
Introducing the Aurora Storage Engine
What Is Amazon Aurora?
Amazon Aurora is a MySQL-compatible relational database service that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora provides up to five times better performance than MySQL with the security, availability, and reliability of a commercial database at one tenth the cost. Aurora also has an upcoming PostgreSQL-compatible edition that is available in preview.
In this post, we are going to dive deep into one of the innovations that allows Aurora to deliver this performance, availability and reliability: the storage layer.
The Evolution of Database Storage
Many customers use directly attached storage (DAS) to house their database data. Larger enterprise customers use storage area networks (SAN). These approaches introduce a number of issues:
- SANs are expensive. Many smaller customers cannot afford the physical SAN infrastructure or storage expertise required to manage a SAN.
- Disk storage is complex to scale out for performance. Even when done well, there are still limitations to how far DAS and SAN can scale.
- Both DAS and SAN infrastructure exist in a single physical data center. If this data center is compromised by a power outage or network interruption, the database server is unavailable.
- If a flood, earthquake, or other natural disaster destroys the data center, the data might be lost. If a backup of the data has been kept offsite, it can take anywhere from minutes to days to get the database server back online in a new location.
Introducing the Amazon Aurora Storage Engine
Amazon Aurora was designed to take advantage of the cloud.
Conceptually, the Amazon Aurora storage engine is a distributed SAN that spans multiple AWS Availability Zones (AZs) in a region. An AZ is a logical data center comprised of physical data centers. Each AZ is isolated from the others, except for a low latency link that allows for rapid communication with the other AZs in the region. The distributed, low latency storage engine at the center of Amazon Aurora depends on AZs.
Storage Allocation
Amazon Aurora currently builds its storage volumes in 10 GB logical blocks called protection groups. The data in each protection group is replicated across six storage nodes. Those storage nodes are then allocated across three AZs in the region in which the Amazon Aurora cluster resides.
When the cluster is created, it consumes very little storage. As the volume of data increases and exceeds the currently allocated storage, Aurora seamlessly expands the volume to meet the demand and adds new protection groups, as necessary. Amazon Aurora continues to scale in this way until it reaches its current limit of 64 TB.

How Amazon Aurora Handles Writes
When data is written to Amazon Aurora, it is sent to six storage nodes in parallel. Those storage nodes are spread across three Availability Zones, which significantly improves durability and availability.
On each storage node, the records first enter an in-memory queue. Log records in this queue are deduplicated. For example, in a case in which the master node successfully writes to the storage node, but the connection between the master and storage node is interrupted, the master node retransmits the log record, but the duplicate log record is discarded. The records that are to be kept are hardened to disk in the hot log.
After the records are persisted, the log record is written to an in-memory structure called the update queue. In the update queue, log records are first coalesced and then used to create data pages. If one or more log sequence numbers (LSNs) are determined to be missing, the storage nodes employ a protocol to retrieve the missing LSN(s) from other nodes in the volume. After the data pages are updated, the log record is backed up and then marked for garbage collection. Pages are then asynchronously backed up to Amazon S3.
When the write becomes durable by being written to the hot log, the storage node will acknowledge receipt of the data. After at least four of the six storage nodes acknowledge receipt, the write is considered successful, and acknowledgement is returned to the client application.
One of the reasons Amazon Aurora can write so much faster than other engines is that it only sends log records to the storage nodes and those writes are done in parallel. In fact, on average, compared to MySQL, Amazon Aurora requires approximately 1/8 the IOPS for a similar workload, even though data is being written to six different nodes.
All of the steps in this process are asynchronous. Writes are performed in parallel using group commit to reduce the latency and improve throughput.
Given the low write latency and the reduced I/O footprint, Amazon Aurora is ideally suited for write-intensive applications.
Fault Tolerance
The following diagram shows data stored in three AZs. The replicated data is continuously backed up to S3, which is designed to provide 99.999999999% durability.

This design makes it possible for Amazon Aurora to withstand the loss of an entire AZ or two storage nodes without any availability impact to the client applications.
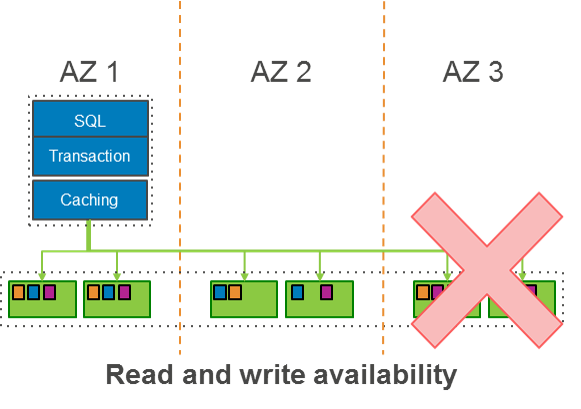
During recovery, Aurora is designed to sustain the loss of an AZ and yet another storage node in a protection group without any loss of data. This is because a write is made durable in Aurora only when it has been persisted to four storage nodes in a protection group. Even if three storage nodes that received the write go down, Aurora can still recover the write from the fourth storage node. To achieve read quorum during recovery, Aurora makes sure that three storage nodes are caught up to the same LSN. However, in order to open the volume for writes, Aurora has to wait for four storage nodes to recover so that it can achieve write quorum for future writes.

For reads, Aurora tries to find the closest storage node to fulfill the read. Each read request is associated with a timestamp, namely an LSN. A storage node can fulfill the read if it is caught up to the LSN (in other words, if it has received all of the updates up to that LSN).
In the event that one or more storage nodes are down or are otherwise unable to communicate with the other storage nodes, those nodes will use the gossip protocol to resynchronize themselves when they come online. If a storage node is lost and a new node is created automatically to take its place, it will also by synchronized through the gossip protocol.
With Amazon Aurora, compute and storage is decoupled. This allows for read replicas to act as compute interfaces to the storage layer without keeping any of the data on the replica itself. This enables read replicas to start serving traffic as soon as the instance comes online without having to synchronize any data. Likewise, the loss of a read replica has no impact on the underlying data. When a read replica becomes the master node, there is no data loss. With support for up to 15 read replicas and built-in load balancing across those read replicas, Amazon Aurora is ideally suited for high availability, read-intensive workloads.
Backup and Recovery
With Amazon Aurora, data is continuously backed up to S3 in real time, with no performance impact to the end user. This eliminates the need for backup windows and automated backup scripts. It also allows users to restore to any point in the user-defined backup retention period. In addition, because all backups are stored in S3, which is highly durable storage, replicated across multiple data centers and designed to provide 99.999999999% durability, the risk of data loss is reduced significantly.
Sometimes users would like to take a snapshot of the data in their Aurora cluster at a specific point in time. Amazon Aurora allows users to do this with no impact on performance.
When restoring from an Amazon Aurora backup, each 10 GB protection group restores in parallel. Additionally, after the protection groups have been restored, there is no need to reapply logs. This means that Amazon Aurora can work at peak performance as soon as the protection groups are restored.
Security
Amazon Aurora allows users to encrypt all data at rest using industry standard AES-256 encryption. Users can also manage keys by using the AWS Key Management Service (AWS KMS). Data in flight can be secured through a TLS connection to the Amazon Aurora cluster. In addition to these features, Amazon Aurora also holds multiple certifications/attestations, including SOC 1, SOC 2, SOC 3, ISO 27001/9001, ISO 27017/27018, and PCI.
Summary
Amazon Aurora was designed for the cloud. By distributing data across multiple Availability Zones, Amazon Aurora provides an extremely durable and highly available database engine. Due to many of the innovations in how and where data is stored, both read and write throughput is significantly improved over other relational database engines. So, too, is the speed with which database restore operations can occur. Finally, due to the fact that Amazon Aurora is a managed service, AWS handles all of the undifferentiated heavy lifting of backups, patching, and storage management.
About the Authors
 Steve Abraham is a principal solutions architect for Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
Steve Abraham is a principal solutions architect for Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
相關推薦
Introducing the Aurora Storage Engine
What Is Amazon Aurora? Amazon Aurora is a MySQL-compatible relational database service that combines the speed and availability of high-end commer
真正解決方案:phpMyAdmin #1089 - Incorrect prefix key; the storage engine doesn't support unique prefix key
fontsize 使用 primary prefix spa ofo mysql- light 處理 先直接給解決方案: 點擊A_I後,不要輸入大小,直接點擊執行!!! 分析 當你在使用phpMyAdmin 創建數據庫表的時候,一般我們需要設置一個主鍵,然後
Got error 28 from storage engine的錯誤處理
l數據庫 方法 設置 作用 剩余空間 none 備份 mysql blank 早上例行檢查數據庫,發現Got error 28 from storage engine這個錯誤,天那,我的數據。心裏哇涼。。。。備份的時間還是很久以前。最近更新了不少,麻煩大了。 好在找到了解決
mysql數據庫報錯[Err] 1286 - Unknown storage engine 'InnoDB'
unknown 打開 重新 data 備註 不能 開頭 完美 日誌文件 打開 my.ini 找到 [mysqld] port=3306 basedir="D:\MySQL Server 5.5" datadir="C:/ProgramData/MySQL/MySQL Ser
Navicat for MySQL出現1030-Got error 28 from storage engine錯誤
Navicat for MySQL出現1030-Got error 28 from storage engine錯誤 剛剛還能用這會兒就用不了了,估計是磁碟空間不足引起的! 在根目錄/下執行命令:df -h [root@localhost ~]# df -h Filesy
Introducing the Münster art exhibition that' Industrie Router s rarer than a solar eclipse
www.inhandnetworks.de Skulptur Projekte Münster is an exhibition that only takes place once every decade. And you’re in luck because this year’s e
Navicat for MySQL出現1030 Got error 28 from storage engine錯誤
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
got error 28 from storage engine mysql
系統在執行查詢列表時,查詢失敗,丟擲如下異常: 後發現伺服器硬碟佔用100%,清理部分檔案之後,重新查詢,正常。 在清理檔案時,因為伺服器原本硬碟空間就比較小,清理所有能清理的檔案之後,也就是降到了90%左右,佔用還是挺高,都考慮是否需要追加硬碟進行擴容了,後想到資料庫中有訪
mysql的“Got error 28 from storage engine”錯誤
Got error 28 from storage engine 原因 磁碟臨時空間不夠導致。 解決辦法: 清空/tmp目錄,或者修
Introducing the Audience Network SDK Beta Program
At Audience Network, we strive to build solutions to help you deliver the best user experience and grow your business. The input we receive from our develo
Introducing the beta for always-on tasks
Update 8 January 2018 -- the beta is temporarily on hold while we sort out some issues that cropped up in the first phase. We'll announce here when
Introducing the latest in textiles: Soft hardware
The latest development in textiles and fibers is a kind of soft hardware that you can wear: cloth that has electronic devices built right into it. Researc
資料庫問題之Got error 28 from storage engine。
問題:Got error 28 from storage engine 原因:儲存引擎不夠,無法執行此SQL語句。 解決方案: 1、在資料庫所在的linux伺服器上,用df檢視磁碟使用情況。 注:df是基於檔案系統總體來計算,通過檔案系統中未分配空間來確定系統中已
mysql 報錯 get error 28 from storage engine 解決方法
登陸 時空 engine 清理 查詢 開發 報錯 mys 百度 研發人員在開發環境調試時反饋,使用客戶端工具連接數據庫之後,點開數據庫就報錯: 1030 Get error 28 from storage engine 於是百度查詢問題,是由於臨時空間不夠,無
Create a Virtual Tape Library Using the AWS Storage Gateway
The AWS Storage Gateway connects an on-premises software appliance with cloud-based storage to integrate your on-premises IT environment with the
Introducing the Smart City Cloud Innovation Center at ASU
Arizona State University (ASU) announced the ASU Smart City Cloud Innovation Center (CIC) powered by AWS, an initiative that focuses on building s
Introducing the AWS Database Ready Program
Introducing the new AWS Database Ready Program, enabling software vendors to modernize their software to support Amazon Aurora. Customers are aski
Introducing the Amazon Simple Notification Service
Today I’d like to tell you about our newest service, the Amazon Simple Notification Service. We want to make it even easier for developers
Introducing the SaaS Enablement Framework for AWS Partners
The software as a service (SaaS) delivery model presents developers with a new landscape of technical, operational, and deployment considerations.
mysql出現1030 Got error 28 from storage engine解決方法
問題表現: 解決方法: mysql 1030 error 沒有足夠的空間,清理磁碟空間即可恢復正常使用。 mysql資料庫就出現了“Got error 28 from storage engine”錯誤,發現問題這樣解決; 1、 XML/HTML程式碼 磁碟臨時空