
Spark-Unit1-spark概述與安裝部署
一、Spark概述
spark官網:spark.apache.org
Spark是用的大規模資料處理的統一計算引擎,它是為大資料處理而設計的快速通用的計算引擎。spark誕生於加油大學伯克利分校AMP實驗室。
mapreduce(MR)與spark的對比:
1.MR在計算中產生的結果儲存在磁碟上,spark儲存在記憶體中;
2.磁碟執行spark的速度是MR的10倍,記憶體執行spark是MR的100多倍;
3.spark並不是為了替代Hadoop,而是為了補充Hadoop;
4.spark沒有儲存,但他可以繼承HDFS。
Spark啟用的是記憶體分散式資料集,而Scala語言可以輕鬆的處理分散式資料集,Scala語言可以說是為Spark而生的,而Spark 的出現推動了Scala語言的發展。
二、Spark特點
1.速度快
磁碟執行spark的速度是MR的10倍,記憶體執行spark是MR的100多倍;
Spark使用最先進的DAG排程程式,查詢優化器和物理執行引擎,實現批處理和流處理的高效能。
註釋:DAG:有向無環圖,上一個RDD的計算結果作為下一個RDD計算的初始值,可以迭代成千上萬次。
查詢優化器:指的是spark sql
批處理:spark sql
流處理:spark streaming
2.便於使用
支援Java/Scala/python/R/SQL編寫應用程式
3.通用性高
不僅支援批處理、流處理,
還支援機器學習(MLlib:machine learning library)和圖形計算(GraphX)
4.相容性高
Spark執行在Hadoop,Apache Mesos。Kubernetes,獨立或雲端。它可以訪問各種資料來源。
Spark實現了Standalone模式作為內建的資源管理和排程框架。
三、Spark的安裝部署
1.準備工作:
新建三臺虛擬機器(建議2G記憶體,1G也可以)/使用遠端連線工具連線 / 關閉防火牆 / 修改主機名
/ 修改對映檔案 / 設定免密登陸 / 安裝jdk(1.8以上版本)
2.在官網下載spark 安裝包(我是2.2.0版本)
然後上傳到Linux系統,解壓,刪包,重新命名
3.修改spark部分配置檔案
進入spark->conf
1)重新命名spark-env.sh.template 為 spark-env.sh,進入該檔案
新增配置資訊:
export JAVA_HOME=/root/sk/jdk1.8.0_132 //jdk安裝路徑
export SPARK_MASTER_HOST=spark-01 //spark主節點機器名
export SPARK_MASTER_PORT=7077 //spark主機點埠號
2)重新命名slaves.template(好像是這個)為slaves,進入該檔案
刪除最後一行“localhost”
新增:spark-02
spark-03 //其他兩臺從節點worker,便於一鍵啟動
4.傳送修改好的spark解壓資料夾到其他兩臺機器
scp -r sprk sprk-02:$PWD
5.啟動spark,訪問web頁面
在spark 的sbin目錄下輸入命令:
./start-all.sh
然後通過ip:埠號訪問UI介面,如:
192.168.50.186:8080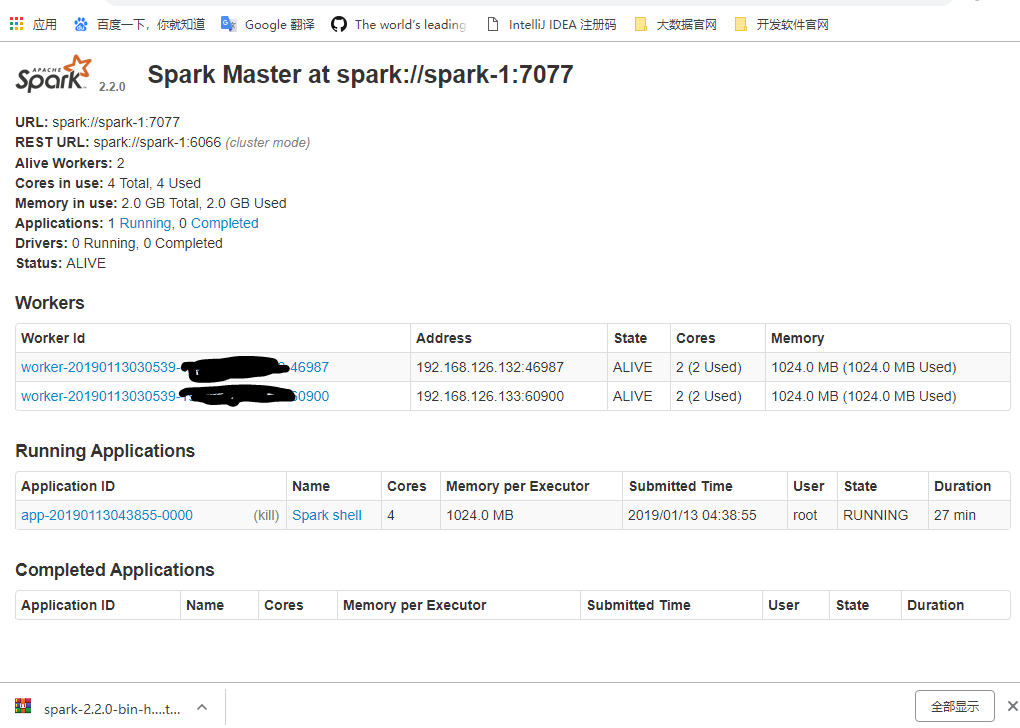
四、Spark的UI介面詳解
URL:統一資源定位符,spark-master的訪問地址
REST URL:可以通過rest的方式訪問叢集
Alive Workers:存活的worker數量
cores in use:可以使用的核心數量
Memory in use:可以使用的記憶體大小
Applications:正在執行和已經完成的應用程式
Driver:通過driver提交的任務情況
Status:節點的狀態