
十種排序演算法
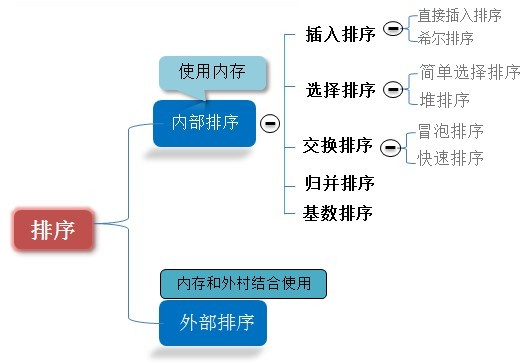
1.常見演算法分類
十種常見排序演算法一般分為以下幾種:
(1)非線性時間比較類排序:交換類排序(快速排序和氣泡排序)、插入類排序(簡單插入排序和希爾排序)、選擇類排序(簡單選擇排序和堆排序)、歸併排序(二路歸併排序和多路歸併排序);
(2)線性時間非比較類排序:計數排序、基數排序和桶排序。
總結:
(1)在比較類排序中,歸併排序號稱最快,其次是快速排序和堆排序,兩者不相伯仲,但是有一點需要注意,資料初始排序狀態對堆排序不會產生太大的影響,而快速排序卻恰恰相反。
(2)線性時間非比較類排序一般要優於非線性時間比較類排序,但前者對待排序元素的要求較為嚴格,比如計數排序要求待排序數的最大值不能太大,桶排序要求元素按照hash分桶後桶內元素的數量要均勻。線性時間非比較類排序的典型特點是以空間換時間。
注:本博文的示例程式碼均已遞增排序為目的。
2.演算法描述與實現
2.1交換類排序
交換排序的基本方法是:兩兩比較待排序記錄的排序碼,交換不滿足順序要求的偶對,直到全部滿足位置。常見的氣泡排序和快速排序就屬於交換類排序。
2.1.1氣泡排序
演算法思想:
從陣列中第一個數開始,依次遍歷陣列中的每一個數,通過相鄰比較交換,每一輪迴圈下來找出剩餘未排序數的中的最大數並”冒泡”至數列的頂端。
演算法步驟:
(1)從陣列中第一個數開始,依次與下一個數比較並次交換比自己小的數,直到最後一個數。如果發生交換,則繼續下面的步驟,如果未發生交換,則陣列有序,排序結束,此時時間複雜度為O(n);
(2)每一輪”冒泡”結束後,最大的數將出現在亂序數列的最後一位。重複步驟(1)。
穩定性:穩定排序。
時間複雜度: O(n)至O(n2),平均時間複雜度為O(n2)。
最好的情況:如果待排序資料序列為正序,則一趟冒泡就可完成排序,排序碼的比較次數為n-1次,且沒有移動,時間複雜度為O(n)。
最壞的情況:如果待排序資料序列為逆序,則氣泡排序需要n-1次趟起泡,每趟進行n-i次排序碼的比較和移動,即比較和移動次數均達到最大值:
比較次數:Cmax=∑i=1n−1(n−i)=n(n−1)/2=O(n2)
移動次數等於比較次數,因此最壞時間複雜度為O(n2)。
示例程式碼:
void bubbleSort(int array[],int len){
//迴圈的次數為陣列長度減一,剩下的一個數不需要排序 2.1.2快速排序
氣泡排序是在相鄰的兩個記錄進行比較和交換,每次交換隻能上移或下移一個位置,導致總的比較與移動次數較多。快速排序又稱分割槽交換排序,是對氣泡排序的改進,快速排序採用的思想是分治思想。。
演算法原理:
(1)從待排序的n個記錄中任意選取一個記錄(通常選取第一個記錄)為分割槽標準;
(2)把所有小於該排序列的記錄移動到左邊,把所有大於該排序碼的記錄移動到右邊,中間放所選記錄,稱之為第一趟排序;
(3)然後對前後兩個子序列分別重複上述過程,直到所有記錄都排好序。
穩定性:不穩定排序。
時間複雜度: O(nlog2n)至O(n2),平均時間複雜度為O(nlgn)。
最好的情況:是每趟排序結束後,每次劃分使兩個子檔案的長度大致相等,時間複雜度為O(nlog2n)。
最壞的情況:是待排序記錄已經排好序,第一趟經過n-1次比較後第一個記錄保持位置不變,並得到一個n-1個元素的子記錄;第二趟經過n-2次比較,將第二個記錄定位在原來的位置上,並得到一個包括n-2個記錄的子檔案,依次類推,這樣總的比較次數是:
Cmax=∑i=1n−1(n−i)=n(n−1)/2=O(n2)
示例程式碼:
//a:待排序陣列,low:最低位的下標,high:最高位的下標
void quickSort(int a[],int low, int high)
{
if(low>=high)
{
return;
}
int left=low;
int right=high;
int key=a[left]; /*用陣列的第一個記錄作為分割槽元素*/
while(left!=right){
while(left<right&&a[right]>=key) /*從右向左掃描,找第一個碼值小於key的記錄,並交換到key*/
--right;
a[left]=a[right];
while(left<right&&a[left]<=key)
++left;
a[right]=a[left]; /*從左向右掃描,找第一個碼值大於key的記錄,並交換到右邊*/
}
a[left]=key; /*分割槽元素放到正確位置*/
quickSort(a,low,left-1);
quickSort(a,left+1,high);
}2.2插入類排序
插入排序的基本方法是:每步將一個待排序的記錄,按其排序碼大小,插到前面已經排序的檔案中的適當位置,直到全部插入完為止。
2.2.1直接插入排序
原理:從待排序的n個記錄中的第二個記錄開始,依次與前面的記錄比較並尋找插入的位置,每次外迴圈結束後,將當前的數插入到合適的位置。
穩定性:穩定排序。
時間複雜度: O(n)至O(n2),平均時間複雜度是O(n2)。
最好情況:當待排序記錄已經有序,這時需要比較的次數是Cmin=n−1=O(n)。
最壞情況:如果待排序記錄為逆序,則最多的比較次數為Cmax=∑i=1n−1(i)=n(n−1)2=O(n2)。
示例程式碼:
//A:輸入陣列,len:陣列長度
void insertSort(int A[],int len)
{
int temp;
for(int i=1;i<len;i++)
{
int j=i-1;
temp=A[i];
//查詢到要插入的位置
while(j>=0&&A[j]>temp)
{
A[j+1]=A[j];
j--;
}
if(j!=i-1)
A[j+1]=temp;
}
}2.2.2 Shell排序
Shell 排序又稱縮小增量排序, 由D. L. Shell在1959年提出,是對直接插入排序的改進。
原理: Shell排序法是對相鄰指定距離(稱為增量)的元素進行比較,並不斷把增量縮小至1,完成排序。
Shell排序開始時增量較大,分組較多,每組的記錄數目較少,故在各組內採用直接插入排序較快,後來增量di逐漸縮小,分組數減少,各組的記錄數增多,但由於已經按di−1分組排序,檔案叫接近於有序狀態,所以新的一趟排序過程較快。因此Shell排序在效率上比直接插入排序有較大的改進。
在直接插入排序的基礎上,將直接插入排序中的1全部改變成增量d即可,因為Shell排序最後一輪的增量d就為1。
穩定性:不穩定排序。
時間複雜度:O(n1.3)到O(n2)。Shell排序演算法的時間複雜度分析比較複雜,實際所需的時間取決於各次排序時增量的個數和增量的取值。研究證明,若增量的取值比較合理,Shell排序演算法的時間複雜度約為O(n1.3)。
對於增量的選擇,Shell 最初建議增量選擇為n/2,並且對增量取半直到 1;D. Knuth教授建議di+1=⌊di−13⌋序列。
//A:輸入陣列,len:陣列長度,d:初始增量(分組數)
void shellSort(int A[],int len, int d)
{
for(int inc=d;inc>0;inc/=2){ //迴圈的次數為增量縮小至1的次數
for(int i=inc;i<len;++i){ //迴圈的次數為第一個分組的第二個元素到陣列的結束
int j=i-inc;
int temp=A[i];
while(j>=0&&A[j]>temp)
{
A[j+inc]=A[j];
j=j-inc;
}
if((j+inc)!=i)//防止自我插入
A[j+inc]=temp;//插入記錄
}
}
}注意:從程式碼中可以看出,增量每次變化取前一次增量的一般,當增量d等於1時,shell排序就退化成了直接插入排序了。
2.3選擇類排序
選擇類排序的基本方法是:每步從待排序記錄中選出排序碼最小的記錄,順序放在已排序的記錄序列的後面,知道全部排完。
2.3.1簡單選擇排序(又稱直接選擇排序)
原理:從所有記錄中選出最小的一個數據元素與第一個位置的記錄交換;然後在剩下的記錄當中再找最小的與第二個位置的記錄交換,迴圈到只剩下最後一個數據元素為止。
穩定性:不穩定排序。
時間複雜度: 最壞、最好和平均複雜度均為O(n2),因此,簡單選擇排序也是常見排序演算法中效能最差的排序演算法。簡單選擇排序的比較次數與檔案的初始狀態沒有關係,在第i趟排序中選出最小排序碼的記錄,需要做n-i次比較,因此總的比較次數是:∑i=1n−1(n−i)=n(n−1)/2=O(n2)。
示例程式碼:
void selectSort(int A[],int len)
{
int i,j,k;
for(i=0;i<len;i++){
k=i;
for(j=i+1;j<len;j++){
if(A[j]<A[k])
k=j;
}
if(i!=k){
A[i]=A[i]+A[k];
A[k]=A[i]-A[k];
A[i]=A[i]-A[k];
}
}
}2.3.2堆排序
直接選擇排序中,第一次選擇經過了n-1次比較,只是從排序碼序列中選出了一個最小的排序碼,而沒有儲存其他中間比較結果。所以後一趟排序時又要重複許多比較操作,降低了效率。J. Willioms和Floyd在1964年提出了堆排序方法,避免這一缺點。
堆的性質:
(1)性質:完全二叉樹或者是近似完全二叉樹;
(2)分類:大頂堆:父節點不小於子節點鍵值,小頂堆:父節點不大於子節點鍵值;圖展示一個最小堆:
(3)左右孩子:沒有大小的順序。
(4)堆的儲存
一般都用陣列來儲存堆,i結點的父結點下標就為(i–1)/2。它的左右子結點下標分別為 2∗i+1 和 2∗i+2。如第0個結點左右子結點下標分別為1和2。
(5)堆的操作
建立:
以最小堆為例,如果以陣列儲存元素時,一個數組具有對應的樹表示形式,但樹並不滿足堆的條件,需要重新排列元素,可以建立“堆化”的樹。
插入:
將一個新元素插入到表尾,即陣列末尾時,如果新構成的二叉樹不滿足堆的性質,需要重新排列元素,下圖演示了插入15時,堆的調整。
刪除:
堆排序中,刪除一個元素總是發生在堆頂,因為堆頂的元素是最小的(小頂堆中)。表中最後一個元素用來填補空缺位置,結果樹被更新以滿足堆條件。
穩定性:不穩定排序。
插入程式碼實現:
每次插入都是將新資料放在陣列最後。可以發現從這個新資料的父結點到根結點必然為一個有序的數列,現在的任務是將這個新資料插入到這個有序資料中,這就類似於直接插入排序中將一個數據併入到有序區間中,這是節點“上浮”調整。不難寫出插入一個新資料時堆的調整程式碼:
//新加入i結點,其父結點為(i-1)/2
//引數:a:陣列,i:新插入元素在陣列中的下標
void minHeapFixUp(int a[], int i)
{
int j, temp;
temp = a[i];
j = (i-1)/2; //父結點
while (j >= 0 && i != 0)
{
if (a[j] <= temp)//如果父節點不大於新插入的元素,停止尋找
break;
a[i]=a[j]; //把較大的子結點往下移動,替換它的子結點
i = j;
j = (i-1)/2;
}
a[i] = temp;
} 因此,插入資料到最小堆時:
//在最小堆中加入新的資料data
//a:陣列,index:插入的下標,
void minHeapAddNumber(int a[], int index, int data)
{
a[index] = data;
minHeapFixUp(a, index);
} 刪除程式碼實現:
按定義,堆中每次都只能刪除第0個數據。為了便於重建堆,實際的操作是將陣列最後一個數據與根結點,然後再從根結點開始進行一次從上向下的調整。
調整時先在左右兒子結點中找最小的,如果父結點不大於這個最小的子結點說明不需要調整了,反之將最小的子節點換到父結點的位置。此時父節點實際上並不需要換到最小子節點的位置,因為這不是父節點的最終位置。但邏輯上父節點替換了最小的子節點,然後再考慮父節點對後面的結點的影響。相當於從根結點將一個數據的“下沉”過程。下面給出程式碼:
//a為陣列,從index節點開始調整,len為節點總數 從0開始計算index節點的子節點為 2*index+1, 2*index+2,len/2-1為最後一個非葉子節點
void minHeapFixDown(int a[],int len,int index){
if(index>(len/2-1))//index為葉子節點不用調整
return;
int tmp=a[index];
int lastIndex=index;
while(index<=(len/2-1)){ //當下沉到葉子節點時,就不用調整了
if(a[2*index+1]<tmp) //如果左子節點大於該節點
lastIndex = 2*index+1;
//如果存在右子節點且大於左子節點和該節點
if(2*index+2<len && a[2*index+2]<a[2*index+1]&& a[2*index+2]<tmp)
lastIndex = 2*index+2;
if(lastIndex!=index){ //如果左右子節點有一個小於該節點則設定該節點的下沉位置
a[index]=a[lastIndex];
index=lastIndex;
}else break; //否則該節點不用下沉調整
}
a[lastIndex]=tmp;//將該節點放到最後的位置
}根據思想,可以有不同版本的程式碼實現,以上是和孫凜同學一起討論出的一個版本,在這裡感謝他的參與,讀者可另行給出。個人體會,這裡建議大家根據對堆調整的過程的理解,寫出自己的程式碼,切勿看示例程式碼去理解演算法,而是理解演算法思想寫出程式碼,否則很快就會忘記。
建堆:
有了堆的插入和刪除後,再考慮下如何對一個數據進行堆化操作。要一個一個的從陣列中取出資料來建立堆吧,不用!先看一個數組,如下圖:
很明顯,對葉子結點來說,可以認為它已經是一個合法的堆了即20,60, 65, 4, 49都分別是一個合法的堆。只要從A[4]=50開始向下調整就可以了。然後再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分別作一次向下調整操作就可以了。下圖展示了這些步驟:
寫出堆化陣列的程式碼:
//建立最小堆
//a:陣列,n:陣列長度
void makeMinHeap(int a[], int n)
{
for (int i = n/2-1; i >= 0; i--)
minHeapFixDown(a, i, n);
} (6)堆排序的實現
由於堆也是用陣列來儲存的,故對陣列進行堆化後,第一次將A[0]與A[n - 1]交換,再對A[0…n-2]重新恢復堆。第二次將A[0]與A[n – 2]交換,再對A[0…n - 3]重新恢復堆,重複這樣的操作直到A[0]與A[1]交換。由於每次都是將最小的資料併入到後面的有序區間,故操作完成後整個陣列就有序了。有點類似於直接選擇排序。
因此,完成堆排序並沒有用到前面說明的插入操作,只用到了建堆和節點向下調整的操作,堆排序的操作如下:
//array:待排序陣列,len:陣列長度
void heapSort(int array[],int len){
//建堆
makeMinHeap(array, len);
//根節點和最後一個葉子節點交換,並進行堆調整,交換的次數為len-1次
for(int i=0;i<len-1;++i){
//根節點和最後一個葉子節點交換
array[0] += array[len-i-1];
array[len-i-1] = array[0]-array[len-i-1];
array[0] = array[0]-array[len-i-1];
//堆調整
minHeapFixDown(array, 0, len-i-1);
}
} (7)堆排序的效能分析
由於每次重新恢復堆的時間複雜度為O(logN),共N - 1次堆調整操作,再加上前面建立堆時N / 2次向下調整,每次調整時間複雜度也為O(logN)。兩次次操作時間相加還是O(N * logN)。故堆排序的時間複雜度為O(N * logN)。
最壞情況:如果待排序陣列是有序的,仍然需要O(N * logN)複雜度的比較操作,只是少了移動的操作;
最好情況:如果待排序陣列是逆序的,不僅需要O(N * logN)複雜度的比較操作,而且需要O(N * logN)複雜度的交換操作。總的時間複雜度還是O(N * logN)。
因此,堆排序和快速排序在效率上是差不多的,但是堆排序一般優於快速排序的重要一點是,資料的初始分佈情況對堆排序的效率沒有大的影響。
2.4歸併排序
演算法思想:
歸併排序屬於比較類非線性時間排序,號稱比較類排序中效能最佳者,在資料中應用中較廣。
歸併排序是分治法(Divide and Conquer)的一個典型的應用。將已有序的子序列合併,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合併成一個有序表,稱為二路歸併。
穩定性:穩定排序演算法;
時間複雜度: 最壞,最好和平均時間複雜度都是Θ(nlgn)。
2.5線性時間非比較類排序
2.5.1計數排序
計數排序是一個非基於比較的排序演算法,該演算法於1954年由 Harold H. Seward 提出,它的優勢在於在對於較小範圍內的整數排序。它的複雜度為Ο(n+k)(其中k是待排序數的範圍),快於任何比較排序演算法,缺點就是非常消耗空間。很明顯,如果而且當O(k)>O(n*log(n))的時候其效率反而不如基於比較的排序,比如堆排序和歸併排序和快速排序。
演算法原理:
基本思想是對於給定的輸入序列中的每一個元素x,確定該序列中值小於x的元素的個數。一旦有了這個資訊,就可以將x直接存放到最終的輸出序列的正確位置上。例如,如果輸入序列中只有17個元素的值小於x的值,則x可以直接存放在輸出序列的第18個位置上。當然,如果有多個元素具有相同的值時,我們不能將這些元素放在輸出序列的同一個位置上,在程式碼中作適當的修改即可。
演算法步驟:
(1)找出待排序的陣列中最大的元素;
(2)統計陣列中每個值為i的元素出現的次數,存入陣列C的第i項;
(3)對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加);
(4)反向填充目標陣列:將每個元素i放在新陣列的第C(i)項,每放一個元素就將C(i)減去1。
時間複雜度:Ο(n+k)。
空間複雜度:Ο(k)。
要求:待排序數中最大數值不能太大。
穩定性:穩定。
程式碼示例:
#define MAXNUM 20 //待排序數的最大個數
#define MAX 100 //待排序數的最大值
int sorted_arr[MAXNUM]={0};
//計算排序
//arr:待排序陣列,sorted_arr:排好序的陣列,n:待排序陣列長度
void countSort(int *arr, int *sorted_arr, int n)
{
int i;
int *count_arr = (int *)malloc(sizeof(int) * (MAX+1));
//初始化計數陣列
memset(count_arr,0,sizeof(int) * (MAX+1));
//統計i的次數
for(i = 0;i<n;i++)
count_arr[arr[i]]++;
//對所有的計數累加,作用是統計arr陣列值和小於小於arr陣列值出現的個數
for(i = 1; i<=MAX; i++)
count_arr[i] += count_arr[i-1];
//逆向遍歷源陣列(保證穩定性),根據計數陣列中對應的值填充到新的陣列中
for(i = n-1; i>=0; i--)
{
//count_arr[arr[i]]表示arr陣列中包括arr[i]和小於arr[i]的總數
sorted_arr[count_arr[arr[i]]-1] = arr[i];
//如果arr陣列中有相同的數,arr[i]的下標減一
count_arr[arr[i]]--;
}
free(count_arr);
}注意:計數排序是典型的以空間換時間的排序演算法,對待排序的資料有嚴格的要求,比如待排序的數值中包含負數,最大值都有限制,請謹慎使用。
2.5.2基數排序
基數排序屬於“分配式排序”(distribution sort),是非比較類線性時間排序的一種,又稱“桶子法”(bucket sort)。顧名思義,它是透過鍵值的部分資訊,將要排序的元素分配至某些“桶”中,藉以達到排序的作用。
具體描述即程式碼示例見本人另一篇blog:基數排序簡介及其並行化。
2.5.3桶排序
桶排序也是分配排序的一種,但其是基於比較排序的,這也是與基數排序最大的區別所在。
思想:桶排序演算法想法類似於散列表。首先要假設待排序的元素輸入符合某種均勻分佈,例如資料均勻分佈在[ 0,1)區間上,則可將此區間劃分為10個小區間,稱為桶,對散佈到同一個桶中的元素再排序。
要求:待排序數長度一致。
排序過程:
(1)設定一個定量的陣列當作空桶子;
(2)尋訪序列,並且把記錄一個一個放到對應的桶子去;
(3)對每個不是空的桶子進行排序。
(4)從不是空的桶子裡把專案再放回原來的序列中。
例如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。這些資料全部在1—100之間。因此我們定製10個桶,然後確定對映函式f(k)=k/10。則第一個關鍵字49將定位到第4個桶中(49/10=4)。依次將所有關鍵字全部堆入桶中,並在每個非空的桶中進行快速排序。
時間複雜度:
對N個關鍵字進行桶排序的時間複雜度分為兩個部分:
(1) 迴圈計算每個關鍵字的桶對映函式,這個時間複雜度是O(N)。
(2) 利用先進的比較排序演算法對每個桶內的所有資料進行排序,對於N個待排資料,M個桶,平均每個桶[N/M]個數據,則桶內排序的時間複雜度為 ∑i=1MO(Ni∗logNi)=O(N∗logNM) 。其中Ni 為第i個桶的資料量。
因此,平均時間複雜度為線性的O(N+C),C為桶內排序所花費的時間。當每個桶只有一個數,則最好的時間複雜度為:O(N)。
示例程式碼:
typedef struct node
{
int keyNum;//桶中數的數量
int key; //儲存的元素
struct node * next;
}KeyNode;
//keys待排序陣列,size陣列長度,bucket_size桶的數量
void inc_sort(int keys[],int size,int bucket_size)
{
KeyNode* k=(KeyNode *)malloc(sizeof(KeyNode)); //用於控制列印
int i,j,b;
KeyNode **bucket_table=(KeyNode **)malloc(bucket_size*sizeof(KeyNode *));
for(i=0;i<bucket_size;i++)
{
bucket_table[i]=(KeyNode *)malloc(sizeof(KeyNode));
bucket_table[i]->keyNum=0;//記錄當前桶中是否有資料
bucket_table[i]->key=0; //記錄當前桶中的資料
bucket_table[i]->next=NULL;
}
for(j=0;j<size;j++)
{
int index;
KeyNode *p;
KeyNode *node=(KeyNode *)malloc(sizeof(KeyNode));
node->key=keys[j];
node->next=NULL;
index=keys[j]/10; //對映函式計算桶號
p=bucket_table[index]; //初始化P成為桶中資料鏈表的頭指標
if(p->keyNum==0)//該桶中還沒有資料
{
bucket_table[index]->next=node;
(bucket_table[index]->keyNum)++; //桶的頭結點記錄桶內元素各數,此處加一
}
else//該桶中已有資料
{
//連結串列結構的插入排序
while(p->next!=NULL&&p->next->key<=node->key)
p=p->next;
node->next=p->next;
p->next=node;
(bucket_table[index]->keyNum)++;
}
}
//列印結果
for(b=0;b<bucket_size;b++)
//判斷條件是跳過桶的頭結點,桶的下個節點為元素節點不為空
for(k=bucket_table[b];k->next!=NULL;k=k->next)
{
printf("%d ",k->next->key);
}
}相關推薦
資料結構十種排序演算法(動圖演示)
0,演算法概述 0.1演算法分類 十種常見排序演算法可以分為兩大類: 非線性時間比較類排序:通過比較來決定元素間的相對次序,由於其時間複雜度不能突破O(nlogn),因此稱為非線性時間比較類排序。 線性時間非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基於比較排
十種排序演算法
1.常見演算法分類 十種常見排序演算法一般分為以下幾種: (1)非線性時間比較類排序:交換類排序(快速排序和氣泡排序)、插入類排序(簡單插入排序和希爾排序)、選擇類排序(簡單選擇排序和堆排序)、歸併排序(二路歸併排序和多路歸併排序); (2)線性時間非比較類排序
【資料結構】十一種排序演算法C++實現
練習了十一種排序演算法的C++實現:以下依次為,冒泡、選擇、希爾、插入、二路歸併、快排、堆排序、計數排序、基數排序、桶排序,可建立sort.h和main.cpp將程式碼放入即可執行。如有錯誤,請指出更正,謝謝交流。 // sort.h # include <
面試官:手撕十大排序演算法,你會幾種?
## 原文連結:[面試官:手撕十大排序演算法,你會幾種?](https://mp.weixin.qq.com/s/VdZ_CMS-RQszFYfoZ_zYqQ) ## 演示地址:[點選檢視演示](https://sm5hw8.coding-pages.com) > 在前面三期,介紹了動態規劃的兩個主要
Java常用的八種排序演算法與程式碼實現(三):桶排序、計數排序、基數排序
三種線性排序演算法:桶排序、計數排序、基數排序 線性排序演算法(Linear Sort):這些排序演算法的時間複雜度是線性的O(n),是非比較的排序演算法 桶排序(Bucket Sort) 將要排序的資料分到幾個有序的桶裡,每個桶裡的資料再單獨進行排序,桶內排完序之後,再把桶裡的
Java常用的八種排序演算法與程式碼實現(二):歸併排序法、快速排序法
注:這裡給出的程式碼方案都是通過遞迴完成的 --- 歸併排序(Merge Sort): 分而治之,遞迴實現 如果需要排序一個數組,我們先把陣列從中間分成前後兩部分,然後對前後兩部分進行分別排序,再將排好序的數組合並在一起,這樣整個陣列就有序了 歸併排序是穩定的排序演算法,時間
[置頂] 找工作知識儲備(3)---從頭說12種排序演算法:原理、圖解、動畫視訊演示、程式碼以及筆試面試題目中的應用
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
五種排序演算法
一:插入排序 二:選擇排序 三:氣泡排序 四:歸併排序 五:快速排序 #include <iostream> #include<vector> #include<algorithm> #include<string>
十大排序演算法的實現 十大經典排序演算法最強總結(含JAVA程式碼實現)
十大經典排序演算法最強總結(含JAVA程式碼實現) 最近幾天在研究排序演算法,看了很多部落格,發現網上有的文章中對排序演算法解釋的並不是很透徹,而且有很多程式碼都是錯誤的,例如有的文章中在“桶排序”演算法中對每個桶進行排序直接使用了Collection.sort
用java實現七種排序演算法。
很多時候,聽別人在討論快速排序,選擇排序,氣泡排序等,都覺得很牛逼,心想,臥槽,排序也分那麼多種,就覺得別人很牛逼呀,其實不然,當我們自己去了解學習後發現,並沒有想象中那麼難,今天就一起總結一下各種排序的實現原理並加以實現。 -WH 一、文章
6分鐘演示,15種排序演算法(視訊)
github:https://github.com/bingmann/sound-of-sorting 排序之聲 - “Audibilization”和排序演算法的視覺化:http://panthema.net/2013/sound-of-sorting/ 視訊:https
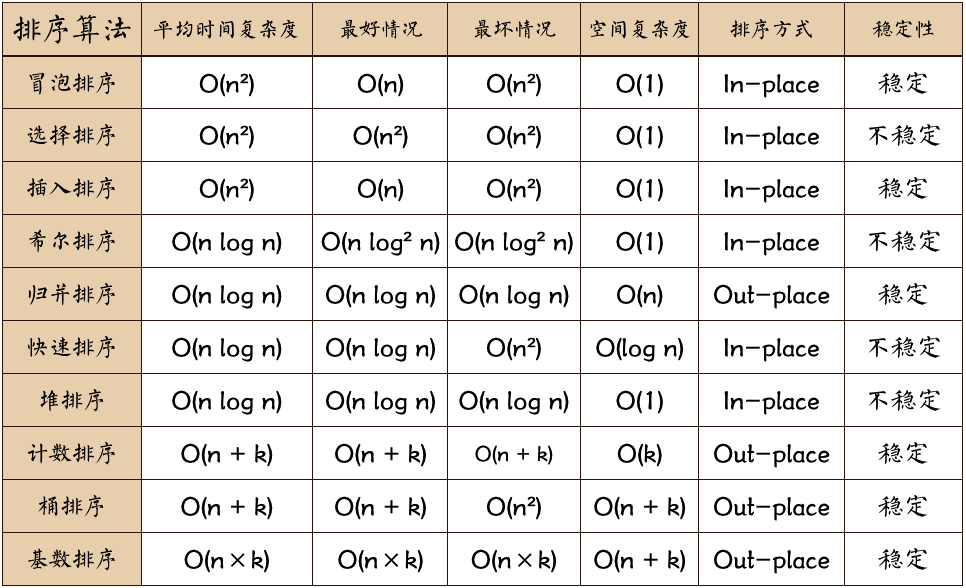
八種排序演算法的時間複雜度複雜度
https://www.cnblogs.com/dll-ft/p/5861210.html 轉載 1、穩定性 歸併排序、氣泡排序、插入排序。基數排序是穩定的 選擇排序、快速排序、希爾排序、堆排序是不穩定的 2、時間複雜度 最基礎的四個演算法:冒泡、選擇
python實現的八種排序演算法
1.快速排序 排序思想: 1.從數列中挑出一個元素,稱為"基準"(pivot) 2.重新排序數列,所有比基準值小的元素放在基準前面,比基準大的元素放在基準後面。在這個分割槽結束之後,該基準就處於數列的中間位置,這就是分割槽操作。 3.遞迴地把小於基準的子數列和大於基準的子數列排序
唔,十種排序
排序的一些重要效能概念: 1,排序的穩定性;2,內排序和外排序; 氣泡排序 主要思想:兩兩比較相鄰元素,出現逆序就交換,知道沒有逆序出現為止。從後向前迴圈,模擬冒泡過程。 時間複雜度: 未優化的氣
Python三種排序演算法的執行速度對比(快速排序、氣泡排序、選擇排序)
最近看了一下快速排序演算法,據說速度比其他的排序演算法快,於是寫了三個排序演算法對比一下,分別是氣泡排序,快速排序,選擇排序,以下是三個排序演算法的程式碼: 氣泡排序 BubbleSort.py # -*- coding:utf8 -*- def Sort(list
幾種排序演算法,記錄一下
個人也就會四種排序(bubble,select,insert,quick),哈哈,看官大人可能有點失望。自己也看過幾種,不過一直沒寫過其他的,就記錄下這四種吧。 程式碼均可直接通過編譯。各種版本實現都有出入,不過思想都是一樣。工作這麼久還沒有一次性完全寫正確過,功力還是差點。 #includ
5 種排序演算法--C語言連結串列
原始碼地址 GitHub:https://github.com/GYT0313/C-DataStructure/blob/master/sortIn5.c 包括: 氣泡排序 快速排序 選擇排序 插入排序 希爾排序 執行: 注意:
演算法圖解-----十種常用演算法
10種演算法 1、二叉查詢樹 節點:左子節點的值都比它小,而右子節點的值都比它大 插入後無需排序, 2、反向索引 搜尋引擎的工作原理,建立一個散列表,鍵為“搜尋詞”,值為“包含搜尋詞的介面”; 3、傅立葉變換 “給它一杯冰沙,它能告訴你其中包含哪些成分”,例如:給定一首歌曲,傅立葉變
【python資料結構與演算法】幾種排序演算法:氣泡排序、快速排序
以下排序演算法,預設的排序結果是從小到大。 一.氣泡排序: 1.氣泡排序思想:越大的元素,就像越大的氣泡。最大的氣泡才能夠浮到最高的位置。 具體來說,即,氣泡排序有兩層迴圈,外層迴圈控制每一輪排序中操作元素的個數——氣泡排序每一輪都會找到遍歷到的元素的最大值,並把它放在最後,下一輪排序時
超炫的6種排序演算法的Python實現
1.氣泡排序 思路:遍歷列表,每一輪每次比較相鄰兩項,將無序的兩項交換,下一輪遍歷比前一輪比較次數減1。 def bubble_sort(a_li