在的記憶體區域。 |
單核CPU快取結構

單核CPU快取
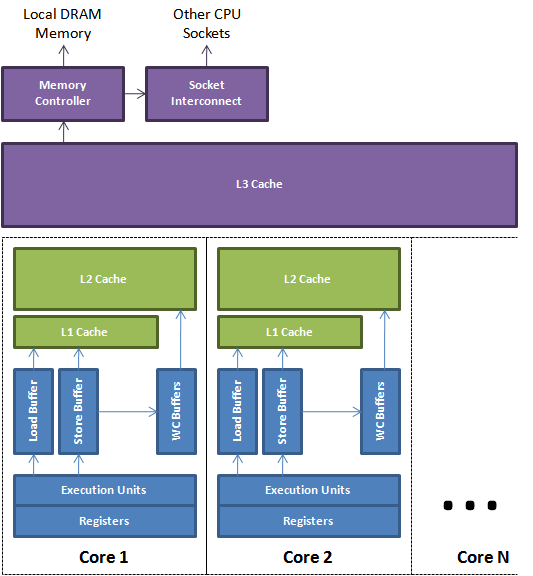
多核CPU快取
所謂快取航就是快取中可以分配的最小儲存單位。
處理器填寫快取線時會載入整個快取線,需要使用多個主記憶體讀週期。
下面降到偽快取時會介紹,多核CPU、記憶體的快取系統;
Information transfer between the cache and the memory is in terms of complete cache lines, rather than individual bytes. Thus if the program needs a particular byte, the entire cache line containing that byte is obtained from the memory. For example, suppose that the cache of Figure 2 was being used and the program fetches the word (two bytes) at location 0004736. If none of the cache lines contain the 16 bytes stored in addresses 0004730 through 000473F, then these 16 bytes are transferred from the memory to one of the cache lines. Because of the spatial locality of the program, we expect that other values in the cache line thus loaded will be referenced in the near future.
Volatile的實現原理
那麼Volatile是如何來保證可見性的呢?在x86處理器下通過工具獲取JIT編譯器生成的彙編指令來看看對Volatile進行寫操作CPU會做什麼事情。
|
Java程式碼: |
instance = new Singleton();//instance是volatile變數 |
|
彙編程式碼: |
0x01a3de1d: movb $0x0,0x1104800(%esi); 0x01a3de24: lock addl $0x0,(%esp); |
有volatile變數修飾的共享變數進行寫操作的時候會多第二行彙編程式碼,通過查IA-32架構軟體開發者手冊可知,lock字首的指令在多核處理器下會引發了兩件事情
- 將當前處理器快取行的資料會寫回到系統記憶體。
- 這個寫回記憶體的操作會引起在其他CPU裡快取了該記憶體地址的資料無效。
Lock字首指令會引起處理器快取回寫到記憶體。Lock字首指令導致在執行指令期間,聲言處理器的 LOCK# 訊號。在多處理器環境中,LOCK# 訊號確保在聲言該訊號期間,處理器可以獨佔使用任何共享記憶體。(因為它會鎖住匯流排,導致其他CPU不能訪問匯流排,不能訪問匯流排就意味著不能訪問系統記憶體),但是在最近的處理器裡,LOCK#訊號一般不鎖匯流排,而是鎖快取,畢竟鎖匯流排開銷比較大。在8.1.4章節有詳細說明鎖定操作對處理器快取的影響,對於Intel486和Pentium處理器,在鎖操作時,總是在總線上聲言LOCK#訊號。但在P6和最近的處理器中,如果訪問的記憶體區域已經快取在處理器內部,則不會聲言LOCK#訊號。相反地,它會鎖定這塊記憶體區域的快取並回寫到記憶體,並使用快取一致性機制來確保修改的原子性,此操作被稱為“快取鎖定”,快取一致性機制會阻止同時修改被兩個以上處理器快取的記憶體區域資料。
一個處理器的快取回寫到記憶體會導致其他處理器的快取無效。IA-32處理器和Intel 64處理器使用MESI(修改,獨佔,共享,無效)控制協議去維護內部快取和其他處理器快取的一致性。在多核處理器系統中進行操作的時候,IA-32 和Intel 64處理器能嗅探其他處理器訪問系統記憶體和它們的內部快取。它們使用嗅探技術保證它的內部快取,系統記憶體和其他處理器的快取的資料在總線上保持一致。例如在Pentium和P6 family處理器中,如果通過嗅探一個處理器來檢測其他處理器打算寫記憶體地址,而這個地址當前處理共享狀態,那麼正在嗅探的處理器將無效它的快取行,在下次訪問相同記憶體地址時,強制執行快取行填充。
Volatile的使用優化
著名的Java併發程式設計大師Doug lea在JDK7的併發包裡新增一個佇列集合類LinkedTransferQueue,他在使用Volatile變數時,用一種追加位元組的方式來優化隊列出隊和入隊的效能。
追加位元組能優化效能?這種方式看起來很神奇,但如果深入理解處理器架構就能理解其中的奧祕。讓我們先來看看LinkedTransferQueue這個類,它使用一個內部類型別來定義佇列的頭佇列(Head)和尾節點(tail),而這個內部類PaddedAtomicReference相對於父類AtomicReference只做了一件事情,就將共享變數追加到64位元組。我們可以來計算下,一個物件的引用佔4個位元組,它追加了15個變數共佔60個位元組,再加上父類的Value變數,一共64個位元組。
為什麼追加64位元組能夠提高併發程式設計的效率呢? 因為對於英特爾酷睿i7,酷睿, Atom和NetBurst, Core Solo和Pentium M處理器的L1,L2或L3快取的快取記憶體行是64個位元組寬,不支援部分填充快取行,這意味著如果佇列的頭節點和尾節點都不足64位元組的話,處理器會將它們都讀到同一個快取記憶體行中,在多處理器下每個處理器都會快取同樣的頭尾節點,當一個處理器試圖修改頭接點時會將整個快取行鎖定,那麼在快取一致性機制的作用下,會導致其他處理器不能訪問自己快取記憶體中的尾節點,而佇列的入隊和出隊操作是需要不停修改頭接點和尾節點,所以在多處理器的情況下將會嚴重影響到佇列的入隊和出隊效率。Doug lea使用追加到64位元組的方式來填滿高速緩衝區的快取行,避免頭接點和尾節點載入到同一個快取行,使得頭尾節點在修改時不會互相鎖定。
那麼是不是在使用Volatile變數時都應該追加到64位元組呢?不是的。在兩種場景下不應該使用這種方式。第一:快取行非64位元組寬的處理器,如P6系列和奔騰處理器,它們的L1和L2快取記憶體行是32個位元組寬。第二:共享變數不會被頻繁的寫。因為使用追加位元組的方式需要處理器讀取更多的位元組到高速緩衝區,這本身就會帶來一定的效能消耗,共享變數如果不被頻繁寫的話,鎖的機率也非常小,就沒必要通過追加位元組的方式來避免相互鎖定。
/**
head of the queue */
private transient final PaddedAtomicReference
< QNode > head;
/**
tail of the queue */
private transient final PaddedAtomicReference
< QNode > tail;
static final class PaddedAtomicReference
< T > extends AtomicReference
< T > {
//
enough padding for 64bytes with 4byte refs
Object
p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T
r) {
super(r);
}
}
public class AtomicReference
< V > implements java.io.Serializable
{
private volatile V
value;
}
|
為什麼追加64位元組能夠提高併發程式設計的效率呢? 因為對於英特爾酷睿i7,酷睿, Atom和NetBurst, Core Solo和Pentium M處理器的L1,L2或L3快取的快取記憶體行是64個位元組寬,不支援部分填充快取行,這意味著如果佇列的頭節點和尾節點都不足64位元組的話,處理器會將它們都讀到同一個快取記憶體行中,在多處理器下每個處理器都會快取同樣的頭尾節點,當一個處理器試圖修改頭接點時會將整個快取行鎖定,那麼在快取一致性機制的作用下,會導致其他處理器不能訪問自己快取記憶體中的尾節點,而佇列的入隊和出隊操作是需要不停修改頭接點和尾節點,所以在多處理器的情況下將會嚴重影響到佇列的入隊和出隊效率。Doug lea使用追加到64位元組的方式來填滿高速緩衝區的快取行,避免頭接點和尾節點載入到同一個快取行,使得頭尾節點在修改時不會互相鎖定。
那麼是不是在使用Volatile變數時都應該追加到64位元組呢?不是的。在兩種場景下不應該使用這種方式。第一:快取行非64位元組寬的處理器,如P6系列和奔騰處理器,它們的L1和L2快取記憶體行是32個位元組寬。第二:共享變數不會被頻繁的寫。因為使用追加位元組的方式需要處理器讀取更多的位元組到高速緩衝區,這本身就會帶來一定的效能消耗,共享變數如果不被頻繁寫的話,鎖的機率也非常小,就沒必要通過追加位元組的方式來避免相互鎖定。
Java併發程式設計實踐寫道:“一個理解volatile變數好的方法:想想它們的行為與SynchrosizedInteger類相似,只不過用get和set方法取代了對volatile變數的讀寫操作。然而訪問volatile變數的操作不會加鎖,也就不會引起執行緒的阻塞,這使volatile相對於synchronized而言,只是輕量級的同步機制”
Memory is stored within the cache system in units know as cache lines. Cache lines are a power of 2 of contiguous bytes which are typically 32-256 in size. The most common cache line size is 64 bytes. False sharing is a term which applies when threads unwittingly impact the performance of each other while modifying independent variables sharing the same cache line. Write contention on cache lines is the single most limiting factor on achieving scalability for parallel threads of execution in an SMP system. I’ve heard false sharing described as the silent performance killer because it is far from obvious when looking at code.
class {int x ,int y} x和y被放在同一個高速快取區,如果一個執行緒修改x;那麼另外一個執行緒修改y,必須等待x修改完成後才能實施。

L1 Cache(一級快取)是CPU第一層快取記憶體,分為資料快取和指令快取。內建的L1快取記憶體的容量和結構對CPU的效能影響較大,不過高速緩衝儲存器均由靜態RAM組成,結構較複雜,在CPU管芯面積不能太大的情況下,L1級快取記憶體的容量不可能做得太大。一般伺服器CPU的L1快取的容量通常在32—4096KB。
L2 Cache 都在CPU中
L3 Cache(三級快取),分為兩種,早期的是外接,現在的都是內建的。而它的實際作用即是,L3快取的應用可以進一步降低記憶體延遲,同時提升大資料量計算時處理器的效能。降低記憶體延遲和提升大資料量計算能力對遊戲都很有幫助。而在伺服器領域增加L3快取在效能方面仍然有顯著的提升。比方具有較大L3快取的配置利用實體記憶體會更有效,故它比較慢的磁碟I/O子系統可以處理更多的資料請求。具有較大L3快取的處理器提供更有效的檔案系統快取行為及較短訊息和處理器佇列長度。
從圖中可以看出為多核共享的
To achieve linear scalability with number of threads, we must ensure no two threads write to the same variable or cache line. Two threads writing to the same variable can be tracked down at a code level. To be able to know if independent variables share the same cache line we need to know the memory layout, or we can get a tool to tell us. Intel VTune is such a profiling tool. In this article I’ll explain how memory is laid out for Java objects and how we can pad out our cache lines to avoid false sharing.
可見每個cpu核心或者執行緒都會可能往同一個快取行寫資料;並且對共享變數,同時cpu核心會有各自的快取行
雖然兩個執行緒修改各種獨立變數,但是因為這些獨立變數被放在同一個快取記憶體區,效能就影響了。測試結果。
當多核CPU執行緒同時修改在同一個快取記憶體行各自獨立的變數時,會不自不覺地影響效能,這就發生了偽共享False sharing,偽共享是效能的無聲殺手。
當多核CPU執行緒同時修改在同一個快取記憶體行各自獨立的變數時,會不自不覺地影響效能,這就發生了偽共享False sharing,偽共享是效能的無聲殺手。
這裡強調多核,是因為單核CPU模擬出的多執行緒不會嚴格意義上同時訪問快取行,所以效能影響不大
解決方便是將快取記憶體剩餘的位元組填充填滿(pad),確保不發生多個欄位被擠入一個快取記憶體區,下面測試結果圖就是和填充後效能比較。
實現位元組填充的框架有 Disruptor,在RingBuffer中實現填充。關於Disruptor可見infoQ這個視訊,用1毫秒的延時得到100K+ TPS吞吐量,
JDK的ArrayQueue並行環境不見得是最快的,該視訊後面討論很多,讓人大跌眼鏡啊,開放原始碼多有好處啊,別人能發現你不能發現的漏洞。
Disruptor
Disruptor沒有像JDK的LinkedBlockQueue等那樣使用鎖,針對CPU快取記憶體進行了優化。
原來我們以為多個執行緒同時寫一個類的欄位會發生爭奪,這是多執行緒基本原理,所以使用了鎖機制,保證這個共用欄位(資源)能夠某個時刻只能一個執行緒寫,但是這樣做的壞處是:有可能發生死鎖。
比如1號執行緒先後訪問共享資源A和B;而2號執行緒先後訪問共享資源B和A,因為在資源A和資源B都有鎖,那麼1號在訪問資源A時,資源A上鎖了,準備訪問資源B,但是無法訪問,因為與此同時;而2號執行緒在訪問資源B,資源B鎖著呢,正準備訪問資源A,發現資源A被1號執行緒鎖著呢,結果彼此無限等待彼此下去,死鎖類似邏輯上自指悖論。
所以,鎖是壞的,破壞效能,鎖是併發計算的大敵。
我們回到佇列上,一把一個佇列有至少兩個執行緒:生產者和消費者,這就具備了資源爭奪的前提,這兩個執行緒一般彼此守在佇列的進出兩端,表面上好像沒有訪問共享資源,實際上佇列存在兩個共享資源:佇列大小或指標.
除了共享資源寫操作上存在資源爭奪問題外,Disruptor的LMAX團隊發現Java在多核CPU情況下有偽共享問題:
CPU會把資料從記憶體載入到快取記憶體中 ,這樣可以獲得更好的效能,快取記憶體預設大小是64 Byte為一個區域,CPU機制限制只能一個CPU的一個執行緒訪問(寫)這個快取記憶體區。
CPU在將主記憶體中資料載入到高速緩衝時,如果發現被載入的資料不足64位元組,那麼就會載入多個數據,以填滿自己的64位元組,悲催就發生了,恰恰hotspot JVM中物件指標等大小都不會超過64位元組,這樣一個高速緩衝中可能載入了兩個物件指標,一個CPU一個高速緩衝,雙核就是兩個CPU各自一個高速緩衝,那麼兩個高速緩衝中各有兩個物件指標,都是指向相同的兩個物件。
因為一個CPU只能訪問(寫)自己快取記憶體區中資料,相當於給這個資料加鎖,那麼另外一個CPU同時訪問自己高速緩衝行中同樣資料時將會被鎖定不能訪問。
這就發生與鎖機制類似的效能陷進,Disruptor的解決辦法是填滿高速緩衝的64位元組,不是物件指標等資料不夠64位元組嗎?那麼加一些位元組填滿64位元組,這樣CPU將資料載入到高速緩衝時,就只能載入一個了,剛剛好啊。
所以,儘管兩個執行緒是在寫兩個不同的欄位值,也會因為雙核CPU底層機制發生偽裝的共享,並沒有真正共享,其實還是排他性的獨享。
現在我們大概知道RingBuffer是個什麼東東了:
1.ring buffer是一個大的陣列.
2.RingBuffer裡所有指標都是Java longs (64位元組) 不斷永遠向前計數,如後面圖,不斷在圓環中迴圈。
3.RingBuffer只有當前序列號,沒有終點序列號,其中資料不會被取出後消除,這樣以便實現從過去某個序列號到當前序列號的重放,這樣當消費者說沒有接受到生產者傳送的訊息,生產者還可以再次傳送,這點是一種原子性的“事務”機制。
This new pattern is an ideal foundation for any asynchronous event processing architecture where high-throughput and low-latency is required.
Concurrent execution of code is about two things, mutual exclusion and visibility of change.
Read and write operations require that all changes are made visible to other threads. However only contended write operations require the mutual exclusion of the changes.
Locks provide mutual exclusion and ensure that the visibility of change occurs in an ordered manner. Locks are incredibly expensive because they require arbitration when contended.
We will illustrate the cost of locks with a simple demonstration. The focus of this experiment is to call a function which increments a 64-bit counter in a loop 500 million
times. This can be executed by a single thread on a 2.4Ghz Intel Westmere EP in just 300ms if written in Java. The language is unimportant to this experiment and results will be similar across all languages with the same basic primitives.
Once a lock is introduced to provide mutual exclusion, even when the lock is as yet un-contended, the cost goes up significantly. The cost increases again, by orders of magnitude,
when two or more threads begin to contend. The results of this simple experiment are shown in the table below

However CAS operations are not free of cost. The processor must lock its instruction pipeline to ensure atomicity and employ a memory barrier to make the changes visible to other threads. CAS operations are available in Java by using the java.util.concurrent.Atomic* classes.
The processors need only guarantee that program logic produces the same results regardless of execution order.
barriter:make the memory state within a processor visible to other processors.
disruptor 是為了解決消費者大於生產者的問題
參考
相關推薦
從快取行出發理解volatile變數、偽共享False sharing、disruptor
volatile關鍵字 當變數被某個執行緒A修改值之後,其它執行緒比如B若讀取此變數的話,立刻可以看到原來執行緒A修改後的值 注:普通變數與volatile變數的區別是volatile的特殊規則保證了新值能立即同步到主記憶體,以及每次使用前可以立即從記憶體重新整理,
從Java視角理解偽共享(False Sharing)
從Java視角理解系統結構連載, 關注我的微博([url="http://weibo.com/coderplay"]連結[/url])瞭解最新動態從我的[url="http://coderplay.iteye.com/blog/1485760"]前一篇博文[/url]中, 我
從計算機的角度理解volatile關鍵字
極簡計算機發展史 我們知道,計算機CPU和記憶體的互動是最頻繁的,記憶體是我們的快取記憶體區。而剛開始使用者磁碟和CPU進行互動,CPU運轉速度越來越快,磁碟遠遠跟不上CPU的讀寫速度,才設計了記憶體,但是隨著CPU的發展,記憶體的讀寫速度也遠遠跟不上CPU的讀寫速度,因此,為了解決
呆呆鍵盤手11.13號學到的有關文字css、偽類選擇器、浮動的內容
1.文字css <ins></ins>下劃線標記 <del></del>刪除線標記 文字對齊:text-align-left/center/right 文字首行縮排:text-indent 單位px em
CSS3選擇器(基礎選擇器、屬性選擇器、偽類選擇器、選擇器策略)
《CSS3基本選擇器》 一、萬用字元選擇器(*)*{marigin:0;padding:0;}二、元素選擇器(E)li {background-color: grey;color: orange;}三、類選擇器(.className)四、id選擇器(#ID)#first
屬性選擇器、偽元素選擇器、結構性偽類選擇器
一、屬性選擇器 html: <body> <div id="box1">示例1</div> <div id="box2">示例2</div> <div id="box3">
從Java記憶體模型理解synchronized、volatile和final關鍵字
你是否真正理解並會用volatile, synchronized, final進行執行緒間通訊呢,如果你不能回答下面的幾個問題,那就說明你並沒有真正的理解: 1、對volatile變數的操作一定具有原子性嗎?(原子操作是不需要synchron
【Java併發程式設計】從CPU快取模型到JMM來理解volatile關鍵字
[toc] # 併發程式設計三大特性 ## 原子性 一個操作或者多次操作,要麼所有的操作全部都得到執行並且不會受到任何因素的干擾而中斷,**要麼所有的操作都執行,要麼都不執行**。 對於基本資料型別的訪問,讀寫都是原子性的【long和double可能例外】。 如果需要更大範圍的原子性保證,可以使用s
無法從命令行或調試器啟動服務,必須首先安裝Windows服務(使用installutil.exe),然後用ServerExplorer、Windows服務器管理工具或NET START命令啟動它
服務器管理 ima sta put 調試器 article 這一 microsoft war 以管理員身份打開cmd窗口 win7: 註冊服務命令 cd C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727 InstallUtil.ex
iOS 從實際出發理解多線程
參數表 兩個類 時間 ios 任務 基本 獲取 clas str 前言 多線程很多開發者多多少少相信也都有了解,以前有些東西理解的不是很透,慢慢的積累之後,這方面的東西也需要自己好好的總結一下。多線程從我剛接觸到iOS的時候就知道這玩意挺重要的
Linux 124課程 2、從命令行管理文件
無法 img 運行 多級 命令 linux mage string sage 文件目錄 / 代表根目錄 整個系統全部在根目錄中/boot 存放啟動配置文件 建議,單獨做成一個分區/dev
無法從命令行或調試器啟動服務,必須首先安裝Windows服務(使用installutil.exe),然後用ServerExplorer、Windows服務器管理工具或NET START命令啟動它
ros 啟動 令行 問題 就是 但是 .com explorer net 1.以管理員身份運行cmd 2.安裝windows服務 cd C:\Windows\Microsoft.NET\Framework\v4.0.30319(InstallUtil.exe的路徑,註意
基於JVM原理、JMM模型和CPU快取模型深入理解Java併發程式設計
許多以Java多執行緒開發為主題的技術書籍,都會把對Java虛擬機器和Java記憶體模型的講解,作為講授Java併發程式設計開發的主要內容,有的還深入到計算機系統的記憶體、CPU、快取等予以說明。實際上,在實際的Java開發工作中,僅僅瞭解併發程式設計的建立、啟動、管理和通訊等基本知識還是不夠的。一
效能、負載、壓力測試——從效能測試角度理解系統開發
引言 最近,由於舊機器下線,我對過去部署的一些服務做了遷移,順帶對新部署的服務做了一個簡單的效能測試。在實施過程中,我發現自己對很多效能指標的理解很不清晰,對於併發數、壓力、吞吐量、延遲等概念,通常是以望文生義的方式使用。對於系統應該關注什麼樣的效能指標,認識也不完整。為此,我閱讀了wiki百科以及一些部落
從路由原理出發,深入閱讀理解react-router 4.0的原始碼
react-router等前端路由的原理大致相同,可以實現無重新整理的條件下切換顯示不同的頁面。路由的本質就是頁面的URL發生改變時,頁面的顯示結果可以根據URL的變化而變化,但是頁面不會重新整理。通過前端路由可以實現單頁(SPA)應用,本文首先從前端路由的原
JAVA併發-從快取一致性說volatile 講的很好
學過計算機組成原理的一定知道,為了解決記憶體速度跟不上CPU速度這個問題,在CPU的設計中加入了快取機制,快取的速度介於CPU和主存之間。在進行運算的時候,CPU將需要的資料對映一份在快取中,然後直接操作位於快取中的資料,操作完畢後再將快取中的資料寫回到主存。這在單執行緒環境中是沒有任何問題的。但是在多執行
JAVA併發-從快取一致性說volatile
學過計算機組成原理的一定知道,為了解決記憶體速度跟不上CPU速度這個問題,在CPU的設計中加入了快取機制,快取的速度介於CPU和主存之間。在進行運算的時候,CPU將需要的資料對映一份在快取中,然後直接操作位於快取中的資料,操作完畢後再將快取中的資料寫回到主存。這在單執行緒環境
【陌上軒客】技術領域:涉獵Java、Go、Python、Groovy 等語言,高效能、高併發、高可用、非同步與訊息中介軟體、快取與資料庫、分散式與微服務、容器和自動化等領域; 興趣愛好:籃球,騎行,讀書,發呆; 職業規劃:勵志成為一名出色的伺服器端系統架構師。
陌上軒客 技術領域:涉獵Java、Go、Python、Groovy 等語言,高效能、高併發、高可用、非同步與訊息中介軟體、快取與資料庫、分散式與微服務、容器和自動化等領域; 興趣愛好:籃球,騎行,讀書,發呆; 職業...
從一個奇怪的錯誤出發理解 Vue 基本概念
有人在學習 Vue 過程中遇到一個奇怪的問題,併為之迷惑不已——為什麼這麼簡單的一個專案都會出錯。 這是一個簡單到幾乎不能再簡單的 Vue 專案,在 index.html 的 body 中有一個 id 為 app 的 div 根元素,其中包含一個 my-com
centos學習:理解環境變數 臨時、永久
臨時變數操作 name=dai echo $name name=$name"chen" //連線 echo $name #include <stdio.h> int main(i