
打造一個健壯高效的網絡爬蟲
以下內容轉自爬蟲界大佬崔慶才的文章,傳送門
整個分享的主題叫做《健壯高效的網絡爬蟲》,本次分享從抓取、解析、存儲、反爬、加速五個方面介紹了利用 Python 進行網絡爬蟲開發的相關知識點和技巧,介紹了不同場景下如何采取不同措施高效地進行數據抓取的方法,包括 Web 抓取、App 抓取、數據存儲、代理選購、驗證碼破解、分布式抓取及管理、智能解析等多方面的內容,另外還結合了不同場景介紹了常用的一些工具包,全部內容是我在從事網絡爬蟲研究過程以來的經驗精華總結。

爬取
對於爬取來說,我們需要學會使用不同的方法來應對不同情景下的數據抓取任務。
爬取的目標絕大多數情況下要麽是網頁,要麽是 App,所以這裏就分為這兩個大類別來進行了介紹。
對於網頁來說,我又將其劃分為了兩種類別,即服務端渲染和客戶端渲染,對於 App 來說,我又針對接口的形式進行了四種類別的劃分——普通接口、加密參數接口、加密內容接口、非常規協議接口。
所以整個大綱是這樣子的:
- 網頁爬取
- 服務端渲染
- 客戶端渲染
- App 爬取
- 普通接口
- 加密參數接口
- 加密內容接口
- 非常規協議接口
爬取 / 網頁爬取
服務端渲染的意思就是頁面的結果是由服務器渲染後返回的,有效信息包含在請求的 HTML 頁面裏面,比如貓眼電影這個站點。客戶端渲染的意思就是頁面的主要內容由 JavaScript 渲染而成,真實的數據是通過 Ajax 接口等形式獲取的,比如淘寶、微博手機版等等站點。

服務端渲染的情況就比較簡單了,用一些基本的 HTTP 請求庫就可以實現爬取,如 urllib、urllib3、pycurl、hyper、requests、grab 等框架,其中應用最多的可能就是 requests 了。
對於客戶端渲染,這裏我又劃分了四個處理方法:
- 尋找 Ajax 接口,此種情形可以直接使用 Chrome/Firefox 的開發者工具直接查看 Ajax 具體的請求方式、參數等內容,然後用 HTTP 請求庫模擬即可,另外還可以通過設置代理抓包來查看接口,如 Fiddler/Charles。
- 模擬瀏覽器執行,此種情形適用於網頁接口和邏輯較為復雜的情況,可以直接以可見即可爬的方式進行爬取,如可以使用 Selenium、Splinter、Spynner、pyppeteer、PhantomJS、Splash、requests-html 等來實現。
- 直接提取 JavaScript 數據,此種情形適用於真實數據沒有經過 Ajax 接口獲取,而是直接包含在 HTML 結果的某個變量中,直接使用正則表達式將其提取即可。
- 模擬執行 JavaScript,某些情況下直接模擬瀏覽器執行效率會偏低,如果我們把 JavaScript 的某些執行和加密邏輯摸清楚了,可以直接執行相關的 JavaScript 來完成邏輯處理和接口請求,比如使用 Selenium、PyExecJS、PyV8、js2py 等庫來完成即可。




爬取 / App 爬取
對於 App 的爬取,這裏分了四個處理情況:
- 對於普通無加密接口,這種直接抓包拿到接口的具體請求形式就好了,可用的抓包工具有 Charles、Fiddler、mitmproxy。
- 對於加密參數的接口,一種方法可以實時處理,例如 Fiddler、mitmdump、Xposed 等,另一種方法是將加密邏輯破解,直接模擬構造即可,可能需要一些反編譯的技巧。
- 對於加密內容的接口,即接口返回結果完全看不懂是什麽東西,可以使用可見即可爬的工具 Appium,也可以使用 Xposed 來 hook 獲取渲染結果,也可以通過反編譯和改寫手機底層來實現破解。
- 對於非常規協議,可以使用 Wireshark 來抓取所有協議的包,或者使用 Tcpdump 來進行 TCP 數據包截獲。



以上便是爬取流程的相關分類和對應的處理方法。
解析
對於解析來說,對於 HTML 類型的頁面來說,常用的解析方法其實無非那麽幾種,正則、XPath、CSS Selector,另外對於某些接口,常見的可能就是 JSON、XML 類型,使用對應的庫進行處理即可。

這些規則和解析方法其實寫起來是很繁瑣的,如果我們要爬上萬個網站,如果每個網站都去寫對應的規則,那麽不就太累了嗎?所以智能解析便是一個需求。

智能解析意思就是說,如果能提供一個頁面,算法可以自動來提取頁面的標題、正文、日期等內容,同時把無用的信息給刨除,例如上圖,這是 Safari 中自帶的閱讀模式自動解析的結果。
對於智能解析,下面分為四個方法進行了劃分:
- readability 算法,這個算法定義了不同區塊的不同標註集合,通過權重計算來得到最可能的區塊位置。
- 疏密度判斷,計算單位個數區塊內的平均文本內容長度,根據疏密程度來大致區分。
- Scrapyly 自學習,是 Scrapy 開發的組件,指定?頁?面和提取結果樣例例,其可?自學習提取規則,提取其他同類?頁?面。
- 深度學習,使?用深度學習來對解析位置進?行行有監督學習,需要?大量量標註數據。
如果能夠容忍一定的錯誤率,可以使用智能解析來大大節省時間。

目前這部分內容我也還在探索中,準確率有待繼續提高。
存儲
存儲,即選用合適的存儲媒介來存儲爬取到的結果,這裏還是分為四種存儲方式來進行介紹。
- 文件,如 JSON、CSV、TXT、圖?、視頻、?頻等,常用的一些庫有 csv、xlwt、json、pandas、pickle、python-docx 等。
- 數據庫,分為關系型數據庫、非關系型數據庫,如 MySQL、MongoDB、HBase 等,常用的庫有 pymysql、pymssql、redis-py、pymongo、py2neo、thrift。
- 搜索引擎,如 Solr、ElasticSearch 等,便於檢索和實現?本匹配,常用的庫有 elasticsearch、pysolr 等。
- 雲存儲,某些媒體文件可以存到如七?牛雲、又拍雲、阿裏雲、騰訊雲、Amazon S3 等,常用的庫有 qiniu、upyun、boto、azure-storage、google-cloud-storage 等。


這部分的關鍵在於和實際業務相結合,看看選用哪種方式更可以應對業務需求。
反爬
反爬這部分是個重點,爬蟲現在已經越來越難了,非常多的網站已經添加了各種反爬措施,在這裏可以分為非瀏覽器檢測、封 IP、驗證碼、封賬號、字體反爬等。

下面主要從封 IP、驗證碼、封賬號三個方面來闡述反爬的處理手段。
反爬 / 封 IP
對於封 IP 的情況,可以分為幾種情況來處理:
- 首先尋找手機站點、App 站點,如果存在此類站點,反爬會相對較弱。
- 使用代理,如抓取免費代理、購買付費代理、使用 Tor 代理、Socks 代理等。
- 在代理的基礎上維護自己的代理池,防止代理浪費,保證實時可用。
- 搭建 ADSL 撥號代理,穩定高效。

反爬 / 驗證碼
驗證碼分為非常多種,如普通圖形驗證碼、算術題驗證碼、滑動驗證碼、點觸驗證碼、手機驗證碼、掃二維碼等。
- 對於普通圖形驗證碼,如果非常規整且沒有變形或幹擾,可以使用 OCR 識別,也可以使用機器學習、深度學習來進行模型訓練,當然打碼平臺是最方便的方式。
- 對於算術題驗證碼,推薦直接使用打碼平臺。
- 對於滑動驗證碼,可以使用破解算法,也可以模擬滑動。後者的關鍵在於缺口的找尋,可以使用圖片比對,也可以寫基本的圖形識別算法,也可以對接打碼平臺,也可以使用深度學習訓練識別接口。
- 對於點觸驗證碼,推薦使用打碼平臺。
- 對於手機驗證碼,可以使用驗證碼分發平臺,也可以購買專門的收碼設備,也可以人工驗證。
- 對於掃二維碼,可以人工掃碼,也可以對接打碼平臺。



反爬 / 封賬號
某些網站需要登錄才能爬取,但是一個賬號登錄之後請求過於頻繁會被封號,為了避免封號,可以采取如下措施:
- 尋找手機站點或 App 站點,此種類別通常是接口形式,校驗較弱。
- 尋找無登錄接口,盡可能尋找?無需登錄即可爬取的接口。
- 維護 Cookies 池,使?用批量賬號模擬登錄,使?時隨機挑選可用 Cookies 使?即可,實現:https://github.com/Python3WebSpider/CookiesPool。

加速
當爬取的數據量非常大時,如何高效快速地進行數據抓取是關鍵。
常見的措施有多線程、多進程、異步、分布式、細節優化等。

加速 / 多線程、多進程
爬蟲是網絡請求密集型任務,所以使用多進程和多線程可以大大提高抓取效率,如使用 threading、multiprocessing 等。
加速 / 異步
將爬取過程改成非阻塞形式,當有響應式再進行處理,否則在等待時間內可以運行其他任務,如使用 asyncio、aiohttp、Tornado、Twisted、gevent、grequests、pyppeteer、pyspider、Scrapy 等。

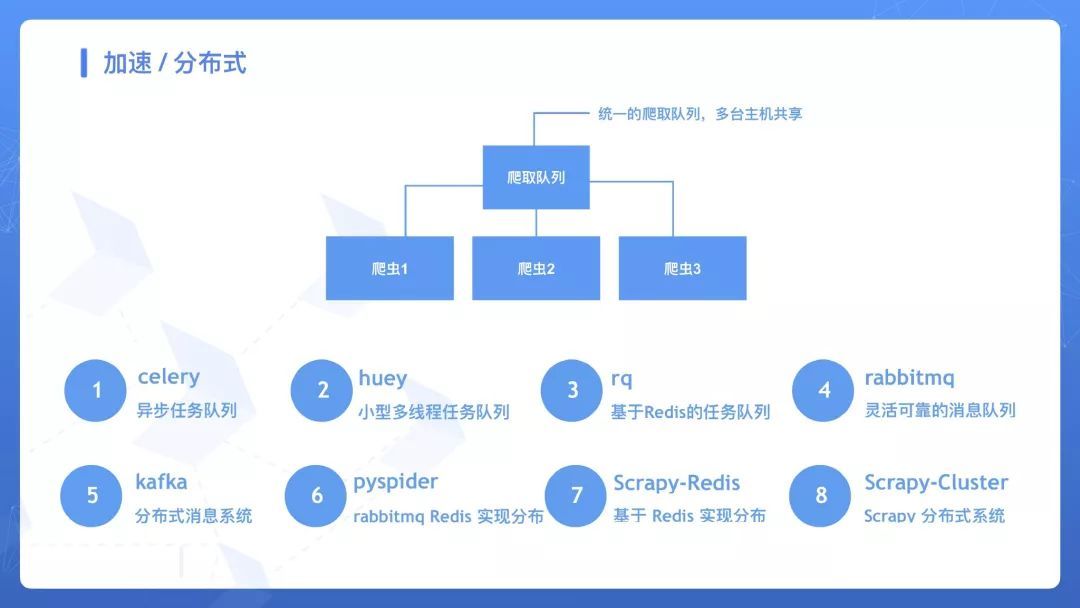
加速 / 分布式
分布式的關鍵在於共享爬取隊列,可以使用 celery、huey、rq、rabbitmq、kafka 等來實現任務隊列的對接,也可以使用現成的框架 pyspider、Scrapy-Redis、Scrapy-Cluster 等。
加速 / 優化
可以采取某些優化措施來實現爬取的加速,如:
- DNS 緩存
- 使用更快的解析方法
- 使用更高效的去重方法
- 模塊分離化管控

加速 / 架構
如果搭建了分布式,要實現高效的爬取和管理調度、監控等操作,我們可以使用兩種架構來維護我們的爬蟲項目。
- 將 Scrapy 項目打包為 Docker 鏡像,使用 K8S 控制調度過程。
- 將 Scrapy 項目部署到 Scrapyd,使用專用的管理工具如 SpiderKeeper、Gerapy 等管理。

以上便是我分享的全部內容,所有的內容幾乎都展開說了,一共講了一個半小時。
上面的文字版的總結可能比較簡略,非常建議大家如有時間的話觀看原版視頻分享,裏面還能看到我本人的真面目哦,現在已經上傳到了 Bilibili,鏈接為:https://www.bilibili.com/video/av34379204,大家也可以通過點擊原文或掃碼來查看視頻。
另外對於這部分內容,其實還有我制作的更豐富的思維導圖,預覽圖如下:

打造一個健壯高效的網絡爬蟲