
【轉】C++動態繫結和虛擬函式表vtable (動態實現原理)
關於C++內部如何實現多型,對程式設計師來說即使不知道也沒關係,但是如果你想加深對多型的理解,寫出優秀的程式碼,那麼這一節就具有重要的意義。 我們知道,函式呼叫實際上是執行函式體中的程式碼。函式體是記憶體中的一個程式碼段,函式名就表示該程式碼段的首地址,函式執行時就從這裡開始。說得簡單一點,就是必須要知道函式的入口地址,才能成功呼叫函式。
找到函式名對應的地址,然後將函式呼叫處用該地址替換,這稱為函式繫結,或符號決議。
一般情況下,在編譯期間(包括連結期間)就能完成符號決議,不用等到程式執行時再進行額外的操作,這稱為靜態繫結。如果編譯期間不能完成符號決議,就必須在程式執行期間完成,這稱為動態繫結。
非虛成員函式屬於靜態繫結:編譯器在編譯期間,根據指標(或物件)的型別完成了繫結。
而對於虛擬函式,知道指標的型別也無濟於事。假設 func() 為虛擬函式,p 的型別為 A,那麼 p->func() 可能呼叫 A 類的函式,也可能呼叫 B、C 類的函式,不能根據指標 p 的型別對函式重新命名。也就是說,虛擬函式在編譯期間無法繫結。
單一繼承
虛擬函式表 vtable
如果一個類包含了虛擬函式,那麼在建立物件時會額外增加一張表,表中的每一項都是虛擬函式的入口地址。這張表就是虛擬函式表,也稱為 vtable。 可以認為虛擬函式表是一個數組。 為了把物件和虛擬函式表關聯起來,編譯器會在物件中安插一個指標,指向虛擬函式表的起始位置。
例如對於下面的繼承關係:
class A {
protected:
int a1;
int a2;
public:
virtual void display() {
cout << "A::display()";
}
virtual void clone() {
cout << "A::clone()";
}
};
class B : public A {
protected:
int b;
public:
virtual void display() {
cout << "B::display()";
} 各個類的記憶體分佈如下所示:
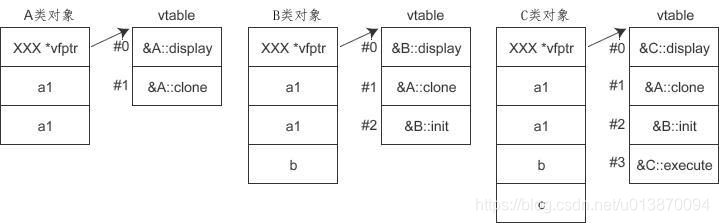
通過上圖可以發現,對於單繼承,不管繼承層次有多深,只需要增加一個指標即可,不會隨著繼承層次的加深讓物件揹負越來越多的指標。而且,基類中的虛擬函式在 vtable 中的索引是固定的,不會隨著繼承層次的增加而改變,例如 display() 的索引值始終是 0。當呼叫虛擬函式時,藉助指標 vfptr 完成一次間接轉換,就可以得到虛擬函式的入口地址。
對於虛擬函式 display(),它在 vtable 中的索引為 0,發生呼叫時:
p->display();
編譯器內部會發生轉換,產生類似下面的程式碼:
( *( p->vptr )[0] ) (p); //*( p->vptr )[0]是函式入口地址
這條語句沒有用到與指標 p 的型別有關的資訊,也沒有用到 Name Mangling 演算法。程式執行後會執行這條語句,完成函式的呼叫,這就是動態繫結。
編譯器在編譯期間會備足各種資訊,並完成相應的轉換,程式執行後只需要執行簡單的程式碼就能找到函式入口地址,進而呼叫函式。
init() 函式在 vtable 中的索引為 2,發生呼叫時:
p->init();
編譯器內部的轉換為:
( *( p->vptr )[2] ) (p);
對於不同的虛擬函式,僅僅改變索引值即可。
當派生類有多重繼承時,虛擬函式表的結構會變得複雜,尤其是有虛繼承時,還會增加虛基類表,更加讓人抓狂,這裡我們就不分析了,有興趣的讀者可以自行研究。
(1)派生類完全擁有基類的記憶體佈局,並保證其完整性。
派生類可以看作是完整的基類的Object再加上派生類自己的Object。如果基類中沒有虛成員函式,那麼派生類與具有相同功能的非派生類將不帶來任何效能上的差異。另外,一定要保證基類的完整性。實際記憶體佈局由編譯器自己決定,VS裡,把虛指標放在最前邊,接著是基類的Object,最後是派生類自己的object。舉個栗子:
class A
{
int b;
char c;
};
class A1 :public A
{
char a;
};
int main()
{
cout << sizeof(A) << " " << sizeof(A1) << endl;
return 0;
}
輸出是什麼?
答案:8 12
A類的話,一個int,一個char,5B,記憶體對齊一下,8B。A1的話,一個int,兩個char,記憶體對齊一下,也是8B。不對嗎?
我說了,要保證基類物件的完整性。那麼一定要保證A1類前面的幾個位元組一定要與A類完全一樣。也就是說,A類作為記憶體補齊的3個位元組也是要出現在A1裡面的。也就是說,A類是這樣的:int(4B)+char(1B)+padding(3B)=8B,A1類:int(4B)+char(1B)+padding(3B)+char(1B)+padding(3B)=12B。
(2)虛指標怎麼處理?
還是視編譯器而定,VS是永遠把vptr放在物件的最前邊。如果基類中含有虛擬函式,那麼處理情況與上邊一樣。可是,如果基類中沒有虛擬函式而派生類有的話,那麼如果把vptr放在派生類的前邊的話,將會導致派生類中基類成分並不在最前邊。這將帶來什麼問題呢?舉慄:假設A不含虛,而A1含。
A *pA;
A1 obj_A1;
pA=&obj_A1;
果A1完全包含A並且A位於A1的最前邊,那麼編譯器只需要把&obj_A1直接賦給pA就可以了。如果不是呢?編譯器就需要把&obj_A1+sizeof(vptr)賦給pA了。
2 多重繼承
說結論:VS的記憶體佈局是按照宣告順序排列記憶體。再舉個栗子:
class point2d
{
public:
virtual ~point2d(){};
float x;
float y;
};
class point3d :public point2d
{
~point3d(){};
float z;
};
class vertex
{
public:
virtual ~vertex(){};
vertex* next;
};
class vertex3d :public point3d, public vertex
{
float bulabula;
};
int _tmain(int argc, _TCHAR* argv[])
{
cout << sizeof(point2d) << " " << sizeof(point3d) << " " << sizeof(vertex) << " " << sizeof(vertex3d) << endl;
return 0;
}
輸出: 12 16 8 24。
記憶體佈局:
point2d: vptr(4)+x(4)+y(4)=12B
point3d: vptr+x+y+z=16B
vertex: vptr+next=8B
vertex3d: vptr+x+y+z+vptr+next+bulabula=28B
為什麼需要多個虛指標?請往下看。
3 虛擬繼承
(1)為什麼要有“虛繼承”這樣的機制?
簡單講,虛繼承是為也防止“diamond”繼承所帶來的問題。也就是類A1、A2都繼承於A,類B又同時繼承於A1、A2。這樣一來,類B中就有兩份類A的成員了,這樣的程式無法通過編譯。我們改成這樣的形式:
class A
{
public:
int a;
virtual ~A();
virtual void fun(){cout<<"A"<<endl;}
};
class A1 :public virtual A
{
public:
int a1;
virtual void fun(){cout<<"A1"<<endl;}
};
class A2 :public virtual A
{
public:
int a2;
virtual void fun(){cout<<"A2"<<endl;}
};
class B :public A1,public A2 {
public:
int b;
virtual void fun(){cout<<"B"<<endl;}
virtual void funB(){};
};
這樣就能防止這樣的事情發生。
(2)虛擬繼承與普通繼承的區別:
普通繼承使得派生類每繼承一個基類便擁有一份基類的成員。而虛擬繼承會把通過虛擬繼承的那一部分,放在物件的最後。從而使得只擁有一份基類中的成員。虛擬物件的偏移量被儲存在Derived類的vtbl的this指向的上一個slot。比較難理解。下面我給你個栗子。
(3)虛擬繼承的記憶體佈局:
每個派生類會把其不變部分放在前面,共享部分放在後面。
上面四個類的大小是怎樣的呢?
int _tmain(int argc, _TCHAR* argv[])
{
cout << sizeof(A) << " " << sizeof(A1) << " " << sizeof(A2) << " " << sizeof(B) << endl;
return 0;
}
輸出:8 16 16 28
記憶體佈局:
A: vptr+a=8B
A1: vptr+a1+vptrA+a=16B
A2: vptr+a2+vptrA+a=16B
A3: vptr+a1+vptrA2+a2+b+vptrA+a=28B
上個草圖:
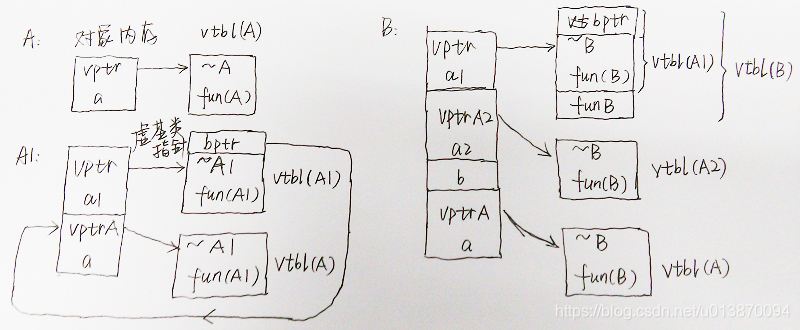
那究竟為什麼需要多個虛指標?將物件記憶體佈局和虛表結構搞清楚之後,答案是不是呼之欲出呢?
是的,因為這樣可以保證在將子類指標/引用轉換成基類指標時編譯器可以直接根據對像的記憶體佈局進行偏移,從而使得指向的第一個內容為虛指標,進而實現多型(根據靜態型別執行相應動作)。