
前端經典面試題: 從輸入URL到頁面載入發生了什麼?
從輸入URL到頁面載入發生了什麼
總體來說分為以下幾個過程:
DNS解析
TCP連線
傳送HTTP請求
伺服器處理請求並返回HTTP報文
瀏覽器解析渲染頁面
連線結束
具體過程
1.DNS解析
DNS解析的過程就是尋找哪臺機器上有你需要資源的過程。當你在瀏覽器中輸入一個地址時,例如www.baidu.com,其實不是百度網站真正意義上的地址。網際網路上每一臺計算機的唯一標識是它的IP地址,但是IP地址並不方便記憶。使用者更喜歡用方便記憶的網址去尋找網際網路上的其它計算機,也就是上面提到的百度的網址。所以網際網路設計者需要在使用者的方便性與可用性方面做一個權衡,這個權衡就是一個網址到IP地址的轉換,這個過程就是DNS解析。它實際上充當了一個翻譯的角色,實現了網址到IP地址的轉換。網址到IP地址轉換的過程是如何進行的?
解析過程
DNS解析是一個遞迴查詢的過程。
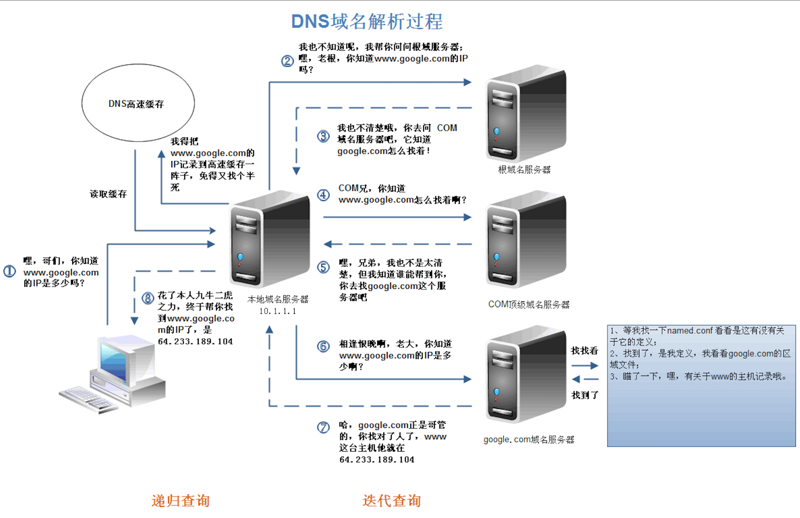
上述圖片是查詢www.google.com的IP地址過程。首先在本地域名伺服器中查詢IP地址,如果沒有找到的情況下,本地域名伺服器會向根域名伺服器傳送一個請求,如果根域名伺服器也不存在該域名時,本地域名會向com頂級域名伺服器傳送一個請求,依次類推下去。直到最後本地域名伺服器得到google的IP地址並把它快取到本地,供下次查詢使用。從上述過程中,可以看出網址的解析是一個從右向左的過程: com -> google.com -> www.google.com。但是你是否發現少了點什麼,根域名伺服器的解析過程呢?事實上,真正的網址是www.google.com.,並不是我多打了一個.,這個.對應的就是根域名伺服器,預設情況下所有的網址的最後一位都是.,既然是預設情況下,為了方便使用者,通常都會省略,瀏覽器在請求DNS的時候會自動加上,所有網址真正的解析過程為: . -> .com -> google.com. -> www.google.com.。
DNS優化
瞭解了DNS的過程,可以為我們帶來哪些?上文中請求到google的IP地址時,經歷了8個步驟,這個過程中存在多個請求(同時存在UDP和TCP請求,為什麼有兩種請求方式,請自行查詢)。如果每次都經過這麼多步驟,是否太耗時間?如何減少該過程的步驟呢?那就是DNS快取。
DNS快取
DNS存在著多級快取,從離瀏覽器的距離排序的話,有以下幾種: 瀏覽器快取,系統快取,路由器快取,IPS伺服器快取,根域名伺服器快取,頂級域名伺服器快取,主域名伺服器快取。
在你的chrome瀏覽器中輸入:chrome://dns/,你可以看到chrome瀏覽器的DNS快取。
系統快取主要存在/etc/hosts(Linux系統)中:
...
DNS負載均衡
不知道大家有沒有思考過一個問題: DNS返回的IP地址是否每次都一樣?如果每次都一樣是否說明你請求的資源都位於同一臺機器上面,那麼這臺機器需要多高的效能和儲存才能滿足億萬請求呢?其實真實的網際網路世界背後存在成千上百臺伺服器,大型的網站甚至更多。但是在使用者的眼中,它需要的只是處理他的請求,哪臺機器處理請求並不重要。DNS可以返回一個合適的機器的IP給使用者,例如可以根據每臺機器的負載量,該機器離使用者地理位置的距離等等,這種過程就是DNS負載均衡,又叫做DNS重定向。大家耳熟能詳的CDN(Content Delivery Network)就是利用DNS的重定向技術,DNS伺服器會返回一個跟使用者最接近的點的IP地址給使用者,CDN節點的伺服器負責響應使用者的請求,提供所需的內容。
2.TCP連線
HTTP協議是使用TCP作為其傳輸層協議的,當TCP出現瓶頸時,HTTP也會受到影響。但由於TCP優化這一塊我平常接觸的並不是很多,再加上大學時的計算機網路的基礎基本上忘完,所以這一部分我也就不在這裡分析了。
HTTPS協議
我不知道把HTTPS放在這個部分是否合適,但是放在這裡好像又說的過去。HTTP報文是包裹在TCP報文中傳送的,伺服器端收到TCP報文時會解包提取出HTTP報文。但是這個過程中存在一定的風險,HTTP報文是明文,如果中間被擷取的話會存在一些資訊洩露的風險。那麼在進入TCP報文之前對HTTP做一次加密就可以解決這個問題了。HTTPS協議的本質就是HTTP + SSL(or TLS)。在HTTP報文進入TCP報文之前,先使用SSL對HTTP報文進行加密。從網路的層級結構看它位於HTTP協議與TCP協議之間。
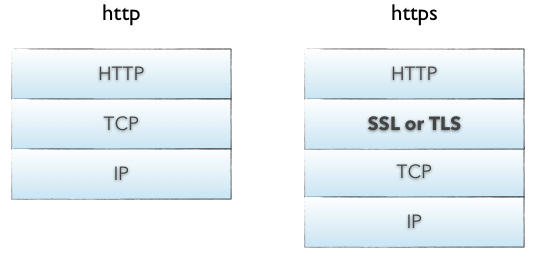
HTTPS過程
HTTPS在傳輸資料之前需要客戶端與伺服器進行一個握手(TLS/SSL握手),在握手過程中將確立雙方加密傳輸資料的密碼資訊。TLS/SSL使用了非對稱加密,對稱加密以及hash等。具體過程請參考經典的阮一峰先生的部落格TLS/SSL握手過程。
HTTPS相比於HTTP,雖然提供了安全保證,但是勢必會帶來一些時間上的損耗,如握手和加密等過程,是否使用HTTPS需要根據具體情況在安全和效能方面做出權衡。
3.HTTP請求
其實這部分又可以稱為前端工程師眼中的HTTP,它主要發生在客戶端。傳送HTTP請求的過程就是構建HTTP請求報文並通過TCP協議中傳送到伺服器指定埠(HTTP協議80/8080, HTTPS協議443)。HTTP請求報文是由三部分組成: 請求行, 請求報頭和請求正文。
請求行
格式如下:Method Request-URL HTTP-Version CRLF
eg: GET index.html HTTP/1.1
常用的方法有: GET, POST, PUT, DELETE, OPTIONS, HEAD。
TODO:
GET和POST有什麼區別?
請求報頭
請求報頭允許客戶端向伺服器傳遞請求的附加資訊和客戶端自身的資訊。
PS: 客戶端不一定特指瀏覽器,有時候也可使用Linux下的CURL命令以及HTTP客戶端測試工具等。
常見的請求報頭有: Accept, Accept-Charset, Accept-Encoding, Accept-Language, Content-Type, Authorization, Cookie, User-Agent等。

上圖是使用Chrome開發者工具擷取的對百度的HTTP請求以及響應報文,從圖中可以看出,請求報頭中使用了Accept, Accept-Encoding, Accept-Language, Cache-Control, Connection, Cookie等欄位。Accept用於指定客戶端用於接受哪些型別的資訊,Accept-Encoding與Accept類似,它用於指定接受的編碼方式。Connection設定為Keep-alive用於告訴客戶端本次HTTP請求結束之後並不需要關閉TCP連線,這樣可以使下次HTTP請求使用相同的TCP通道,節省TCP連線建立的時間。
請求正文
當使用POST, PUT等方法時,通常需要客戶端向伺服器傳遞資料。這些資料就儲存在請求正文中。在請求包頭中有一些與請求正文相關的資訊,例如: 現在的Web應用通常採用Rest架構,請求的資料格式一般為json。這時就需要設定Content-Type: application/json。
4.伺服器處理請求並返回HTTP報文
自然而然這部分對應的就是後端工程師眼中的HTTP。後端從在固定的埠接收到TCP報文開始,這一部分對應於程式語言中的socket。它會對TCP連線進行處理,對HTTP協議進行解析,並按照報文格式進一步封裝成HTTP Request物件,供上層使用。這一部分工作一般是由Web伺服器去進行,我使用過的Web伺服器有Tomcat, Jetty和Netty等等。
HTTP響應報文也是由三部分組成: 狀態碼, 響應報頭和響應報文。
狀態碼
狀態碼是由3位陣列成,第一個數字定義了響應的類別,且有五種可能取值:
1xx:指示資訊–表示請求已接收,繼續處理。
2xx:成功–表示請求已被成功接收、理解、接受。
3xx:重定向–要完成請求必須進行更進一步的操作。
4xx:客戶端錯誤–請求有語法錯誤或請求無法實現。
5xx:伺服器端錯誤–伺服器未能實現合法的請求。
平時遇到比較常見的狀態碼有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500(分別表示什麼請自行查詢)。
TODO:
301和302有什麼區別?
HTTP快取

該圖是本公司對狀態碼的一個總結,繪製而成的status code map,請大家參考。
響應報頭
常見的響應報頭欄位有: Server, Connection...。
響應報文
伺服器返回給瀏覽器的文字資訊,通常HTML, CSS, JS, 圖片等檔案就放在這一部分。
5.瀏覽器解析渲染頁面
瀏覽器在收到HTML,CSS,JS檔案後,它是如何把頁面呈現到螢幕上的?下圖對應的就是WebKit渲染的過程。
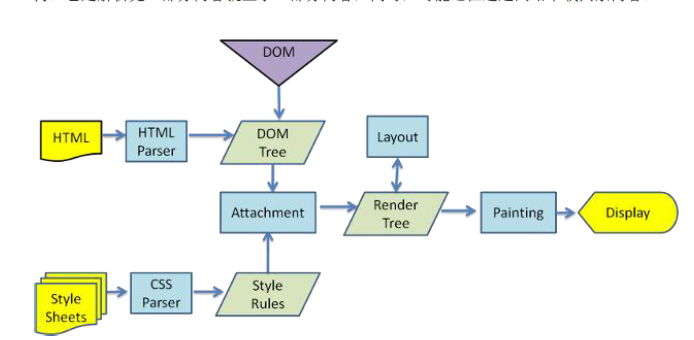
瀏覽器是一個邊解析邊渲染的過程。首先瀏覽器解析HTML檔案構建DOM樹,然後解析CSS檔案構建渲染樹,等到渲染樹構建完成後,瀏覽器開始佈局渲染樹並將其繪製到螢幕上。這個過程比較複雜,涉及到兩個概念: reflow(迴流)和repain(重繪)。DOM節點中的各個元素都是以盒模型的形式存在,這些都需要瀏覽器去計算其位置和大小等,這個過程稱為relow;當盒模型的位置,大小以及其他屬性,如顏色,字型,等確定下來之後,瀏覽器便開始繪製內容,這個過程稱為repain。頁面在首次載入時必然會經歷reflow和repain。reflow和repain過程是非常消耗效能的,尤其是在移動裝置上,它會破壞使用者體驗,有時會造成頁面卡頓。所以我們應該儘可能少的減少reflow和repain。

JS的解析是由瀏覽器中的JS解析引擎完成的。JS是單執行緒執行,也就是說,在同一個時間內只能做一件事,所有的任務都需要排隊,前一個任務結束,後一個任務才能開始。但是又存在某些任務比較耗時,如IO讀寫等,所以需要一種機制可以先執行排在後面的任務,這就是:同步任務(synchronous)和非同步任務(asynchronous)。JS的執行機制就可以看做是一個主執行緒加上一個任務佇列(task queue)。同步任務就是放在主執行緒上執行的任務,非同步任務是放在任務佇列中的任務。所有的同步任務在主執行緒上執行,形成一個執行棧;非同步任務有了執行結果就會在任務佇列中放置一個事件;指令碼執行時先依次執行執行棧,然後會從任務佇列裡提取事件,執行任務佇列中的任務,這個過程是不斷重複的,所以又叫做事件迴圈(Event loop)。
瀏覽器在解析過程中,如果遇到請求外部資源時,如影象,iconfont,JS等。瀏覽器將重複1-6過程下載該資源。請求過程是非同步的,並不會影響HTML文件進行載入,但是當文件載入過程中遇到JS檔案,HTML文件會掛起渲染過程,不僅要等到文件中JS檔案載入完畢還要等待解析執行完畢,才會繼續HTML的渲染過程。原因是因為JS有可能修改DOM結構,這就意味著JS執行完成前,後續所有資源的下載是沒有必要的,這就是JS阻塞後續資源下載的根本原因。CSS檔案的載入不影響JS檔案的載入,但是卻影響JS檔案的執行。JS程式碼執行前瀏覽器必須保證CSS檔案已經下載並載入完畢。
Web優化
上面部分主要介紹了一次完整的請求對應的過程,瞭解該過程的目的無非就是為了Web優化。在談到Web優化之前,我們回到一個更原始的問題,Web前端的本質是什麼。我的理解是: 將資訊快速並友好的展示給使用者並能夠與使用者進行互動。快速的意思就是在儘可能短的時間內完成頁面的載入,試想一下當你在淘寶購買東西的時候,淘寶頁面載入了10幾秒才顯示出物品,這個時候你還有心情去購買嗎?怎麼快速的完成頁面的載入呢?優雅的學院派雅虎給出了常用的一些手段,也就是我們熟悉的雅虎34條軍規。這34軍規實際上就是圍繞請求過程進行的一些優化方式。
如何儘快的載入資源?答案就是能不從網路中載入的資源就不從網路中載入,當我們合理使用快取,將資源放在瀏覽器端,這是最快的方式。如果資源必須從網路中載入,則要考慮縮短連線時間,即DNS優化部分;減少響應內容大小,即對內容進行壓縮。另一方面,如果載入的資源數比較少的話,也可以快速的響應使用者。當資源到達瀏覽器之後,瀏覽器開始進行解析渲染,瀏覽器中最耗時的部分就是reflow,所以圍繞這一部分就是考慮如何減少reflow的次數。
本文轉載自 https://segmentfault.com/a/1190000006879700
感謝分享~分享使人進步~
相關推薦
前端經典面試題: 從輸入URL到頁面載入發生了什麼?
從輸入URL到頁面載入發生了什麼總體來說分為以下幾個過程:DNS解析TCP連線傳送HTTP請求伺服器處理請求並返回HTTP報文瀏覽器解析渲染頁面連線結束具體過程1.DNS解析DNS解析的過程就是尋找哪臺機器上有你需要資源的過程。當你在瀏覽器中輸入一個地址時,例如www.bai
怎麼獲取URL欄的GET或POST請求、面試題:輸入url按回車發生了什麼、JDBC的引數
我本來想查“為什麼URL欄輸入網址,按回車後,使用GET請求方法”(我知道Http請求預設使用GET方法) (1)GET和POST兩種基本請求方法的區別【講解方式很有趣很幽默】 (2)在URL輸入算get還是post【重點講了get與post在"表現形式上、原理上、Http響應上"
深入淺出經典面試題:從瀏覽器中輸入URL到頁面載入發生了什麼 - Part 2
備註: 因為文章太長,所以將它分為三部分,本文是第二部分。 第一部分:深入淺出經典面試題:從瀏覽器中輸入URL到頁面載入發生了什麼 - Part 1 TCP連線 DNS解析返回域名的IP之後,接下來就是瀏覽器要和該IP建立TCP連線了。為什麼是TCP而不是UDP?那是因為HTTP是基於TCP上的。
深入淺出經典面試題:從瀏覽器中輸入URL到頁面載入發生了什麼 - Part 3
深入淺出經典面試題:從瀏覽器中輸入URL到頁面載入發生了什麼 - Part 3 備註: 因為文章太長,所以將它分為三部分,本文是第三部分。 第一部分:深入淺出經典面試題:從瀏覽器中輸入URL到頁面載入發生了什麼 - Part 1 第二部分:深入淺出經典面試題:從瀏覽器中輸入URL到頁
前端經典面試題-代碼
color borde 格式 空格 存在 urn 默認 url convert 1、檢測變量類型。 // 此方法不僅可檢測出6種基本數據類型,還能檢測出Array、Function Object.prototype.toString.call(Array) // [‘Ob
新手小白必知的5道Web前端經典面試題
想成功就業web前端工程師,想要能高薪就業,那麼除了好的web前端技能以外,還得有好的面試技巧,如果提前就瞭解更多企業的面試要求及面試題目,那麼可以讓我們的面試成功的機率大大的提高,今天就給大家分享5道經典的web前端面試題,相信可以祝大家一臂之力。
從輸入URL到頁面載入發生了什麼?(個人閱讀筆記筆記)
DNS解析 TCP連線 發生HTTP報文 伺服器處理請求並返回HTTP報文 瀏覽器解析渲染頁面 連線結束 DNS解析 當你在位址列輸入https://www.csdn.net/,這其實不是網站真實的地址,網際網路上每一臺計算機的唯一標識是它的IP地址,但是
2018Web前端經典面試題合集
javascript: JavaScript中如何檢測一個變數是一個String型別?請寫出函式實現 typeof(obj) === "string" typeof obj === "string" obj.constructor === String 請用js去除字串
2018前端經典面試題
1, html和xml有什麼區別 html是超文字標記語言 xml是可擴充套件標記語言 html語法寬鬆,xml語法嚴謹 html使用固有標記,xml沒有固有標記 html標籤預定義,xml標籤可擴充套件,可定義 html是用來顯示資料的,xml是用來描述和儲
經典面試題——從矩陣的左上角到右下角有多少種方法。
不多說,程式碼獻上,三種方法 #include <iostream> using namespace std; int mat[11][11]; int dp[11]; int main() { int n, m; int i, j; //樸素DP
2018年web前端經典面試題總結整理
對於很多同學來說,面試就是一個考驗,很多人技術上沒有任何問題,但是就是過補了面試那一關,那麼如何提升自己的面試機率呢?當然是瞭解一些面試題了,因為很多時候,一些我們忽略的小問題可能就是企業比較看重的,所以,今天給大家整理總結了一些面試題。希望可以對大家的面試有一定的幫助,可以讓大家更從容面對招聘者的考驗。
2018最新Web前端經典面試題及答案
javascript: JavaScript中如何檢測一個變數是一個String型別?請寫出函式實現 typeof(obj) === "string" typeof obj === "string" obj.constructor === String 請用js去除字
2018年web前端經典面試題總結,你能做對幾個?
對程式設計師小哥哥小姐姐來說,很多時候差的不是技術,卻過不了面試那一關。這時候我們就需要總結分析一下面試題目了,揣摩公司與hr的心理及需求,有時候我們忽略的小問題就是決定能不能拿到offer的重要因素,希望大家都可以找到自己心儀的工作,從容應對面試~ 1、webpack怎麼引入第三方的庫?
前端經典面試題a++和++a 總結及自我解答(1)
1. 如果 a=1 ; b = a++ + (a++) + 1 + (++a) + (a++) + (++a) + a + (++a) = ? 並且這時候a =? 解答: 先說 a =? 首先求a , 有一個極簡單的方法,個人總結啊:
前端經典面試題---CSS篇
什麼是CSS盒模型? css盒子模型又稱框模型 (Box Model) ,包含了元素內容(content)、內邊距(padding)、邊框(border)、外邊距(margin)幾個要素。 標準模式下,一個塊的總寬度= width + margi
2018年web前端經典面試題及答案
javascript: JavaScript中如何檢測一個變數是一個String型別?請寫出函式實現方法1、function isString(obj){ return typeof(obj) === "string"? true: false; //
前端經典面試題---Ajax篇
原生Ajax(相容) function ajax(options){ options = options||{}; var xhr = window.XMLHttpRequest ? (new XMLHttpRequest(
從輸入URL到頁面載入發生了什麼
問題:在瀏覽器中輸入URL到整個頁面顯示在使用者面前時這個過程中到底發生了什麼。仔細思考這個問題,發現確實很深,這個過程涉及到的東西很多。總體來說分為以下幾個過程:DNS解析TCP連線傳送HTTP請求伺服器處理請求並返回HTTP報文瀏覽器解析渲染頁面連線結束具體過程1、DNS
2018 前端經典面試題
三列布局(左右固定;中間自適應)一、流體佈局<!DOCTYPE html> <html lang="en"> <head> <style> .left { float: left; height:
面試必考 瀏覽器輸入URL後面究竟發生了什麼
1.將域名傳輸至DNS伺服器 2.DNS伺服器進行解析 瀏覽器如何通過域名去查詢 URL 對應的 IP 呢 1 瀏覽器的快取 2 作業系統的快取 3 路由的快取 ISP的dns伺服器進行遞迴查詢 瀏覽器通過向 DNS 伺服器傳送域名,DNS 伺服器查詢到與域名相對應的 IP