
Ambari叢集的搭建過程
版本;
Linux: CentOS6.6
臨時節點規劃:

一、五臺虛擬機器的搭建
參考:https://blog.csdn.net/qq_36269293/article/details/79854531
主要是第一臺linux的搭建,克隆之後:
修改主機名:
修改IP地址:
驗證是否能夠聯網等問題
二、叢集環境的搭建
五臺機器搭建完成之後,現在搭建叢集,搭建之前要安裝一些元件:
1. 安裝元件yum –y install httpd
yum –y install ntp
yum -y install yum-utils
yum -y install wget
yum -y install createrepo
yum -y install openssl
yum -y install ruby*
yum -y install redhat-lsb*
yum -y install snappy*2.重啟元件
設定開機自啟動:
chkconfig ntpd on
chkconfig httpd on
重啟元件
service ntpd restart
service httpd restart
檢視時間是否一致
date
不一致的話重啟即可:
reboot3.安裝JDK,配置環境變數
vi /etc/profile
export JAVA_HOME=/usr/local/apps/java/jdk1.8.0_60
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
重新整理:
source /etc/profile
驗證:
java -version
4.修改selinx和禁用THP
vi /etc/selinux/config
修改成: SELINUX=disabled
vi /etc/rc.d/rc.local
新增:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
重啟:
reboot
驗證:
cat /sys/kernel/mm/transparent_hugepage/defrag
cat /sys/kernel/mm/transparent_hugepage/enabled
5.安裝Mysql
解壓
tar -xvf MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tar -C /usr/local/apps/mysql/
檢視系統自帶mysql
rpm -qa | grep mysql
刪除系統自帶mysql
rpm -e mysql-libs-5.1.73-3.el6_5.x86_64 --nodeps
安裝服務端
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
安裝客戶端
rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm
啟動mysql
service mysql start
檢視臨時密碼
cat /root/.mysql_secret
修改密碼
/usr/bin/mysql_secure_installation
6.登入Mysql,建立資料庫以及使用者
mysql -uroot -pgygh123
建立資料庫
create database gygh character set utf8;
create database ambari character set utf8;
create database hive character set utf8;
create database oozie character set utf8;
建立使用者
CREATE USER "gygh"@"%"IDENTIFIED BY "gygh123";
CREATE USER "ambari"@"%"IDENTIFIED BY "ambari123";
CREATE USER "hive"@"%"IDENTIFIED BY "hive123";
CREATE USER "oozie"@"%"IDENTIFIED BY "oozie123";
賦許可權
grant all privileges on *.* to 'gygh'@'%' identified by 'gygh123' with grant option;
grant all privileges on *.* to 'ambari'@'%' identified by 'ambari123' with grant option;
grant all privileges on *.* to 'hive'@'%' identified by 'hive123' with grant option;
grant all privileges on *.* to 'oozie'@'%' identified by 'oozie123' with grant option;
重新整理
FLUSH PRIVILEGES;
FLUSH PRIVILEGES;
FLUSH PRIVILEGES;
7.安裝Ambari
建立資料夾
mkdir -p /var/www/html/ambari
mkdir -p /var/www/html/hdp
mkdir -p /var/www/html/hdp/HDP-UTILS-1.1.0.21
解壓Ambari到資料夾
cd /usr/local/apps/bakDIR
tar -zvxf ambari-2.4.1.0-centos6.tar.gz -C /var/www/html/ambari/
tar -zvxf HDP-2.5.0.0-centos6-rpm.tar.gz -C /var/www/html/hdp/
tar -zvxf HDP-UTILS-1.1.0.21-centos6.tar.gz -C /var/www/html/hdp/HDP-UTILS-1.1.0.21
清空yum
yum clean all
配置yum源
cd /etc/yum.repos.d/
wget –nv http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.4.1.0/ambari.repo -O/etc/yum.repos.d/ambari.repo
wget -nv http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.5.0.0/hdp.repo -O /etc/yum.repos.d/hdp.repo
vi ambari.repo
#VERSION_NUMBER=2.4.1.0-22
[Updates-ambari-2.4.1.0]
name=ambari-2.4.1.0 - Updates
baseurl=http://node06/ambari/AMBARI-2.4.1.0/centos6/
gpgcheck=1
gpgkey=http://node06/ambari/AMBARI-2.4.1.0/centos6/2.4.1.0-22/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
vi hdp.repo
#VERSION_NUMBER=2.5.0.0-1245
[HDP-2.5.0.0]
name=HDP Version - HDP-2.5.0.0
baseurl=http://node06/hdp/HDP/centos6/
gpgcheck=1
gpgkey=http://node06/hdp/HDP/centos6/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.21]
name=HDP-UTILS Version - HDP-UTILS-1.1.0.21
baseurl=http://node06/hdp/HDP-UTILS-1.1.0.21/
gpgcheck=1
gpgkey=http://node06/hdp/HDP-UTILS-1.1.0.21/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
createrepo
createrepo /var/www/html/hdp/HDP/centos6/
createrepo /var/www/html/hdp/HDP-UTILS-1.1.0.21/
createrepo /var/www/html/ambari/AMBARI-2.4.1.0/centos6/
yum makecache
yum repolist
瀏覽器端:http://node06/ambari/ (windows端配置ip地址對映的前提下,沒有配置需要把node06換成ip地址)
http://node06/hdp/
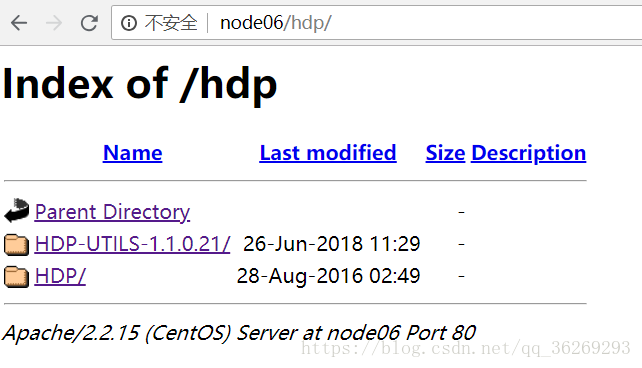
檢視是否有檔案存在
安裝ambari:
yum -y install ambari-server
ambari-server setup(根據提示一步步安裝)
echo $JAVA_HOME
建立 /usr/share/java
將mysql-connector-java-5.1.17.jar 複製到該資料夾下
建立軟連結 ln -s mysql-connector-java-5.1.17.jar mysql-connector-java.jar
備註:如果啟動出現缺失驅動問題,可以執行以下操作:
yum install mysql-connector-java 或者將驅動包放在/usr/share/java 下載入驅動進 ambari 的設定中
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java-5.1.17.jar
執行以下操作:
use ambari
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
安裝完成之後啟動:
ambari-server start
在瀏覽器端訪問:http://node06:8080/
剩下的就是安裝各種元件了。
******************************************************************************************************************************
node01
node02
node03
node04
node05
node06
python /usr/lib/python2.6/site-packages/ambari_agent/HostCleanup.py --silent --skip=node01
python /usr/lib/python2.6/site-packages/ambari_agent/HostCleanup.py --silent --skip=node02
python /usr/lib/python2.6/site-packages/ambari_agent/HostCleanup.py --silent --skip=node03
python /usr/lib/python2.6/site-packages/ambari_agent/HostCleanup.py --silent --skip=node04
python /usr/lib/python2.6/site-packages/ambari_agent/HostCleanup.py --silent --skip=node05
hive啟動命令;
beeline> !connect jdbc:hive2://node04:10000
/usr/hdp/2.5.0.0-1245/hive/bin/beeline -u jdbc:hive2://node06:10000 -n root
相關推薦
redis叢集搭建過程中踩過的幾個坑
這兩天在玩redis的叢集,搭建過程中遇到了以下幾個問題 首先是redis:[ERR] Not all 16384 slots are covered by nodes. 不是所有的slot都被分配
Kubernetes Docker叢集搭建過程
一、環境準備 兩臺裝置,IP分別為95.211(作為Master)和95.217。兩臺裝置的作業系統都是Centos7.3。 二、K8s獲取 三、安裝etcd和flannel 在安裝K8s之前必需要先安裝etcd和flannel。 下載成功後分別解壓,然後將程式加入到
Hadoop偽分散式叢集搭建過程及避坑指南
一個偶然的機會,讓我進了hadoop這個坑。我不得不說,Google真是個非常厲害的公司。為計算機行業貢獻了很多亮瞎雙眼額技術。初入Hadoop一般都要了解HDFS,YARN,Mapreduce。現在來總結一下Hadoop分散式叢集的搭建過程。1.首先準備好相應的安裝包,同時
Hadoop叢集搭建過程問題總結
1.datanode節點無法啟動 (1)無法與slave是通訊 檢查slaves檔案slave節點名稱是否正確 檢查防火牆是否關閉(使用setup命令關閉防火牆,iptables -F 命令有時會失效,chkconfig IPtables on 命令需重啟生效) 檢查/et
Hadoop2.7.3+Spark2.1.0完全分散式叢集搭建過程
1.選取三臺伺服器(CentOS系統64位) 114.55.246.88 主節點 114.55.246.77 從節點 114.55.246.93 從節點 之後的操作如果是用普通使用者操作的話也必須知道root使用者的密碼,因為有些操作是得用root使用者操作。如
Ambari叢集的搭建過程
版本;Linux: CentOS6.6臨時節點規劃: 一、五臺虛擬機器的搭建參考:https://blog.csdn.net/qq_36269293/article/details/79854531主要是第一臺linux的搭建,克隆之後:修改主機名:修改IP地址:驗證是否
搭建hadoop偽分散式叢集環境過程中遇見的問題總結
1、網路配置問題: 在centos7中配置網路環境後,本機(win10系統)與虛擬機器centos7網路不通(本機可以ping通虛擬機器,但是虛擬機器ping不通本機); 解決方式: 方式1:檢視本機win10系統的防火牆是否關閉,若沒有,直接關閉win10系統的防火牆即可; 方式2
高可用HDFS叢集原理筆記及搭建過程
HDFS高可用叢集原理及搭建 如何實現HDFS高可用? HDFS的高可用是HDFS持續對客戶端提供讀、寫服務的能力,因為客戶端對HDFS的讀寫操作之前要訪問namenode伺服器,客戶端需要從namenode端獲取元資料之後才能繼續進行讀、寫。HDFS的高可用的關鍵在於nodenam
redis 叢集詳解及搭建過程
1. 引言 從 3.0 版本開始,redis 具備了叢集功能,實現了分散式、容錯、去中心化等特性,在生產環境中對於保證資料一致性和安全性、提高系統響應能力都有著很必要的意義。 本文我們就來介紹 redis 叢集的三種搭建模式和搭建方法。
HA機制的大資料叢集的搭建過程
叢集規劃 說明: 1、在hadoop2.0中通常由兩個NameNode組成,一個處於active狀態,另一個處於standby狀態。Active NameNode對外提供服務,而Standby NameNode則不對外提供服務,僅同步active nameno
大資料叢集搭建之節點的網路配置過程(二)
緊接著上一章來設定windows的vmnet8的ip地址和虛擬機器中centos的ip地址。 NAT虛擬網路的配置圖如下圖所示: 1、這裡根據VMware中得到的閘道器地址去設定vmnet8的ip地址。 閘道器地址檢視: 2、得到的閘道器地址後去
centos下hadoop叢集搭建詳細過程
Hadoop叢集搭建全過程 參考操作:課本劉鵬《雲端計算》,劉鵬《實戰hadoop》,上網google 需要軟體:VMware-workstation-9.0.exe;CentOS-6.4-i386-bin-DVD1.iso(3.51G,裡面的外掛比較全,VMtools都
搭建ambari叢集
Ambari叢集部署手冊 (ambari離線安裝) 一、名詞介紹: Ambari 叢集管理工具 HDP 叢集軟體儲存庫 Mysql 元資料庫 JDK 開發工具包 https://blog.csdn.net/microhhh/arti
叢集搭建通用過程及一些注意點
叢集搭建通用過程及一些注意點 0.設定靜態ip(vim /etc/sysconfig/network-scripts/ifcfg-eth0 中配置靜態ip),ip不變有利於後面的操作,但其實變了也只需要修改hosts檔案即可,這就是用計算機名的好處。 關於修改網路,當虛擬機器是克隆的
Zookeeper偽分散式叢集環境搭建過程
前言 ZooKeeper是一個分散式的,開放原始碼的分散式應用程式協調服務,目前很多架構都基於它來實現配置維護、域名服務、分散式同步、組服務等等。 ZooKeeper的基本運轉流程: 1.選舉Leader 2.同步資料 3.選舉Leader過程中演算法
Ubuntu14.04下Ambari安裝搭建部署大資料叢集(圖文分五大步詳解)(博主強烈推薦)
不多說,直接上乾貨! 寫在前面的話 (1) 最近一段時間,因擔任我團隊實驗室的大資料環境叢集真實物理機器工作,至此,本人秉持負責、認真和細心的態度,先分別在虛擬機器上模擬搭建ambari(基於CentOS6.5版本)和cloudermanager(基於CentOS6.5或Ub
CentOS6.5下Ambari安裝搭建部署大資料叢集(圖文分五大步詳解)(博主強烈推薦)
第一步: 第二步: 第三步: 第四步: 第五步: 成功! 歡迎大家,加入我的微信公眾號:大資料躺過的坑 人工智慧躺過的坑 同時,大家可以關注我的個人部
搭建Hadoop叢集的過程中的坑
Hadoop預設埠表及用途 埠 用途 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode會連線這個埠 50070 dfs.namenod
HBase完全分散式叢集環境搭建過程總結
一、前言 暑期實驗室實習學姐告知學習HBase,便利用複習之餘的時間搭建HBase環境,先前不瞭解搞了個單機版的,學姐說實驗室開發不用單機2333[尷尬],於是又開始建立虛擬機器開始完全分散式叢集環境的搭建。搭建主要是各種百度,也遇到了一些bug,也來來回回刪增了
kettle工具-叢集模式搭建過程
一、叢集的原理與優缺點1.1叢集的原理 Kettle叢集是由一個主carte伺服器和多個從carte伺服器組成的,類似於master-slave結構,不同的是’master’處理具體任務,只負責任務的分發和收集執行結果。Master carte結點收到請求後,