
Python3網路爬蟲快速入門實戰解析
一 前言
強烈建議:請在電腦的陪同下,閱讀本文。本文以實戰為主,閱讀過程如稍有不適,還望多加練習。
本文的實戰內容有:
- 網路小說下載(靜態網站)
- 優美桌布下載(動態網站)
- 愛奇藝VIP視訊下載
二 網路爬蟲簡介
網路爬蟲,也叫網路蜘蛛(Web Spider)。它根據網頁地址(URL)爬取網頁內容,而網頁地址(URL)就是我們在瀏覽器中輸入的網站連結。比如:https://www.baidu.com/,它就是一個URL。
在講解爬蟲內容之前,我們需要先學習一項寫爬蟲的必備技能:審查元素(如果已掌握,可跳過此部分內容)。
1 審查元素
在瀏覽器的位址列輸入URL地址,在網頁處右鍵單擊,找到檢查。(不同瀏覽器的叫法不同,Chrome瀏覽器叫做檢查,Firefox瀏覽器叫做檢視元素,但是功能都是相同的)
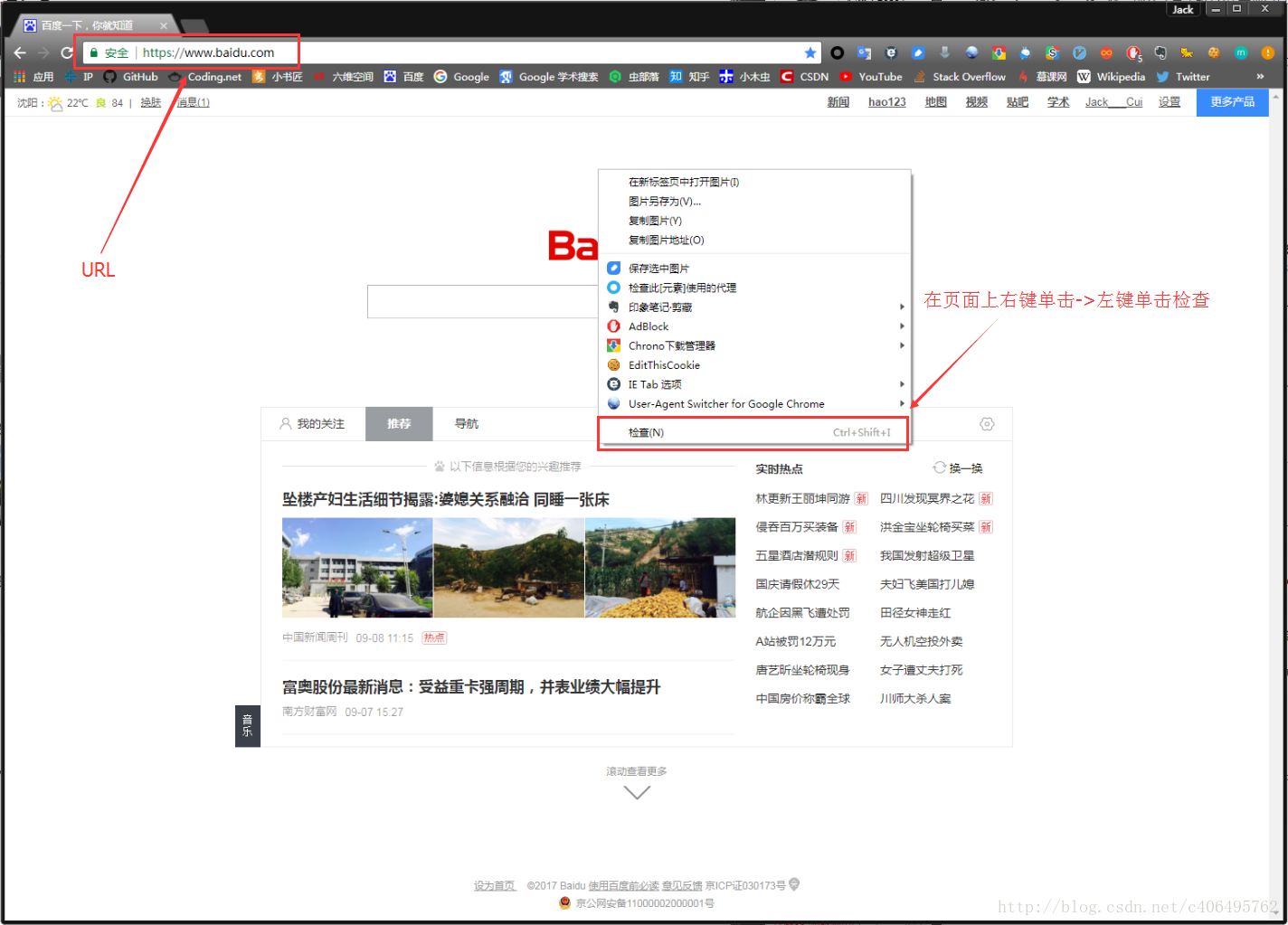
我們可以看到,右側出現了一大推程式碼,這些程式碼就叫做HTML。什麼是HTML?舉個容易理解的例子:我們的基因決定了我們的原始容貌,伺服器返回的HTML決定了網站的原始容貌。
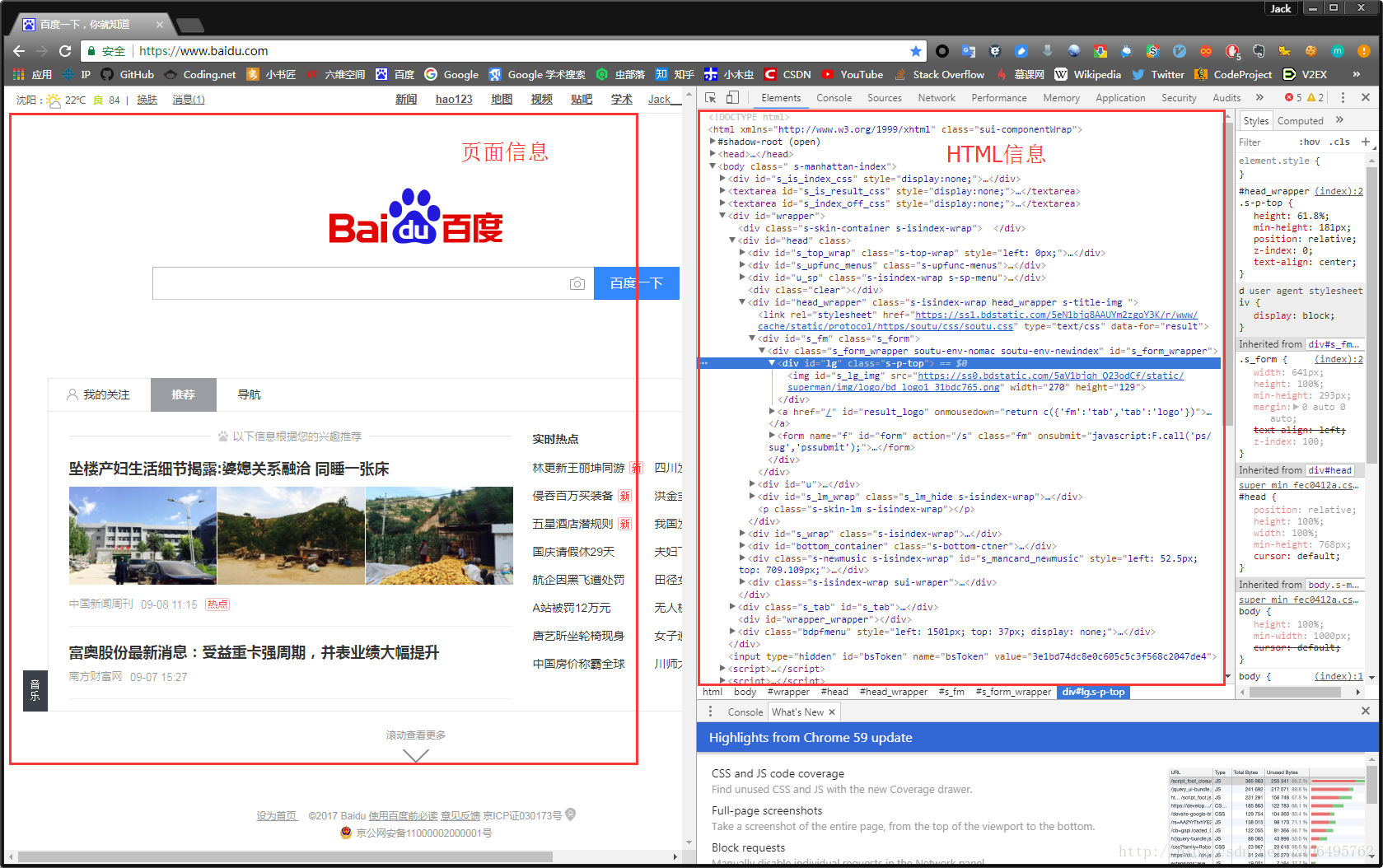
為啥說是原始容貌呢?因為人可以整容啊!扎心了,有木有?那網站也可以”整容”嗎?可以!請看下圖:
我能有這麼多錢嗎?顯然不可能。我是怎麼給網站”整容”的呢?就是通過修改伺服器返回的HTML資訊。我們每個人都是”整容大師”,可以修改頁面資訊。我們在頁面的哪個位置點選審查元素,瀏覽器就會為我們定位到相應的HTML位置,進而就可以在本地更改HTML資訊。
再舉個小例子:我們都知道,使用瀏覽器”記住密碼”的功能,密碼會變成一堆小黑點,是不可見的。可以讓密碼顯示出來嗎?可以,只需給頁面”動個小手術”!以淘寶為例,在輸入密碼框處右鍵,點選檢查。
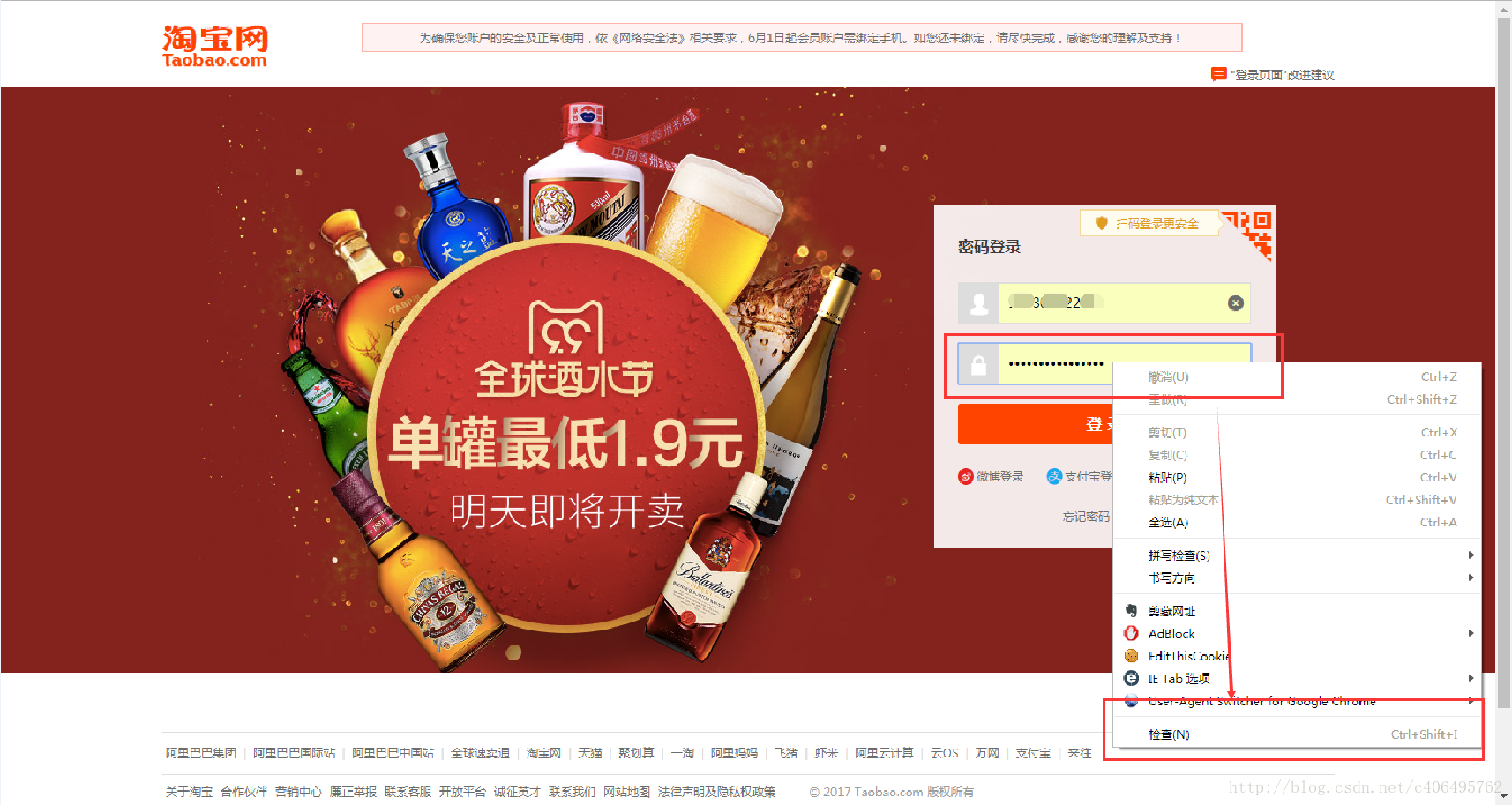
可以看到,瀏覽器為我們自動定位到了相應的HTML位置。將下圖中的password屬性值改為text屬性值(直接在右側程式碼處修改):
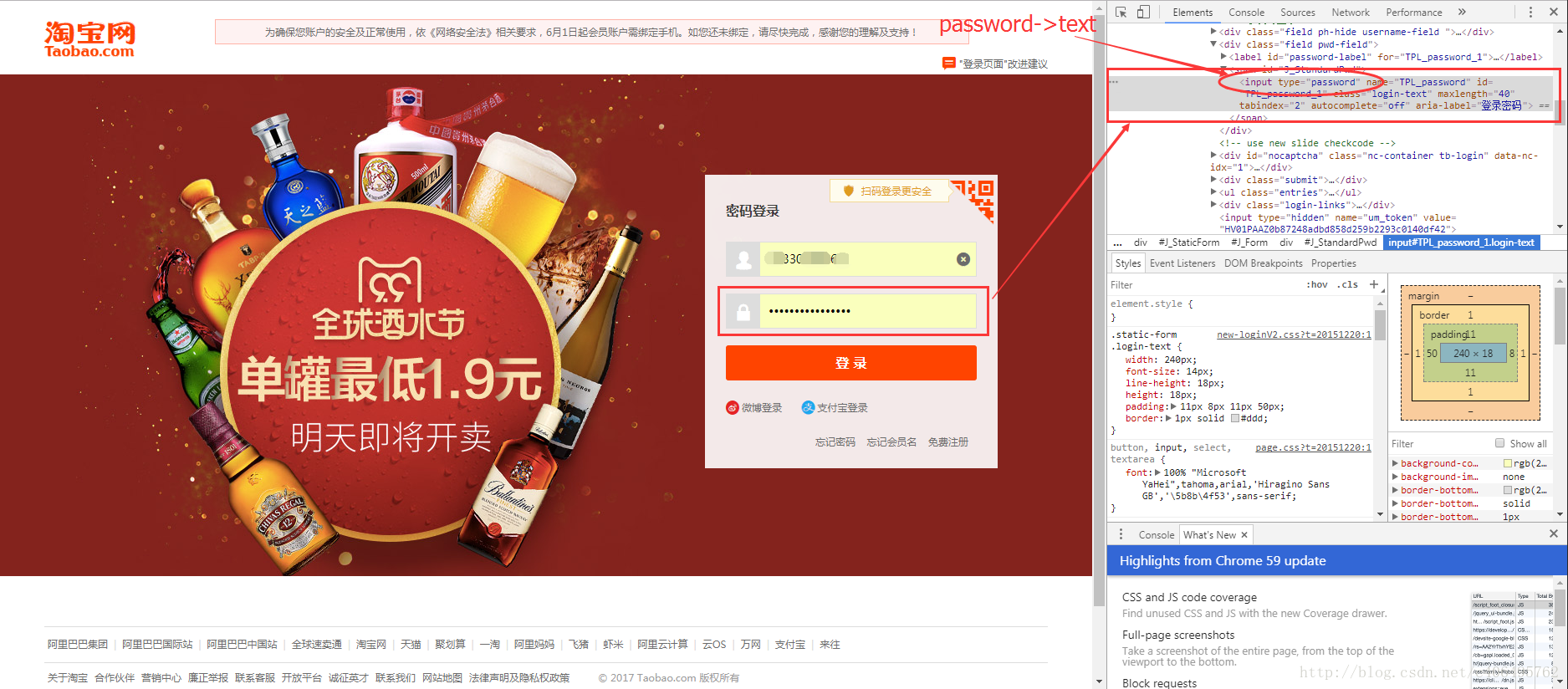
我們讓瀏覽器記住的密碼就這樣顯現出來了:
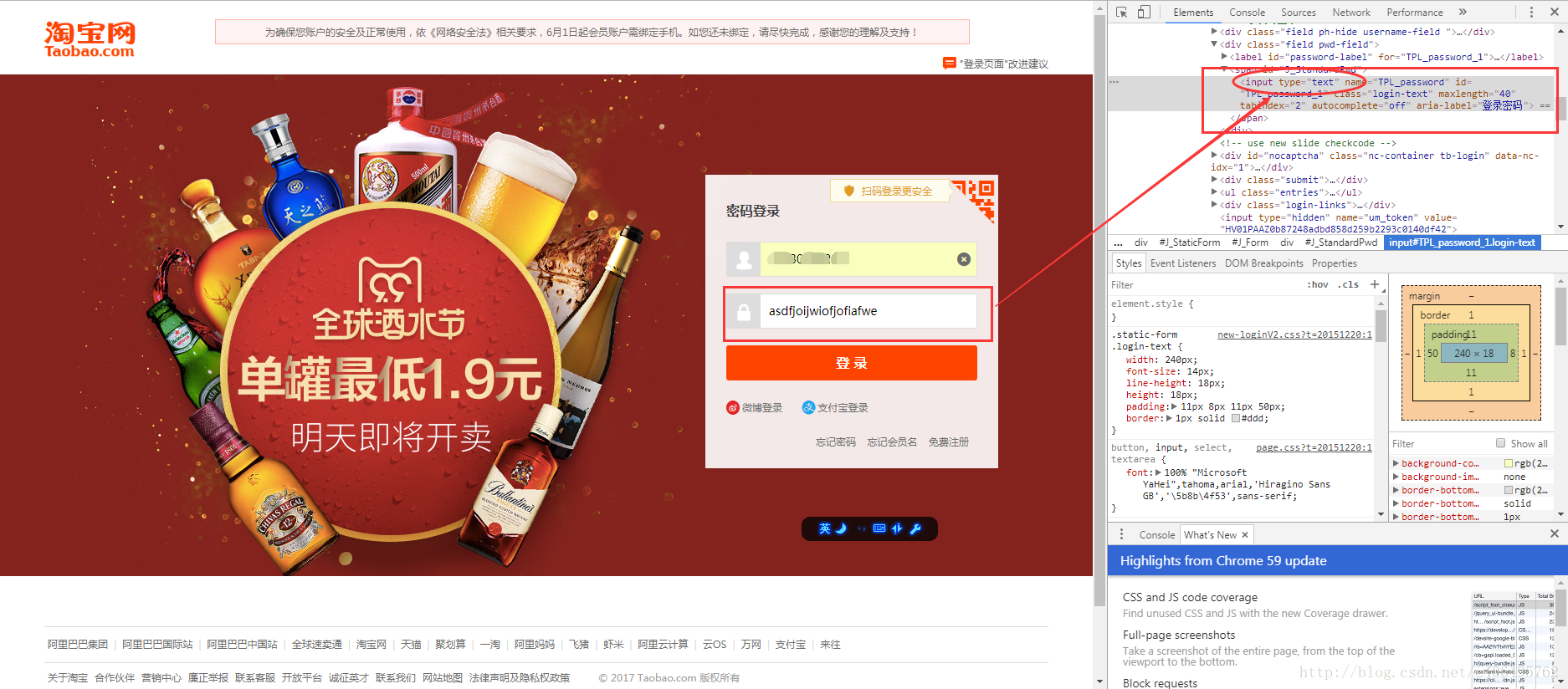
說這麼多,什麼意思呢?瀏覽器就是作為客戶端從伺服器端獲取資訊,然後將資訊解析,並展示給我們的。我們可以在本地修改HTML資訊,為網頁”整容”,但是我們修改的資訊不會回傳到伺服器,伺服器儲存的HTML資訊不會改變。重新整理一下介面,頁面還會回到原本的樣子。這就跟人整容一樣,我們能改變一些表面的東西,但是不能改變我們的基因。
2 簡單例項
網路爬蟲的第一步就是根據URL,獲取網頁的HTML資訊。在Python3中,可以使用urllib.request和requests進行網頁爬取。
- urllib庫是python內建的,無需我們額外安裝,只要安裝了Python就可以使用這個庫。
- requests庫是第三方庫,需要我們自己安裝。
requests庫強大好用,所以本文使用requests庫獲取網頁的HTML資訊。requests庫的github地址:https://github.com/requests/requests
(1) requests安裝
在cmd中,使用如下指令安裝requests:
pip install requests或者:
easy_install requests(2) 簡單例項
requests庫的基礎方法如下:
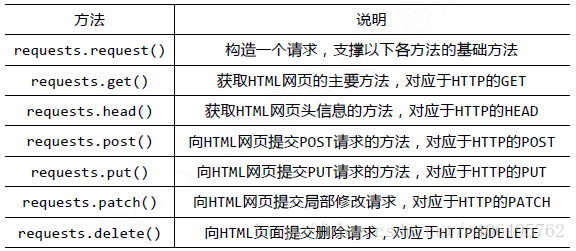
requests庫的開發者為我們提供了詳細的中文教程,查詢起來很方便。本文不會對其所有內容進行講解,摘取其部分使用到的內容,進行實戰說明。
首先,讓我們看下requests.get()方法,它用於向伺服器發起GET請求,不瞭解GET請求沒有關係。我們可以這樣理解:get的中文意思是得到、抓住,那這個requests.get()方法就是從伺服器得到、抓住資料,也就是獲取資料。讓我們看一個例子(以 www.gitbook.cn為例)來加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)requests.get()方法必須設定的一個引數就是url,因為我們得告訴GET請求,我們的目標是誰,我們要獲取誰的資訊。執行程式看下結果:
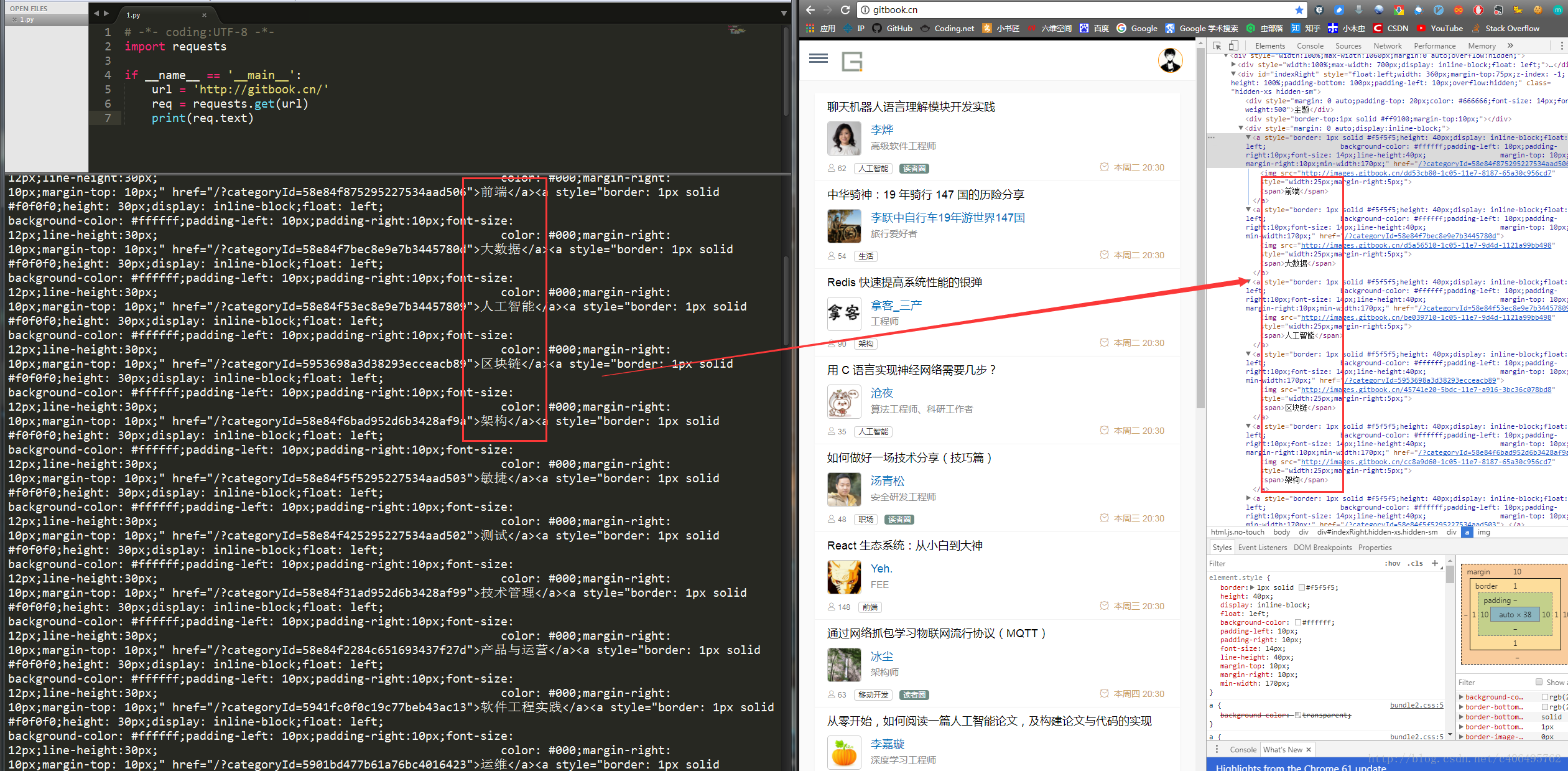
左側是我們程式獲得的結果,右側是我們在www.gitbook.cn網站審查元素獲得的資訊。我們可以看到,我們已經順利獲得了該網頁的HTML資訊。這就是一個最簡單的爬蟲例項,可能你會問,我只是爬取了這個網頁的HTML資訊,有什麼用呢?客官稍安勿躁,接下來進入我們的實戰正文。
三 爬蟲實戰
1 小說下載
(1) 實戰背景
筆趣看是一個盜版小說網站,這裡有很多起點中文網的小說,該網站小說的更新速度稍滯後於起點中文網正版小說的更新速度。並且該網站只支援線上瀏覽,不支援小說打包下載。因此,本次實戰就是從該網站爬取並儲存一本名為《一念永恆》的小說,該小說是耳根正在連載中的一部玄幻小說。PS:本例項僅為交流學習,支援耳根大大,請上起點中文網訂閱。
(2) 小試牛刀
我們先用已經學到的知識獲取HTML資訊試一試,編寫程式碼如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
print(req.text)執行程式碼,可以看到如下結果:
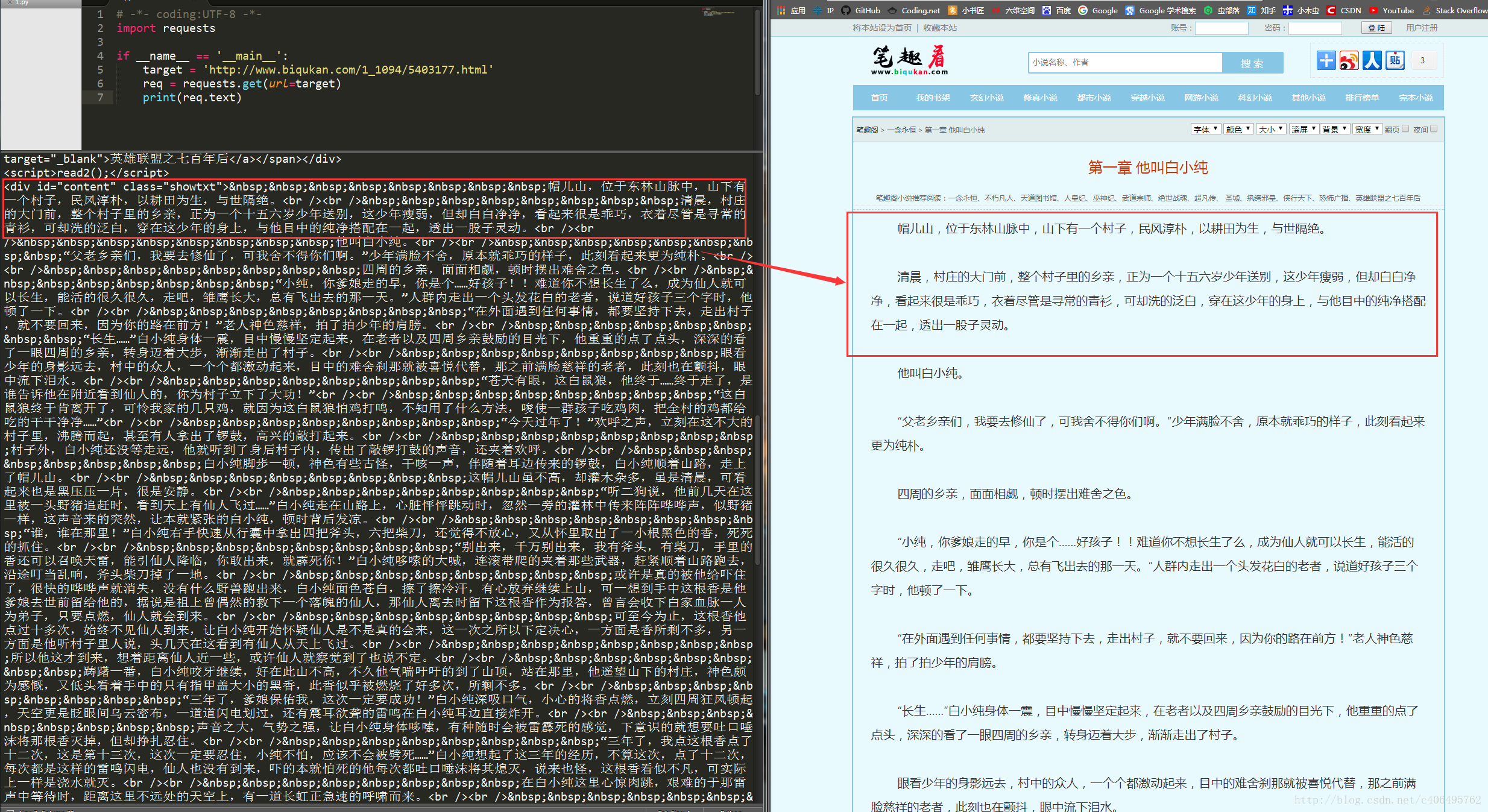
可以看到,我們很輕鬆地獲取了HTML資訊。但是,很顯然,很多資訊是我們不想看到的,我們只想獲得如右側所示的正文內容,我們不關心div、br這些html標籤。如何把正文內容從這些眾多的html標籤中提取出來呢?這就是本次實戰的主要內容。
(3)Beautiful Soup
爬蟲的第一步,獲取整個網頁的HTML資訊,我們已經完成。接下來就是爬蟲的第二步,解析HTML資訊,提取我們感興趣的內容。對於本小節的實戰,我們感興趣的內容就是文章的正文。提取的方法有很多,例如使用正則表示式、Xpath、Beautiful Soup等。對於初學者而言,最容易理解,並且使用簡單的方法就是使用Beautiful Soup提取感興趣內容。
Beautiful Soup的安裝方法和requests一樣,使用如下指令安裝(也是二選一):
- pip install beautifulsoup4
- easy_install beautifulsoup4
一個強大的第三方庫,都會有一個詳細的官方文件。我們很幸運,Beautiful Soup也是有中文的官方文件。
同理,我會根據實戰需求,講解Beautiful Soup庫的部分使用方法,更詳細的內容,請檢視官方文件。
現在,我們使用已經掌握的審查元素方法,檢視一下我們的目標頁面,你會看到如下內容:
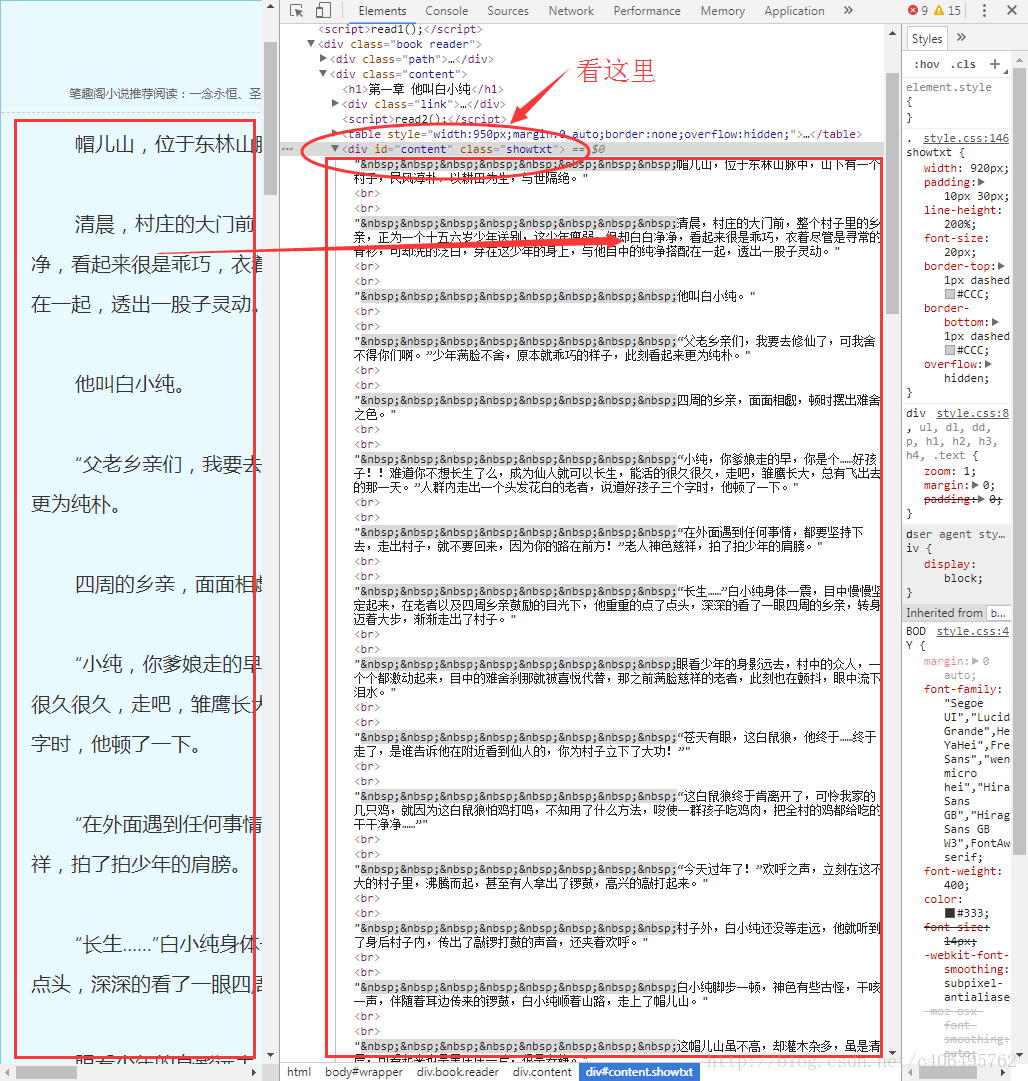
不難發現,文章的所有內容都放在了一個名為div的“東西下面”,這個”東西”就是html標籤。HTML標籤是HTML語言中最基本的單位,HTML標籤是HTML最重要的組成部分。不理解,沒關係,我們再舉個簡單的例子:
一個女人的包包裡,會有很多東西,她們會根據自己的習慣將自己的東西進行分類放好。鏡子和口紅這些會經常用到的東西,會歸放到容易拿到的外側口袋裡。那些不經常用到,需要注意安全存放的證件會放到不容易拿到的裡側口袋裡。
html標籤就像一個個“口袋”,每個“口袋”都有自己的特定功能,負責存放不同的內容。顯然,上述例子中的div標籤下存放了我們關心的正文內容。這個div標籤是這樣的:
<div id="content", class="showtxt">細心的朋友可能已經發現,除了div字樣外,還有id和class。id和class就是div標籤的屬性,content和showtxt是屬性值,一個屬性對應一個屬性值。這東西有什麼用?它是用來區分不同的div標籤的,因為div標籤可以有很多,我們怎麼加以區分不同的div標籤呢?就是通過不同的屬性值。
仔細觀察目標網站一番,我們會發現這樣一個事實:class屬性為showtxt的div標籤,獨一份!這個標籤裡面存放的內容,是我們關心的正文部分。
知道這個資訊,我們就可以使用Beautiful Soup提取我們想要的內容了,編寫程式碼如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt') print(texts)在解析html之前,我們需要建立一個Beautiful Soup物件。BeautifulSoup函式裡的引數就是我們已經獲得的html資訊。然後我們使用find_all方法,獲得html資訊中所有class屬性為showtxt的div標籤。find_all方法的第一個引數是獲取的標籤名,第二個引數class_是標籤的屬性,為什麼不是class,而帶了一個下劃線呢?因為python中class是關鍵字,為了防止衝突,這裡使用class_表示標籤的class屬性,class_後面跟著的showtxt就是屬性值了。看下我們要匹配的標籤格式:
<div id="content", class="showtxt">這樣對應的看一下,是不是就懂了?可能有人會問了,為什麼不是find_all(‘div’, id = ‘content’, class_ = ‘showtxt’)?這樣其實也是可以的,屬性是作為查詢時候的約束條件,新增一個class_=’showtxt’條件,我們就已經能夠準確匹配到我們想要的標籤了,所以我們就不必再新增id這個屬性了。執行程式碼檢視我們匹配的結果:
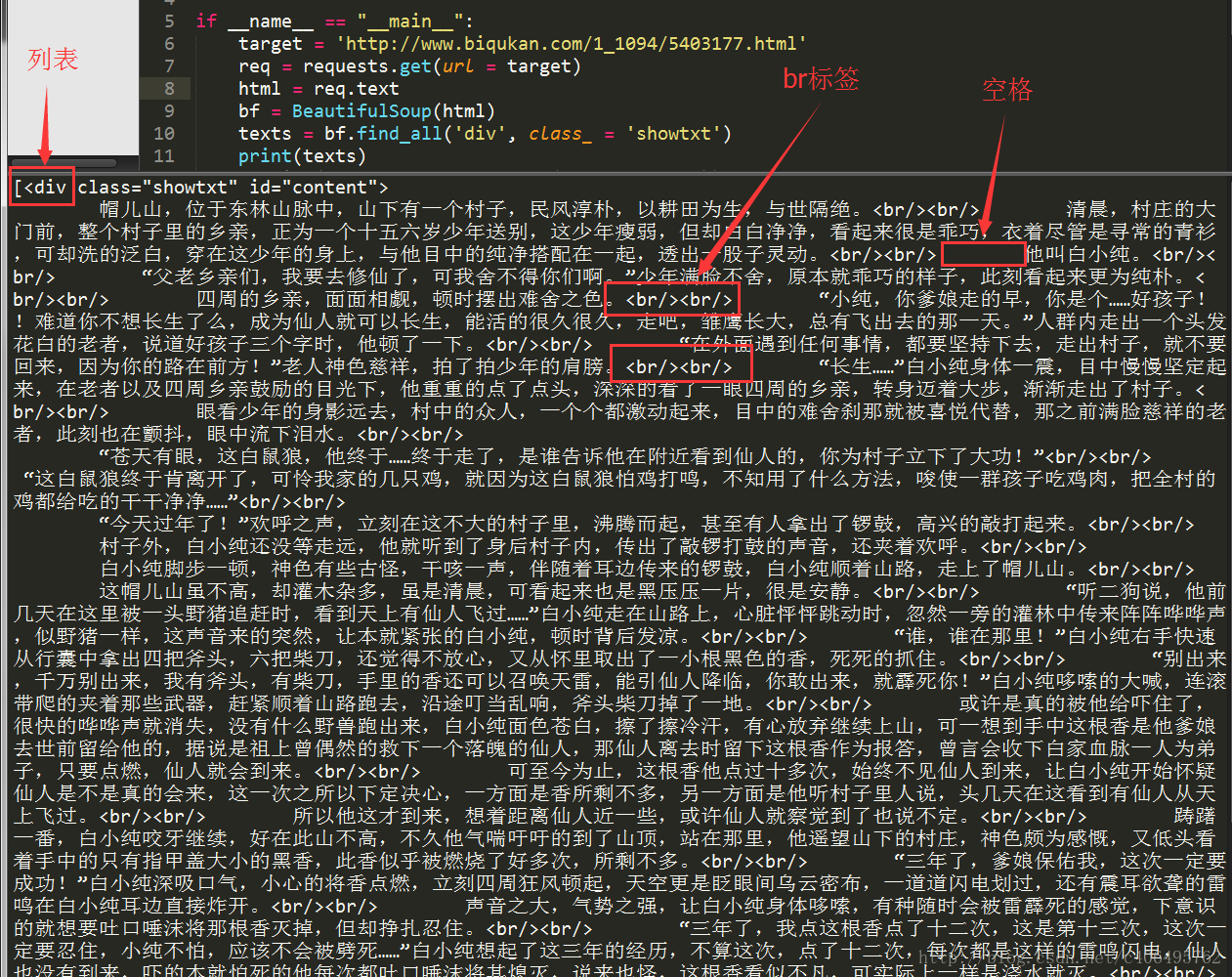
我們可以看到,我們已經順利匹配到我們關心的正文內容,但是還有一些我們不想要的東西。比如div標籤名,br標籤,以及各種空格。怎麼去除這些東西呢?我們繼續編寫程式碼:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target) html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts[0].text.replace('\xa0'*8,'\n\n'))find_all匹配的返回的結果是一個列表。提取匹配結果後,使用text屬性,提取文字內容,濾除br標籤。隨後使用replace方法,剔除空格,替換為回車進行分段。 在html中是用來表示空格的。replace(‘\xa0’*8,’\n\n’)就是去掉下圖的八個空格符號,並用回車代替:
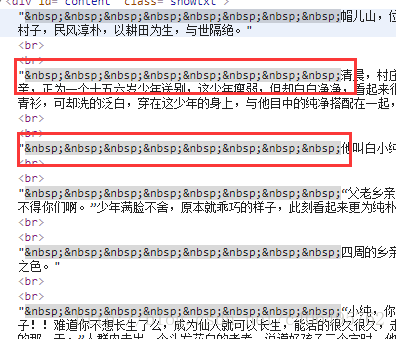
程式執行結果如下:
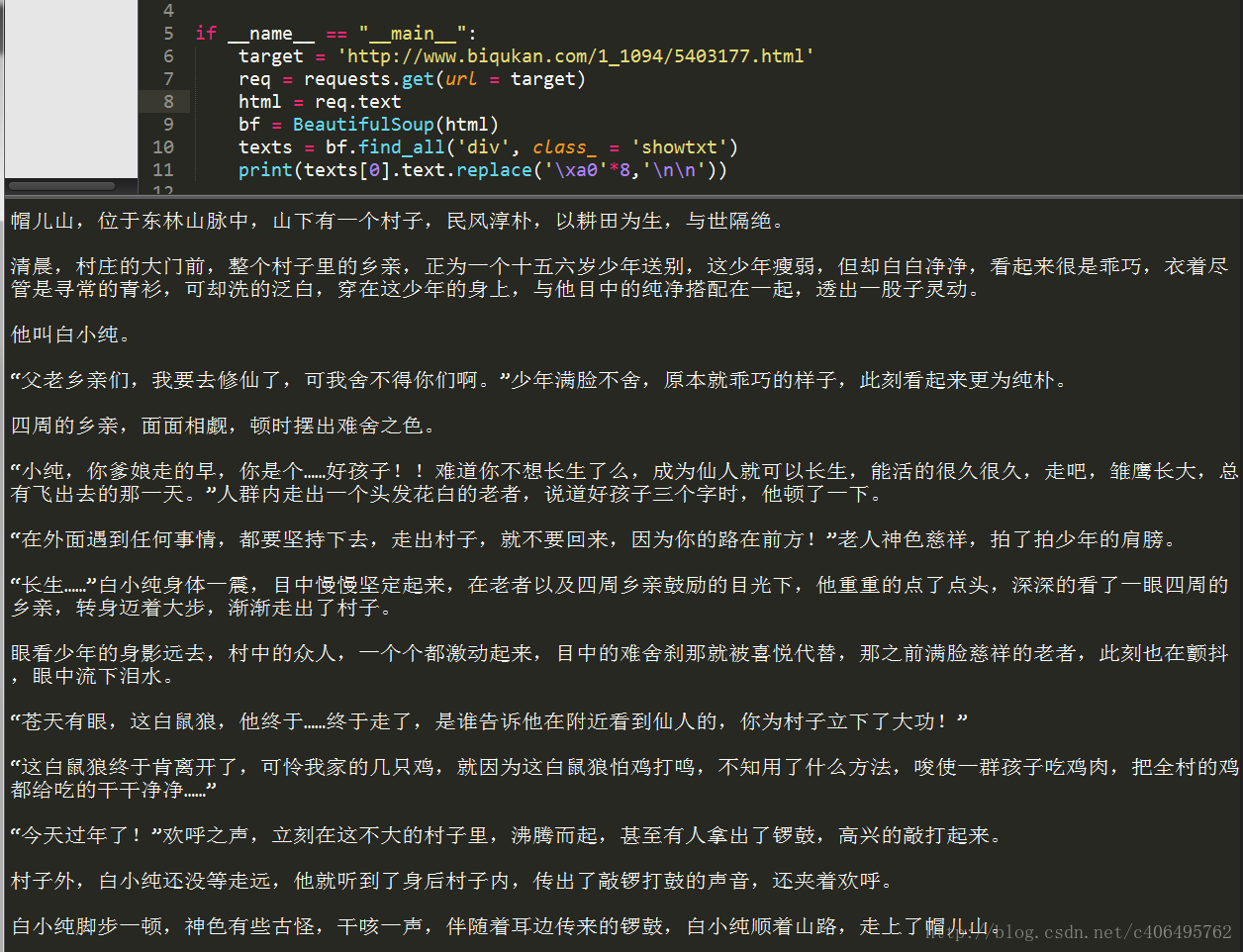
可以看到,我們很自然的匹配到了所有正文內容,並進行了分段。我們已經順利獲得了一個章節的內容,要想下載正本小說,我們就要獲取每個章節的連結。我們先分析下小說目錄:
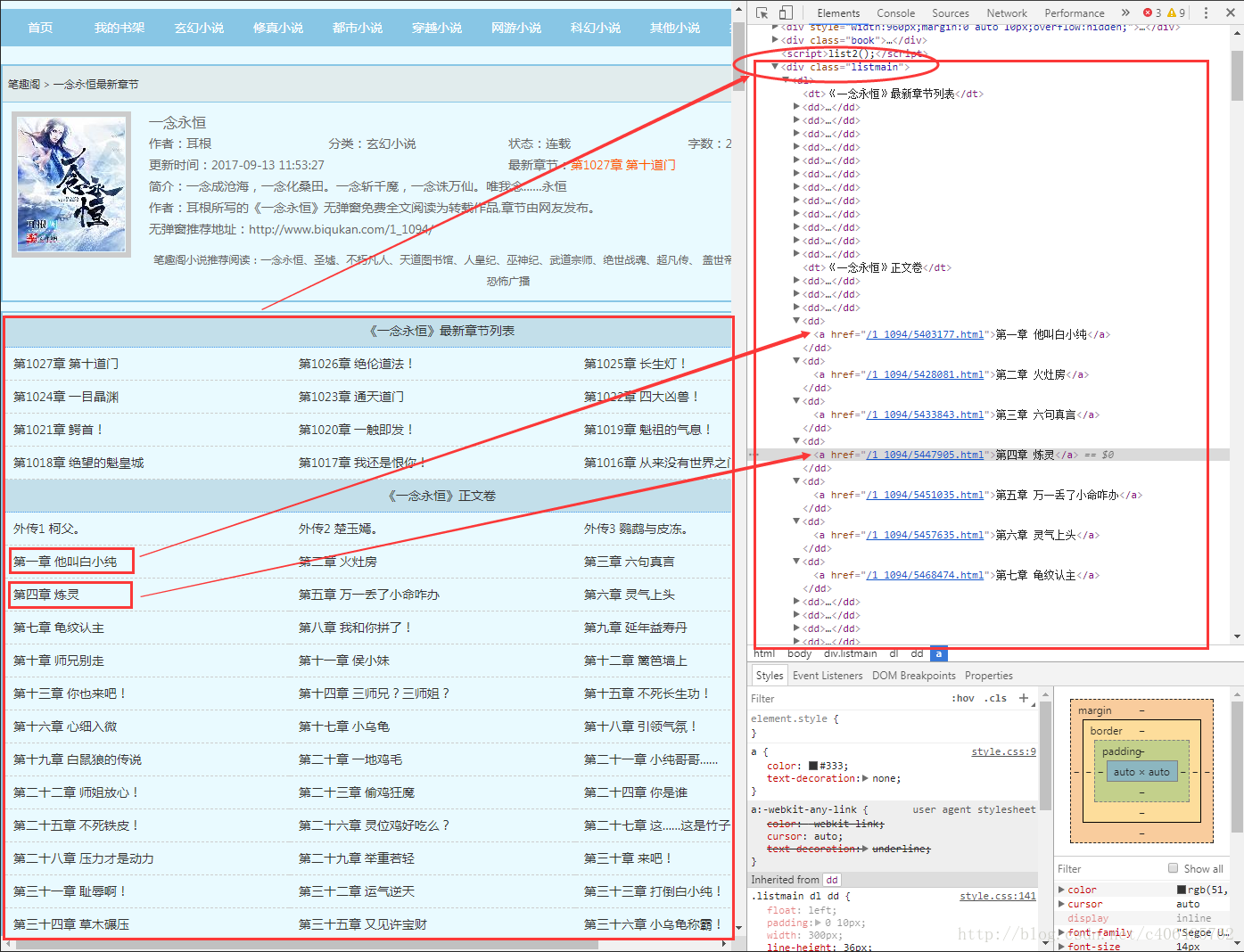
通過審查元素,我們發現可以發現,這些章節都存放在了class屬性為listmain的div標籤下,選取部分html程式碼如下:
<div class="listmain">
<dl>
<dt>《一念永恆》最新章節列表</dt>
<dd><a href="/1_1094/15932394.html">第1027章 第十道門</a></dd>
<dd><a href="/1_1094/15923072.html">第1026章 絕倫道法!</a></dd>
<dd><a href="/1_1094/15921862.html">第1025章 長生燈!</a></dd>
<dd><a href="/1_1094/15918591.html">第1024章 一目晶淵</a></dd>
<dd><a href="/1_1094/15906236.html">第1023章 通天道門</a></dd>
<dd><a href="/1_1094/15903775.html">第1022章 四大凶獸!</a></dd>
<dd><a href="/1_1094/15890427.html">第1021章 鱷首!</a></dd>
<dd><a href="/1_1094/15886627.html">第1020章 一觸即發!</a></dd>
<dd><a href="/1_1094/15875306.html">第1019章 魁祖的氣息!</a></dd>
<dd><a href="/1_1094/15871572.html">第1018章 絕望的魁皇城</a></dd>
<dd><a href="/1_1094/15859514.html">第1017章 我還是恨你!</a></dd>
<dd><a href="/1_1094/15856137.html">第1016章 從來沒有世界之門!</a></dd>
<dt>《一念永恆》正文卷</dt> <dd><a href="/1_1094/5386269.html">外傳1 柯父。</a></dd>
<dd><a href="/1_1094/5386270.html">外傳2 楚玉嫣。</a></dd> <dd><a href="/1_1094/5386271.html">外傳3 鸚鵡與皮凍。</a></dd>
<dd><a href="/1_1094/5403177.html">第一章 他叫白小純</a></dd> <dd><a href="/1_1094/5428081.html">第二章 火灶房</a></dd>
<dd><a href="/1_1094/5433843.html">第三章 六句真言</a></dd> <dd><a href="/1_1094/5447905.html">第四章 煉靈</a></dd>
</dl>
</div>在分析之前,讓我們先介紹一個概念:父節點、子節點、孫節點。<div>和</div>限定了<div>標籤的開始和結束的位置,他們是成對出現的,有開始位置,就有結束位置。我們可以看到,在<div>標籤包含<dl>標籤,那這個<dl>標籤就是<div>標籤的子節點,<dl>標籤又包含<dt>標籤和<dd>標籤,那麼<dt>標籤和<dd>標籤就是<div>標籤的孫節點。有點繞?那你記住這句話:誰包含誰,誰就是誰兒子!
他們之間的關係都是相對的。比如對於<dd>標籤,它的子節點是<a>標籤,它的父節點是<dl>標籤。這跟我們人是一樣的,上有老下有小。
看到這裡可能有人會問,這有好多<dd>標籤和<a>標籤啊!不同的<dd>標籤,它們是什麼關係啊?顯然,兄弟姐妹嘍!我們稱它們為兄弟結點。
好了,概念明確清楚,接下來,讓我們分析一下問題。我們看到每個章節的名字存放在了<a>標籤裡面。<a>標籤還有一個href屬性。這裡就不得不提一下<a>標籤的定義了,<a>標籤定義了一個超連結,用於從一張頁面連結到另一張頁面。<a> 標籤最重要的屬性是 href 屬性,它指示連結的目標。
我們將之前獲得的第一章節的URL和<a> 標籤對比看一下:
http://www.biqukan.com/1_1094/5403177.html
<a href="/1_1094/5403177.html">第一章 他叫白小純</a>不難發現,<a> 標籤中href屬性存放的屬性值/1_1094/5403177.html是章節URLhttp://www.biqukan.com/1_1094/5403177.html的後半部分。其他章節也是如此!那這樣,我們就可以根據<a>標籤的href屬性值獲得每個章節的連結和名稱了。
總結一下:小說每章的連結放在了class屬性為listmain的<div>標籤下的<a>標籤中。連結具體位置放在html->body->div->dl->dd->a的href屬性中。先匹配class屬性為listmain的<div>標籤,再匹配<a>標籤。編寫程式碼如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
print(div[0])還是使用find_all方法,執行結果如下:
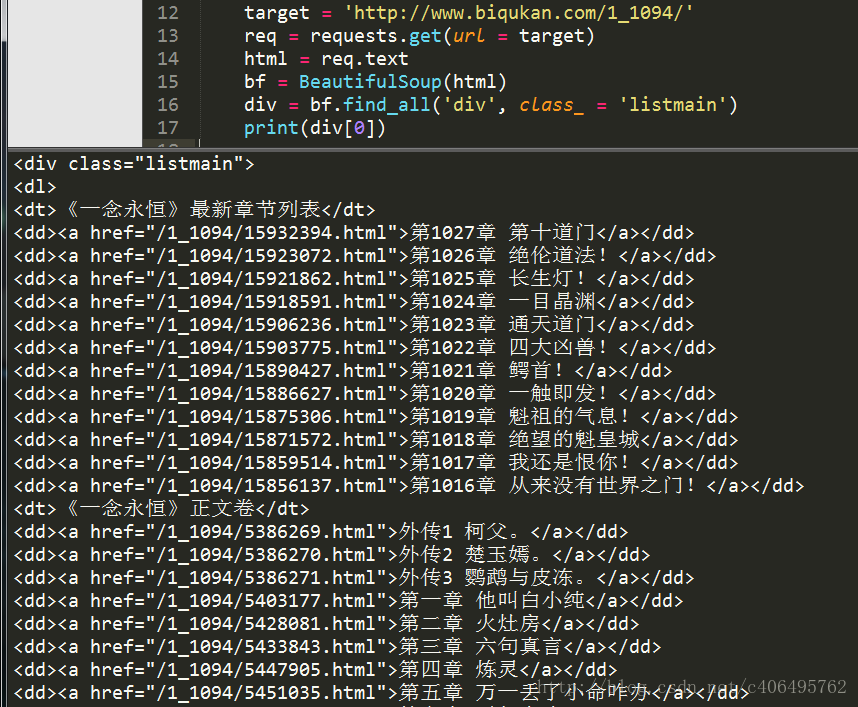
很順利,接下來再匹配每一個<a>標籤,並提取章節名和章節文章。如果我們使用Beautiful Soup匹配到了下面這個<a>標籤,如何提取它的href屬性和<a>標籤裡存放的章節名呢?
<a href="/1_1094/5403177.html">第一章 他叫白小純</a>方法很簡單,對Beautiful Soup返回的匹配結果a,使用a.get(‘href’)方法就能獲取href的屬性值,使用a.string就能獲取章節名,編寫程式碼如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server = 'http://www.biqukan.com/'
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target) html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))因為find_all返回的是一個列表,裡邊存放了很多的<a>標籤,所以使用for迴圈遍歷每個<a>標籤並打印出來,執行結果如下。
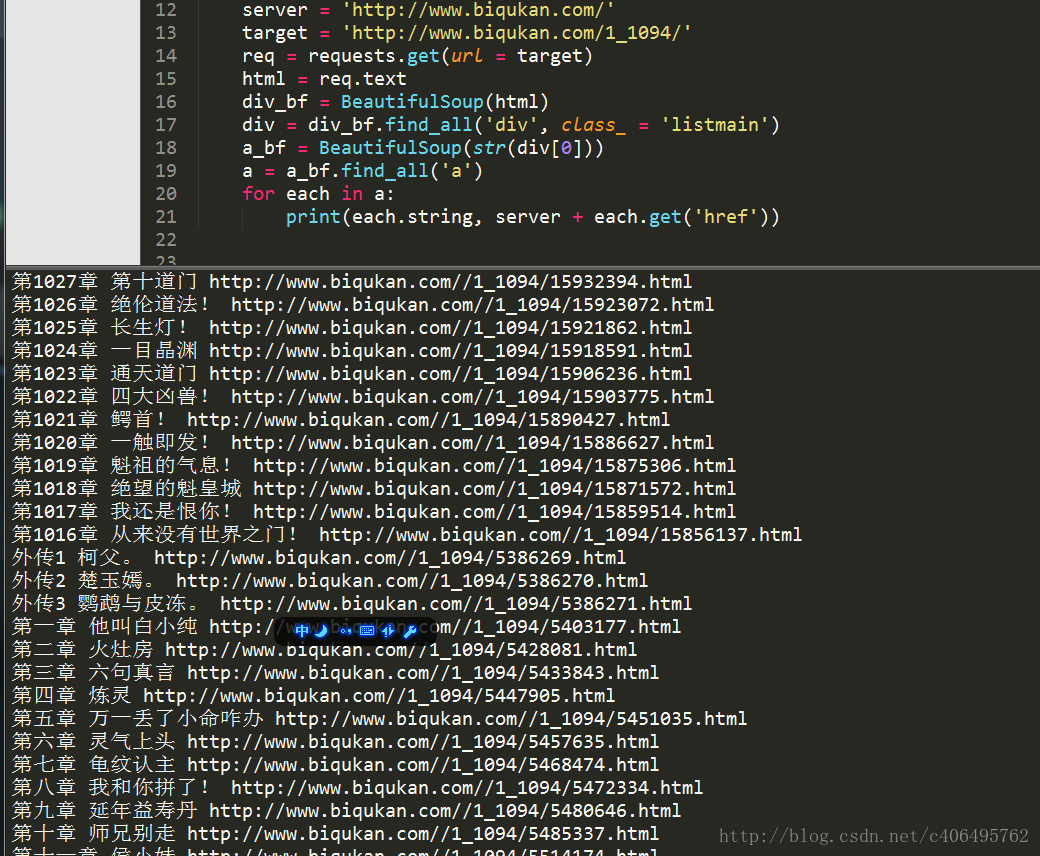
最上面匹配的一千多章的內容是最新更新的12章節的連結。這12章內容會和下面的重複,所以我們要濾除,除此之外,還有那3個外傳,我們也不想要。這些都簡單地剔除就好。
(3)整合程式碼
每個章節的連結、章節名、章節內容都有了。接下來就是整合程式碼,將獲得內容寫入文字檔案儲存就好了。編寫程式碼如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests, sys
"""
類說明:下載《筆趣看》網小說《一念永恆》
Parameters:
無
Returns:
無
Modify:
2017-09-13
"""
class downloader(object):
def __init__(self):
self.server = 'http://www.biqukan.com/'
self.target = 'http://www.biqukan.com/1_1094/'
self.names = [] #存放章節名
self.urls = [] #存放章節連結
self.nums = 0 #章節數
"""
函式說明:獲取下載連結
Parameters:
無
Returns:
無
Modify:
2017-09-13
"""
def get_download_url(self):
req = requests.get(url = self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
self.nums = len(a[15:]) #剔除不必要的章節,並統計章節數
for each in a[15:]:
self.names.append(each.string)
self.urls.append(self.server + each.get('href'))
"""
函式說明:獲取章節內容
Parameters:
target - 下載連線(string)
Returns:
texts - 章節內容(string)
Modify:
2017-09-13
"""
def get_contents(self, target):
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
texts = texts[0].text.replace('\xa0'*8,'\n\n')
return texts
"""
函式說明:將爬取的文章內容寫入檔案
Parameters:
name - 章節名稱(string)
path - 當前路徑下,小說儲存名稱(string)
text - 章節內容(string)
Returns:
無
Modify:
2017-09-13
"""
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
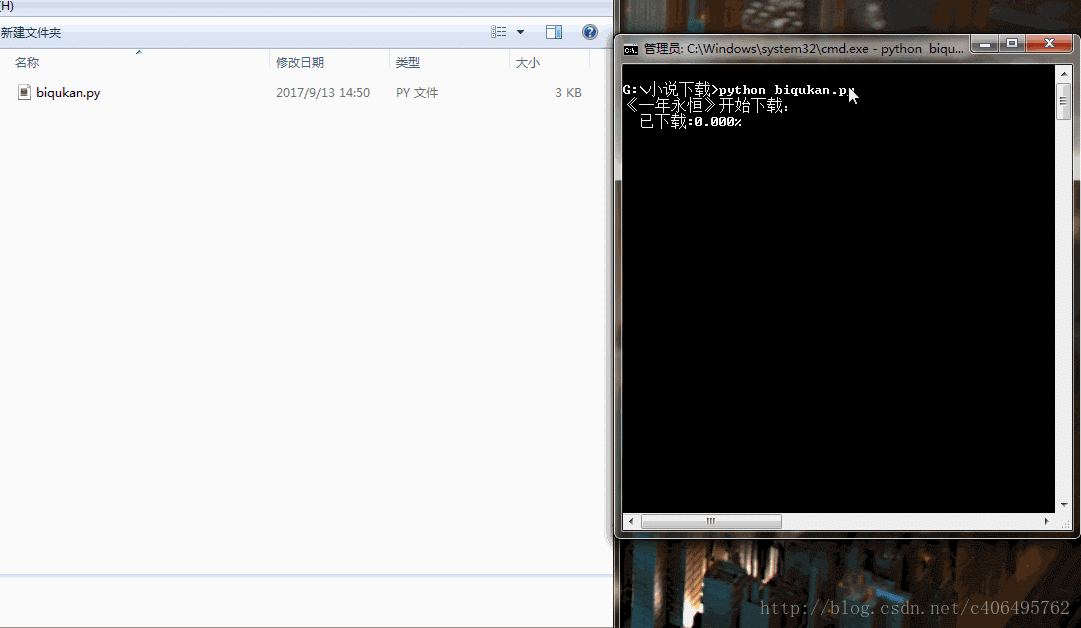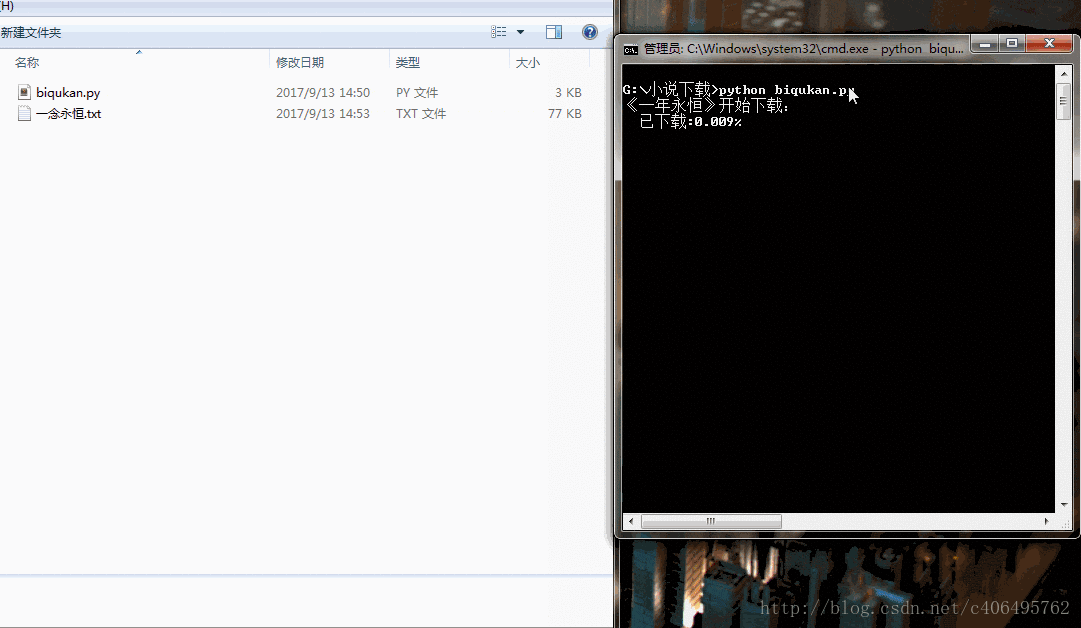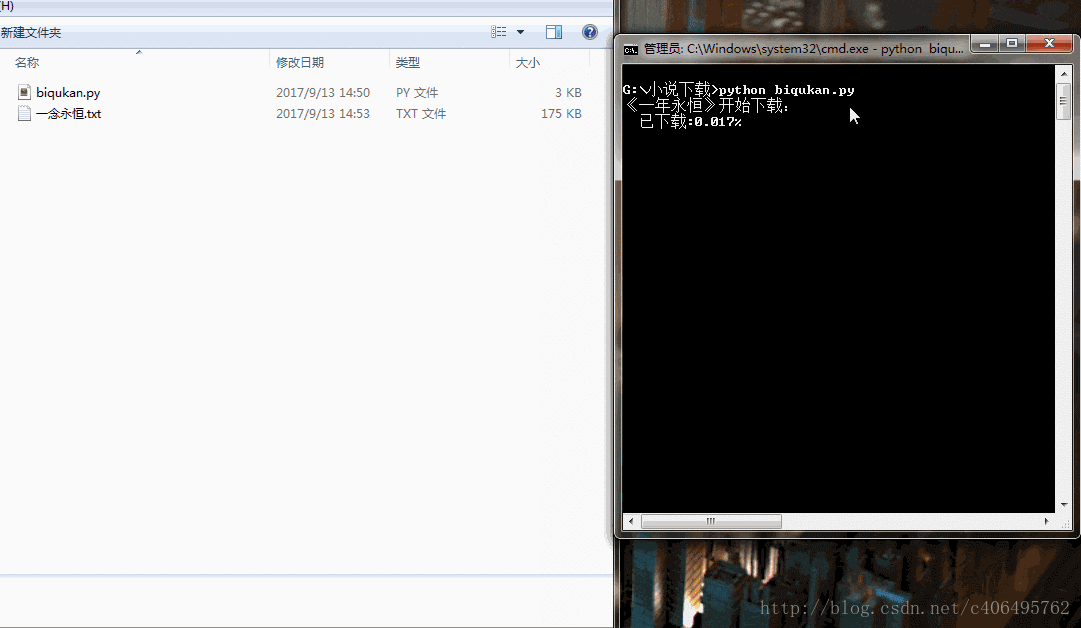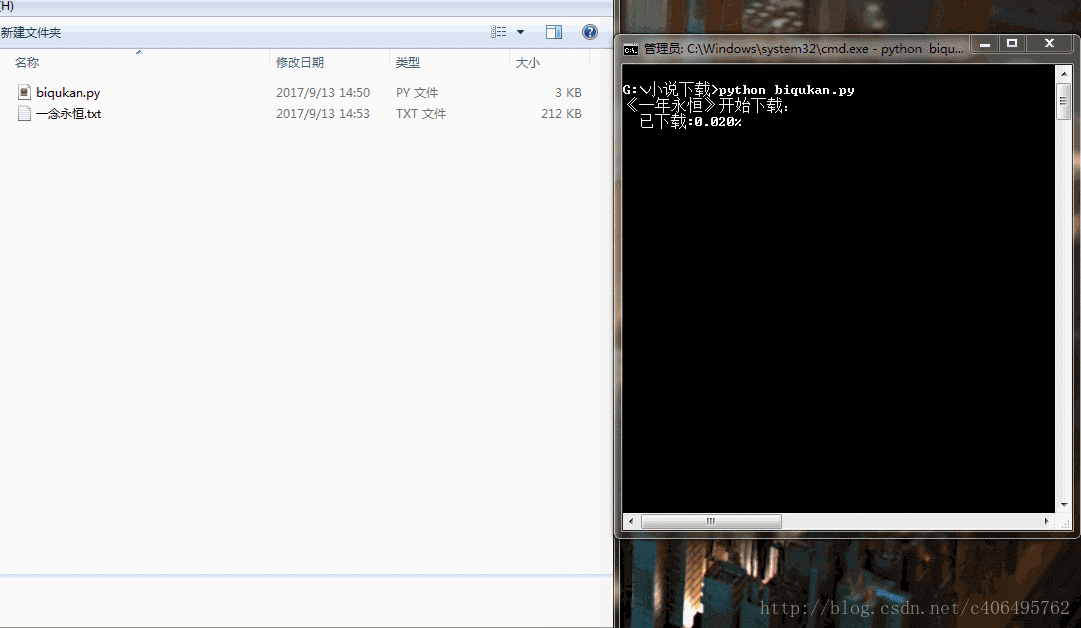
print('《一年永恆》開始下載:')
for i in range(dl.nums):
dl.writer(dl.names[i], '一念永恆.txt', dl.get_contents(dl.urls[i]))
sys.stdout.write(" 已下載:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
print('《一年永恆》下載完成')很簡單的程式,單程序跑,沒有開程序池。下載速度略慢,喝杯茶休息休息吧。程式碼執行效果如下圖所示:
2 優美桌布下載
(1)實戰背景
已經會爬取文字了,是不是感覺爬蟲還是蠻好玩的呢?接下來,讓我們進行一個進階實戰,瞭解一下反爬蟲。
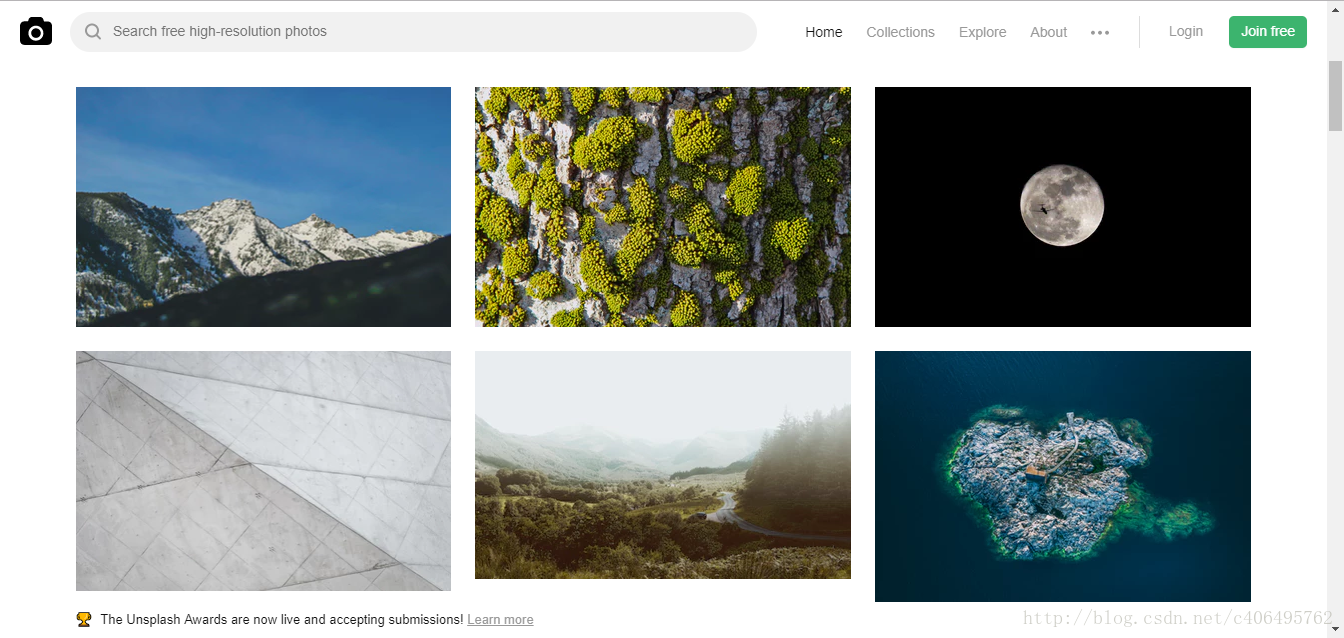
看一看這些優美的桌布,這個網站的名字叫做Unsplash,免費高清桌布分享網是一個堅持每天分享高清的攝影圖片的站點,每天更新一張高質量的圖片素材,全是生活中的景象作品,清新的生活氣息圖片可以作為桌面桌布也可以應用於各種需要的環境。
看到這麼優美的圖片,我的第一反應就是想收藏一些,作為知乎文章的題圖再好不過了。每張圖片我都很喜歡,批量下載吧,不多爬,就下載50張好了。
(2)實戰進階
我們已經知道了每個html標籤都有各自的功能。<a>標籤存放一下超連結,圖片存放在哪個標籤裡呢?html規定,圖片統統給我放到<img>標籤中!既然這樣,我們擷取就Unsplash網站中的一個<img>標籤,分析一下:
<img alt="Snow-capped mountain slopes under blue sky" src="https://images.unsplash.com/photo-1428509774491-cfac96e12253?dpr=1&auto=compress,format&fit=crop&w=360&h=240&q=80&cs=tinysrgb&crop=" class="cV68d" style="width: 220px; height: 147px;">可以看到,<img>標籤有很多屬性,有alt、src、class、style屬性,其中src屬性存放的就是我們需要的圖片儲存地址,我們根據這個地址就可以進行圖片的下載。
那麼,讓我們先捋一捋這個過程:
- 使用requeusts獲取整個網頁的HTML資訊;
- 使用Beautiful Soup解析HTML資訊,找到所有
<img>標籤,提取src屬性,獲取圖片存放地址; - 根據圖片存放地址,下載圖片。
我們信心滿滿地按照這個思路爬取Unsplash試一試,編寫程式碼如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'https://unsplash.com/'
req = requests.get(url=target)
print(req.text)按照我們的設想,我們應該能找到很多<img>標籤。但是我們發現,除了一些<script>標籤和一些看不懂的程式碼之外,我們一無所獲,一個<img>標籤都沒有!跟我們在網站審查元素的結果完全不一樣,這是為什麼?

答案就是,這個網站的所有圖片都是動態載入的!網站有靜態網站和動態網站之分,上一個實戰爬取的網站是靜態網站,而這個網站是動態網站,動態載入有一部分的目的就是為了反爬蟲。
對於什麼是動態載入,你可以這樣理解:我們知道化妝術學的好,賊厲害,可以改變一個人的容貌。相應的,動態載入用的好,也賊厲害,可以改變一個網站的容貌。
動態網站使用動態載入常用的手段就是通過呼叫JavaScript來實現的。怎麼實現JavaScript動態載入,我們不必深究,我們只要知道,動態載入的JavaScript指令碼,就像化妝術需要用的化妝品,五花八門。有粉底、口紅、睫毛膏等等,它們都有各自的用途。動態載入的JavaScript指令碼也一樣,一個動態載入的網站可能使用很多JavaScript指令碼,我們只要找到負責動態載入圖片的JavaScript指令碼,不就找到我們需要的連結了嗎?
對於初學者,我們不必看懂JavaScript執行的內容是什麼,做了哪些事情,因為我們有強大的抓包工具,它自然會幫我們分析。這個強大的抓包工具就是Fiddler:
PS:也可以使用瀏覽器自帶的Networks,但是我更推薦這個軟體,因為它操作起來更高效。
安裝方法很簡單,傻瓜式安裝,一直下一步即可,對於經常使用電腦的人來說,應該沒有任何難度。
這個軟體的使用方法也很簡單,開啟軟體,然後用瀏覽器開啟我們的目標網站,以Unsplash為例,抓包結果如下:
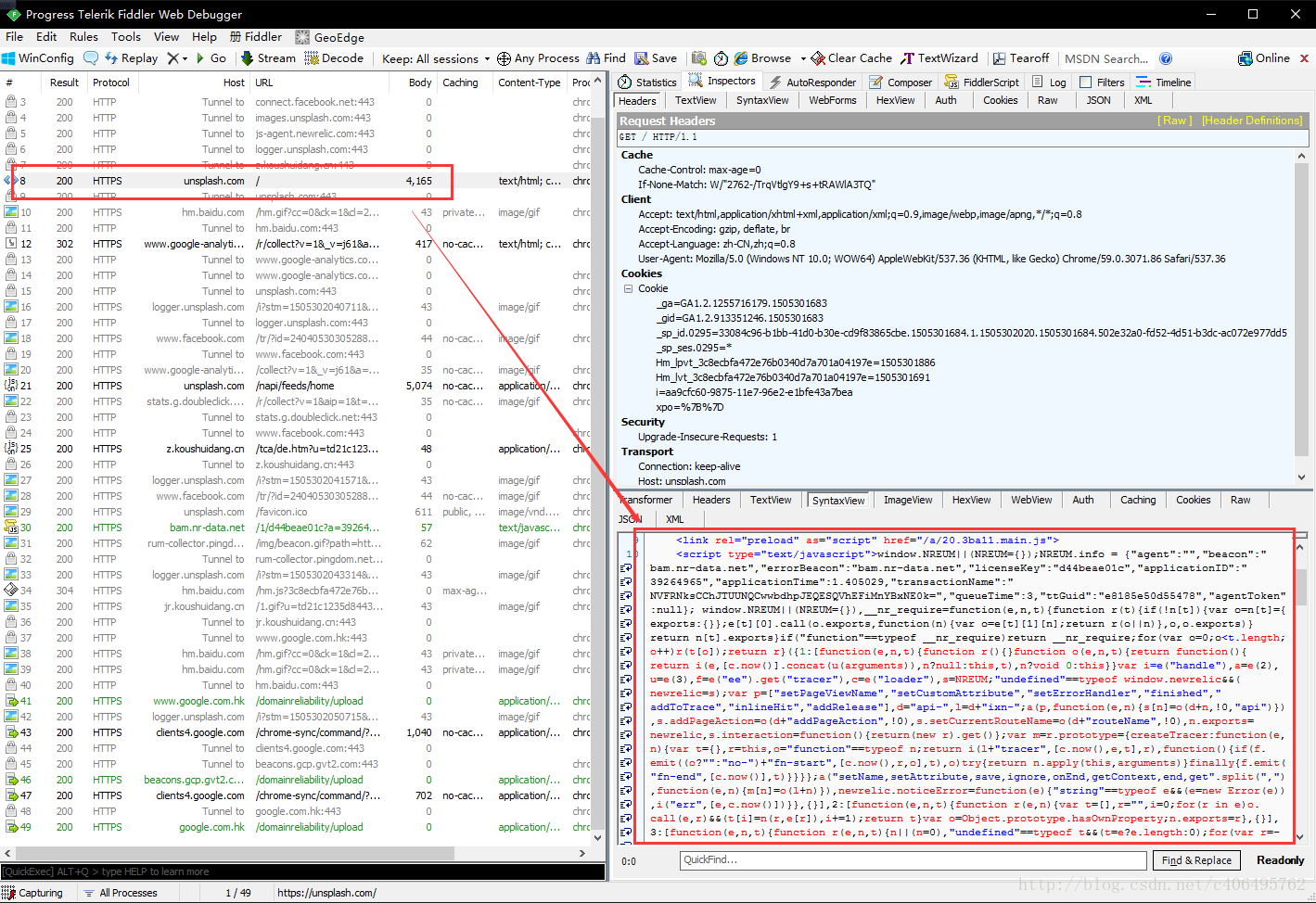
我們可以看到,上圖左側紅框處是我們的GET請求的地址,就是網站的URL,右下角是伺服器返回的資訊,我們可以看到,這些資訊也是我們上一個程式獲得的資訊。這個不是我們需要的連結,我們繼續往下看。
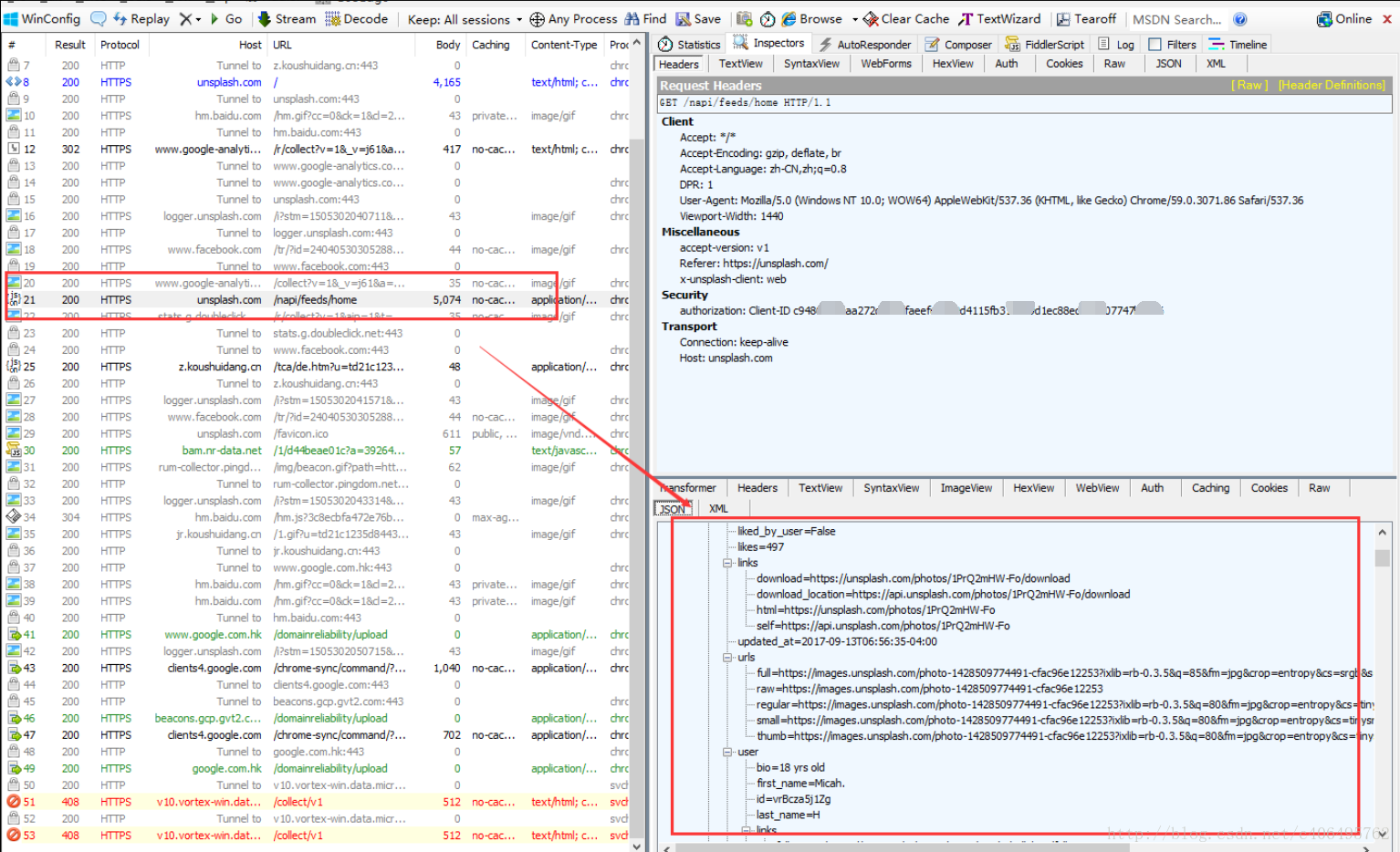
我們發現上圖所示的就是一個JavaScript請求,看右下側伺服器返回的資訊是一個json格式的資料。這裡面,就有我們需要的內容。我們區域性放大看一下:
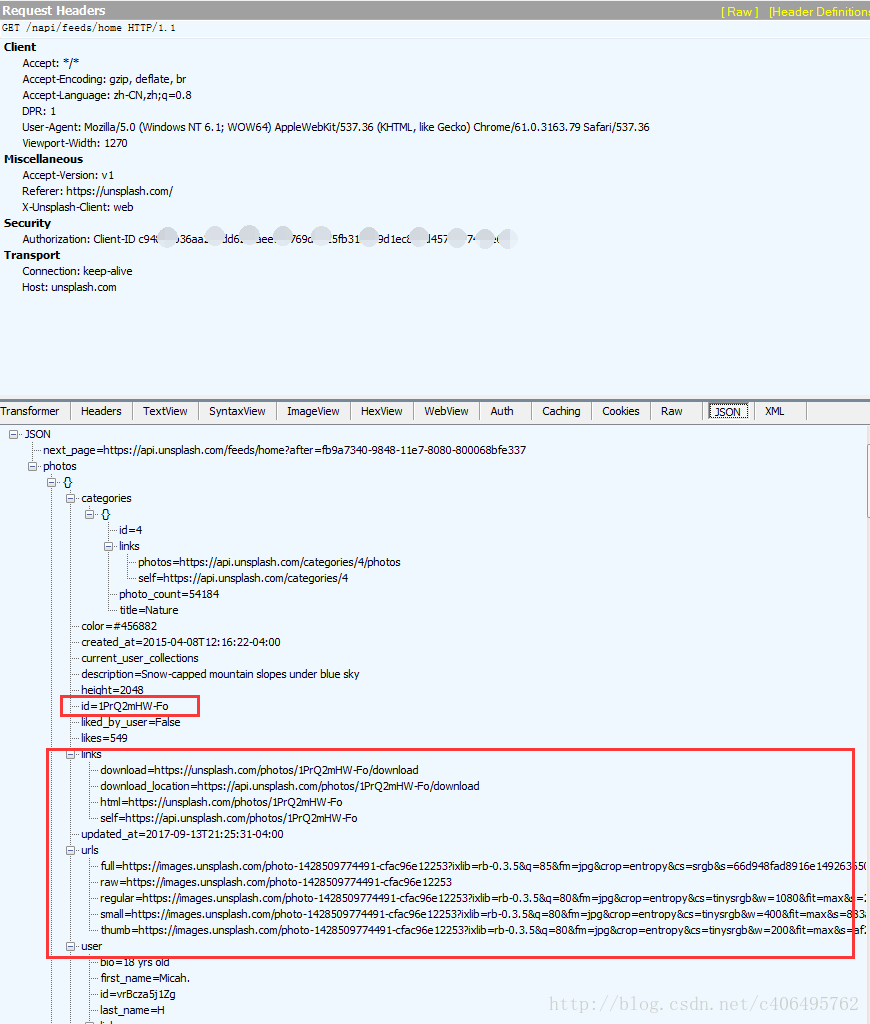
這是Fiddler右側的資訊,上面是請求的Headers資訊,包括這個Javascript的請求地 址:http://unsplash.com/napi/feeds/home,其他資訊我們先不管,我們看看下面的內容。裡面有很多圖片的資訊,包括圖片的id,圖片的大小,圖片的連結,還有下一頁的地址。這個指令碼以json格式儲存傳輸的資料,json格式是一種輕量級的資料交換格式,起到封裝資料的作用,易於人閱讀和編寫,同時也易於機器解析和生成。這麼多連結,可以看到圖片的連結有很多,根據哪個連結下載圖片呢?先別急,讓我們繼續分析:
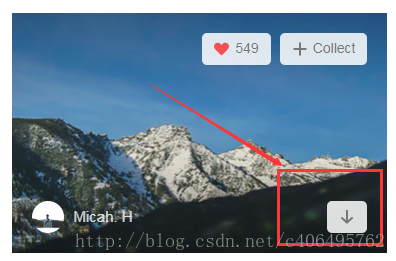
在這個網站,我們可以按這個按鈕進行圖片下載。我們抓包分下下這個動作,看看傳送了哪些請求。
https://unsplash.com/photos/1PrQ2mHW-Fo/download?force=true
https://unsplash.com/photos/JX7nDtafBcU/download?force=true
https://unsplash.com/photos/HCVbP3zqX4k/download?force=true通過Fiddler抓包,我們發現,點選不同圖片的下載按鈕,GET請求的地址都是不同的。但是它們很有規律,就是中間有一段程式碼是不一樣的,其他地方都一樣。中間那段程式碼是不是很熟悉?沒錯,它就是我們之前抓包分析得到json資料中的照片的id。我們只要解析出每個照片的id,就可以獲得圖片下載的請求地址,然後根據這個請求地址,我們就可以下載圖片了。那麼,現在的首要任務就是解析json資料了。
json格式的資料也是分層的。可以看到next_page裡存放的是下一頁的請求地址,很顯然Unsplash下一頁的內容,也是動態載入的。在photos下面的id裡,存放著圖片的id,這個就是我們需要獲得的圖片id號。
怎麼程式設計提取這些json資料呢?我們也是分步完成:
- 獲取整個json資料
- 解析json資料
編寫程式碼,嘗試獲取json資料:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
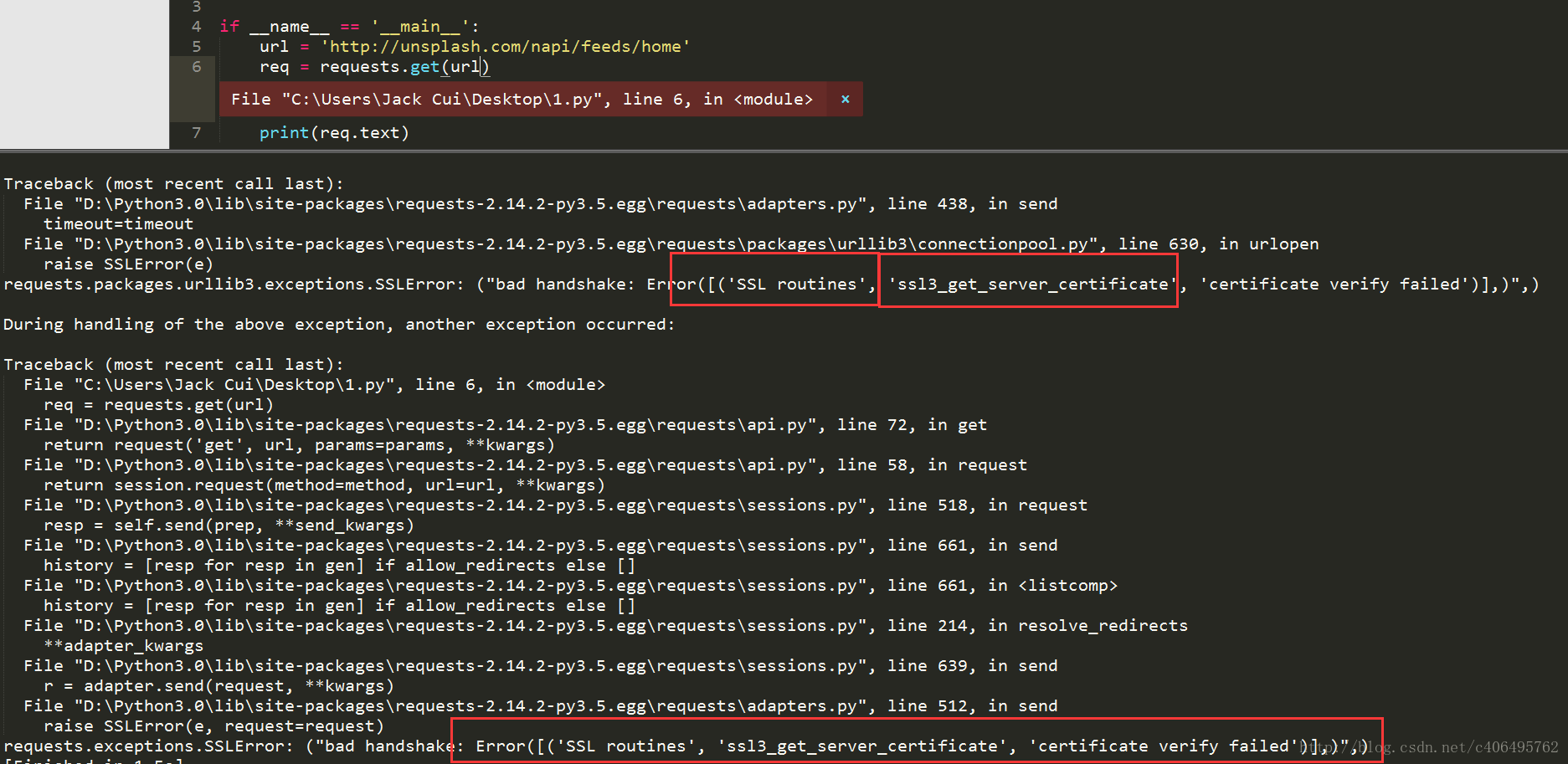
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target) print(req.text)很遺憾,程式報錯了,問題出在哪裡?通過錯誤資訊,我們可以看到SSL認證錯誤,SSL認證是指客戶端到伺服器端的認證。一個非常簡單的解決這個認證錯誤的方法就是設定requests.get()方法的verify引數。這個引數預設設定為True,也就是執行認證。我們將其設定為False,繞過認證不就可以了?
有想法就要嘗試,編寫程式碼如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target, verify=False)
print(req.text)認證問題解決了,又有新問題了:
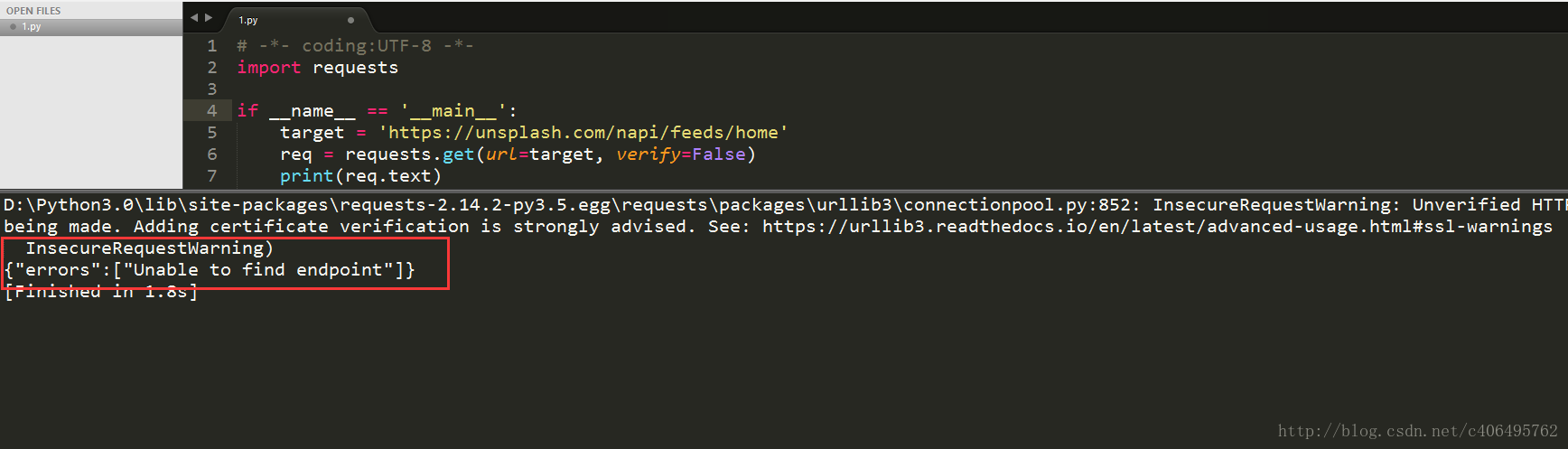
可以看到,我們GET請求又失敗了,這是為什麼?這個網站反爬蟲的手段除了動態載入,還有一個反爬蟲手段,那就是驗證Request Headers。接下來,讓我們分析下這個Requests Headers:
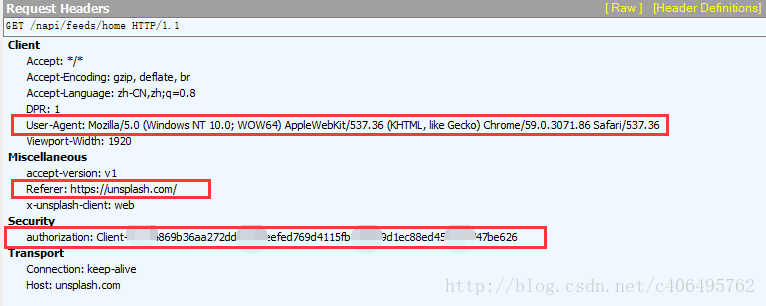
我截取了Fiddler的抓包資訊,可以看到Requests Headers裡又很多引數,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。它們都是什麼意思呢?
專業的解釋能說的太多,我挑重點:
User-Agent:這裡面存放瀏覽器的資訊。可以看到上圖的引數值,它表示我是通過Windows的Chrome瀏覽器,訪問的這個伺服器。如果我們不設定這個引數,用Python程式直接傳送GET請求,伺服器接受到的User-Agent資訊就會是一個包含python字樣的User-Agent。如果後臺設計者驗證這個User-Agent引數是否合法,不讓帶Python字樣的User-Agent訪問,這樣就起到了反爬蟲的作用。這是一個最簡單的,最常用的反爬蟲手段。
Referer:這個引數也可以用於反爬蟲,它表示這個請求是從哪發出的。可以看到我們通過瀏覽器訪問網站,這個請求是從https://unsplash.com/,這個地址發出的。如果後臺設計者,驗證這個引數,對於不是從這個地址跳轉過來的請求一律禁止訪問,這樣就也起到了反爬蟲的作用。
authorization:這個引數是基於AAA模型中的身份驗證資訊允許訪問一種資源的行為。在我們用瀏覽器訪問的時候,伺服器會為訪問者分配這個使用者ID。如果後臺設計者,驗證這個引數,對於沒有使用者ID的請求一律禁止訪問,這樣就又起到了反爬蟲的作用。
Unsplash是根據哪個引數反爬蟲的呢?根據我的測試,是authorization。我們只要通過程式手動新增這個引數,然後再發送GET請求,就可以順利訪問了。怎麼什麼設定呢?還是requests.get()方法,我們只需要新增headers引數即可。編寫程式碼如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
print(req.text)headers引數值是通過字典傳入的。記得將上述程式碼中your Client-ID換成諸位自己抓包獲得的資訊。程式碼執行結果如下:
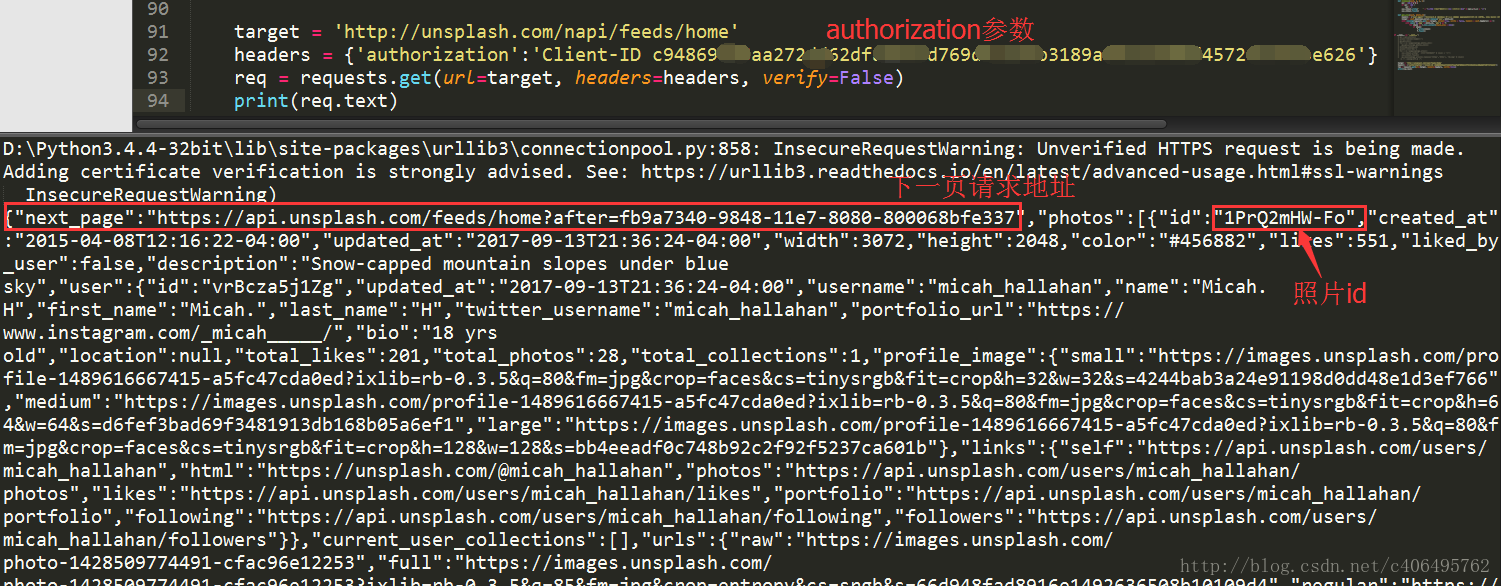 皇天不負有心人,可以看到我們已經順利獲得json資料了,裡面有next_page和照片的id。接下來就是解析json資料。根據我們之前分析可知,next_page放在了json資料的最外側,照片的id放在了photos->id裡。我們使用json.load()方法解析資料,編寫程式碼如下:
皇天不負有心人,可以看到我們已經順利獲得json資料了,裡面有next_page和照片的id。接下來就是解析json資料。根據我們之前分析可知,next_page放在了json資料的最外側,照片的id放在了photos->id裡。我們使用json.load()方法解析資料,編寫程式碼如下:
# -*- coding:UTF-8 -*-
import requests, json
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
print('下一頁地址:',next_page)
for each in html['photos']:
print('圖片ID:',each['id'])解析json資料很簡單,跟字典操作一樣,就是字典套字典。json.load()裡面的引數是原始的json格式的資料。程式執行結果如下:

圖片的ID已經獲得了,再通過字串處理一下,就生成了我們需要的圖片下載請求地址。根據這個地址,我們就可以下載圖片了。下載方式,使用直接寫入檔案的方法。
(3)整合程式碼
每次獲取連結加一個1s延時,因為人在瀏覽頁面的時候,翻頁的動作不可能太快。我們要讓我們的爬蟲儘量友好一些。
# -*- coding:UTF-8 -*-
import requests, json, time, sys
from contextlib import closing
class get_photos(object):
def __init__(self):
self.photos_id = []
self.download_server = 'https://unsplash.com/photos/xxx/download?force=trues'
self.target = 'http://unsplash.com/napi/feeds/home'
self.headers = {'authorization':'Client-ID c94869b36aa272dd62dfaeefed769d4115fb3189a9d1ec88ed457207747be626'}
"""
函式說明:獲取圖片ID
Parameters:
無
Returns:
無
Modify:
2017-09-13
"""
def get_ids(self):
req = requests.get(url=self.target, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
for i in range(5):
req = requests.get(url=next_page, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
"""
函式說明:圖片下載
Parameters:
無
Returns:
無
Modify:
2017-09-13
"""
def download(self, photo_id, filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}
target = self.download_server.replace('xxx', photo_id)
with closing(requests.get(url=target, stream=True, verify = False, headers = self.headers)) as r:
with open('%d.jpg' % filename, 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):
if chunk:
f.write(chunk)
f.flush()
if __name__ == '__main__':
gp = get_photos()
print('獲取圖片連線中:')
gp.get_ids()
print('圖片下載中:')
for i in range(len(gp.photos_id)):
print(' 正在下載第%d張圖片' % (i+1))
gp.download(gp.photos_id[i], (i+1))下載速度還行,有的圖片下載慢是因為圖片太大。可以看到右側也列印了一些警報資訊,這是因為我們沒有進行SSL驗證。
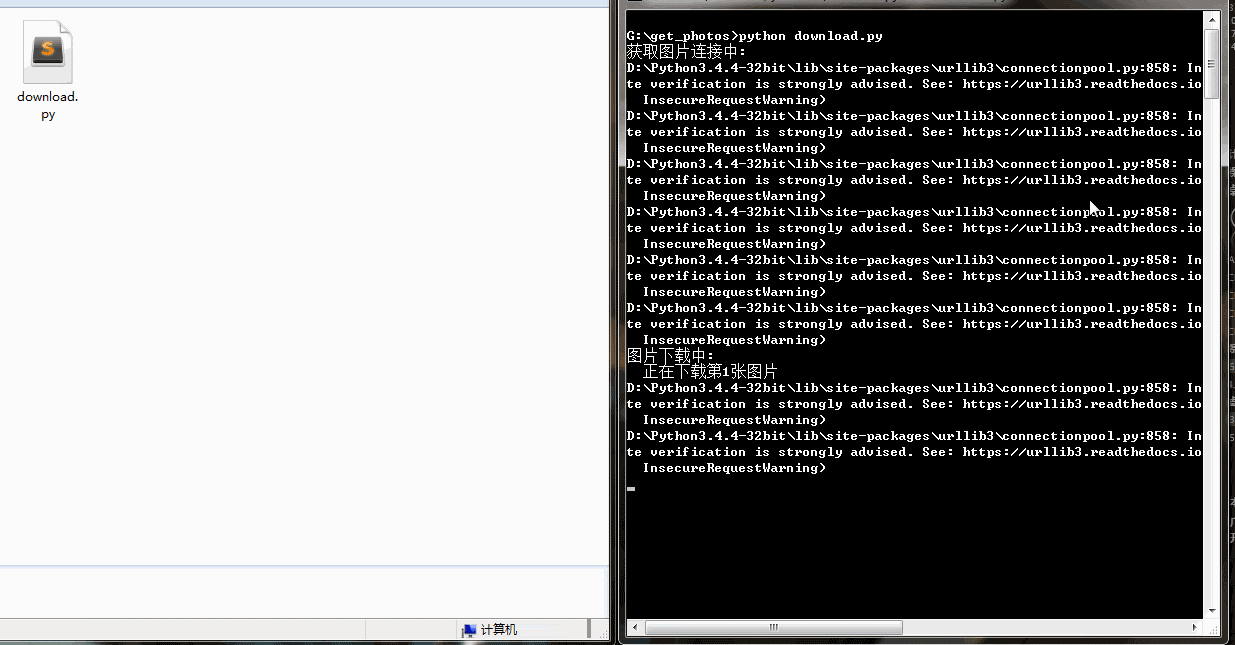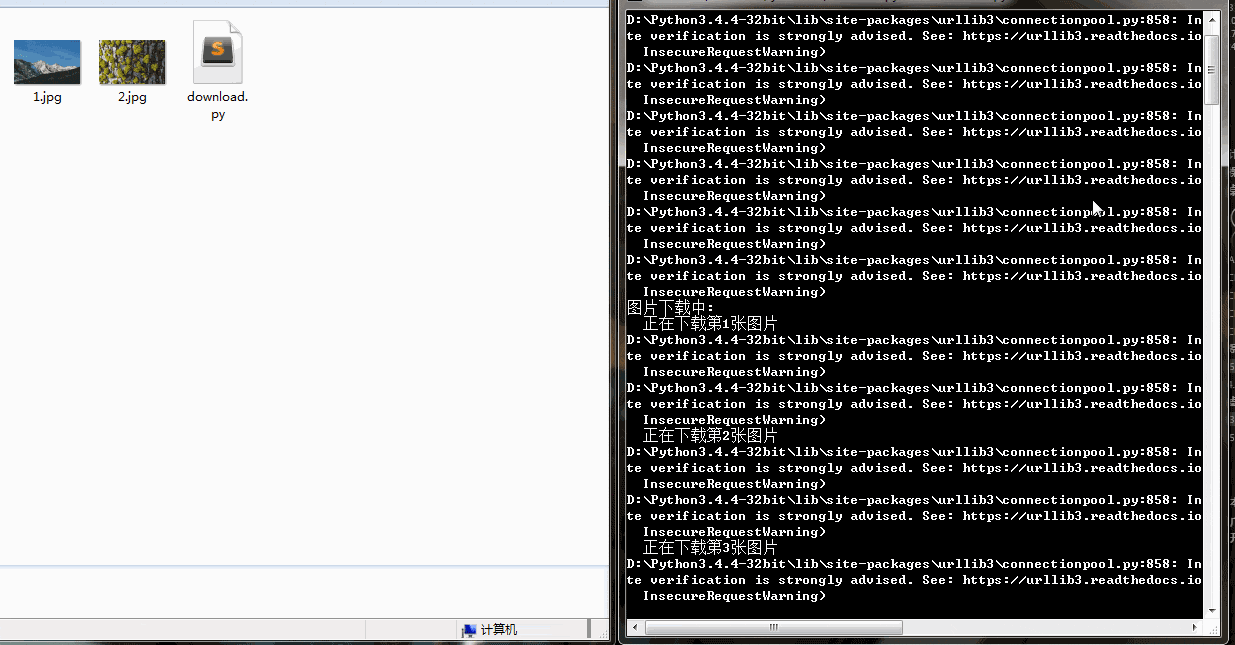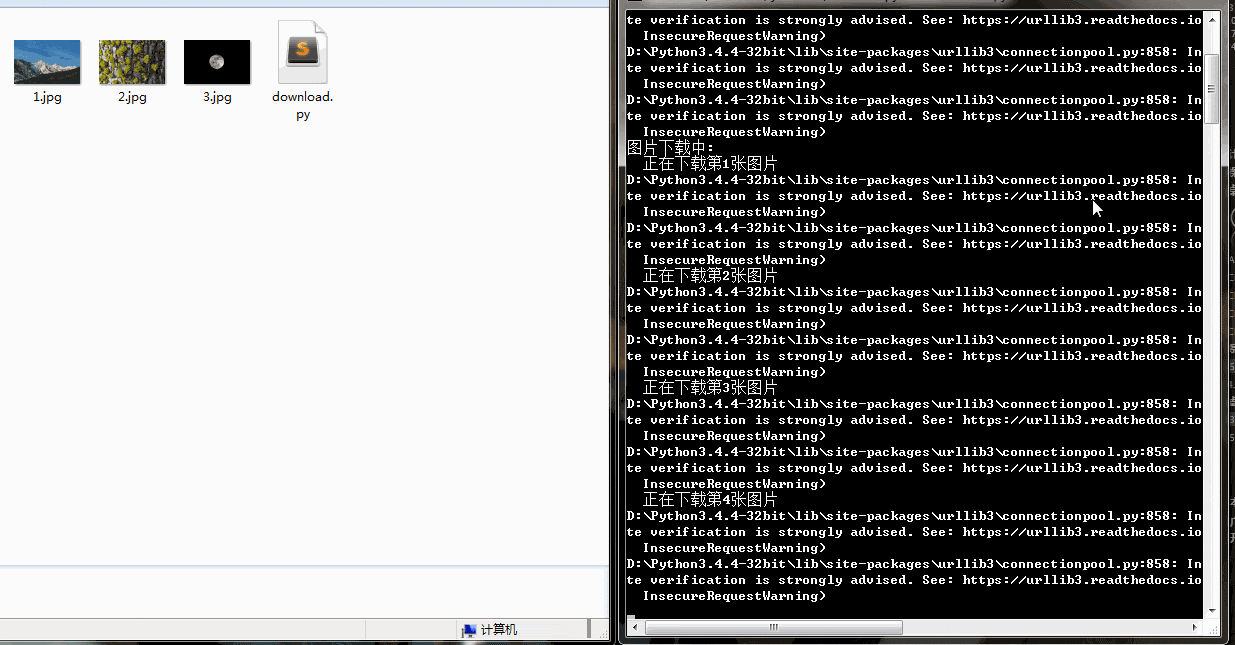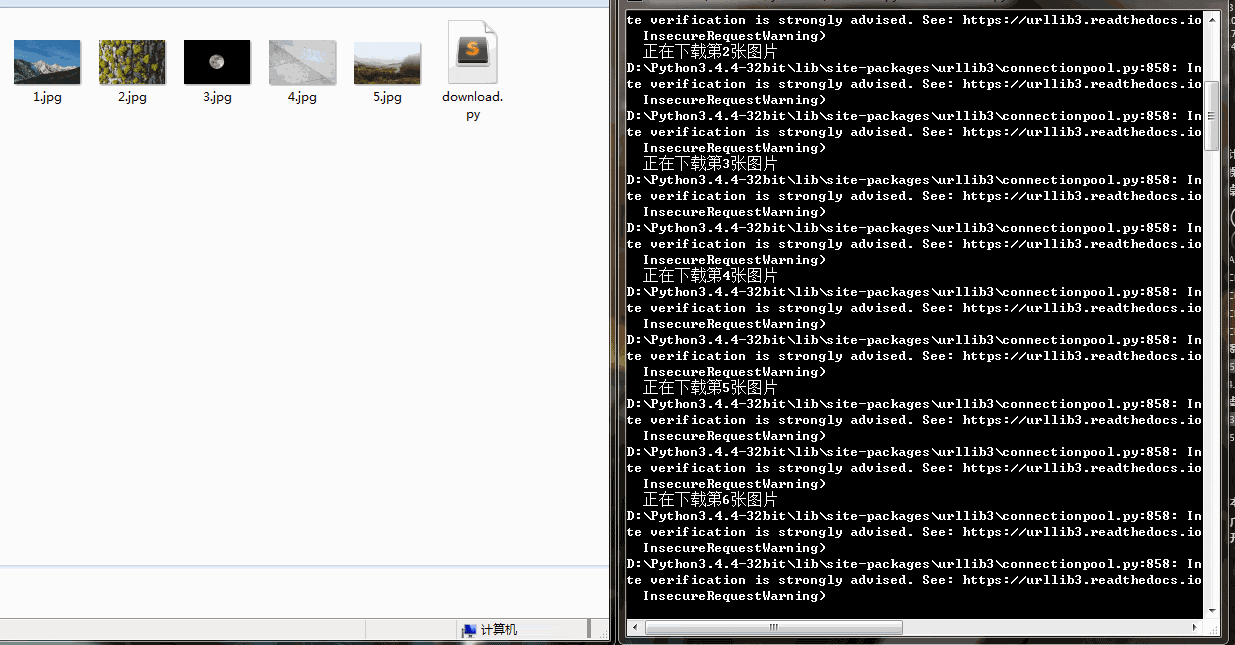
學會了爬取圖片,簡單的動態載入的網站也難不倒你了。趕快試試國內的一些圖片網站吧!
3 愛奇藝VIP視訊下載
(1)實戰背景
愛奇藝的VIP視訊只有會員能看,普通使用者只能看前6分鐘。比如加勒比海盜5:

我們怎麼免費看VIP視訊呢?一個簡單的方法,就是通過旋風視訊VIP解析網站。
這個網站為我們提供了免費的視訊解析,它的通用解析方式是:
http://api.xfsub.com/index.php?url=[播放地址或視訊id]比如,對於繡春刀這個電影,我們只需要在瀏覽器位址列輸入:
http://api.xfsub.com/index.php?url=http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1這樣,我們就可以線上觀看這些VIP視訊了:

但是這個網站只提供了線上解析視訊的功能,沒有提供下載介面,如果想把視訊下載下來,我們就可以利用網路爬蟲進行抓包,將視訊下載下來。
(2)實戰升級
分析方法相同,我們使用Fiddler進行抓包:

相關推薦
Python3網路爬蟲快速入門實戰解析
一 前言 三 爬蟲實戰 優美桌布下載 1實戰背景 2實戰進階 3整合程式碼 愛奇藝VIP視訊下載 1實戰背景 2實戰升級 3編寫程式碼 四 總結 一 前言 強烈建議:請在電腦的陪同下,閱讀本文。本文以實戰為主,閱讀過程
Python3網路爬蟲快速入門實戰解析(一小時入門 Python 3 網路爬蟲)
一 前言三 爬蟲實戰 優美桌布下載 1實戰背景2實戰進階3整合程式碼 愛奇藝VIP視訊下載 1實戰背景2實戰升級3編寫程式碼 四 總結 一 前言 強烈建議:請在電腦的陪同下,閱讀本文。本文以實戰
Flask系列----快速入門實戰解析(上篇)
Flask入門 Flask並不是小白就能隨意入門的,需要基礎知識。例如: Python基礎 網路基礎 Jinja2模板引擎和Werkzeug WSGI套件 工具的使用(PyCharm) 所以,小白請謙虛,請Google不會的專業名稱!我
Python網路爬蟲快速入門到精通
阿里雲大學線上工作坊上線,原理精講+實操演練,讓你真正掌握雲端計算、大資料技能。 Python專家為你詳細講解爬蟲技術的原理與實戰,3大框架詳解+6場實戰演練+反爬技術+分散式爬蟲,講師線上答疑,全面掌握Python爬蟲。 爬蟲有什麼用呢? 你要找工作,想知道哪個崗位當前最熱門,爬取分析
解析庫使用(xPath)〈Python3網路爬蟲開發實戰〉
僅做記錄 XPath對網頁進行解析的過程: from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.htm
Python3網路爬蟲:Scrapy入門實戰之爬取動態網頁圖片
Python版本: python3.+ 執行環境: Mac OS IDE: pycharm 一 前言 二 Scrapy相關方法介紹 1 搭建Scrapy專案 2 shell分析 三 網頁分析
python3爬蟲-快速入門-爬取圖片和標題
瀏覽器 ebr tle path requests itl edi 大致 應用 直接上代碼,先來個爬取豆瓣圖片的,大致思路就是發送請求-得到響應數據-儲存數據,原理的話可以先看看這個 https://www.cnblogs.com/sss4/p/7809821.html
《python3網路爬蟲開發實戰》--Scrapy
1. 架構 引擎(Scrapy):用來處理整個系統的資料流處理, 觸發事務(框架核心) 排程器(Scheduler):用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複
urllib庫的學習總結(python3網路爬蟲開發實戰專案)
urllib庫是python內建的HTTP請求庫,包含以下四個模組: request:最基本的HTTP請求模組,可以用來模擬傳送請求。只需要給庫方法傳入URL以及額外的引數,就可以模擬實現這個過程了。 error:異常處理模組,如果出現請求錯誤,我們可以捕獲這些異常,然後進行重試或其
《python3網路爬蟲開發實戰》--模擬登陸
1.cookies池的搭建 Cookies池需要有自動生成 Cookies、定時檢測 Cookies、提供隨機 Cookies等幾大核心功能。 Cookies 池架構的基本模
selenium學習〈Python3網路爬蟲開發實戰〉
僅做記錄 #動態渲染頁面爬取(selenium) #1)模組匯入 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.comm
《 Python3 網路爬蟲開發實戰》學習筆記1-爬蟲基礎
本記錄將按照本人的學習程序,將學習過程中遇到的問題和重難點如實記錄下來,一個是鞏固自身所學,另一個也希望能對後來人有所幫助。 目錄(第1部分) 第1章開發環境配置 第2章爬蟲基礎 2.1 HTTP基本原理 2.1.1 URI和URL 2.1.2超文字 2.1
python3網路爬蟲-破解天眼查+企業工商資料-分散式爬蟲系統-原始碼深度解析
Python爬蟲-2018年-我破解天眼查和啟信寶企業資料爬蟲--破解反爬技術那些事情 最近在自己用python3+mongdb寫了一套分散式多執行緒的天眼查爬蟲系統,實現了對天眼查整個網站的全部資料各種維度的採集和儲存,主要是為了深入學習爬蟲技術使用,並且根據天眼查網頁的
Python3網路爬蟲:Scrapy入門之使用ImagesPipline下載圖片
Python版本: python3.+ 執行環境: Mac OS IDE: pycharm 一前言 二初識ImagesPipline ImagesPipline的特性 ImagesPipline的工
《Python3網路爬蟲開發實戰》PDF+原始碼+《精通Python爬蟲框架Scrapy》中英文PDF原始碼
下載:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw 《Python 3網路爬蟲開發實戰》中文PDF+原始碼 下載:https://pan.baidu.com/s/1BgQ54kCnGch4eaz4WuoC9w 《精通Pyt
《崔慶才Python3網路爬蟲開發實戰教程》學習筆記(2):常用庫函式的安裝與配置
python的一大優勢就是庫函式極其豐富,網路爬蟲工具的開發使用也是藉助於這一優勢來完成的。那麼要想用Python3做網路爬蟲的開發需要那些庫函式的支援呢? 與網路爬蟲開發相關的庫大約有6種,分別為: 請求庫:requests,selenium,ChromeDrive
讀書隨筆——Python3網路爬蟲開發實戰
說是說讀書隨筆,其實是採坑經驗了 。不管了,我還是隨手記一下吧。我不會說我配置書中要求的環境配置了一天的。我一開始是在一個微信公眾號上看到這本書的,之後在學校圖書館找書的時候突然想起來了,就順手一查,沒想到圖書館裡還有就想借過來玩玩。具體好不好玩看法可能不一樣吧。OK。前面比
Python3網路爬蟲開發實戰——第1章 開發環境
主要是說要爬蟲就要安裝的工具,僅簡單說一下。大部分都能pip安裝。 python3 建議安裝Anaconda,這樣python3和Anaconda同時安裝好了,為以後省去不少麻煩。 請求庫: requests, selenium, chromedriver, geckodr
【 專欄 】- Python3網路爬蟲入門
Python3網路爬蟲入門 歡迎Follow、Star:https://github.com/Jack-Cherish/python-spider 進階教程:http://cuijiahua.com/blog/spider/
記錄Python3網路爬蟲開發實戰的各種坑:Flask安裝(Windows環境下)
1.Flask 的安裝 文章推薦使用pip安裝,命令如下:pip3 install flask 2.測試程式碼 from flask import Flask app = Flask(__name__) @app.route("/")