
BP網路函式逼近 C++實現
阿新 • • 發佈:2019-01-13
BP網路函式逼近

題目選擇2)
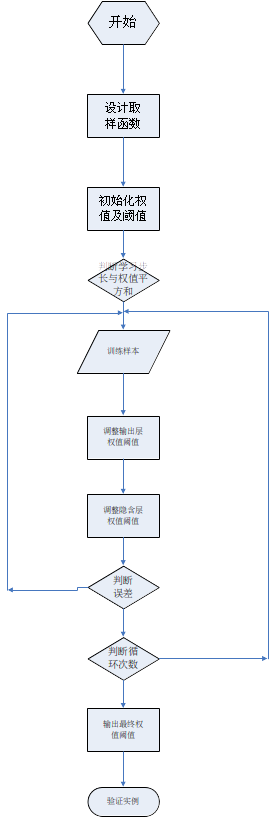
流程圖如下
原始碼
////////////////////////////////////////////////// //題目函式逼近(2)z=sin(x)sin(y) ////////////////////////////////////////////////// ///////////////////標頭檔案//////////////////////// #include<iostream.h> #include <math.h> #include<fstream.h> #include <time.h> #include <stdlib.h> #include <cstring> //本BP網路採用三層神經網路,並且隱含層的結點數為3.樣本數量為225 /////////////////定義全域性變數////////////////// double step=0.5,f,ne;//定義學習步長、平均誤差 int pass=0,i,j,k; double sigmoid(double x);//作用函式為S型函式 double DER_sigmoid (double z);//作用函式的導數 double x[225][2]={0.0};//樣本輸入 double X[225][3]={0}; double O2[225][3]={0.0};//第二層的輸出 double X2[225][4]={0};//第三層的輸入 double Y[225]={0};//理想輸出 double y[225]={0.0};//實際輸出 double E,max;//每次訓練的200個樣本誤差累加,每次訓練的最大誤差 double W2[3][3]={0.0};//第2層網路的權值 double W3[4]={0.0};//第3層網路的權值 double derW2,derW1;//權值調整量 //double EN1[200][4]={0},EN2[225][3]={0}; //誤差對W的偏導數,分別是第3層、第2層; /////////////////////定義作用函式////////////////////////////// double sigmoid(double x)//第2,3層作用函式 { f=exp(x)/(exp(x)+1); return f; } void main() { ///////////////////////權值初始值/////////////////////// srand((unsigned)time(NULL));//以時間為種子 ofstream out("函式逼近(2)題.txt");//輸出檔案 out<<"輸出隱含層連線權值初始值:"<<"\n"; for (i=0;i<3;i++) { for (j=0;j<3;j++) { W2[i][j]=(rand()%60); W2[i][j]=W2[i][j]/100-0.3;//第2層權值初始值的設定在[-0.3,0.3]內取 out<<"W["<<i<<"]["<<j<<"]="<<W2[i][j]<<" "; } out<<"\n"; } out<<"輸出層權值初始值:"<<"\n"; for (i=0;i<4;i++) { W3[i]=(rand()%60);//第3層權值初始值的設定在[-0.3,0.3]內取 W3[i]=W3[i]/100-0.3; out<<"W["<<i<<"]="<<W3[i]<<"\n"; } out<<"\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\"<<"\n"; ////////////////////////////取225個樣本///////// int n=0; double D1=(3*3.1415926)/15; double D2=(3*3.1415926)/16; double x1[15]={0},y1[15]={0}; for (i=0;i<15;i++) { x1[i]=D1*n;//在[0,3pai]之間均勻取15個x y1[i]=D2*(n+1);//在[0,3pai]之間均勻取15個y n++; } i=0; for (j=0;j<15;j++) { k=0; while (k<15) { x[i][0]=x1[j]; x[i][1]=y1[k]; Y[i]=sin(x1[j])*sin(y1[k]); k++; i++; } } ///////////////////訓練BP網路///////////////////////// //////////////輸入的X[225][3]///////// for (i=0;i<225;i++) { for (j=0;j<3;j++) { switch(j) { case 0: X[i][0]=-1; case 1:X[i][1]=x[i][0]; case 2:X[i][2]=x[i][1]; } //out<<"輸入X["<<i<<"]["<<j<<"]="<<X[i][j]<<" \n"; } } double e=0; double p1,p2;//第2,3層的活化值 do { /////////////////////////網路學習////////////////////////// e=0; ++pass; for (i=0;i<225;i++) { for (j=0;j<3;j++) { p1=0;//第2層活化值置0 for (k=0;k<3;k++) { p1=p1+X[i][k]*W2[k][j]; } O2[i][j]=sigmoid(p1); //out<<"O2["<<i<<"]["<<j<<"]="<<O2[i][j]<<"\n"; } } ///////////////第3層的輸入///////// for (i=0;i<225;i++) { for (k=0;k<4;k++) { switch(k) { case 0: X2[i][0]=-1; case 1: X2[i][1]=O2[i][0]; case 2: X2[i][2]=O2[i][1]; case 3: X2[i][3]=O2[i][2]; } //out<<"輸入X2["<<i<<"]["<<k<<"]="<<X2[i][k]<<" \n"; } p2=0;//第3層活化值置0 for (j=0;j<4;j++) { p2=p2+X2[i][j]*W3[j]; } y[i]=sigmoid(p2);//實際輸出 e=e+0.5*(Y[i]-y[i])*(Y[i]-y[i]); ne=e/(i+1); //////////////////////////權值修改///////////////////////////////// for (j=0;j<4;j++)//第3層權值修改 { double x1=0; x1=x1-(Y[i]-y[i])*y[i]*(1-y[i])*X2[i][j]; W3[j]=W3[j]-step*x1; } for (k=0;k<3;k++) { for (j=0;j<3;j++)//第2層權值修改 { double x2=0; x2=x2-O2[i][k]*(1-O2[i][k])*(Y[i]-y[i])*y[i]*(1-y[i])*X[i][j]; W2[j][k]=W2[j][k]-step*x2; } } } } while(ne>0.02&&pass<6000); out<<"訓練樣本次數:"<<pass<<" 小於最大訓練6000次數,結果可靠!\n"; out<<"最大誤差:"<<ne<<"\n"; out<<"最後一個週期200個樣本的誤差累計和為:"<<e<<"\n"; out<<"輸出隱含層連線權值:"<<"\n"; for (i=0;i<3;i++) { for (j=0;j<4;j++) { out<<"W["<<i<<"]["<<j<<"]="<<W2[i][j]<<" "; } out<<"\n"; } out<<"輸出層權值:"<<"\n"; for (j=0;j<4;j++) { out<<"W["<<j<<"]="<<W3[j]<<"\n"; } /////////////////驗證第3個樣本///////// { i=3; for (j=0;j<3;j++) { p1=0.0;//第2層活化值置零 for (k=0;k<3;k++) { p1=p1+X[i][k]*W2[k][j]; } O2[i][j]=sigmoid(p1); out<< O2[i][j]<<" \n"; } for (k=0;k<4;k++) { switch(k) { case 0: X2[i][0]=-1; case 1: X2[i][1]=O2[i][0]; case 2: X2[i][2]=O2[i][1]; case 3: X2[i][3]=O2[i][2]; } out<<"輸入X2["<<i<<"]["<<k<<"]="<<X2[i][k]<<" \n"; } p2=0.0;//第3層活化值置零 for (j=0;j<4;j++) { p2=p2+X2[i][j]*W3[j]; } y[i]=sigmoid(p2);//實際輸出 e=fabs(Y[i]-y[i]); out<<"第三個樣本的誤差e:"<<e<<"\n"; } }
結果截圖
