
Kafka簡介、基本原理、執行流程與使用場景
一、簡介
Apache Kafka是分散式釋出-訂閱訊息系統,在 kafka官網上對 kafka 的定義:一個分散式釋出-訂閱訊息傳遞系統。 它最初由LinkedIn公司開發,Linkedin於2010年貢獻給了Apache基金會併成為頂級開源專案。Kafka是一種快速、可擴充套件的、設計內在就是分散式的,分割槽的和可複製的提交日誌服務。
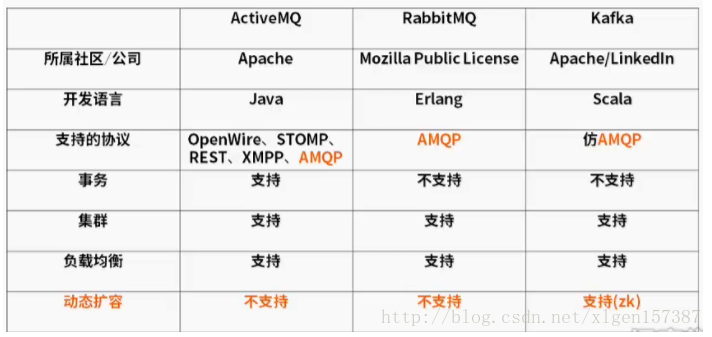
幾種分散式系統訊息系統的對比:
二、Kafka基本架構
它的架構包括以下元件:
1、話題(Topic):是特定型別的訊息流。訊息是位元組的有效負載(Payload),話題是訊息的分類名或種子(Feed)名;
2、生產者(Producer):是能夠釋出訊息到話題的任何物件;
3、服務代理(Broker):已釋出的訊息儲存在一組伺服器中,它們被稱為代理(Broker)或Kafka叢集;
4、消費者(Consumer):可以訂閱一個或多個話題,並從Broker拉資料,從而消費這些已釋出的訊息;
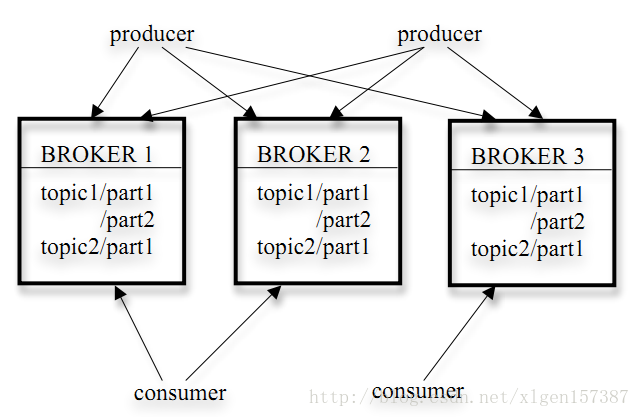
上圖中可以看出,生產者將資料傳送到Broker代理,Broker代理有多個話題topic,消費者從Broker獲取資料。
三、基本原理
我們將訊息的釋出(publish)稱作 producer,將訊息的訂閱(subscribe)表述為 consumer,將中間的儲存陣列稱作 broker(代理),這樣就可以大致描繪出這樣一個場面:

生產者將資料生產出來,交給 broker 進行儲存,消費者需要消費資料了,就從broker中去拿出資料來,然後完成一系列對資料的處理操作。
乍一看返也太簡單了,不是說了它是分散式嗎,難道把 producer、 broker 和 consumer 放在三臺不同的機器上就算是分散式了嗎。看 kafka 官方給出的圖:
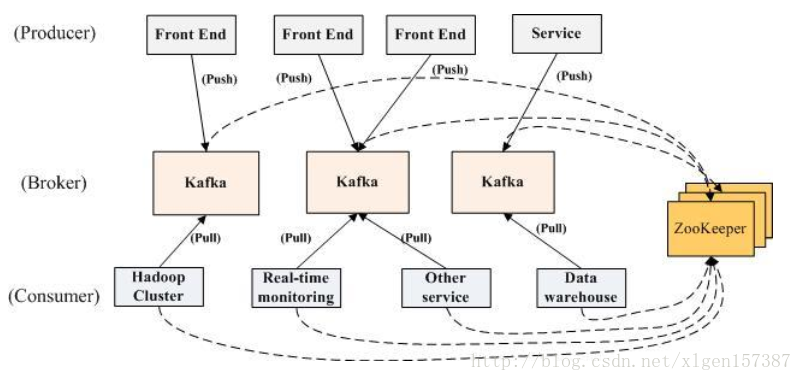
多個 broker 協同合作,producer 和 consumer 部署在各個業務邏輯中被頻繁的呼叫,三者通過 zookeeper管理協調請求和轉發。這樣一個高效能的分散式訊息釋出訂閱系統就完成了。
圖上有個細節需要注意,producer 到 broker 的過程是 push,也就是有資料就推送到 broker,而 consumer 到 broker 的過程是 pull,是通過 consumer 主動去拉資料的,而不是 broker 把資料主懂傳送到 consumer 端的。
四、Zookeeper在kafka的作用
上述,提到了Zookeeper,那麼Zookeeper在kafka的作用是什麼?
(1)無論是kafka叢集,還是producer和consumer都依賴於zookeeper來保證系統可用性叢集儲存一些meta資訊。
(2)Kafka使用zookeeper作為其分散式協調框架,很好的將訊息生產、訊息儲存、訊息消費的過程結合在一起。
(3)同時藉助zookeeper,kafka能夠生產者、消費者和broker在內的所以元件在無狀態的情況下,建立起生產者和消費者的訂閱關係,並實現生產者與消費者的負載均衡。
五、執行流程
首先看一下如下的過程:
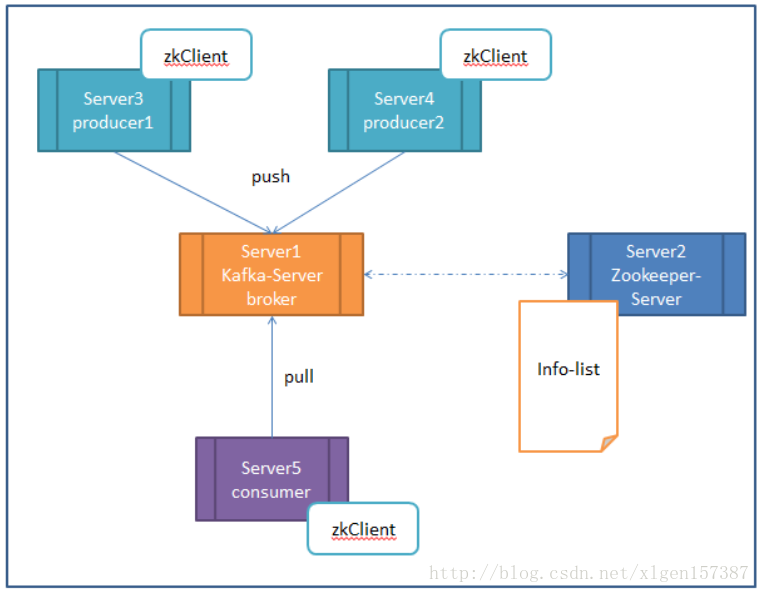
我們看上面的圖,我們把 broker 的數量減少,叧有一臺。現在假設我們按照上圖進行部署:
(1)Server-1 broker 其實就是 kafka 的 server,因為 producer 和 consumer 都要去還它。 Broker 主要還是做儲存用。
(2)Server-2 是 zookeeper 的 server 端,它維持了一張表,記錄了各個節點的 IP、埠等資訊。
(3)Server-3、 4、 5 他們的共同之處就是都配置了 zkClient,更明確的說,就是執行前必須配置 zookeeper的地址,道理也很簡單,這之間的連線都是需要 zookeeper 來進行分發的。
(4)Server-1 和 Server-2 的關係,他們可以放在一臺機器上,也可以分開放,zookeeper 也可以配叢集。目的是防止某一臺掛了。
簡單說下整個系統執行的順序:
(1)啟動zookeeper 的 server
(2)啟動kafka 的 server
(3)Producer 如果生產了資料,會先通過 zookeeper 找到 broker,然後將資料存放到 broker
(4)Consumer 如果要消費資料,會先通過 zookeeper 找對應的 broker,然後消費。
六、Kafka的特性
(1)高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒,每個topic可以分多個partition, consumer group 對partition進行consume操作;
(2)可擴充套件性:kafka叢集支援熱擴充套件;
(3)永續性、可靠性:訊息被持久化到本地磁碟,並且支援資料備份防止資料丟失;
(4)容錯性:允許叢集中節點失敗(若副本數量為n,則允許n-1個節點失敗);
(5)高併發:支援數千個客戶端同時讀寫;
(6)支援實時線上處理和離線處理:可以使用Storm這種實時流處理系統對訊息進行實時進行處理,同時還可以使用Hadoop這種批處理系統進行離線處理;
七、Kafka的使用場景
(1)日誌收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如Hadoop、Hbase、Solr等;
(2)訊息系統:解耦和生產者和消費者、快取訊息等;
(3)使用者活動跟蹤:Kafka經常被用來記錄web使用者或者app使用者的各種活動,如瀏覽網頁、搜尋、點選等活動,這些活動資訊被各個伺服器釋出到kafka的topic中,然後訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到Hadoop、資料倉庫中做離線分析和挖掘;
(4)運營指標:Kafka也經常用來記錄運營監控資料。包括收集各種分散式應用的資料,生產各種操作的集中反饋,比如報警和報告;
(5)流式處理:比如spark streaming和storm;
(6)事件源;
相關閱讀:
參考文章:
相關推薦
Kafka簡介、基本原理、執行流程與使用場景
一、簡介 Apache Kafka是分散式釋出-訂閱訊息系統,在 kafka官網上對 kafka 的定義:一個分散式釋出-訂閱訊息傳遞系統。 它最初由LinkedIn公司開發,Linkedin於2010年貢獻給了Apache基金會併成為頂級開源專案。Kafka
003-spring cloud gateway-概述、基本原理、Route Predicate Factory
默認端口 子網掩碼 彈性 技術 link exc ring ipv4 路由 一、概述 前提條件:Spring 5, Spring Boot 2 and Project Reactor. Spring Cloud Gateway旨在提供一種簡單而有效的方式來路由到
dubbo面試題、基本原理、核心配置
dubbo作為當前國內熱門的RPC框架,其基本原理、配置調優等是面試中會經常問到的,瞭解這些或者知道這些配置項的存在對工作也會事半功倍,遇到類似的問題可以不再去問那個廣告滿天飛的某度了。 1.Dubbo簡介 Dubbo |ˈdʌbəʊ|是一個由阿里巴巴開源的、分散式的RPC(Remote P
kafka入門:簡介、使用場景、設計原理、主要配置及集群搭建(轉)
request 上傳 結構 數據 send gist segments ring 希望 問題導讀: 1.zookeeper在kafka的作用是什麽? 2.kafka中幾乎不允許對消息進行“隨機讀寫”的原因是什麽? 3.kafka集群consumer和producer狀態信息
:Hadoop、NoSQL、分散式、lucene、solr、nutch kafka入門:簡介、使用場景、設計原理、主要配置及叢集搭
需要考慮的影響效能點很多,除磁碟IO之外,我們還需要考慮網路IO,這直接關係到kafka的吞吐量問題.kafka並沒有提供太多高超的技巧;對於producer端,可以將訊息buffer起來,當訊息的條數達到一定閥值時,批量傳送給broker;對於consumer端也是一樣,批量fetch多條訊息.不
kafka入門:簡介、使用場景、設計原理、主要配置及叢集搭建(轉)
問題導讀: 1.zookeeper在kafka的作用是什麼? 2.kafka中幾乎不允許對訊息進行“隨機讀寫”的原因是什麼? 3.kafka叢集consumer和producer狀態資訊是如何儲存的? 4.partitions設計的目的的根本原因是什麼? 一、入門 1、簡介
kafka入門:簡介、使用場景、設計原理、主要配置及叢集搭建
問題導讀: 1.zookeeper在kafka的作用是什麼? 2.kafka中幾乎不允許對訊息進行“隨機讀寫”的原因是什麼? 3.kafka叢集consumer和producer狀態資訊是如何儲存的? 4.partitions設計的目的的根本原因是什麼?
10034---kafka入門:簡介、使用場景、設計原理、主要配置及叢集搭建
一個Topic可以認為是一類訊息,每個topic將被分成多個partition(區),每個partition在儲存層面是append log檔案。任何釋出到此partition的訊息都會被直接追加到log檔案的尾部,每條訊息在檔案中的位置稱為offset(偏移量),offset為一個long型數字,它
kafka入門:簡介、使用場景、設計原理、配置及叢集搭建
問題導讀: 1.zookeeper在kafka的作用是什麼? 2.kafka中幾乎不允許對訊息進行“隨機讀寫”的原因是什麼? 3.kafka叢集consumer和producer狀態資訊是如何儲存的? 4.partitions設計的目的的根本原因是什麼? 一、入
推薦 kafka 簡介、使用場景、設計原理、主要配置及叢集搭建
需要考慮的影響效能點很多,除磁碟IO之外,我們還需要考慮網路IO,這直接關係到kafka的吞吐量問題.kafka並沒有提供太多高超的技巧;對於producer端,可以將訊息buffer起來,當訊息的條數達到一定閥值時,批量傳送給broker;對於consumer端也是一樣,批量fetch多條訊息.不
kafka入門:簡介、使用場景、設計原理、主要配置及叢集搭建http://www.aboutyun.com/thread-9341-1-1.html
文章轉自:http://www.aboutyun.com/thread-9341-1-1.html 問題導讀: 1.zookeeper在kafka的作用是什麼? 2.kafka中幾乎不允許對訊息進行“隨機讀寫”的原因是什麼? 3.kafka叢集consumer和
哈希(Hash)與加密(Encrypt)的基本原理、區別及工程應用
class 區別 自己 裏的 lpad returns .net 角度 table 0、摘要 今天看到吉日嘎拉的一篇關於管理軟件中信息加密和安全的文章,感覺非常有實際意義。文中作者從實踐經驗出發,討論了信息管理軟件中如何通過哈希和加密進行數據保護。但是從文章評論
【轉】哈希(Hash)與加密(Encrypt)的基本原理、區別及工程應用
phy 理論 靈活運用 十分 實際應用 廣泛 tle 多網站 net 0、摘要 今天看到吉日嘎拉的一篇關於管理軟件中信息加密和安全的文章,感覺非常有實際意義。文中作者從實踐經驗出發,討論了信息管理軟件中如何通過哈希和加密進行數據保護。但是從文章評論中也可以
FPGA組成、工作原理和開發流程
1.5 embed nec 基礎 查找 clear 配置 系統性能 發現 FPGA組成、工作原理和開發流程 原創 2012年01月07日 09:11:52 9402 0 4 ********************************LoongEmbedd
Day1 - Python基礎1 介紹、基本語法、流程控制
變量 產生 html Coding 變量的數據類型 1.3 pytho 開頭 class Day1 - Python基礎1 介紹、基本語法、流程控制 1.Python介紹 註:編程語言主要從這幾個角度進行分類,編譯型VS解釋型、動態VS靜態語言和強定義VS弱
常見排序演算法的基本原理、程式碼實現和時間複雜度分析
排序演算法無論是在實際應用還是在工作面試中,都扮演著十分重要的角色。最近剛好在學習演算法導論,所以在這裡對常見的一些排序演算法的基本原理、程式碼實現和時間複雜度分析做一些總結 ,也算是對自己知識的鞏固。 說明: 1.本文所有的結果均按照非降序排列; 2.本文所有的程式均用c++實現,
關於raid的基本原理、軟raid的實現演示
需要 hunk 否則 一個 復制 裝備 容錯 穩定 raid 一、RAID的基本原理1、什麽是RAID?RAID是指磁盤陣列(Redundant Arrays of Independent Drives,RAID),其是由多個價格便宜的磁盤組合成一個容量巨大的磁盤組,以此來
【STM32】SPI的基本原理、庫函式(SPI一般步驟)
《STM32中文參考手冊V10》-第23章 序列外設介面SPI SPI的基本介紹 SPI的簡介 SPI,是英語Serial Peripheral interface的縮寫,顧名思義就是序列外圍裝置介面,是Motorola首先在其MC68HCXX系列處理器上定義
Linux程序間通訊的基本原理、通訊方式及其同步方式的理解
***基本原理***:通常情況下,程式只能訪問自身的資料,和其它程序沒有溝通,每個程序都是一個單獨存在的個體,程序之間不需要協作就可以完成自身的任務了。但隨著需要解決問題複雜性的增加,一個程序不可能完成所有的工作,必須由多個程序之間互相配合才能更快、更好、更強的解決問題,如
ftrace、kpatch、systemtap的基本原理、聯絡和區別
1、ftrace Linux當前版本中,功能最強大的除錯、跟蹤手段。其最基本的功能是提供了動態和靜態探測點,用於探測核心中指定位置上的相關資訊。 靜態探測點,是在核心程式碼中呼叫ftrace提供的相應介面實現,稱之為靜態是因為,是在核心程式碼中寫死的,靜態編譯到核心程式碼中