
HDFS NameNode主要內部結構

1、HDFS結構
hdfs的採用的是master/slave模型,一個hdfs cluster包含一個NameNode和若干的DataNode,NameNode是master。
NameNode主要負責管理hdfs檔案系統,掌握著整個HDFS的檔案目錄樹及其目錄與檔案,這些資訊會以檔案的形式永久地儲存在本地磁碟。具體地包括namespace管理(其實就是目錄結構),block管理(其中包括
filename->block,block->ddatanode list的對應關係)。NameNode提供的是始終被動接收服務的server,主要有三類協議介面:ClientProtocol介面、DatanodeProtocol介面、NamenodeProtocol介面。
DataNode主要是用來儲存資料檔案,hdfs將一個檔案分割成一個個的block,這些block可能儲存在一個DataNode上或者是多個DataNode上。dn負責實際的底層的檔案的讀寫,如果客戶端client程式發起了讀hdfs上的檔案的命令,那麼首先將這些檔案分成block,然後DataNode將告知client這些block資料是儲存在哪些DataNode上的,之後,client將直接和DataNode互動。
2、FSNamesystem
NameNode的核心是FSNamesysem
FSNamesystem持有幾大主要資料結構:FSDirectory維護系統目錄結構、BlocksMap維護資料塊資訊、LeaseManagr維護租約資訊;此外,還通過DatandeDescriptor、corruptReplicas等維護資料結點(DN)狀態、壞副本等資訊;
FSNamesystem內部維護多個數據結構之間的關係:
- fsname->block列表的對映
- 所有有效blocks集合
- block與其所屬的datanodes之間的對映(該對映是通過block reports動態構建的,維護在namenode的記憶體中。每個datanode在啟動時向namenode報告其自身node上的block)
- 每個datanode與其上的blocklist的對映
- 採用心跳檢測根據LRU演算法更新的機器(datanode)列表
FSNamesystem體系結構

2.1、FSDirectory
FSDirectory用於維護當前系統中的檔案樹,儲存整個檔案系統的目錄狀態儲存整個檔案系統的目錄狀態我們可以在$HADOOP_HOME/tmp/dfs/name/current下找到這些檔案:fsimage以及edits。
fsimage:儲存了最新的元資料檢查點;
edits:儲存了HDFS中自最新的元資料檢查點後的名稱空間變化記錄;
為了防止edits中儲存的最新變更記錄過大,HDFS會定期合併fsimage和edits檔案形成新的fsimage檔案,然後重新記錄edits檔案。由於NameNode存在單點問題(Hadoop2.0以前版本),因此為了減少NameNode的壓力,HDFS把fsimage和edits的合併的工作放到SecondaryNameNode上,然後將合併後的檔案返回給NameNode。但是,這也會造成一個新的問題,當NameNode宕機,那麼NameNode中edits的記錄就會丟失。也就是說,NameNode中的名稱空間資訊有可能發生丟失。
2.2、FsImage
在fsimage中,並沒有記錄每一個block對應到哪幾個datanodes的對應表資訊,而只是儲存了所有的關於namespace的相關資訊。FSImage用於持久化檔案樹的變更以及系統啟動時載入持久化資料。 HDFS啟動時通過FSImage來載入磁碟中原有的檔案樹,系統Standby之後,通過FSEditlog來儲存在檔案樹上的修改,FSEditLog定期將儲存的修改資訊刷到FSImage中進行持久化儲存。
Fsimage是一個二進位制檔案,它記錄了HDFS中所有檔案和目錄的元資料資訊。關於fsimage的內部結構我們可以參看下圖:
第一行是檔案系統元資料,第二行是目錄的元資料資訊,第三行是檔案的元資料資訊。namespaceID:當前名稱空間的ID,在NameNode的生命週期內保持不變,DataNode註冊時,返回該ID作為其registrationID,每次和NameNode通訊時都要檢查,不認識的namespaceID拒絕連線;path的length為0,即表示這個目錄為根目錄。
NameNode將這些資訊讀入記憶體之後,構造一個檔案目錄結構樹,將表示檔案或目錄的節點填入到結構中。
在NameNode載入fsimage完成之後,BlocksMap中只有每個block到其所屬的datanodes
list的對應關係資訊還沒建立。然後通過dn的blockReport來收集構建。當所有的DataNode彙報給NameNode的blockReport處理完畢後,BlocksMap整個結構也就構建完成了。
GFS 在 Master 上儲存的檔案結構是採用名稱空間的方式,沒有目錄記憶體儲的檔案列表結構,沒有連結或別名機制,每一個名稱空間的對映條目都是採用檔案的絕對路徑儲存,並且採用字首壓縮技術(Prefix
compression)進行壓縮儲存。這樣可以更高效地進行檔案的定位和訪問。
2.3、BlocksMap
namenode中是通過block->datanode list的方式來維護一個block的副本是儲存在哪幾個datanodes上的對應關係的。
2.3.1、版本一
從以上fsimage中載入如namenode記憶體中的資訊中可以很明顯的看出,在fsimage中,並沒有記錄每一個block對應到哪幾個datanodes的對應表資訊,而只是儲存了所有的關於namespace的相關資訊。而真正每個block對應到datanodes列表的資訊在hadoop中並沒有進行持久化儲存,而是在所有datanode啟動時,每個datanode對本地磁碟進行掃描,將本datanode上儲存的block資訊彙報給namenode,namenode在接收到每個datanode的塊資訊彙報後,將接收到的塊資訊,以及其所在的datanode資訊等儲存在記憶體中。HDFS就是通過這種塊資訊彙報的方式來完成 block -> datanodes list的對應表構建。Datanode向namenode彙報塊資訊的過程叫做blockReport,而namenode將block -> datanodes list的對應表資訊儲存在一個叫BlocksMap的資料結構中。 BlocksMap的內部資料結構如下: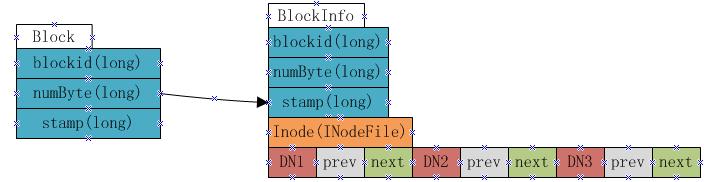
如上圖顯示,BlocksMap實際上就是一個Block物件對BlockInfo物件的一個Map表,其中Block物件中只記錄了blockid,block大小以及時間戳資訊,這些資訊在fsimage中都有記錄。而BlockInfo是從Block物件繼承而來,因此除了Block物件中儲存的資訊外,還包括代表該block所屬的HDFS檔案的INodeFile物件引用以及該block所屬datanodes列表的資訊(即上圖中的DN1,DN2,DN3,該資料結構會在下文詳述)。 BlockInfo中datanode列表資料結構 在BlockInfo中,將該block所屬的datanodes列表儲存在一個Object[]陣列中,但該陣列不僅僅儲存了datanodes列表,還包含了額外的資訊。實際上該陣列儲存瞭如下資訊:

上圖表示一個block包含有三個副本,分別放置在DN1,DN2和DN3三個datanode上,每個datanode對應一個三元組,該三元組中的第二個元素,即上圖中prev block所指的是該block在該datanode上的前一個BlockInfo引用。第三個元素,也就是上圖中next Block所指的是該block在該datanode上的下一個BlockInfo引用。每個block有多少個副本,其對應的BlockInfo物件中就會有多少個這種三元組。 Namenode採用這種結構來儲存block->datanode list的目的在於節約namenode記憶體。由於namenode將block->datanodes的對應關係儲存在了記憶體當中,隨著HDFS中檔案數的增加,block數也會相應的增加,namenode為了儲存block->datanodes的資訊已經耗費了相當多的記憶體,如果還像這種方式一樣的儲存datanode->block list的對應表,勢必耗費更多的記憶體,而且在實際應用中,要查一個datanode上儲存的block list的應用實際上非常的少,大部分情況下是要根據block來查datanode列表,所以namenode中通過上圖的方式來儲存block->datanode list的對應關係,當需要查詢datanode->block list的對應關係時,只需要沿著該資料結構中next Block的指向關係,就能得出結果,而又無需儲存datanode->block list在記憶體中。 因此在namenode啟動並載入fsimage完成之後,實際上BlocksMap中的key,也就是Block物件都已經載入到BlocksMap中,每個key對應的value(BlockInfo)中,除了表示其所屬的datanodes列表的陣列為空外,其他資訊也都已經成功載入。所以可以說:fsimage載入完畢後,BlocksMap中僅缺少每個塊對應到其所屬的datanodes list的對應關係資訊。所缺這些資訊,就是通過上文提到的從各datanode接收blockReport來構建。當所有的datanode彙報給namenode的blockReport處理完畢後,BlocksMap整個結構也就構建完成。
2.3.2、版本二
block->datanode的資訊沒有持久化儲存,而是namenode通過datanode的blockreport獲取block->datanode list
BlocksMap負責維護了三種資訊(維護Block -> { INode, datanodes, self ref } 的對映 ):
block->datanode list
block->INodeFile
datanode->blocks
這要歸功於Object[] triplets結構:

他是一個三元組,每個block有幾個副本,就有幾個三元組。
三元組的第一個元素表示該block所屬的Datanode,型別是DatanodeDescriptor,通過它獲得block->datanode list
第二/三個元素表示該block所在Datanode上的前/後一個block(前驅和後繼),型別是BlockInfo,通過它獲得datanode->blocks
藉助這個三元組可以找到一個block所屬的所有datanode,也可以通過三元組的後兩個元素資訊找到一個datanode上所有的block。
2.3.3、版本三

BlocksMap是NameNode儲存block物件的容器。所有的Block物件被封裝成BlockInfo物件,BlockInfo物件組織成HashMap進行儲存;
BlockInfo物件使用多個(與複本個數相同)三元組(triplets)儲存每個block複本的位置資訊;
三元組中第一個位元指向相應複本所在的DataNode;如圖中虛線所示;第二個位元指向相同DataNode中前一個Block;第三個位元指向相同DataNode中後一個Block;如圖中實現所示,從一個DatanodeDescriptor開始,通過一個雙向連結串列,可以找到該DataNode上所有的Block;
BlocksMap結構比較簡單,實際上就是一個Block到BlockInfo的對映。
Block
Block是HDFS中的基本讀寫單元,主要包括:
- blockId: 一個long型別的塊id
- numBytes: 塊大小
- generationStamp: 塊更新的時間戳
BlockInfo
BlockInfo擴充套件自Block,除基本資訊外還包括一個inode引用,表示該block所屬的檔案;以及一個神奇的三元組陣列Object[] triplets,用來表示儲存該block的datanode資訊,假設系統中的備份數量為3。那麼這個陣列結構如下:

- DN1,DN2,DN3分別表示存有改block的三個datanode的引用(DataNodeDescriptor)
- DN1-prev-blk表示在DN1上block列表中當前block的前置block引用
- DN1-next-blk表示在DN1上block列表中當前block的後置block引用
DN2,DN3的prev-blk和next-blk類似。 HDFS採用這種結構存放block->datanode list的資訊主要是為了節省記憶體空間,block->datanodelist之間的對映關係需要佔用大量記憶體,如果同樣還要將datanode->blockslist的資訊儲存在記憶體中,同樣要佔用大量記憶體。採用三元組這種方式能夠從其中一個block獲得到該block所屬的datanode上的所有block列表。
Conclusion
通過fsimage與blocksmap兩種資料結構,NameNode就能建立起完整的名稱空間資訊以及檔案塊對映資訊。在NameNode載入fsimage之後,BlocksMap中只有每個block到其所屬的DataNode列表的對應關係資訊還沒建立,這個需要通過DataNode的blockReport來收集構建,當所有的DataNode上報給NameNode的blockReport處理完畢後,BlocksMap整個結構也就構建完成。
HDFS檔案系統名稱空間
http://www.aboutyun.com/thread-7388-1-1.html
https://github.com/leotse90/SparkNotes/blob/master/HDFS%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%E5%91%BD%E5%90%8D%E7%A9%BA%E9%97%B4.md#hdfs檔案系統名稱空間
http://blog.csdn.net/liuaigui/article/details/5993604
GFS uses a B-tree to map namespace to metadata; no directory nodes; 100 bytes per file
雜湊表¶
http://origin.redisbook.com/datatype/hash.html
相關推薦
HDFS NameNode主要內部結構
1、HDFS結構 hdfs的採用的是master/slave模型,一個hdfs cluster包含一個NameNode和若干的DataNode,NameNode是master。 NameNode主要負責管理hdfs檔案系統,掌握著整個HDFS的檔案目錄樹及其目錄
LoadRunner內部結構(1)
防止 lis 報告 port sched rac protocol 通過 客戶端 LoadRunner內部結構(1) 根據http://www.wilsonmar.com/1loadrun.htm 翻譯: LoadRunner內部結構 1,
LoadRunner內部結構(2)
res 文件 tar ngs attr 關聯 exec -s telnet LoadRunner內部結構(2) 接著(1)的內容: 17.默認的LRReport文件夾創建在本地分析機器的My Documents文件夾下來存儲分析會話文件. 18.可以使用HTML
Tomcat內部結構及請求原理(轉)
周期 成了 authent 代碼 部分 min 它的 war ace Tomcat Tomcat是一個JSP/Servlet容器。其作為Servlet容器,有三種工作模式:獨立的Servlet容器、進程內的Servlet容器和進程外的Servlet容器。 Tomcat的組織
kafka內部結構筆記
app bit view 般的 分享 end scale out 參數 寫入 集群架構 搭建一套測試集群,共三個節點,每個節點上面都有procuder/broker/consumer角色。沒有WebUI頁面,架構如下: kafka架構 在系統架構中,將消息系統獨立可起到架
SEO之網站內部結構優化
有一個 服務 自定義404 小技巧 直接 加載速度 引擎 com 好的 如何優化網站的內部結構?網站內部結構優化是網站SEO過程中不可缺少的環節,在網站建設的初期就要做好設置工作。網站內部結構的優化主要包括:網站結構、頁面元素、後期優化等,下面就從這幾個方面為大家講解,希望
SQL Server索引內部結構:SQL Server索引的階梯級別10
個數字 索引 avi 查詢 ica 關鍵字 比較 mage emp 作者David Durant,2012年1月20日 該系列 本文是“Stairway系列:SQL Server索引的階梯”的一部分 索引是數據庫設計的基礎,並告訴開發人員使用數據庫關於設計者的意圖。不幸的是
19、《每天5分鐘玩轉Docker容器技術》學習--Overlay Network內部結構詳解
hostman cloudman cloud openstack docker 一、環境描述以容器方式運行 Consul:通過 http://192.168.56.129:8500 訪問 Consul修改 docker02 和 docker03 的 docker daemon 的配置文件,
深入理解Flink ---- Metrics的內部結構
open scheduled 以及 only sta OS volatile 添加 closed 從Metrics的使用說起 Flink的Metrics種類有四種Counters, Gauges, Histograms和Meters. 如何使用Metrics呢? 以Coun
見微知著 —— Redis 字符串內部結構源碼分析
是否 log object 選擇 max 指針 bst 怎麽 上一個 前言 本篇我們開始講字典 key 的內部結構,也就是 sds 字符串。首先它不是普通字符串,而是 sds 字符串,這個 sds 的意思是「Simple Dynamic String」,它的結構很簡單,它是
淺析卷積神經網路的內部結構
提到卷積神經網路(CNN),很多人的印象可能還停留在黑箱子,輸入資料然後輸出結果的狀態。裡面超級多的引數、眼花繚亂的命名可能讓你無法短時間理解CNN的真正內涵。這裡推薦斯坦福大學的CS231n課程,知乎上有筆記的中文翻譯。如果你需要更淺顯、小白的解釋,可以讀讀看本文。文章大部分理解都源自於CS3
class的好處就是內部結構井井有條,程式碼沒有不裸露,都封裝到屬性或方法裡
class的好處就是內部結構井井有條,程式碼沒有不裸露,都封裝到屬性或方法裡 這是一個函式裡帶子函式的例子: def scope_test(): def do_local(): spam = "local spam" def do_nonlocal():
redis - 探索「字串」內部結構
Redis 中的字串是可以修改的字串,在記憶體中它是以位元組陣列的形式存在的。我們知道 C 語言裡面的字串標準形式是以 NULL 作為結束符,但是在 Redis 裡面字串不是這麼表示的。因為要獲取 NULL 結尾的字串的長度使用的是 strlen 標準庫函式,這個函式的演算法複雜度是 O(n),它需
tensor內部結構
內部結構 1.tensor分為頭資訊區(Tensor)和儲存區(Storage); 資訊區:tensor的形狀(size)、步長(stride)、資料型別(type),資訊區佔用記憶體較少 儲存區:資料儲存為連續陣列,主要記憶體佔用在儲存區 2.每一個tensor有著一個對
Hadoop商業環境實戰-HDFS NameNode 宕機元資料一致保障及SNN機制深入研究
版權宣告:本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。版權宣告:禁止轉載,歡迎學習。QQ郵箱地址:[email protected],如有任何商業交流,可隨時
mathematica做恆星內部結構作業
基本程式碼 使用在LINUX環境下的Mathematica,注意路徑 載入資料(依次,設定目錄,載入資料檔案並選擇資料範圍) SetDirectory["/home/yiwen/Desktop/Data"]; data6 = Import["20171218-6.dat
Xilinx A7 芯片內部結構分析(1)-- CLB
協議 感覺 我們 latency 構圖 共享 ron multipl 收獲 一直以來,覺得自己關於FPGA方面,摸不到“低”——對底層架構認識不清,夠不著“高”——沒真正獨立做過NB的應用,如高速、復雜協議或算法、神經網絡加速等高大上的應用,所以能力和認識水平都處於中間水平
hadoop平臺報錯:ATTEMPTING TO OPERATE ON HDFS NAMENODE AS ROOT(start-all.sh)啟動失敗解決方法
如果遇到 需要修改start-dfs.sh stop-dfs.sh start-yarn.sh
HDFS NameNode 高併發資料讀寫架構及QJM選舉深入研究-Hadoop商業環境實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。期待加入IOT時代最具戰鬥力的團隊。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡
JAVA類檔案Class內部結構
文章目錄 JAVA的平臺無關性怎麼實現的? JAVA的類檔案結構? 魔數與版本 常量池 訪問標誌 類索引父類索引與介面索引集合 欄位表集合 方法表集合 屬性表集合