
So you want to write a package manager
Versions provide me a nice, ordered package environment. Branches hitch me to someone else’s ride, where that “someone” may or may not be hopped up on cough syrup and blow. Revisions are useful when the authors of the project you need to pull in have provided so little guidance that you basically just have to spin the wheel and pick a revision. Once you find one that works, you write that revision to the manifest as a signal to your team that you never
Now, any of these could go right or wrong. Maybe those pleasant-seeming packages are brimming with crypto backdoored by NSA. Maybe that dude pulling me on a rope tow is actually a trained car safety instructor. Maybe it’s a, uh, friendly demon running the roulette table?
Regardless, what’s important about these different identifiers is how it defines the update process. Revisions have no
Really, this is all just an expansion and exploration of yet another aspect of the FLOSS worldview:
I know that relying on other peoples’ code means hitching my project to theirs, entailing at least some logistical and cognitive overhead.
We know there’s always going to be some risk, and some overhead, to pulling in other peoples’ code. Having a few well-defined patterns at least make the alignment strategy immediately evident. And we care about that because, once again, manifests are an expression of user intent: simply looking at the manifest’s version specifier clearly reveals how the author wants to relate to third-party code. It can’t make the upstream code any better, but following a pattern reduces cognitive load. If your PDM works well, it will ease the logistical challenges, too.
The Unit of Exchange
I have hitherto been blithely ignoring something big: just what is a project, or a package, or a dependency? Sure, it’s a bunch of source code, and yes, it emanates, somehow, from source control. But is the entire repository the project, or just some subset of it? The real question here is, “what’s the unit of source code exchange?”
For languages without a particularly meaningful source-level relationship to the filesystem, the repository can be a blessing, as it provides a natural boundary for code that the language does not. In such cases, the repository is the unit of exchange, so it’s only natural that the manifest sits at the repository root:
$ ls -a
.
..
.git
MANIFEST
<ur source code heeere>
However, for languages that do have a well-defined relationship to the filesystem, the repository isn’t providing value as a boundary. (Go is the strongest example of this that I know, and I deal with it in the Go section.) In fact, if the language makes it sane to independently import different subsets of the repository’s code, then using the repository as the unit of exchange can actually get in the way.
It can be inconvenient for consumersthat want only some subset of the repository, or different subsets at different revisions. Or, it can create pain for the author, who feels she must break down a repository into atomic units for import. (Maintaining many repositories sucks; we only do it because somehow, the last generation of DVCS convinced us all it was a good idea.) Either way, for such languages, it may be preferable to define a unit of exchange other than the repository. If you go down that path, here’s what you need to keep in mind:
- The manifest (and the lock file) take on a particularly meaningful relationship to their neighboring code. Generally, the manifest then defines a single ‘unit.’
- It is still ABSOLUTELY NECESSARY that your unit of exchange be situated on its own timeline — and you can’t rely on the VCS anymore to provide it. No timeline, no universes; no universes, no PDM; no PDM, no sanity.
- And remember: software is hard enough without adding a time dimension. Timeline information shouldn’t be in the source itself. Nobody wants to write real code inside a tesseract.
Between versions in the manifest file and path dependencies, it would appear that Cargo has figured this one out, too.
Other Thoughts
Mostly these are bite-sized new ideas, but also some review.
- Choose a format primarily for humans, secondarily for machines: TOML or YAML, else (ugh) JSON. Such formats are declarative and stateless, which makes things simpler. Proper comments are a big plus — manifests are the home of experiments, and leaving notes for your collaborators about the what and why of said experiments can be very helpful!
- TIMTOWTDI, at least at the PDM level, is your arch-nemesis. Automate housekeeping completely. If PDM commands that change the manifest go beyond add/remove and upgrade commands, it’s probably accidental, not essential. See if it can be expressed in terms of these commands.
- Decide whether to have a central package registry (almost certainly yes). If so, jam as much info for the registry into the manifest as needed, as long as it in no way impedes or muddles the dependency information needed by the PDM.
- Avoid having information in the manifest that can be unambiguously inferred from static analysis. High on the list of headaches you do not want is unresolvable disagreement between manifest and codebase. Writing the appropriate static analyzer is hard? Tough tiddlywinks. Figure it out so your users won’t have to.
- Decide what versioning scheme to use (Probably semver, or something like it/enhancing it with a total order). It’s probably also wise to allow things outside the base scheme: maybe branch names, maybe immutable commit IDs.
- Decide if your software will combine PDM behavior with other functionality like an LPM (probably yes). Keep any instructions necessary for that purpose cleanly separated from what the PDM needs.
- There are other types of constraints — e.g., required minimum compiler or interpreter version — that may make sense to put in the manifest. That’s fine. Just remember, they’re secondary to the PDM’s main responsibility (though it may end up interleaving with it).
- Decide on your unit of exchange. Make a choice appropriate for your language’s semantics, but absolutely ensure your units all have their own timelines.
The Lockdown
Transforming a manifest into a lock file is the process by which the fuzz and flubber of development are hardened into reliable, reproducible build instructions. Whatever crazypants stuff a developer does with dependencies, the lock file ensures another user can replicate it — zero thinking required. When I reflect on this apropos of the roiling, seething mass that is software, it’s pretty amazing.
This transformation is the main process by which we mitigate harm arising from the inherent risks of development. It’s also how we address one particular issue in the FLOSS worldview:
I know that I/my team bear the final responsibility to ensure the project we create works as intended, regardless of the insanity that inevitably occurs upstream.
Now, some folks don’t see the value in precise reproducibility. “Manifests are good enough!”, “It doesn’t matter until the project gets serious” and “npm became popular long before shrinkwrap (npm’s lock file) was around!” are some arguments I’ve seen. But these arguments strike me as wrongheaded. Rather than asking, “Do I need reproducible builds?” ask “Do I lose anything from reproducible builds?” Literally everyone benefits from them, eventually. (Unless emailing around tarballs and SSH’ing to prod to bang out changes in nano is your idea of fun). The only question is if you need reproducibility a) now, b) soon, or else c) can we be friends? because I think maybe you’re not actually involved in shipping software, yet you’re still reading this, which makes you a weird person, and I like weird people.
The only real potential downside of reproducible builds is the tool becoming costly (slow) or complicated (extra housekeeping commands or arcane parameters), thus impeding the flow of development. These are real concerns, but they’re also arguments against poor implementations, not reproducibility itself. In fact, they’re really UX guidelines that suggest what ‘svelte’ looks like on a PDM: fast, implicit, and as automated as possible.
The algorithm
Well, those guidelines just scream “algorithm!” And indeed, lock file generation must be fully automated. The algorithm itself can become rather complicated, but the basic steps are easily outlined:
- Build a dependency graph (so: directed, acyclic, and variously labeled) by recursively following dependencies, starting from those listed in the project’s manifest
- Select a revision that meets the constraints given in the manifest
- If any shared dependencies are found, reconcile them with <strategy>
- Serialize the final graph (with whatever extra per-package metadata is needed), and write it to disk. Ding ding, you have a lock file!
(Author’s note: The general problem here is boolean satisfiability, which is NP-complete. This breakdown is still roughly helpful, but trivializes the algorithm.)
This provides us a lock file containing a complete list of all dependencies (i.e., all reachable deps in the computed, fully resolved dep graph). “All reachable” means, if our project has three direct dependencies, like this:
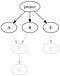
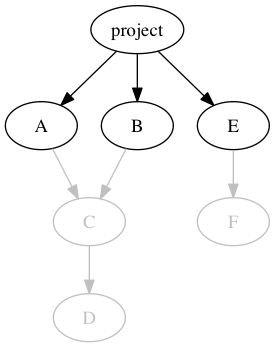
We still directly include all the transitively reachable dependencies in the lock file:
Exactly how much metadata is needed depends on language specifics, but the basics are the package identifier, an address for retrieval, and the closest thing to an immutable revision (i.e. a commit hash) that the source type allows. If you add anything else — e.g., a target location on disk — it should only be to ensure that there is absolutely zero ambiguity in how to dump out the dependency code.
Of the four basic steps in the algorithm, the first and last are more or less straightforward if you have a working familiarity with graphs. Sadly, graph geekery is beyond my ability to bequeath in an article; please feel free to reach out to me if that’s where you’re stuck.
The middle two steps (which are really just “choose a revision” split in two), on the other hand, have hiccups that we can and should confront. The second is mostly easy. If a lock file already exists, keep the locked revisions indicated there unless:
- The user expressly indicated to ignore the lock file
- A floating version, like a branch, is the version specifier
- The user is requesting an upgrade of one or more dependencies
- The manifest changed andno longer admits them
- Resolving a shared dependency will not allow it
This helps avoid unnecessary change: if the manifest would admit 1.0.7, 1.0.8, and 1.0.9, but you’d previously locked to 1.0.8, then subsequent resolutions should notice that and re-use 1.0.8. If this seems obvious, good! It’s a simple example that’s illustrative of the fundamental relationship between manifest and lock file.
This basic idea approach is well-established — Bundler calls it “conservative updating.” But it can be extended further. Some PDMs recommend against, or at least are indifferent to, lock files committed in libraries, but that’s a missed opportunity. For one, it makes things simpler for users by removing conditionality — commit the lock file always, no matter what. But also, when computing the top-level project’s depgraph, it’s easy enough to make the PDM interpret a dependency’s lock file as being revision preferences, rather than requirements. Preferences expressed in dependencies are, of course, given less priority than those expressed in the top-level project’s lock file (if any). As we’ll see next, when shared dependencies exist, such ‘preferences’ can promote even greater stability in the build.
Diamonds, SemVer and Bears, Oh My!
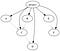
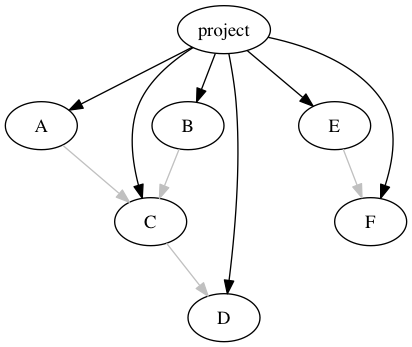
The third issue is harder. We have to select a strategy for picking a version when two projects share a dependency, and the right choice depends heavily on language characteristics. This is also known as the “diamond dependency problem,” and it starts with a subset of our depgraph:
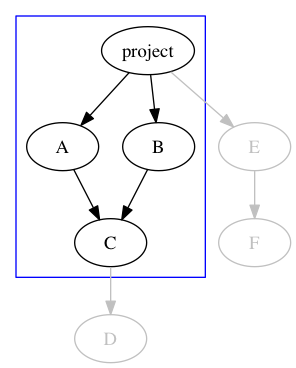
With no versions specified here, there’s no problem. However, if A and B require different versions of C, then we have a conflict, and the diamond splits:
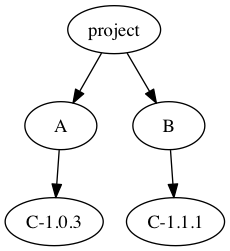
There are two classes of solution here: allow multiple C’s (duplication), or try to resolve the conflict (reconciliation). Some languages, like Go, don’t allow the former. Others do, but with varying levels of risky side effects. Neither approach is intrinsically superior for correctness. However, user intervention is never needed with multiple C’s, making that approach far easier for users. Let’s tackle that first.
If the language allows multiple package instances, the next question is state: if there’s global state that dependencies can and do typically manipulate, multiple package instances can get clobbery in a hurry. Thus, in node.js, where there isn’t a ton of shared state, npm has gotten away with avoiding all possibility of conflicts by just intentionally checking out everything in ‘broken diamond’ tree form. (Though it can achieve the happy diamond via “deduping,” which is the default in npm v3).
Frontend javascript, on the other hand, has the DOM — the grand daddy of global shared state — making that approach much riskier. This makes it a much better idea for bower to reconcile (“flatten”, as they call it) all deps, shared or not. (Of course, frontend javascript also has the intense need to minimize the size of the payload sent to the client.)
If your language permits it, and the type system won’t choke on it, and the global state risks are negligible, and you’re cool with some binary/process footprint bloating and (probably negligible) runtime performance costs, AND bogging down static analysis and transpilation tooling is OK, then duplication is the shared deps solution you’re looking for. That’s a lot of conditions, but it may still be preferable to reconciliation strategies, as most require user intervention — colloquially known as DEPENDENCY HELL — and all involve potentially uncomfortable compromises in the logic itself.
If we assume that the A -> C and B -> C relationships are both specified using versions, rather than branches or revisions, then reconciliation strategies include:
- Highlander: Analyze the A->C relationship and the B->C relationship to determine if A can be safely switched to use C-1.1.1, or B can be safely switched to use C-1.0.3. If not, fall back to realpolitik.
- Realpolitik: Analyze other tagged/released versions of C to see if they can satisfy both A and B’s requirements. If not, fall back to elbow grease.
- Elbow grease: Fork/patch C and create a custom version that meets both A and B’s needs. At least, you THINK it does. It’s probably fine. Right?
Oh, but wait! I left out the one where semver can save the day:
- Phone a friend: ask the authors of A and B if they can both agree on a version of C to use. (If not, fall back to Highlander.)
The last is, by far, the best initial approach. Rather than me spending time grokking A, B and C well enough to resolve the conflict myself, I can rely on signals from A and B’s authors — the people with the least uncertainty about their projects’ relationship to C— to find a compromise:
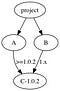
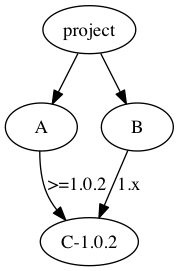
A’s manifest says it can use any patch version of v1.0 newer than 2, and B’s manifest says it can use any minor and patch version of v1. This could potentially resolve to many versions, but if A’s lock file pointed at 1.0.3, then the algorithm can choose that, as it results in the least change.
Now, that resolution may not actually work. Versions are, after all, just a crude signaling system. 1.x is a bit of a broad range, and it’s possible that B’s author was lax in choosing it. Nevertheless, it’s still a good place to start, because:
- Just because the semver ranges suggest solution[s], doesn’t mean I have to accept them.
- A PDM tool can always further refine semver matches with static analysis (if the static analyses feasible for the language has anything useful to offer).
- No matter which of the compromise solutions is used, I still have to do integration testing to ensure everything fits for my project’s specific needs.
- The goal of all the compromise approaches is to pick an acceptable solution from a potentially large search space (as large as all available revisions of C). Reducing the size of that space for zero effort is beneficial, even if occasional false positives are frustrating.
Most important of all, though, is that if I do the work and discover that B actually was too lax and included versions for C that do not work (or excludes versions that do work), I can file patches against B’s manifest to change the range appropriately. Such patches record the work you’ve done, publicly and for posterity, in a way that helps others avoid the same pothole. A decidedly FLOSSy solution, to a distinctly FLOSSy problem.
Dependency Parameterization
When discussing the manifest, I touched briefly on the possibility of allowing parameterization that would necessitate variations in the dependency graphs. If this is something your language would benefit from, it can add some wrinkles to the lock file.
Because the goal of a lock file is to completely and unambiguously describe the dependency graph, parameterizing things can get expensive quickly. The naive approach would construct a full graph in memory for each unique parameter combination; assuming each parameter is a binary on/off, the number of graphs required grows exponentially (2^N) in the number of parameters. Yikes.
However, that approach is less “naive,” than it is “braindead.” A better solution might enumerate all the combinations of parameters, divide them into sets based on which combinations have the same input set of dependencies, and generate one graph per set. And an even better solution might handle all the combinations by finding the smallest input dependency set, then layering all the other combinations on top in a single, multivariate graph. (Then again, I’m an amateur algorithmicist on my best day, so I’ve likely missed a big boat here.)
Maybe this sounds like fun. Or maybe it’s vertigo-inducing jibberish. Either way, skipping it’s an option. Even if your manifest does parameterize dependencies, you can always just get everything, and the compiler will happily ignore what it doesn’t need. And, once your PDM inevitably becomes wildly popular and you are showered with conference keynote speaker invitations, someone will show up and take care of this hard part, Because Open Source.
That’s pretty much it for lock files. Onwards, to the final protocol!
Compiler, phase zero: Lock to Deps

If your PDM is rigorous in generating the lock file, this final step may amount to blissfully simple code generation: read through the lock file, fetch the required resources over the network (intermediated through a cache, of course), then drop them into their nicely encapsulated, nothing-will-mess-with-them place on disk.
There are two basic approaches to encapsulating code: either place it under the source tree, or dump it in some central, out-of-the-way location where both the package identifier and version are represented in the path. If the latter is feasible, it’s a great option, because it hides the actual dependee packages from the user, who really shouldn’t need to look at them anyway. Even if it’s not feasible to use the central location directly as compiler/interpreter inputs — probably the case for most languages — then do it anyway, and use it as a cache. Disk is cheap, and maybe you’ll find a way to use it directly later.
If your PDM falls into the latter, can’t-store-centrally camp, you’ll have to encapsulate the dependency code somewhere else. Pretty much the only “somewhere else” that you can even hope to guarantee won’t be mucked with is under the project’s source tree. (Go’s new vendor directories satisfy this requirement nicely.) That means placing it in the scope of what’s managed by the project’s version control system, which immediately begs the question: should dependency sources be committed?
…probably not. There’s a persnickety technical argument against committing: if your PDM allows for conditional dependencies, then which conditional branch should be committed? “Uh, Sam, obv: just commit all of them and let the compiler use what it wants.” Well then, why’d you bother constructing parameterized dep graphs for the lock file in the first place? And, what if the different conditional branches need different versions of the same package? And…and…
See what I mean? Obnoxious. Someone could probably construct a comprehensive argument for never committing dep sources, but who cares? People will do it anyway. So, being that PDMs are an exercise in harm reduction, the right approach ensures that committing dep sources is a safe choice/mistake to make.
For PDMs that directly control source loading logic — generally, interpreted or JIT-compiled languages — pulling in a dependency with its deps committed isn’t a big deal: you can just write a loader that ignores those deps in favor of the ones your top-level project pulls together. However, if you’ve got a language, such as Go, where filesystem layout is the entire game, deps that commit their deps are a problem: they’ll override whatever reality you’re trying to create at the top-level.
For wisdom on this, let’s briefly turn to distributed systems:
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
- Leslie Lamport
If that sounds like hell — you’re right! Anything that doesn’t have to behave like a distributed system, shouldn’t. You can’t allow person A’s poor use of your PDM to prevent person B’s build from working. So, if language constraints leave you no other choice, the only recourse is to blow away the committed deps-of-deps when putting them into place on disk.
That’s all for this bit. Pretty simple, as promised.
The Dance of the Four States
OK, we’ve been through the details on each of the states and protocols. Now we can step back and assemble the big picture.
There’s a basic set of commands that most PDMs provide to users. Using the common/intuitive names, that list looks something like this:
- init: Create a manifest file, possibly populating it based on static analysis of the existing code.
- add: Add the named package[s] to the manifest.
- rm: Remove the named package[s] from the manifest. (Often omitted, because text editors exist).
- update: Update the pinned version of package[s] in the lock file to the latest available version allowed by the manifest.
- install: Fetch and place all dep sources listed in the lock file, first generating a lock file from the manifest if it does not exist.
Our four-states concept makes it easy to visualize how each of these commands interacts with the system. (For brevity, let’s also abbreviate our states to P[roject code], M[anifest], L[ock file], and D[ependency code]):
相關推薦
So you want to write a package manager
Versions provide me a nice, ordered package environment. Branches hitch me to someone else’s ride, where that “someone” may or may not be hopped up on coug
So you want to get a degree in UX — What’s next?
Step 0 : Do you really need a degree?Before you start looking at all the schools out there, take a moment to step back and examine your goals, motivations,
So You Want to be a Functional Programmer (Part 1)
So You Want to be a Functional Programmer (Part 1)Taking that first step to understanding Functional Programming concepts is the most important and sometim
So you want to use GoGo Protobuf
Introduction In the Go protobuf ecosystem there are two major implementations to choose from. There’s the official golang/protobuf, which uses
*UVA10900_So you want to be a 2n-aire? _概率dp_連續概率
題意 初始有1元,依次回答 n 道題,看到第 i 題時已知答對的概率,可選擇 1.答題:答錯收入0,答對乘2 2.不答:拿錢離開 每道題的概率為 t 到1的均勻分佈。 每次答題前知道概率做出最優決策,求得到的錢的期望。 思路 求期望為倒推的dp 設 e[i]
C++ debugger package is missing or incompatible - do you want to fix it
打開了一個別人的專案,無端端出現這個問題。Google了一大圈按照別人的方式也沒解決,下面是我的解決方式 點選 attach debugger to android process 及下圖debug圖示的時候出現這個問題 出現如下圖所示錯誤,C++ de
I want to be a Great Web Front-end Developer
功能 baseline ner 工作 run 代碼規範 family end 異步 有時覺得特別的浮躁,可能是每天春運般的擠地鐵,隨處可見因為一點小磕小蹭吹胡子瞪眼睛的人,可能是身邊的人貌似一下子都好有錢,買房買車或者買第N套房。 很想靜下來心尋找到自己inner pa
How to write a robust system level service - some key learning - 如何寫好一個健壯的系統級服務
set gic compute som com 服務 ant odin connect Scenario: Rewriting a quartz job service. Background: The existing service logic was hardcodi
mysql更新字段值提示You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode
error without 使用 using ble mod code span set 1 引言 當更新字段缺少where語句時,mysql會提示一下錯誤代碼: Error Code: 1175. You are using safe update mode and yo
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
join with python ast 環境 測試 href from local 環境是win10 python3.5 安裝beautifulsoup後,運行測試報錯 from bs4 import BeautifulSoup soup = Beautiful
[error:沒有解析庫]Couldn't find a tree builder with the features you requested: xml. Do you need to install a parser library?
error ted requested install lib you features builder all 將代碼拷貝到服務器上運行,發生錯誤提示需要新安裝parser library. 查看代碼中發現有以下內容: soup = BeautifulSoup(open(
Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
res requested tro fin IT html str 成功 color python3.6.3 我在處理爬蟲時候使用BeautifulSoup中遇到報錯 “ bs4.FeatureNotFound: Couldn‘t find a tree builde
Who do you want to be bad? (誰會是壞人?)人工智能機器小愛的問話
自己的 智能 英語語法 BE rdquo 需要 not 出了 實現 人工智能的語言理解一直是一個千古謎團。 正如人工智能機器小愛(A.L.I.C.E)的問話:“Who do you want to be bad ?(誰會是壞人?)” 縱觀世
Umbraco項目發布錯誤 --More than one type want to be a model for content type authorize
bin 後臺 dir 出現 event bsp div eve 項目發布 在開發項目時,解決方案下面包括三個項目 MyUmbracoProject MyUmbracoProject.Core MyUmbracoProject.FrontEnd 第一個項目MyU
If you want to allow applications containing errors to be published on the server
serve enable errors websphere ebsp ror HERE The win If you want to allow applications containing errors to be published on the server, en
彈出AlertDialog的時候報You need to use a Theme.AppCompat theme (or descendant) with this activity錯誤
今天遇到一個bug,用百度地圖的時候,我對上面的標註設定了點選監聽,設定的相應的反應是彈出一個AlertDialog 記錄一解決bug的歷程 但是Dialog卻沒有彈出來,一看AS下面,報了這錯,起初我看我gradle.app裡面 implementation 'com.android.suppo
cdde::block Debug ERROR: You need to specify a debugger program in the debuggers's settings.
有的小夥伴有可能在使用code::blocks程式設計的時候,在除錯是出現下面的問題 這種情況是因為沒有指定除錯程式,或者是指定的是錯誤的,或者就沒有下載除錯程式,沒有下載的,下載一個mingw下載gdb程式就行。 在確定安裝了gdb後,在code::blocks的偵錯程式選項,選擇
更新資料庫中資料時出現: Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe m
在資料庫中更新資料時報錯: You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle
OpenPano: How to write a Panorama Stitcher
OpenPano: How to write a Panorama Stitcher This is a summary of the algorithms I used to write OpenPano: an open source panorama stitcher. You
Android studio 執行時報錯Do you want to uninstall the existing application?的解決方法
轉載自:https://www.cnblogs.com/1124hui/p/6609689.html (解決方法)Android studio 執行時報錯Do you want to uninstall the existing application?的解決方法 在And