
Spark系列(三)Spark的工作機制
什麼時候才能迴歸到看論文,寫感想的日子呀~剛剛交完房租的我血槽已空。看了師妹關於Spark報告的PPT,好懷念學生時代開組會的時光啊,雖然我已經離開學校不長不短兩個月,但我還是非常認真的翻閱了,並作為大自然的搬運工來搬運知識了。
Spark的執行模式
1、Local,本地執行,通過多執行緒來實現平行計算。
2、本地偽叢集執行模式,用單機模擬叢集,有多個程序。
3、Standalone,spark做資源排程,任務的排程和計算。部署繁瑣。
4、Yarn, Mesos,通用的統一資源管理機制,可以在上面執行多種計算框架。
著重介紹比較廣泛應用叢集管理器Yarn
YARN 是在 Hadoop 2.0中引入的叢集管理器,它可以讓多種資料處理框架執行在一個共享的資源池上,並且通常安裝在與 Hadoop 檔案系統(簡稱 HDFS)相同的物理節點上。
第一步是找到你的 Hadoop 的配置目錄,並把它設為環境變數HADOOP_CONF_DIR。這個目錄包含 yarn-site.xml 和其他配置檔案;如果你把 Hadoop 裝到 HADOOP_HOME 中,那麼這個目錄通常位於HADOOP_HOME/conf 中,否則可能位於系統目錄 /etc/hadoop/conf中。然後用如下方式提交你的應用:
export HADOOP_CONF_DIR="..."
spark-submit --master yarn yourapp
有兩種將應用連線到叢集的模式:客戶端模式以及叢集模式。在客戶端模式下應用的驅動器程式執行在提交應用的機器上(比如你的膝上型電腦),而在叢集模式下,驅動器程式也執行在一個 YARN 容器內部。這就涉及了應用的兩種提交方式。
應用的提交方式
Driver執行在客戶端,即為客戶端模式
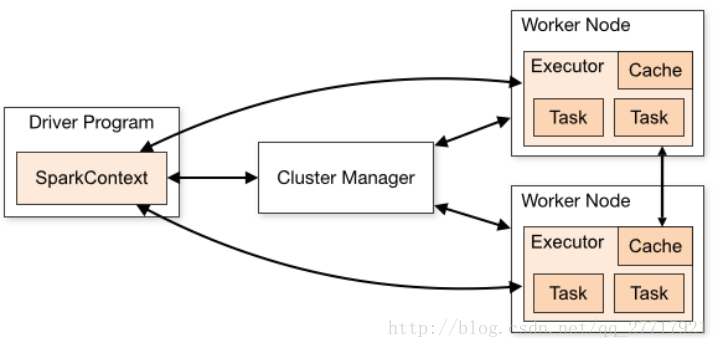
Driver執行在叢集上,是叢集中的某一個Worker,即叢集模式
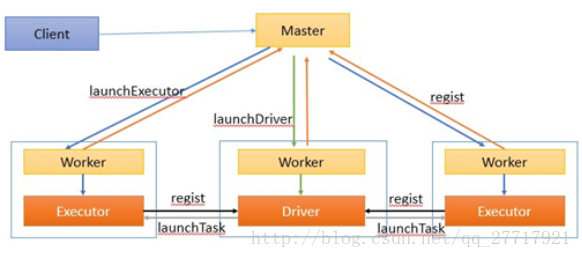
執行流程
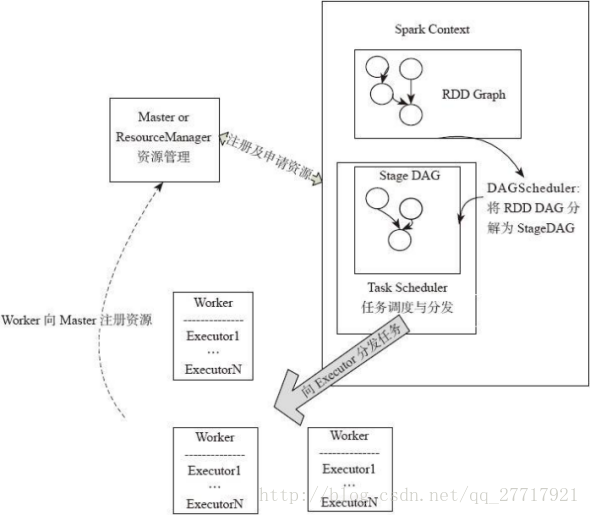
基於上圖我們將詳細介紹資源的排程和任務的分配,主要從Application的排程-Job排程-Stage排程來說明
Application的排程
多使用者需要共享叢集資源時,可以依據叢集管理者的配置,分配資源
YARN:配置每個應用分配的executor數量,每個executor佔用的的記憶體大小和CPU核數
Job的排程
Job的排程符合FIFO, 排程池裡面是很多工集,任務集有兩個ID ,JOBID 和stageID,ID小的先執行。 JOB: FIFOstage: DAGScheduler
Stage的排程
Stage的DAG以最後執行的 Stage為根進行廣度優先遍歷,遍歷到最開始執行的Stage執行。DAGScheduler中還維持了幾個重要的Key-Value集 :
waitingStages中記錄仍有未執行的父Stage,防止過早執行;
runningStages中儲存正在執行的Stage,防止重複執行;
failedStages中儲存執行失敗的Stage,需要重新執行。DONE
相關推薦
Spark系列(三)Spark的工作機制
什麼時候才能迴歸到看論文,寫感想的日子呀~剛剛交完房租的我血槽已空。看了師妹關於Spark報告的PPT,好懷念學生時代開組會的時光啊,雖然我已經離開學校不長不短兩個月,但我還是非常認真的翻閱了,並作為大自然的搬運工來搬運知識了。Spark的執行模式1、Local,本地執行,通
spark 教程三 spark Map filter flatMap union distinct intersection操作
文件的 ask wordcount 本地文件 png var foreach sets list RDD的創建 spark 所有的操作都圍繞著彈性分布式數據集(RDD)進行,這是一個有容錯機制的並可以被並行操作的元素集合,具有只讀、分區、容錯、高效、無需物化、可以緩存、RD
Spark系列4- Spark Streaming
1 流計算 靜態資料和流資料 靜態資料類似儲存在水庫中的水,是相對靜止不動的,如資料倉庫中儲存的資料、關係型資料庫中儲存的資料等。流資料是指在時間分佈和數量上無限的一系列動態資料合體,資料記錄是流資料的最小組成單元。 靜態資料和流資料的處理,分別對應兩種不同的計
Spark系列(1)—Spark單機安裝與測試
Spark作為最有可能代替mapreduce的分散式計算框架,當前非常火,本人也開始關注Spark並試著從hadoop+mahout轉向Spark。 1.本地環境 本地為ubuntu14.04+jdk1.7 2.原始碼下載 我所使用的版本是:0.9.1版本,原始碼包為:s
【Spark系列】三、Spark工作機制
Spark工作機制 Client Driver程式 Spark Context RDD DAG DAGSchedular TaskSchedular SparkEnv Worker Node
自學it18大數據筆記-第三階段Spark-day14;Spark-day15(開始試水找工作了)——會持續更新……
str logs 感謝 和源 不能 同名 cal day5 img 寫在最前:轉行大數據領域,沒報班,自學試試,能堅持下來以後就好好做這行,不能就……!準備從現有這套it18掌的視屏殘本開始……自學是痛苦的,發博客和大家分享下學習成果——也是監督自己,督促自己堅持學下去。
spark源碼系列之累加器實現機制及自定義累加器
大數據 spark一,基本概念 累加器是Spark的一種變量,顧名思義該變量只能增加。有以下特點: 1,累加器只能在Driver端構建及並只能是Driver讀取結果,Task只能累加。 2,累加器不會改變Spark Lazy計算的特點。只會在Job觸發的時候進行相關累加操作。 3,現有累加器的類型。相信有很
Spark Streaming的工作機制
系統 lan park 儀表 red 進行 工作 數據 現場 1. Spark Streaming的工作機制 Spark Streaming 是Spark核心API的一個擴展,可以實現高吞吐量的、具備容錯機制的實時流數據的處理。 支持從多種數據源獲取數
Spark架構與工作機制
Spark架構與工作機制 Spark的架構 — 架構元件概念簡介 Spark叢集中Master負責叢集整體資源管理和排程,Worker負責單個節點的資源管理。Driver程式是應用邏輯執行的起點,而多個Executor用來對資料進行並行處理。 Spark的構成:
spark入門系列教程三——spark sql(一)
Spark SQL是用於結構化資料處理的Spark模組,可以通過sql、dataset、dataframe與spark sql進行互動。更多理論性知識請移步官網http://spark.apache.org/docs/2.3.1/sql-programming-guide.html 在spark 2.0以前
Spark(四) -- Spark工作機制
一、應用執行機制 一個應用的生命週期即,使用者提交自定義的作業之後,Spark框架進行處理的一系列過程。 在這個過程中,不同的時間段裡,應用會被拆分為不同的形態來執行。 1、應用執行過程中的基本元件和形態 Driver: 執行在客戶端或者叢集中,執行A
Spark工作機制
spark作業:Application : 使用者自定義的spark程式。使用者提交後,spark為app分配資源將程式轉換並執行。Driver Program : 執行Application的main()函式並建立SparkContext。RDD DAG : 當RDD遇到A
【Spark工作機制詳解】 執行機制
Spark主要包括 排程與任務分配、I/O模組、通訊控制模組、容錯模組 、 Shuffle模組。 Spark 按照 ①應用 application ②作業 job ③ stage ④ task 四個層次進行排程,採用經典的FIFO和FAIR等排程演
Spark 系列(三)—— 彈性式資料集RDDs
一、RDD簡介 RDD 全稱為 Resilient Distributed Datasets,是 Spark 最基本的資料抽象,它是隻讀的、分割槽記錄的集合,支援並行操作,可以由外部資料集或其他 RDD 轉換而來,它具有以下特性: 一個 RDD 由一個或者多個分割槽(Partitions)組成。對於 RDD
大資料學習筆記——Spark工作機制以及API詳解
Spark工作機制以及API詳解 本篇文章將會承接上篇關於如何部署Spark分散式叢集的部落格,會先對RDD程式設計中常見的API進行一個整理,接著再結合原始碼以及註釋詳細地解讀spark的作業提交流程,排程機制以及shuffle的過程,廢話不多說,我們直接開始吧! 1. Spark基本API解讀 首先我們寫
Spark入門實戰系列--2.Spark編譯與部署(中)--Hadoop編譯安裝
二進制包 1.10 不能 mapr 修復 att 機器 mave end 【註】該系列文章以及使用到安裝包/測試數據 能夠在《[傾情大奉送–Spark入門實戰系列] (http://blog.csdn.net/yirenboy/article/deta
大數據入門第二十二天——spark(三)自定義分區、排序與查找
get buffer arr clas ron arm scala mut all 一、自定義分區 1.概述 默認的是Hash的分區策略,這點和Hadoop是類似的,具體的分區介紹,參見:https://blog.csdn.net/high2011/arti
spark筆記之RDD容錯機制之checkpoint
原理 chain for 機制 方式 方法 相對 例如 contex 10.checkpoint是什麽(1)、Spark 在生產環境下經常會面臨transformation的RDD非常多(例如一個Job中包含1萬個RDD)或者具體transformation的RDD本身計算
小白學習Spark系列四:rdd踩坑總結
build .text 大數據分析 遇到 ESS bstr 分隔符 讀取配置 關註 初次嘗試用 Spark+scala 完成項目的重構,由於兩者之前都沒接觸過,所以邊學邊用的過程大多艱難。首先面臨的是如何快速上手,然後是代碼調優、性能調優。本章主要記錄自己在項目中遇到的
大資料之Spark(三)--- Spark核心API,Spark術語,Spark三級排程流程原始碼分析
一、Spark核心API ----------------------------------------------- [SparkContext] 連線到spark叢集,入口點. [HadoopRDD] extends RDD 讀取hadoop