
S3 Select and Glacier Select – Retrieving Subsets of Objects

|
Amazon Simple Storage Service (S3) stores data for millions of applications used by market leaders in every industry. Many of these customers also use Amazon Glacier
S3 Select
S3 Select, launching in preview now generally available, enables applications to retrieve only a subset of data from an object by using simple SQL expressions. By using S3 Select to retrieve only the data needed by your application, you can achieve drastic performance increases – in many cases you can get as much as a 400% improvement.
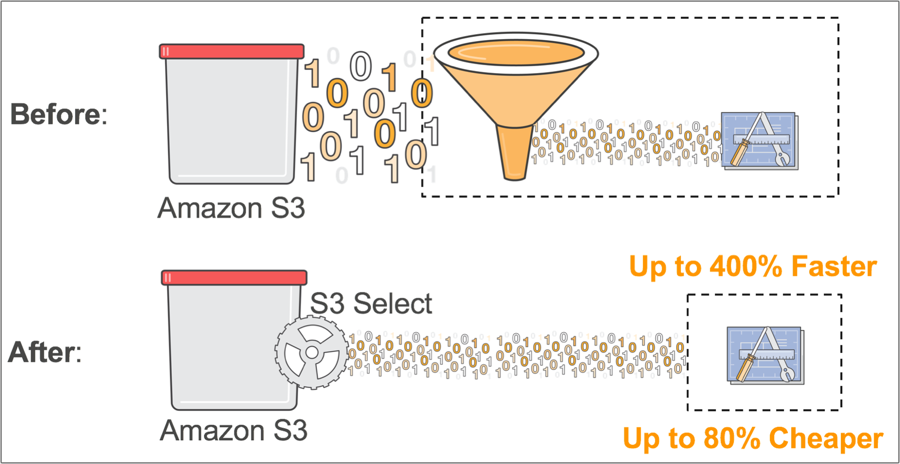
As an example, let’s imagine you’re a developer at a large retailer and you need to analyze the weekly sales data from a single store, but the data for all 200 stores is saved in a new GZIP-ed CSV every day. Without S3 Select, you would need to download, decompress and process the entire CSV to get the data you needed. With S3 Select, you can use a simple SQL expression to return only the data from the store you’re interested in, instead of retrieving the entire object. This means you’re dealing with an order of magnitude less data which improves the performance of your underlying applications.
Let’s look at a quick Python example, which shows how to retrieve the first column from an object containing data in CSV format.
import boto3
s3 = boto3.client('s3')
r = s3.select_object_content(
Bucket='jbarr-us-west-2',
Key='sample-data/airportCodes.csv',
ExpressionType='SQL',
Expression="select * from s3object s where s.\"Country (Name)\" like '%United States%'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}},
OutputSerialization = {'CSV': {}},
)
for event in r['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])Pretty cool!
We expect customers to use S3 Select to accelerate all sorts of applications. For example, this partial data retrieval ability is especially useful for serverless applications built with AWS Lambda. When we modified the Serverless MapReduce reference architecture to retrieve only the data needed using S3 Select we saw a 2X improvement in performance and an 80% reduction in cost.
Query pushdown using S3 Select is now supported with Spark, Hive and Presto in Amazon EMR. You can use this feature to push down the computational work of filtering large data sets for processing from the EMR cluster to Amazon S3, which can improve performance and reduce the amount of data transferred between Amazon EMR and Amazon S3.
Things To Know
Amazon Athena, Amazon Redshift, and Amazon EMR as well as partners like Cloudera, DataBricks, and Hortonworks will all support S3 Select.
Glacier Select
Some companies in highly regulated industries like Financial Services, Healthcare, and others, write data directly to Amazon Glacier to satisfy compliance needs like SEC Rule 17a-4 or HIPAA. Many S3 users have lifecycle policies designed to save on storage costs by moving their data into Glacier when they no longer need to access it on a regular basis. Most legacy archival solutions, like on premise tape libraries, have highly restricted data retrieval throughput and are unsuitable for rapid analytics or processing. If you want to make use of data stored on one of those tapes you might have to wait for weeks to get useful results. In contrast, cold data stored in Glacier can now be easily queried within minutes.
This unlocks a lot of exciting new business value for your archived data. Glacier Select allows you to to perform filtering directly against a Glacier object using standard SQL statements.
Glacier Select works just like any other retrieval job except it has an additional set of parameters you can pass in initiate job request. SelectParameters
Here a quick example:
import boto3
glacier = boto3.client("glacier")
jobParameters = {
"Type": "select", "ArchiveId": "ID",
"Tier": "Expedited",
"SelectParameters": {
"InputSerialization": {"csv": {}},
"ExpressionType": "SQL",
"Expression": "SELECT * FROM archive WHERE _5='498960'",
"OutputSerialization": {
"csv": {}
}
},
"OutputLocation": {
"S3": {"BucketName": "glacier-select-output", "Prefix": "1"}
}
}
glacier.initiate_job(vaultName="reInventSecrets", jobParameters=jobParameters)
Things To Know
Glacier Select is generally available in all commercial regions that have Glacier.
Glacier is priced in 3 dimensions.
- GB of Data Scanned
- GB of Data Returned
- Select Requests
Pricing for each dimension is determined by the speed at which you want your results returned: expedited (1-5 minutes), standard (3-5 hours), and bulk (5-12 hours).
Soon, in 2018, Athena will be integrated with Glacier using Glacier Select.
I hope you’re able to get started enhancing your applications or building new ones with these capabilities.
相關推薦
The used SELECT statements have a different number of columns???
自己 lin ack -o _id strong clas 之前 不一致 今天我們組就我一個人留守在這裏修復bug了,有點小悲傷啊,他們都問我能不能hold得住啊,我當然能hold得住啊; 在看一個入庫的存儲過程中,在數據庫運行的時候是沒問題的,項目已啟動,進行入庫操作就是
Angular 學習筆記 (Material Select and AutoComplete)
記入一些思考 : 這 2 個元件有點像,經常會搞混. select 的定位是選擇. 目前 select 最糟糕的一點是 not search friendly。 還有當需要 multiple select 很多很多時, 一定要開啟 options 來 unselect, 操作不友好. 再來
Oracle使用遊標更新資料 Oracle遊標之select for update和where current of 語句
Oracle使用遊標更新資料 2016年11月20日 13:15:49 hzwy23 閱讀數:5313 友情推廣 ###使用遊標修改資料 ####定義一個遊標,遊標名稱為 mycursor #####更新scott使用者中emp表中empno
UNION關鍵字報錯:ERROR 1222 (21000): The used SELECT statements have a different number of columns
今天進行總結時,發現這個錯誤,後來,發現這是由於union 造成。 在使用union時,有以下規則。 1.必須由兩條或者兩條以上的select語句組成,語句之間用關鍵字union分隔 2.每
The used select statements have a different number of columns解決辦法
1. 問題原因 這個異常出現在兩個表使用union all進行合併時遇到的, 表A存在的欄位數量和表B最初是一致的,包括欄位名字和型別都是一致,使用union all連線無異常; 後來由於需要在表B添加了一個新的欄位,導致兩張表的欄位在數量上不一致,出現了異常;
for each/in/of的解釋and example for each/in/of的解釋and example
for each/in/of的解釋and example for-of 迴圈:程式碼示例for (var value of myArray) {console.log(value
【轉載】 ABAP SELECT-INTO用法 SELECT @ (AT) 新語法 SELECT * INTO DATA(@IT_ITAB)
READ TABLE LT_ITAB INTO DATA(LS_ITAB) INDEX 1. 看起來實際上是在執行時宣告變數。 寫程式時一直沒有使用ABAP的新語法,今天記錄一下新語法的使用,總結不全,想到什麼就寫什麼,不喜勿噴! 找了個select,點了一下F1進去看看 先找個簡單
select dummy 與 select sysdate的區別
select dummy from dual ,select sysdate from dual之間的區別在哪裡呢; 下面來看一下: SQL> set autotra traceonly exp SQL> select dummy from dual; Execu
Brain-Computer Interfaces and Augmented Reality: A State of the Art
Brain-Computer Interfaces and Augmented Reality: A State of the Art 腦機介面和增強現實:最先進的技術 文章目錄 Brain-Computer Interfaces and Augmented R
leetcode [Divide and Conquer] No.315 Count of Smaller Numbers After Self
題目描述 You are given an integer array nums and you have to return a new counts array. The counts array has the property where counts
【SQL】INSERT INTO SELECT語句與SELECT INTO FROM語句
INSERT INTO SELECT語句與SELECT INTO FROM語句,都是將一個結果集插入到一個表中; #INSERT INTO SELECT語句 1、語法形式: Insert into Table2(field1,field2,…) select value1,value2,
嵌入式Linux網路程式設計,I/O多路複用,select()示例,select()客戶端,select()伺服器,單鏈表
文章目錄 1,IO複用select()示例 1.1 select()---net.h 1.2 select()---client.c 1.3 select()---sever.c 1.4 select()---linklist.h
獲取select 所有option &&select 移除和新增 選中的option
//獲取select 所有option 方法 var months= $("#addedmonths").map(function(){ return $(this).val(); }).get().join(", “) ; //select 移除和新增 選中的
【轉載】 ABAP SELECT-INTO用法 SELECT @ (AT) SELECT * INTO DATA(@IT_ITAB 新語法
寫程式時一直沒有使用ABAP的新語法,今天記錄一下新語法的使用,總結不全,想到什麼就寫什麼,不喜勿噴! 找了個select,點了一下F1進去看看 先找個簡單點的語法,因為程式要使用插入內表的操作,以前的步驟都是新建工作區,新建內表,再select,所以這裡直接進去INTO
Regina Barzilay, James Collins, and Phil Sharp join leadership of new effort on machine learning in health
Regina Barzilay and James Collins have been named the faculty co-leads of the Abdul Latif Jameel Clinic for Machine Learning in Health, or J-Clinic, effect
Apple Lost Innovation, Copies the Developer App and launches in WWDC Breach of Trust with…
Apple knows we cant create patent on software and now that they will go on and on copying any of the developer apps which we trust and submit and they will
Vision, Data and AI: Connecting the Factory of the Future
Artificial intelligence and the Internet of Things are helping companies make the factory of the future a reality by harnessing the power of machine vision
AI, Chatbots and Designing the Next Generation of Automated Customer Engagement
No matter how much sweetness or spin you add to it, early incarnations of AI-powered chatbots are the call centers of this generation. They're relatively i
Learning and Leading in the Era of Artificial Intelligence and Machine Learning, Part 1
Learning and Leading in the Era of Artificial Intelligence and Machine Learning, Part 1Wikimedia CommonsWith this 2-part blog series, I’ll explore the evol