
跟大佬一起讀原始碼:CurrentHashMap的擴容機制
併發程式設計——ConcurrentHashMap#transfer() 擴容逐行分析
前言
ConcurrentHashMap 是併發中的重中之重,也是最常用的資料結果,之前的文章中,我們介紹了 putVal 方法。併發程式設計之 ConcurrentHashMap(JDK 1.8) putVal 原始碼分析。其中分析了 initTable 方法和 putVal 方法,但也留下了一句話:
這篇文章僅僅是 ConcurrentHashMap 的開頭,關於 ConcurrentHashMap 裡面的精華太多,值得我們好好學習。
說道精華,他的擴容方法絕對是精華,要知道,ConcurrentHashMap 擴容是高度併發的。
今天來逐行分析原始碼。
先說結論
首先說結論。原始碼加註釋我會放在後面。該方法的執行邏輯如下:
-
通過計算 CPU 核心數和 Map 陣列的長度得到每個執行緒(CPU)要幫助處理多少個桶,並且這裡每個執行緒處理都是平均的。預設每個執行緒處理 16 個桶。因此,如果長度是 16 的時候,擴容的時候只會有一個執行緒擴容。
-
初始化臨時變數 nextTable。將其在原有基礎上擴容兩倍。
-
死迴圈開始轉移。多執行緒併發轉移就是在這個死迴圈中,根據一個 finishing 變數來判斷,該變數為 true 表示擴容結束,否則繼續擴容。
3.1 進入一個 while 迴圈,分配陣列中一個桶的區間給執行緒,預設是 16. 從大到小進行分配。當拿到分配值後,進行 i-- 遞減。這個 i 就是陣列下標。(
其中有一個 bound 引數,這個引數指的是該執行緒此次可以處理的區間的最小下標,超過這個下標,就需要重新領取區間或者結束擴容,還有一個 advance 引數,該引數指的是是否繼續遞減轉移下一個桶,如果為 true,表示可以繼續向後推進,反之,說明還沒有處理好當前桶,不能推進)
3.2 出 while 迴圈,進 if 判斷,判斷擴容是否結束,如果擴容結束,清空臨死變數,更新 table 變數,更新庫容閾值。如果沒完成,但已經無法領取區間(沒了),該執行緒退出該方法,並將 sizeCtl 減一,表示擴容的執行緒少一個了。如果減完這個數以後,sizeCtl 迴歸了初始狀態,表示沒有執行緒再擴容了,該方法所有的執行緒擴容結束了。(這裡主要是判斷擴容任務是否結束,如果結束了就讓執行緒退出該方法,並更新相關變數)。然後檢查所有的桶,防止遺漏。
3.3 如果沒有完成任務,且 i 對應的槽位是空,嘗試 CAS 插入佔位符,讓 putVal 方法的執行緒感知。
3.4 如果 i 對應的槽位不是空,且有了佔位符,那麼該執行緒跳過這個槽位,處理下一個槽位。
3.5 如果以上都是不是,說明這個槽位有一個實際的值。開始同步處理這個桶。
3.6 到這裡,都還沒有對桶內資料進行轉移,只是計算了下標和處理區間,然後一些完成狀態判斷。同時,如果對應下標內沒有資料或已經被佔位了,就跳過了。 -
處理每個桶的行為都是同步的。防止 putVal 的時候向連結串列插入資料。
4.1 如果這個桶是連結串列,那麼就將這個連結串列根據 length 取於拆成兩份,取於結果是 0 的放在新表的低位,取於結果是 1 放在新表的高位。
4.2 如果這個桶是紅黑數,那麼也拆成 2 份,方式和連結串列的方式一樣,然後,判斷拆分過的樹的節點數量,如果數量小於等於 6,改造成連結串列。反之,繼續使用紅黑樹結構。
4.3 到這裡,就完成了一個桶從舊錶轉移到新表的過程。
好,以上,就是 transfer 方法的總體邏輯。還是挺複雜的。再進行精簡,分成 3 步驟:
- 計算每個執行緒可以處理的桶區間。預設 16.
- 初始化臨時變數 nextTable,擴容 2 倍。
- 死迴圈,計算下標。完成總體判斷。
- 1 如果桶內有資料,同步轉移資料。通常會像連結串列拆成 2 份。
大體就是上的的 3 個步驟。
再來看看原始碼和註釋。
再看原始碼分析
原始碼加註釋:
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*
* transferIndex 表示轉移時的下標,初始為擴容前的 length。
*
* 我們假設長度是 32
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { int n = tab.length, stride; // 將 length / 8 然後除以 CPU核心數。如果得到的結果小於 16,那麼就使用 16。 // 這裡的目的是讓每個 CPU 處理的桶一樣多,避免出現轉移任務不均勻的現象,如果桶較少的話,預設一個 CPU(一個執行緒)處理 16 個桶 if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range 細分範圍 stridea:TODO // 新的 table 尚未初始化 if (nextTab == null) { // initiating try { // 擴容 2 倍 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // 更新 nextTab = nt; } catch (Throwable ex) { // try to cope with OOME // 擴容失敗, sizeCtl 使用 int 最大值。 sizeCtl = Integer.MAX_VALUE; return;// 結束 } // 更新成員變數 nextTable = nextTab; // 更新轉移下標,就是 老的 tab 的 length transferIndex = n; } // 新 tab 的 length int nextn = nextTab.length; // 建立一個 fwd 節點,用於佔位。當別的執行緒發現這個槽位中是 fwd 型別的節點,則跳過這個節點。 ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); // 首次推進為 true,如果等於 true,說明需要再次推進一個下標(i--),反之,如果是 false,那麼就不能推進下標,需要將當前的下標處理完畢才能繼續推進 boolean advance = true; // 完成狀態,如果是 true,就結束此方法。 boolean finishing = false; // to ensure sweep before committing nextTab // 死迴圈,i 表示下標,bound 表示當前執行緒可以處理的當前桶區間最小下標 for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; // 如果當前執行緒可以向後推進;這個迴圈就是控制 i 遞減。同時,每個執行緒都會進入這裡取得自己需要轉移的桶的區間 while (advance) { int nextIndex, nextBound; // 對 i 減一,判斷是否大於等於 bound (正常情況下,如果大於 bound 不成立,說明該執行緒上次領取的任務已經完成了。那麼,需要在下面繼續領取任務) // 如果對 i 減一大於等於 bound(還需要繼續做任務),或者完成了,修改推進狀態為 false,不能推進了。任務成功後修改推進狀態為 true。 // 通常,第一次進入迴圈,i-- 這個判斷會無法通過,從而走下面的 nextIndex 賦值操作(獲取最新的轉移下標)。其餘情況都是:如果可以推進,將 i 減一,然後修改成不可推進。如果 i 對應的桶處理成功了,改成可以推進。 if (--i >= bound || finishing) advance = false;// 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進 // 這裡的目的是:1. 當一個執行緒進入時,會選取最新的轉移下標。2. 當一個執行緒處理完自己的區間時,如果還有剩餘區間的沒有別的執行緒處理。再次獲取區間。 else if ((nextIndex = transferIndex) <= 0) { // 如果小於等於0,說明沒有區間了 ,i 改成 -1,推進狀態變成 false,不再推進,表示,擴容結束了,當前執行緒可以退出了 // 這個 -1 會在下面的 if 塊裡判斷,從而進入完成狀態判斷 i = -1; advance = false;// 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進 }// CAS 修改 transferIndex,即 length - 區間值,留下剩餘的區間值供後面的執行緒使用 else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound;// 這個值就是當前執行緒可以處理的最小當前區間最小下標 i = nextIndex - 1; // 初次對i 賦值,這個就是當前執行緒可以處理的當前區間的最大下標 advance = false; // 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進,這樣對導致漏掉某個桶。下面的 if (tabAt(tab, i) == f) 判斷會出現這樣的情況。 } }// 如果 i 小於0 (不在 tab 下標內,按照上面的判斷,領取最後一段區間的執行緒擴容結束) // 如果 i >= tab.length(不知道為什麼這麼判斷) // 如果 i + tab.length >= nextTable.length (不知道為什麼這麼判斷) if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { // 如果完成了擴容 nextTable = null;// 刪除成員變數 table = nextTab;// 更新 table sizeCtl = (n << 1) - (n >>> 1); // 更新閾值 return;// 結束方法。 }// 如果沒完成 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 嘗試將 sc -1. 表示這個執行緒結束幫助擴容了,將 sc 的低 16 位減一。 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)// 如果 sc - 2 不等於識別符號左移 16 位。如果他們相等了,說明沒有執行緒在幫助他們擴容了。也就是說,擴容結束了。 return;// 不相等,說明沒結束,當前執行緒結束方法。 finishing = advance = true;// 如果相等,擴容結束了,更新 finising 變數 i = n; // 再次迴圈檢查一下整張表 } } else if ((f = tabAt(tab, i)) == null) // 獲取老 tab i 下標位置的變數,如果是 null,就使用 fwd 佔位。 advance = casTabAt(tab, i, null, fwd);// 如果成功寫入 fwd 佔位,再次推進一個下標 else if ((fh = f.hash) == MOVED)// 如果不是 null 且 hash 值是 MOVED。 advance = true; // already processed // 說明別的執行緒已經處理過了,再次推進一個下標 else {// 到這裡,說明這個位置有實際值了,且不是佔位符。對這個節點上鎖。為什麼上鎖,防止 putVal 的時候向連結串列插入資料 synchronized (f) { // 判斷 i 下標處的桶節點是否和 f 相同 if (tabAt(tab, i) == f) { Node<K,V> ln, hn;// low, height 高位桶,低位桶 // 如果 f 的 hash 值大於 0 。TreeBin 的 hash 是 -2 if (fh >= 0) { // 對老長度進行與運算(第一個運算元的的第n位於第二個運算元的第n位如果都是1,那麼結果的第n為也為1,否則為0) // 由於 Map 的長度都是 2 的次方(000001000 這類的數字),那麼取於 length 只有 2 種結果,一種是 0,一種是1 // 如果是結果是0 ,Doug Lea 將其放在低位,反之放在高位,目的是將連結串列重新 hash,放到對應的位置上,讓新的取於演算法能夠擊中他。 int runBit = fh & n; Node<K,V> lastRun = f; // 尾節點,且和頭節點的 hash 值取於不相等 // 遍歷這個桶 for (Node<K,V> p = f.next; p != null; p = p.next) { // 取於桶中每個節點的 hash 值 int b = p.hash & n; // 如果節點的 hash 值和首節點的 hash 值取於結果不同 if (b != runBit) { runBit = b; // 更新 runBit,用於下面判斷 lastRun 該賦值給 ln 還是 hn。 lastRun = p; // 這個 lastRun 保證後面的節點與自己的取於值相同,避免後面沒有必要的迴圈 } } if (runBit == 0) {// 如果最後更新的 runBit 是 0 ,設定低位節點 ln = lastRun; hn = null; } else { hn = lastRun; // 如果最後更新的 runBit 是 1, 設定高位節點 ln = null; }// 再次迴圈,生成兩個連結串列,lastRun 作為停止條件,這樣就是避免無謂的迴圈(lastRun 後面都是相同的取於結果) for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; // 如果與運算結果是 0,那麼就還在低位 if ((ph & n) == 0) // 如果是0 ,那麼建立低位節點 ln = new Node<K,V>(ph, pk, pv, ln); else // 1 則建立高位 hn = new Node<K,V>(ph, pk, pv, hn); } // 其實這裡類似 hashMap // 設定低位連結串列放在新連結串列的 i setTabAt(nextTab, i, ln); // 設定高位連結串列,在原有長度上加 n setTabAt(nextTab, i + n, hn); // 將舊的連結串列設定成佔位符 setTabAt(tab, i, fwd); // 繼續向後推進 advance = true; }// 如果是紅黑樹 else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; // 遍歷 for (Node<K,V> e = t.first; e != null; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); // 和連結串列相同的判斷,與運算 == 0 的放在低位 if ((h & n) == 0) { if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; } // 不是 0 的放在高位 else { if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } // 如果樹的節點數小於等於 6,那麼轉成連結串列,反之,建立一個新的樹 ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; // 低位樹 setTabAt(nextTab, i, ln); // 高位數 setTabAt(nextTab, i + n, hn); // 舊的設定成佔位符 setTabAt(tab, i, fwd); // 繼續向後推進 advance = true; } } } } } } 程式碼加註釋比較長,有興趣可以逐行對照,有 2 個判斷樓主看不懂為什麼這麼判斷,知道的同學可以提醒一下。
然後,說說精華的部分。
- Cmap 支援併發擴容,實現方式是,將表拆分,讓每個執行緒處理自己的區間。如下圖:
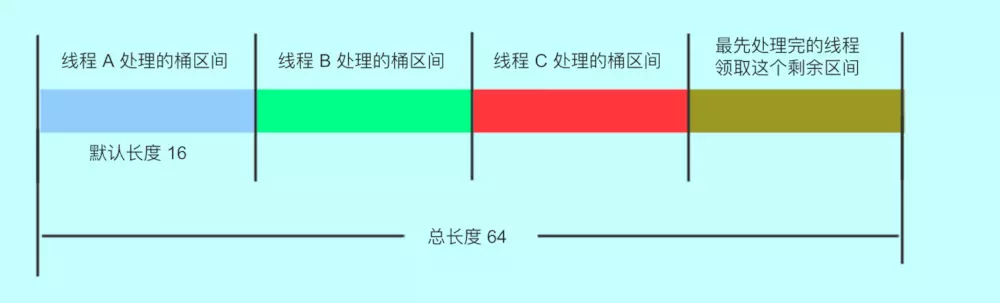
假設總長度是 64 ,每個執行緒可以分到 16 個桶,各自處理,不會互相影響。
- 而每個執行緒在處理自己桶中的資料的時候,是下圖這樣的:
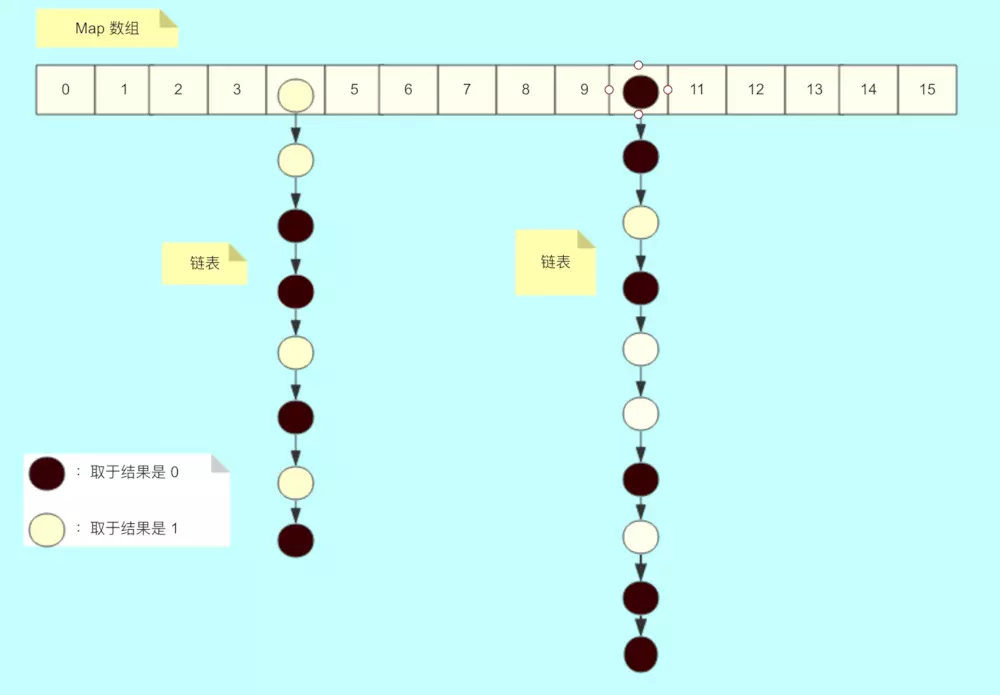
擴容前的狀態。
當對 4 號桶或者 10 號桶進行轉移的時候,會將連結串列拆成兩份,規則是根據節點的 hash 值取於 length,如果結果是 0,放在低位,否則放在高位。
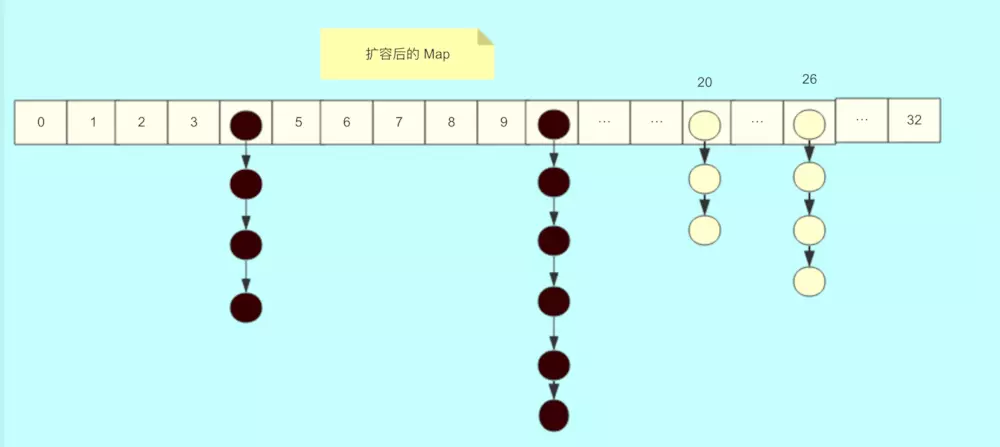
因此,10 號桶的資料,黑色節點會放在新表的 10 號位置,白色節點會放在新桶的 26 號位置。
下圖是迴圈處理桶中資料的邏輯: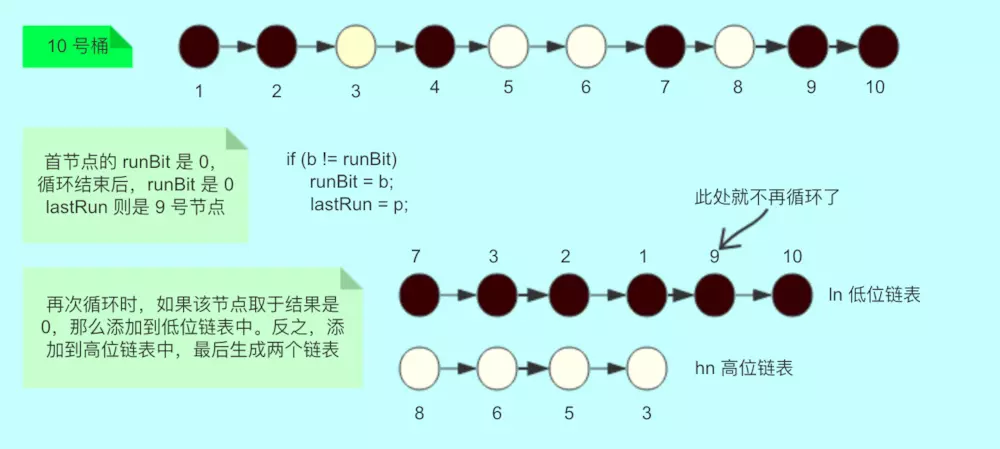
處理完之後,新桶的資料是這樣的:
總結
transfer 方法可以說很牛逼,很精華,內部多執行緒擴容效能很高,
通過給每個執行緒分配桶區間,避免執行緒間的爭用,通過為每個桶節點加鎖,避免 putVal 方法導致資料不一致。同時,在擴容的時候,也會將連結串列拆成兩份,這點和 HashMap 的 resize 方法類似。
而如果有新的執行緒想 put 資料時,也會幫助其擴容。鬼斧神工,令人讚歎。
作者:莫那一魯道
連結:https://www.jianshu.com/p/2829fe36a8dd
來源:簡書
簡書著作權歸作者所有,任何形式的轉載都請聯絡作者獲得授權並註明出處。
深入理解ConcurrentHashMap原理分析以及執行緒安全性問題
在之前的文章提到ConcurrentHashMap是一個執行緒安全的,那麼我麼看一下ConcurrentHashMap如何進行操作的。
ConcurrentHashMap與HashTable區別?
HashTable
put()原始碼
從程式碼可以看出來在所有put 的操作的時候 都需要用 synchronized 關鍵字進行同步。並且key 不能為空。
這樣相當於每次進行put 的時候都會進行同步 當10個執行緒同步進行操作的時候,就會發現當第一個執行緒進去 其他執行緒必須等待第一個執行緒執行完成,才可以進行下去。效能特別差。
CurrentHashMap
分段鎖技術:ConcurrentHashMap相比 HashTable而言解決的問題就是 的 它不是鎖全部資料,而是鎖一部分資料,這樣多個執行緒訪問的時候就不會出現競爭關係。不需要排隊等待了。
從圖中可以看出來ConcurrentHashMap的主幹是個Segment陣列。
這就是為什麼ConcurrentHashMap支援允許多個修改同時併發進行,原因就是採用的Segment分段鎖功能,每一個Segment 都想的於小的hash table並且都有自己鎖,只要修改不再同一個段上就不會引起併發問題。
final Segment<K,V>[] segments;
1
使用ConConcurrentHashMap時候 有時候會遇到跨段的問題,跨段的時候【size()、 containsValue()】,可能需要鎖定部分段或者全段,當操作結束之後,又回按照 順序 進行 釋放 每一段的鎖。注意是按照順序解鎖的。,每個Segment又包含了多個HashEntry.
transient volatile HashEntry<K,V>[] table;
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
//其他省略
}
1
2
3
4
5
6
7
8
9
需要注意的是 Segment 是一種可重入鎖(繼承ReentrantLock)
那麼我簡單說一下ReentrantLock 與synchronized有什麼區別?
synchronized 是一個同步鎖 synchronized (this)
同步鎖 當一個執行緒A 訪問 【資源】的程式碼同步塊的時候,A執行緒就會持續持有當前鎖的狀態,如果其他執行緒B-E 也要訪問【資源】的程式碼同步塊的時候將會收到阻塞,因此需要排隊等待A執行緒釋放鎖的狀態。(如圖情況1)但是注意的是,當一個執行緒B-E 只是不能方法 A執行緒 【資源】的程式碼同步塊,仍然可以訪問其他的非資源同步塊。
ReentrantLock 可重入鎖 通常兩類:公平性、非公平性
公平性:根據執行緒請求鎖的順序依次獲取鎖,當一個執行緒A 訪問 【資源】的期間,執行緒A 獲取鎖資源,此時內部存在一個計數器num+1,在訪問期間,執行緒B、C請求 資源時,發現A 執行緒在持有當前資源,因此在後面生成節點排隊(B 處於待喚醒狀態),假如此時a執行緒再次請求資源時,不需要再次排隊,可以直接再次獲取當前資源 (內部計數器+1 num=2) ,當A執行緒釋放所有鎖的時候(num=0),此時會喚醒B執行緒進行獲取鎖的操作,其他C-E執行緒就同理。(情況2)
非公平性:當A執行緒已經釋放所之後,準備喚醒執行緒B獲取資源的時候,此時執行緒M 獲取請求,此時會出現競爭,執行緒B 沒有競爭過M執行緒,測試M獲取的執行緒因此,M會有限獲得資源,B繼續睡眠。(情況2)
synchronized 是一個非公平性鎖。 非公平性 會比公平性鎖的效率要搞很多原因,不需要通知等待。
ReentrantLock 提供了 new Condition可以獲得多個Condition物件,可以簡單的實現比較複雜的執行緒同步的功能.通過await(),signal()以實現。
ReentrantLock 提供可以中斷鎖的一個方法lock.lockInterruptibly()方法。
Jdk 1.8 synchronized和 ReentrantLock 比較的話,官方比較建議用synchronized。
在瞭解Segment 機制之後我們繼續看一下ConcurrentHashMap核心構造方法程式碼。
// 跟HashMap結構有點類似
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;//負載因子
this.threshold = threshold;//閾值
this.table = tab;//主幹陣列即HashEntry陣列
}
1
2
3
4
5
6
7
構造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//MAX_SEGMENTS 為1<<16=65536,也就是最大併發數為65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
//ssize 為segments陣列長度,concurrentLevel計算得出
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//segmentShift和segmentMask這兩個變數在定位segment時會用到
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//計算cap的大小,即Segment中HashEntry的陣列長度,cap也一定為2的n次方.
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
//建立segments陣列並初始化第一個Segment,其餘的Segment延遲初始化
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
從以上程式碼可以看出ConcurrentHashMap有比較重要的三個引數:
loadFactor 負載因子 0.75
threshold 初始 容量 16
concurrencyLevel 實際上是Segment的實際數量。
ConcurrentHashMap如何發生ReHash?
ConcurrentLevel 一旦設定的話,就不會改變。ConcurrentHashMap當元素個數大於臨界值的時候,就會發生擴容。但是ConcurrentHashMap與其他的HashMap不同的是,它不會對Segmengt 數量增大,只會增加Segmengt 後面的連結串列容量的大小。即對每個Segmengt 的元素進行的ReHash操作。
我們再看一下核心的ConcurrentHashMapput ()方法:
public V put(K key, V value) {
Segment<K,V> s;
//concurrentHashMap不允許key/value為空
if (value == null)
throw new NullPointerException();
//hash函式對key的hashCode重新雜湊,避免差勁的不合理的hashcode,保證雜湊均勻
int hash = hash(key);
//返回的hash值無符號右移segmentShift位與段掩碼進行位運算,定位segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
主要注意的是 當前put 方法 當前key 為空的時候 ,程式碼報錯。
這個程式碼主要是把Key 通過Hash函式計算出hash值 現計算出當前key屬於那個Segment 呼叫Segment.put 分段方法Segment.put()
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);
//tryLock()是ReentrantLock獲取鎖一個方法。如果當前執行緒獲取鎖成功 返回true,如果別線程獲取了鎖返回false不成功時會遍歷定位到的HashEnry位置的連結串列(遍歷主要是為了使CPU快取連結串列),若找不到,則建立HashEntry。tryLock一定次數後(MAX_SCAN_RETRIES變數決定),則lock。若遍歷過程中,由於其他執行緒的操作導致連結串列頭結點變化,則需要重新遍歷。
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//定位HashEntry,可以看到,這個hash值在定位Segment時和在Segment中定位HashEntry都會用到,只不過定位Segment時只用到高几位。
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//若c超出閾值threshold,需要擴容並rehash。擴容後的容量是當前容量的2倍。這樣可以最大程度避免之前雜湊好的entry重新雜湊。擴容並rehash的這個過程是比較消耗資源的。
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
Put 時候 ,通過Hash函式將即將要put 的元素均勻的放到所需要的Segment 段中,呼叫Segment的put 方法進行資料。
Segment的put 是加鎖中完成的。如果當前元素數大於最大臨界值的的話將會產生rehash. 先通過 getFirst 找到連結串列的表頭部分,然後遍歷連結串列,呼叫equals 比配是否存在相同的key ,如果找到的話,則將最新的Key 對應value值。如果沒有找到,新增一個HashEntry 它加到整個Segment的頭部。
我們先看一下Get 方法的原始碼:
//計算Segment中元素的數量
transient volatile int count;
***********************************************************
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
***********************************************************
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
********************************************************
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1.讀取的時候 傳遞Key值,通過Hash函式計算出 對應Segment 的位置。
2.呼叫segmentFor(int hash) 方法,用於確定操作應該在哪一個segment中進行 ,通過 右無符號位運算 右移segmentShift位在與運算 segmentMask【偏移碼】 獲得需要操作的Segment
確定了需要操作的Segment 再呼叫 get 方法獲取對應的值。通過count 值先判斷當前值是否為空。在呼叫getFirst()獲取頭節點,然後遍歷列表通過equals對比的方式進行比對返回值。
ConcurrentHashMap為什麼讀的時候不加鎖?
ConcurrentHashMap是分段併發分段進行讀取資料的。
Segment 裡面有一個Count 欄位,用來表示當前Segment中元素的個數 它的型別是volatile變數。所有的操作到最後都會 在最後一部更新count 這個變數,由於volatile變數 happer-before的特性。導致get 方法能夠幾乎準確的獲取最新的結構更新。
再看一下ConcurrentHashMapRemove()方法:
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
呼叫Segment 的remove 方法,先定位當前要刪除的元素C,此時需要把A、B元素全部複製一遍,一個一個接入到D上。
remove 也是在加鎖的情況下進行的。
volatile 變數
我們發現 對於CurrentHashMap而言的話,原始碼裡面又很多地方都用到了這個變數。比如HashEntry 、value 、Segment元素個數Count。
volatile 屬於JMM 模型中的一個詞語。首先先簡單說一下 Java記憶體模型中的 幾個概念:
原子性:保證 Java記憶體模型中原子變數記憶體操作的。通常有 read、write、load、use、assign、store、lock、unlock等這些。
可見性:就是當一個執行緒對一個變數進行了修改,其他執行緒即可立即得到這個變數最新的修改資料。
有序性:如果在本執行緒內觀察,所有操作都是有序的;如果在一個執行緒中觀察另一個執行緒,所有操作都是無序的。
先行發生:happen-before 先行發生原則是指Java記憶體模型中定義的兩項操作之間的依序關係,如果說操作A先行發生於操作B,其實就是說發生操作B之前.
傳遞性
volatile 變數 與普通變數的不同之處?
volatile 是有可見性,一定程度的有序性。
volatile 賦值的時候新值能夠立即重新整理到主記憶體中去,每次使用的時候能夠立刻從記憶體中重新整理。
做一個簡單例子看一下 這個功能
public class VolatileTest{
int a=1;
int b=2;
//賦值操作
public void change(){
a=3;
b=a;
}
//列印操作
public void print(){
System.out.println("b:"+b+",a:"+a);
}
@Test
public void testNorMal(){
VolatileTest vt=new VolatileTest();
for (int i = 0; i < 100000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
vt.change();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
vt.print();
}
}).start();
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
跑了 n 次會出現一條 b=3,a=1 的錯誤列印記錄。這就是因為普通變數相比volatile 不存在 可見性。
---------------------
作者:技術小排骨
來源:CSDN
原文:https://blog.csdn.net/jjc120074203/article/details/78625433
版權宣告:本文為博主原創文章,轉載請附上博文連結!