
Spark2.1.0——Spark初體驗
學習一個工具的最好途徑,就是使用它。這就好比《極品飛車》玩得好的同學,未必真的會開車,要學習車的駕駛技能,就必須用手觸控方向盤、用腳感受剎車與油門的力道。在IT領域,在深入瞭解一個系統的原理、實現細節之前,應當先準備好它的執行環境或者原始碼閱讀環境。如果能在實際環境下安裝和執行Spark,顯然能夠提升讀者對於Spark的一些感受,對系統能有個大體的印象,有經驗的工程師甚至能夠猜出一些Spark在實現過程中採用的設計模式、程式設計模型。
考慮到大部分公司在開發和生產環境都採用Linux作業系統,所以筆者選用了64位的Linux。在正式安裝Spark之前,先要找臺好機器。為什麼?因為筆者在安裝、編譯、除錯的過程中發現Spark非常耗費記憶體,如果機器配置太低,恐怕會跑不起來。Spark的開發語言是Scala,而Scala需要執行在JVM之上,因而搭建Spark的執行環境應該包括JDK和Scala。
本文只介紹最基本的與Spark相關的準備工作,至於Spark在實際生產環境下的配置,則需要結合具體的應用場景進行準備。
安裝JDK
自Spark2.0.0版本開始,Spark已經準備放棄對Java 7的支援,所以我們需要選擇Java 8。我們還需要使用命令getconf LONG_BIT檢視linux機器是32位還是64位,然後下載相應版本的JDK並安裝。
下載地址:
配置環境:
cd ~ vim .bash_profile
新增如下配置:
exportJAVA_HOME=/opt/java exportPATH=$PATH:$JAVA_HOME/bin exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
輸入以下命令使環境變數快速生效:
source .bash_profile
安裝完畢後,使用java –version命令檢視,確認安裝正常,如圖1所示。

圖1 檢視java安裝是否正常
安裝Scala
由於從Spark 2.0.0開始,Spark預設使用Scala 2.11來編譯、打包,不再是以前的Scala 2.10,所以我們需要下載Scala 2.11。
下載地址:
選擇Scala 2.11的版本進行下載,下載方法如下:
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
移動到選好的安裝目錄,例如:
mv scala-2.11.8.tgz~/install/
進入安裝目錄,執行以下命令:
chmod 755scala-2.11.8.tgz tar -xzvfscala-2.11.8.tgz
配置環境:
cd ~ vim .bash_profile
新增如下配置:
export SCALA_HOME=$HOME/install/scala-2.11.8 export PATH=$SCALA_HOME/bin:$PATH
輸入以下命令使環境變數快速生效:
source .bash_profile
安裝完畢後鍵入scala,進入scala命令列以確認安裝正常,如圖2所示。

圖2 進入Scala命令列
安裝Spark
Spark進入2.0時代之後,目前一共有兩個大的版本:一個是2.0.0,一個是2.1.0。本書選擇2.1.0。
下載地址:
下載方法如下:
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.6.tgz
移動到選好的安裝目錄,如:
mv spark-2.1.0-bin-hadoop2.6.tgz~/install/
進入安裝目錄,執行以下命令:
chmod 755 spark-2.1.0-bin-hadoop2.6.tgz tar -xzvf spark-2.1.0-bin-hadoop2.6.tgz
配置環境:
cd ~ vim .bash_profile
新增如下配置:
export SPARK_HOME=$HOME/install/spark-2.1.0-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
輸入以下命令使環境變數快速生效:
source .bash_profile
安裝完畢後鍵入spark-shell,進入scala命令列以確認安裝正常,如圖3所示。
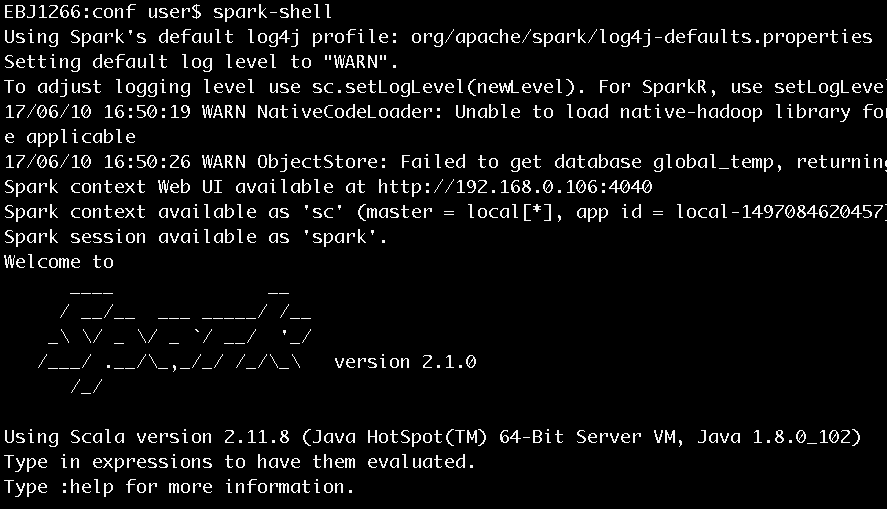
圖3 執行spark-shell進入Scala命令列
既然已經介紹瞭如何準備好基本的Spark執行環境,現在是時候實踐一下,以便於在使用過程中提升讀者對於Spark最直接的感觸!本文通過Spark的基本使用,讓讀者對Spark能有初步的認識,便於引導讀者逐步深入學習。
執行spark-shell
在《Spark2.1.0——執行環境準備》一文曾經簡單運行了spark-shell,並用下圖進行了展示(此處再次展示此圖)。
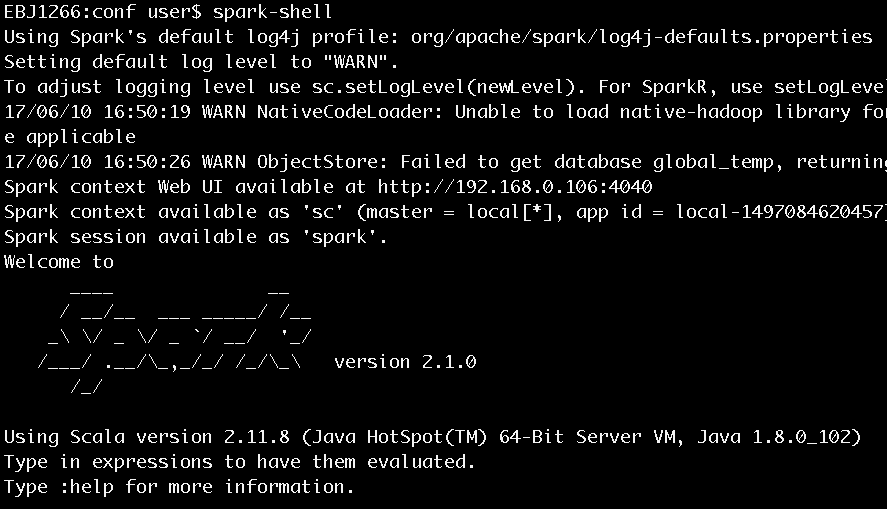
圖4 執行spark-shell進入Scala命令列
圖4中顯示了很多資訊,這裡進行一些說明:
- 在安裝完Spark 2.1.0後,如果沒有明確指定log4j的配置,那麼Spark會使用core模組的org/apache/spark/目錄下的log4j-defaults.properties作為log4j的預設配置。log4j-defaults.properties指定的Spark日誌級別為WARN。使用者可以到Spark安裝目錄的conf資料夾下從log4j.properties.template複製一份log4j.properties檔案,並在其中增加自己想要的配置。
- 除了指定log4j.properties檔案外,還可以在spark-shell命令列中通過sc.setLogLevel(newLevel)語句指定日誌級別。
- SparkContext的Web UI的地址是:http://192.168.0.106:4040。192.168.0.106是筆者安裝Spark的機器的ip地址,4040是SparkContext的Web UI的預設監聽埠。
- 指定的部署模式(即master)為local[*]。當前應用(Application)的ID為local-1497084620457。
- 可以在spark-shell命令列通過sc使用SparkContext,通過spark使用SparkSession。sc和spark實際分別是SparkContext和SparkSession在Spark REPL中的變數名,具體細節已在《Spark2.1.0——剖析spark-shell》一文有過分析。
由於Spark core的預設日誌級別是WARN,所以看到的資訊不是很多。現在我們將Spark安裝目錄的conf資料夾下的log4j.properties.template以如下命令複製出一份:
cp log4j.properties.template log4j.properties
並將log4j.properties中的log4j.logger.org.apache.spark.repl.Main=WARN修改為log4j.logger.org.apache.spark.repl.Main=INFO,然後我們再次執行spark-shell,將打印出更豐富的資訊,如圖5所示。
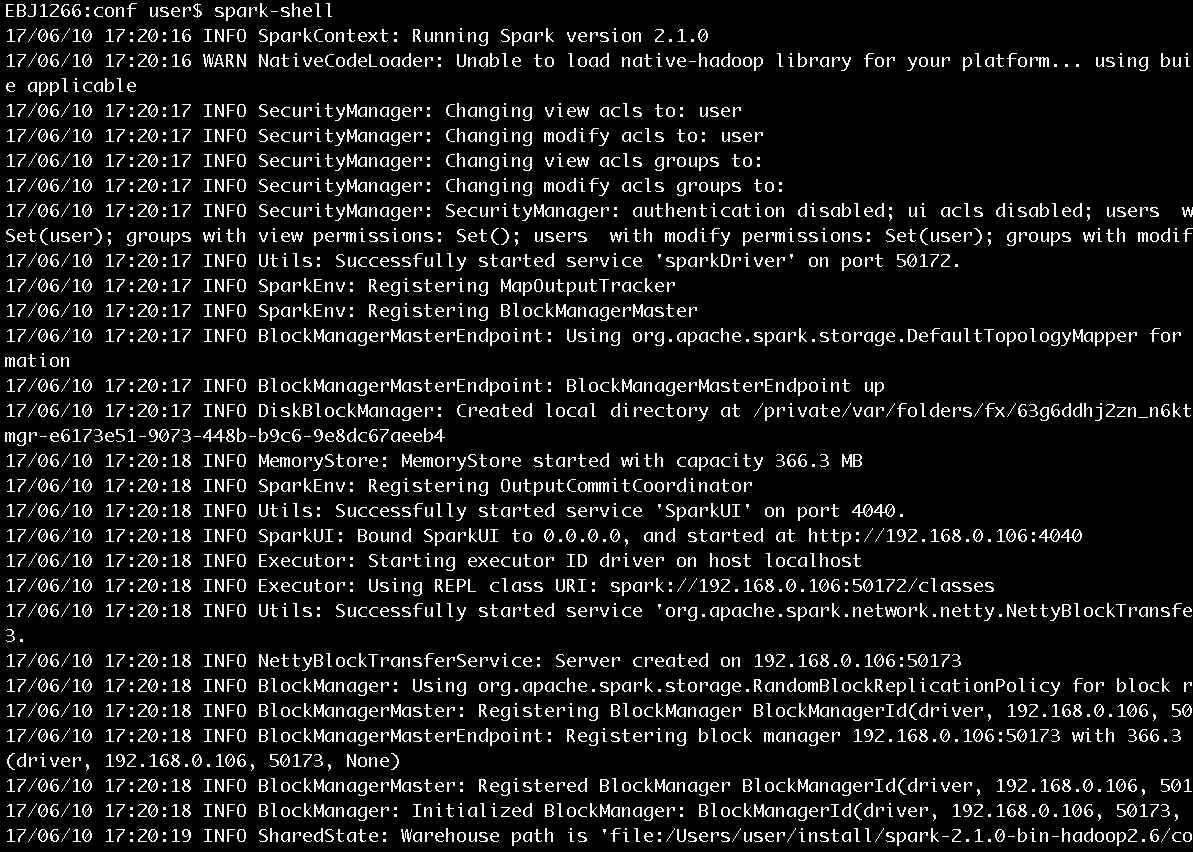
圖5 Spark啟動過程列印的部分資訊
從圖5展示的啟動日誌中我們可以看到SecurityManager、SparkEnv、BlockManagerMasterEndpoint、DiskBlockManager、MemoryStore、SparkUI、Executor、NettyBlockTransferService、BlockManager、BlockManagerMaster等資訊。它們是做什麼的?剛剛接觸Spark的讀者只需要知道這些資訊即可,具體內容將在後邊的博文給出。
執行word count
這一節,我們通過word count這個耳熟能詳的例子來感受下Spark任務的執行過程。啟動spark-shell後,會開啟Scala命令列,然後按照以下步驟輸入指令碼:
步驟1
輸入val lines =sc.textFile("../README.md", 2),以Spark安裝目錄下的README.md檔案的內容作為word count例子的資料來源,執行結果如圖6所示。

圖6 步驟1執行結果
圖6告訴我們lines的實際型別是MapPartitionsRDD。
步驟2
textFile方法對文字檔案是逐行讀取的,我們需要輸入val words =lines.flatMap(line => line.split(" ")),將每行文字按照空格分隔以得到每個單詞,執行結果如圖7所示。
圖7 步驟2執行結果
圖7告訴我們lines在經過flatMap方法的轉換後得到的words的實際型別也是MapPartitionsRDD。
步驟3
對於得到的每個單詞,通過輸入val ones = words.map(w => (w,1)),將每個單詞的計數初始化為1,執行結果如圖8所示。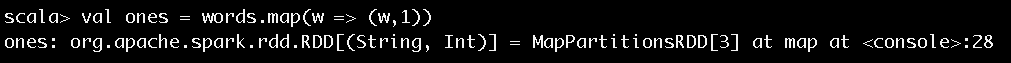
圖8 步驟3執行結果
圖8告訴我們words在經過map方法的轉換後得到的ones的實際型別也是MapPartitionsRDD。
步驟4
輸入val counts = ones.reduceByKey(_ + _),對單詞進行計數值的聚合,執行結果如圖9所示。

圖9 步驟4執行結果
圖9告訴我們ones在經過reduceByKey方法的轉換後得到的counts的實際型別是ShuffledRDD。
步驟5
輸入counts.foreach(println),將每個單詞的計數值打印出來,作業的執行過程如圖10和圖11所示。作業的輸出結果如圖12所示。
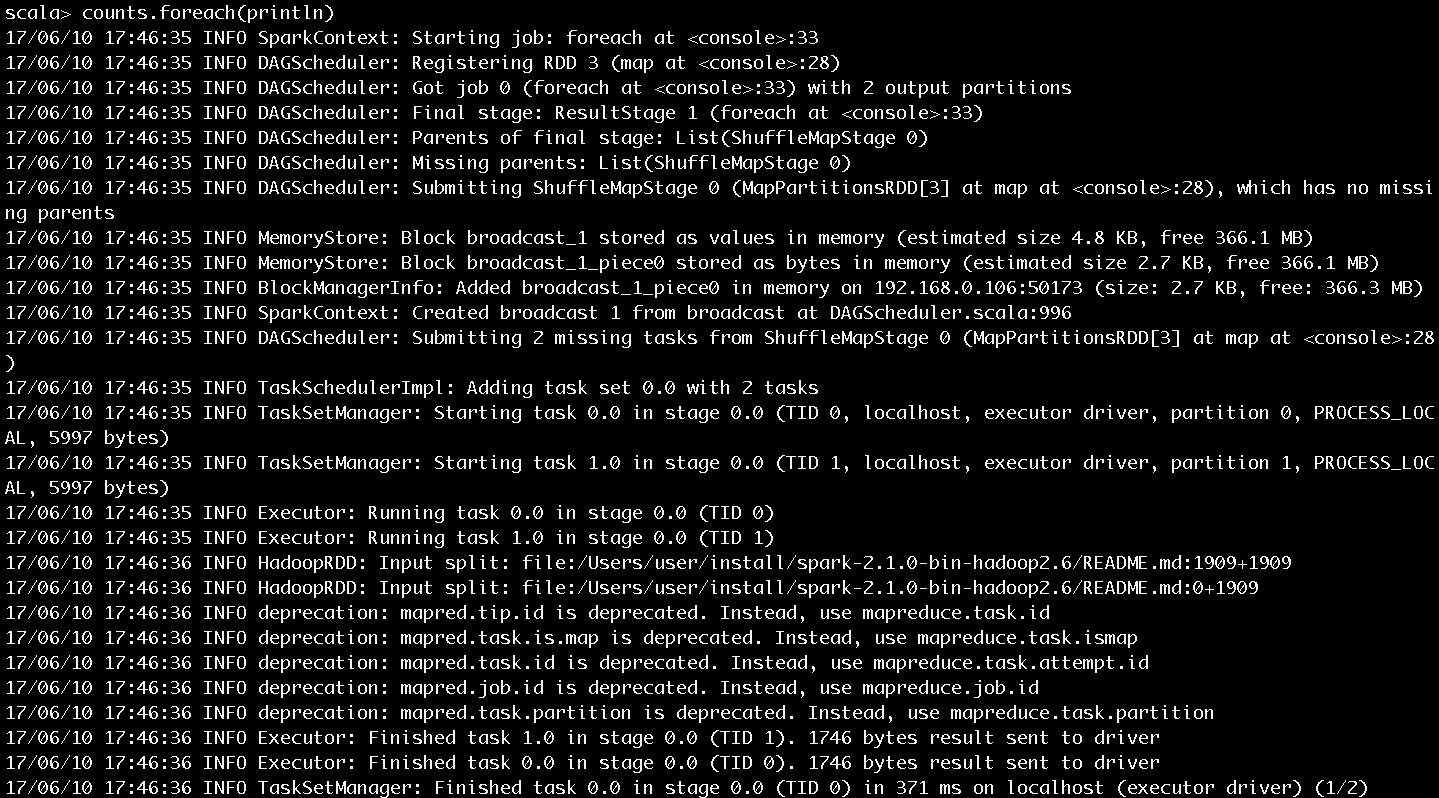
圖10 步驟5執行過程第一部分
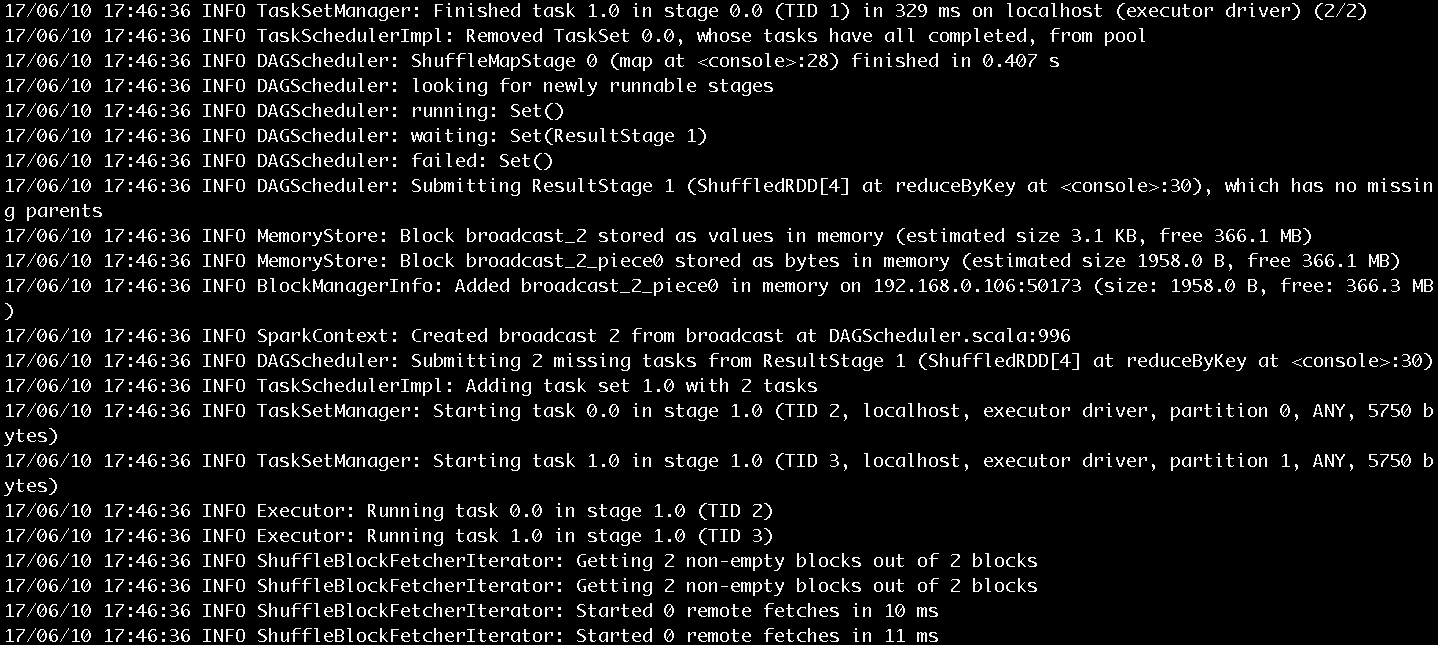
圖11 步驟5執行過程第二部分
圖10和圖11展示了很多作業提交、執行的資訊,這裡挑選關鍵的內容進行介紹:
- SparkContext為提交的Job生成的ID是0。
- 一共有四個RDD,被劃分為ResultStage和ShuffleMapStage。ShuffleMapStage的ID為0,嘗試號為0。ResultStage的ID為1,嘗試號也為0。在Spark中,如果Stage沒有執行完成,就會進行多次重試。Stage無論是首次執行還是重試都被視為是一次Stage嘗試(Stage Attempt),每次Attempt都有一個唯一的嘗試號(AttemptNumber)。
- 由於Job有兩個分割槽,所以ShuffleMapStage和ResultStage都有兩個Task被提交。每個Task也會有多次嘗試,因而也有屬於Task的嘗試號。從圖中看出ShuffleMapStage中的兩個Task和ResultStage中的兩個Task的嘗試號也都是0。
- HadoopRDD則用於讀取檔案內容。
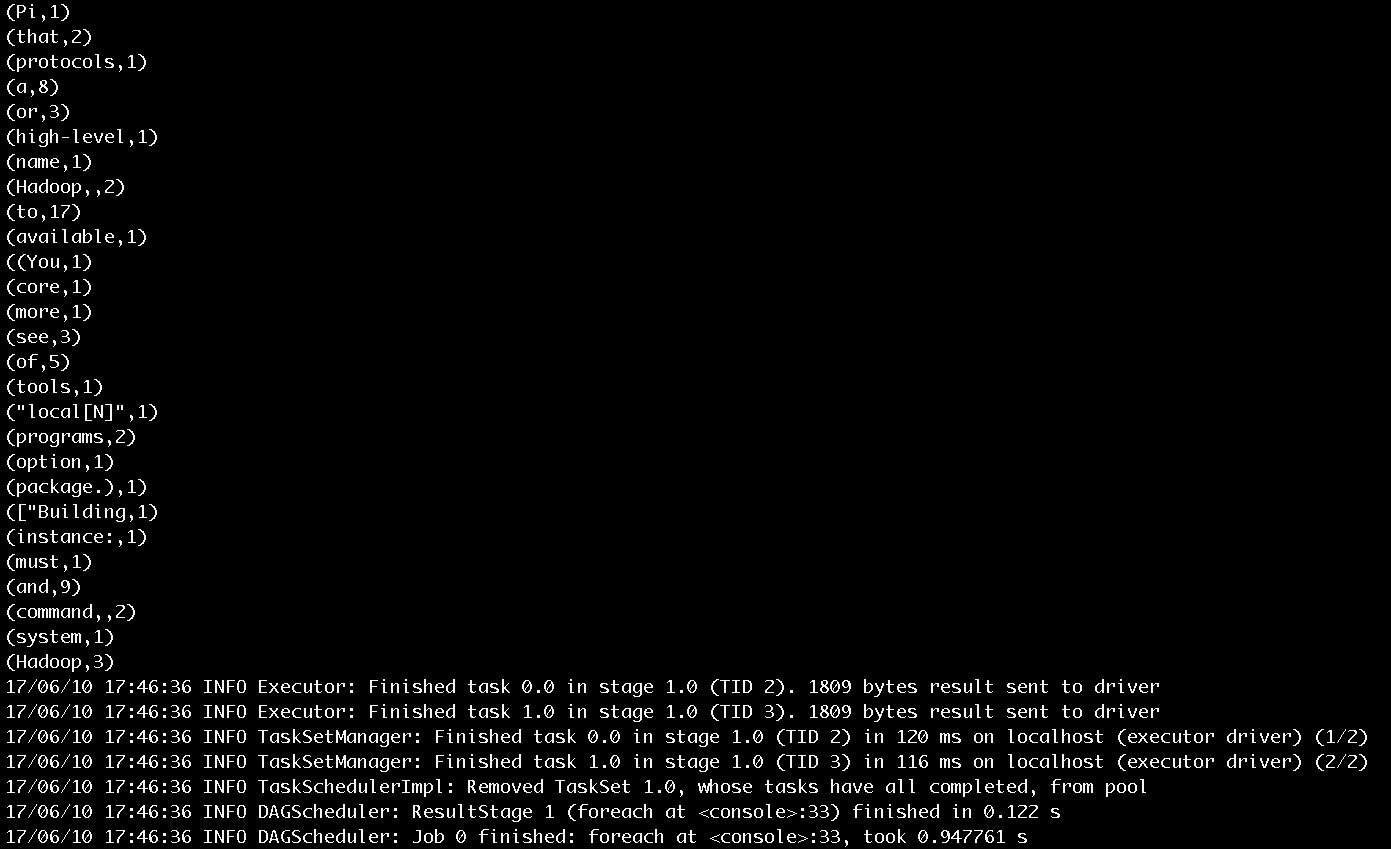
圖12 步驟5輸出結果
圖12展示了單詞計數的輸出結果和最後列印的任務結束的日誌資訊。
本文介紹的word count例子是以SparkContext的API來實現的,讀者朋友們也可以選擇在spark-shell中通過運用SparkSession的API來實現。
有了對Spark的初次體驗,下面可以來分析下spark-shell的實現原理了,請看——《Spark2.1.0——剖析spark-shell》
想要對Spark原始碼進行閱讀的同學,可以看看《Spark2.1.0——程式碼結構及載入Ecplise方法》
關於《Spark核心設計的藝術 架構設計與實現》
經過近一年的準備,基於Spark2.1.0版本的《Spark核心設計的藝術 架構設計與實現》一書現已出版發行,圖書如圖:
相關推薦
Spark2.1.0——Spark初體驗
學習一個工具的最好途徑,就是使用它。這就好比《極品飛車》玩得好的同學,未必真的會開車,要學習車的駕駛技能,就必須用手觸控方向盤、用腳感受剎車與油門的力道。在IT領域,在深入瞭解一個系統的原理、實現細節之前,應當先準備好它的執行環境或者原始碼閱讀環境。如果能在實際環境下安裝和執行Spark,顯然能夠
Spark2.1.0——SparkContext初始化之Spark環境的建立
閱讀指導:在《Spark2.1.0——SparkContext概述》一文中,曾經簡單介紹了SparkEnv。本節內容將詳細介紹SparkEnv的建立過程。 在Spark中,凡是需要執行任務的地方就需要SparkEnv。在生產環境中,SparkEnv往往運行
Spark2.1.0文件:Spark程式設計指南-Spark Programming Guide
1 概述 從一個較高的層次來看,每一個 Spark 應用程式由兩部分組成:driver program(驅動程式)端執行的 main 函式以及在整個叢集中被執行的各種並行操作。Spark 提供的主要抽象是一個彈性分散式資料集(RDD),它是可以被並行處理且跨節點分佈的元素的
Spark之——Hadoop2.7.3+Spark2.1.0 完全分散式環境 搭建全過程
一、修改hosts檔案在主節點,就是第一臺主機的命令列下;vim /etc/hosts我的是三臺雲主機:在原檔案的基礎上加上;ip1 master worker0 namenode ip2 worker1 datanode1 ip3 worker2 datanode2其中的i
Spark2.1.0文件:Spark Streaming 程式設計指南(上)
本文翻譯自spark官方文件,僅翻譯了Scala API部分,目前版本為2.1.0,如有疏漏錯誤之處請多多指教。 原文地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 因文件篇幅較
子雨大資料之Spark入門教程---Spark2.1.0入門:第一個Spark應用程式:WordCount 2.2
前面已經學習了Spark安裝,完成了實驗環境的搭建,並且學習了Spark執行架構和RDD設計原理,同時,我們還學習了Scala程式設計的基本語法,有了這些基礎知識作為鋪墊,現在我們可以沒有障礙地開始編寫一個簡單的Spark應用程式了——詞頻統計。 任務要求 任務:
git系列1之安裝初體驗(windows)
conf pan cnblogs it管理 png 下一步 rac -1 stage 1.百度雲盤地址 https://pan.baidu.com/s/1o8vAt78 2.下載後雙擊直接下一步下一步即可 3.創建一個目錄,並在目錄中創建文件README.CD 4.
在Spark2.1.0中使用Date作為DateFrame列
down -s log set tor com ref ons 使用 參考網址:How to store custom objects in Dataset? 在Spark2.1.0中使用Date作為DateFrame列
Spark2.1.0——運行環境準備
目錄 linux lin hadoop -h rtc 內存 ssp 代碼結構 學習一個工具的最好途徑,就是使用它。這就好比《極品飛車》玩得好的同學,未必真的會開車,要學習車的駕駛技能,就必須用手觸摸方向盤、用腳感受剎車與油門的力道。在IT領域,在深入了解一個系統
(1)java8初體驗
turn person tab nbsp wysiwyg mac 為我 target ide 很多博客都拿Comparator,我也貼一下吧。 java8以前的匿名內部類用來排序。 //匿名內部類 @Test public void java8Test() {
eclipse4.7.0+maven3.3.9+scala2.11.8+spark2.1.0+hadoop2.7.1在ubuntu16裡的wordcount例項
刪掉src/test下的junit內容 pom.xml參考如下進行修改(確認好使) <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XM
spark2.1.0 on yarn with CDH5.8.0 安裝實戰
Spark 版本釋出很快,CDH整合最新Spark版本需要一定時間,並且CDH 整合的Spark版本不支援Spark-sql。本文件的目的在目前cdh平臺整合最新spark,方便測試和使用最新功能。 spark-env.sh #HADOOP_CONF_DIR ha
spark2.1.0編譯 cdh5.7.0版本
一、實現目標 從spark官網下載2.1.0的原始碼,然後編譯對應hadoop版本的spark,從而可以解決很多相容性問題,使程式執行環境更加優越,順暢。 二、環境準備 1.硬體 無論雲主機還是虛擬機器,記憶體一定要4G以上,最好8G+。 2.軟體 (1)java:spark
【TP5.1】容器初體驗
author:咔咔 wechat:fangkangfk 我們先來用寫一個呼叫普通方法案例 比如我們在common下有一個vessle的類 現在需要在index下面的index檔案呼叫 那麼我們就是在index這個檔案引入c
spark 初體驗
一、spark的產生背景 (1)MapReduce的發展: MRv1的缺點: 早在 Hadoop1.x 版本,當時採用的是 MRv1 版本的 MapReduce 程式設計模型。MRv1 版本的實現 都封裝在 org.apache.hadoop.mapred
Doxygen生成美麗註釋文件(1):初體驗
Hello Doxygen [TOC] Chapter 1 - 準備工作 (Windows環境) 1.1 程式包下載 Doxygen 原始碼: git clone https://github.com/doxygen/doxygen.git GUI版
Spark2.1.0模型設計與基本架構(上)
隨著近十年網際網路的迅猛發展,越來越多的人融入了網際網路——利用搜索引擎查詢詞條或問題;社交圈子從現實搬到了Facebook、Twitter、微信等社交平臺上;女孩子們現在少了逛街,多了在各大電商平臺上的購買;喜歡棋牌的人能夠在對戰平臺上找到世界各地的玩家對弈。在國內隨著網民數量的持續增加,造成網際網路公
Spark2.1.0事件匯流排分析——LiveListenerBus詳解
LiveListenerBus繼承了SparkListenerBus,並實現了將事件非同步投遞給監聽器,達到實時重新整理UI介面資料的效果。LiveListenerBus主要由以下部分組成: eventQueue:是SparkListenerEvent事件的阻塞佇列,佇
Spark2.1.0模型設計與基本架構(下)
閱讀提示:讀者如果對Spark的背景知識不是很瞭解的話,建議首先閱讀《SPARK2.1.0模型設計與基本架構(上)》一文。 Spark模型設計 1. Spark程式設計模型 正如Hadoop在介紹MapReduce程式設計模型時選擇word count的例子,並且使用圖形來說明一樣,筆者對於Spark程式設計
spark2.1.0釋出了
2016年12月28日釋出 此版本更改 預設scala版本是Scala 2.11 官網看到 Spark runs on Java 7+, Python 2.6+/3.4+ and R 3.1+. For the Scala API, Spark 2.1.0uses Scala 2