
Caffe學習系列(22):caffe圖形化操作工具digits執行例項
經過前面的操作,我們就把資料準備好了。
一、訓練一個model
右擊右邊Models模組的” Images" 按鈕 ,選擇“classification"
在開啟頁面右下角可以看到,系統提供了一個caffe model,分別為LeNet, AlexNet, GoogLeNet, 如果使用這三個模型,則所有引數都已經設定好了,就不用再設定了。
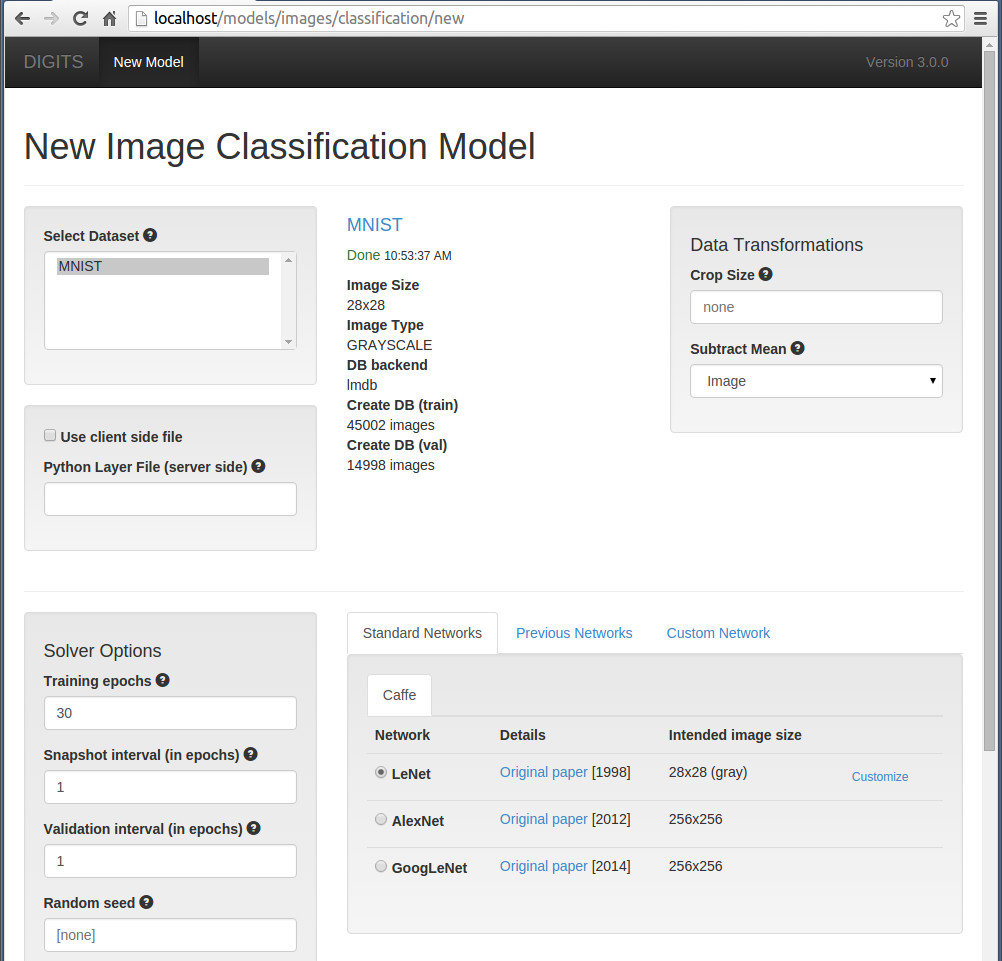
在下面,系統為我們列舉出了本機所帶的顯示卡,我們可以選擇其中一塊進行執行。
在最下面,輸入一個model name, 就可以點選create 按鈕了。如果有些選項不對,會有錯誤提示,很人性化。

在訓練過程頁面,左上角顯示了生成的配置檔名稱 (放在job目錄檔案下,預設路徑為:/usr/share/digits/digits/jobs/),執行過程中儲存的caffemodel快照也儲存在這個目錄下面。
頁面中間顯示了訓練和測試的資料資訊,右面顯示了訓練所用的時間和gpu使用情況,下面就是一些實時化圖表,可以看到訓練階段的loss, 測試階段的loss和accuracy,相當方便,甚至還可以看到學習率的變化情況,吃驚吧!
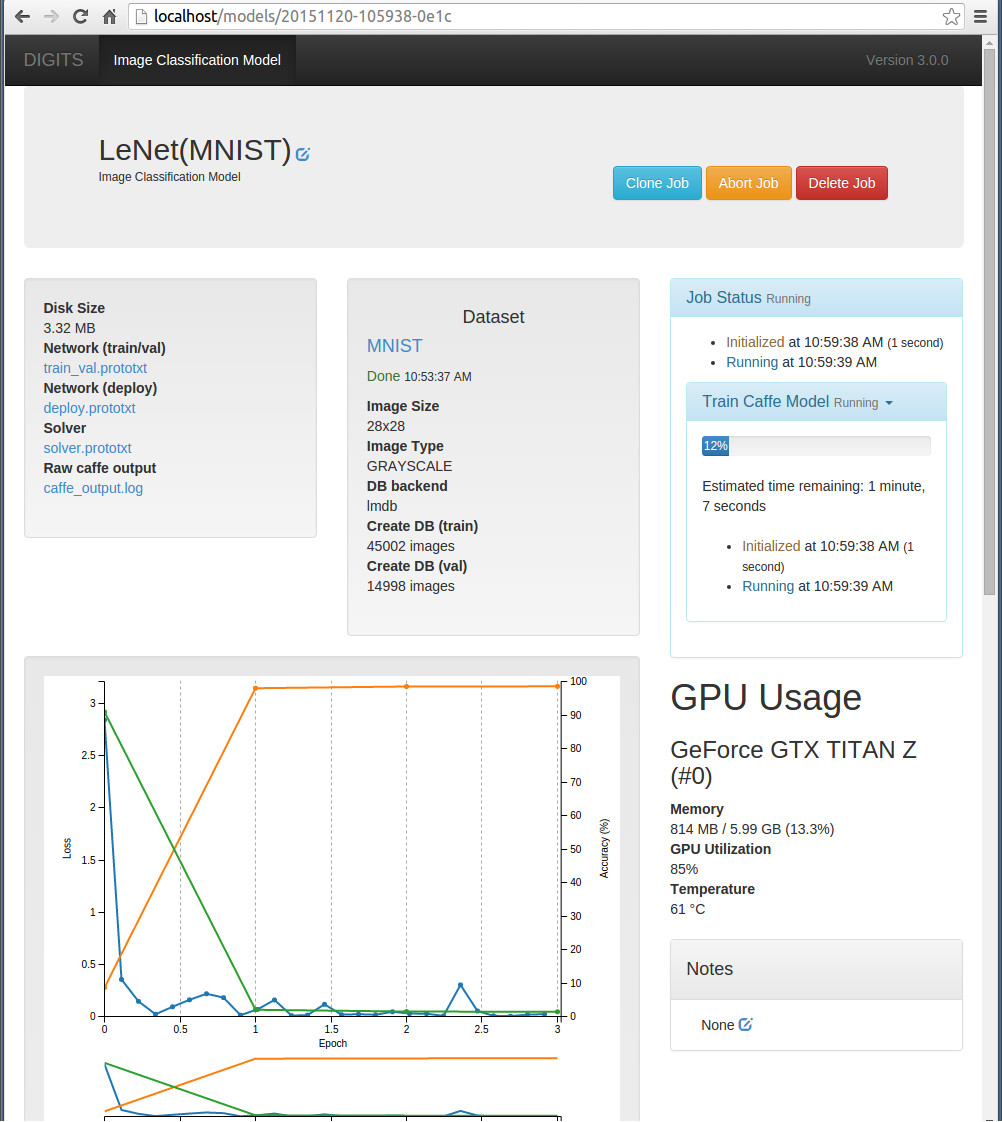
模型訓練好後,直接就可以在下面進行測試了。
二、測試新來的圖片
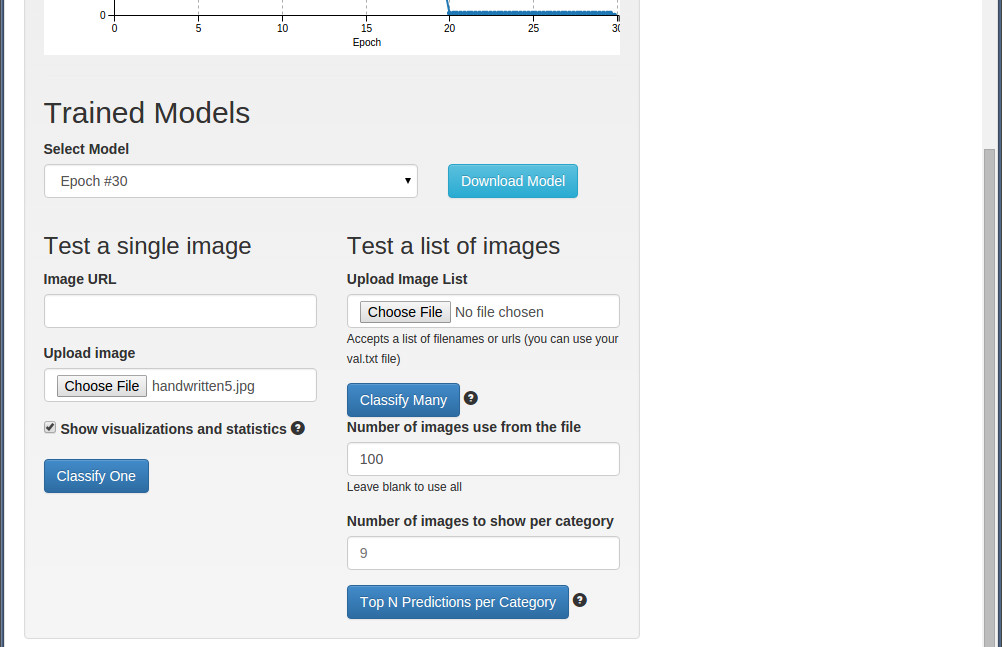
將頁面拖到最下面,選擇Upload imager按鈕,載入一幅測試圖片。在 /home/username/mnist/test/ 下面有大量的測試圖片,隨便選一張就可以了。
也可以通過在Image URL方框裡,輸入一張網上的圖片地址來進行測試。
載入好測試圖片,在 Show visualizations and statistics
點選”Classify One" 按鈕就可以開始測試了。
如果你不是對一張圖片進行測試,而是一個測試集,則是在" Upload Image List"這個地方,選擇測試圖片的列表清單檔案(如 val.txt)
系統會彈出一個新的頁面,顯示top-5的分類情況 ,同時digits還提供了測試資料與權值的視覺化和統計資訊。
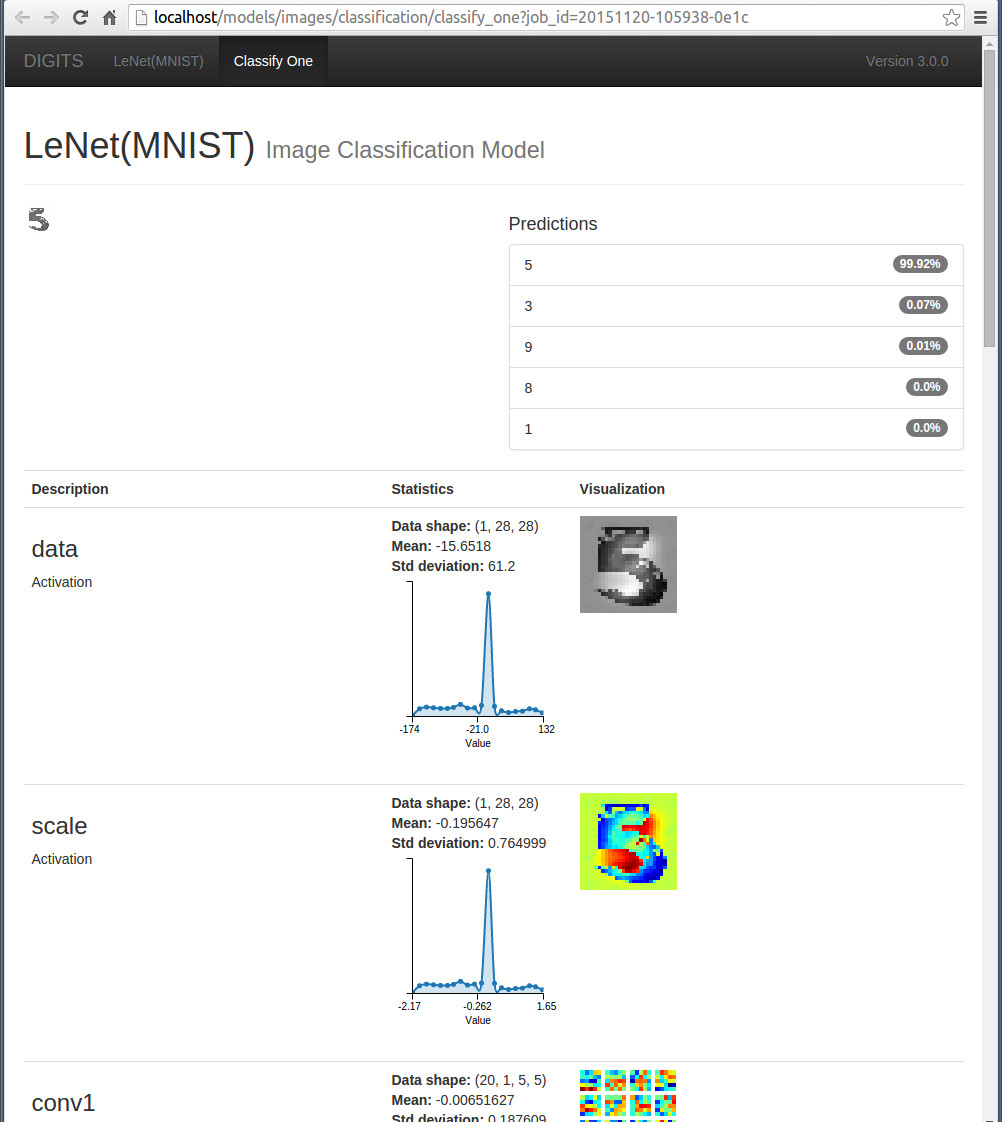
最後一句話總結,nvidia digits, 誰用誰知道!
相關推薦
Caffe學習系列(22):caffe圖形化操作工具digits執行例項
經過前面的操作,我們就把資料準備好了。 一、訓練一個model 右擊右邊Models模組的” Images" 按鈕 ,選擇“classification" 在開啟頁面右下角可以看到,系統提供了一個caffe model,分別為LeNet, AlexNet, GoogLeNet, 如果使用這三個模型,
Caffe學習系列(21):caffe圖形化操作工具digits的安裝與執行
經過前面一系列的學習,我們基本上學會了如何在linux下執行caffe程式,也學會了如何用python介面進行資料及引數的視覺化。 也許有人會覺得比較複雜。確實,對於一個使用慣了windows視窗操作的使用者來說,各種命令就要了人命,甚至會非常抵觸命令操作。沒有學過python,要自己去用python程
Caffe學習系列(13):資料視覺化環境(python介面)配置 jupyter notebook
caffe程式是由c++語言寫的,本身是不帶資料視覺化功能的。只能藉助其它的庫或介面,如opencv, python或matlab。大部分人使用python介面來進行視覺化,因為python出了個比較強大的東西:ipython notebook, 現在的最新版本改名叫jupyter notebook,它能將
【21】digits工具:caffe圖形化操作工具digits的安裝
經過前面一系列的學習,我們基本上學會了如何在linux下執行caffe程式,也學會了如何用python介面進行資料及引數的視覺化。 也許有人會覺得比較複雜。確實,對於一個使用慣了windows視窗操作的使用者來說,各種命令就要了人命,甚至會非常抵觸命令操作。沒有學過python,要自己去用pyt
Caffe學習系列(14):初識資料視覺化
轉載自http://www.cnblogs.com/denny402/p/5092075.html 在jupyter notebook裡 首先將caffe的根目錄作為當前目錄,然後載入caffe程式自帶的小貓圖片,並顯示。 圖片大小為360x480,三通道 In [
【2】Caffe學習系列(11):影象資料轉換成db(leveldb/lmdb)檔案
在深度學習的實際應用中,我們經常用到的原始資料是圖片檔案,如jpg,jpeg,png,tif等格式的,而且有可能圖片的大小還不一致。而在caffe中經常使用的資料型別是lmdb或leveldb,因此就產生了這樣的一個問題:如何從原始圖片檔案轉換成caffe中能夠執行的db(l
Caffe學習系列(20):用訓練好的caffemodel來進行分類
#coding=utf-8 #載入必要的庫 import numpy as npimport sys,os #設定當前目錄 caffe_root = '/home/xxx/caffe/' sys.path.insert(0, caffe_root + 'python') import caffe os.c
Caffe學習系列(1):安裝配置ubuntu14.04+cuda7.5+caffe+cudnn
一、版本 linux系統:Ubuntu 14.04 (64位) 顯示卡:Nvidia K20c cuda: cuda_7.5.18_linux.run cudnn: cudnn-7.0-linux-x64-v4.0-rc 二、下載 Ubuntu 14.04下載地址:http://www.ubunt
Caffe學習系列(7):solver及其配置
solver算是caffe的核心的核心,它協調著整個模型的運作。caffe程式執行必帶的一個引數就是solver配置檔案。執行程式碼一般為 # caffe train --solver=*_slover.prototxt 在Deep Learning中,往往loss
Caffe學習系列(23):如何將別人訓練好的model用到自己的資料上
caffe團隊用imagenet圖片進行訓練,迭代30多萬次,訓練出來一個model。這個model將圖片分為1000類,應該是目前為止最好的圖片分類model了。 假設我現在有一些自己的圖片想進行分類,但樣本量太小,可能只有幾百張,而一般深度學習都要求樣本量在1萬以上,因此訓練出來的model精度太低,根
Docker系列(七):Docker圖形化管理和監控
Docker管理工具之官方三劍客 Docker Machine是什麼鬼 從前 現在 你需要登入主機,按照主機及作業系統特有的安裝以及配置步驟安裝Docker,使其 能執行Docker容器。 Docker Machine的產生簡化了這一過程,讓你可以使用一條命令在你的計算機,公有云
Java I/O系統學習系列五:Java序列化機制
在Java的世界裡,建立好物件之後,只要需要,物件是可以長駐記憶體,但是在程式終止時,所有物件還是會被銷燬。這其實很合理,但是即使合理也不一定能滿足所有場景,仍然存在著一些情況,需要能夠在程式不執行的情況下保持物件,所以序列化機制應運而生。 1. 為什麼要有序列化 簡單來說序列化的作用就是將記憶體中的
SQLite學習筆記三:SQLite視覺化管理工具彙總
蒐集了一些SQLite工具,在這裡做個總結,有的工具用的多一些,有的只是簡單試用,甚至未試用,所以有描述不當的還請回復指正,也歡迎補充完善! 2015-03-11 更新情況: SQLiteSpy最新版本1.9.8,重大改變,支援db拖拽 SQLiteStudio
spark mlib 機器學習系列之一:Spark rdd 常見操作
package mlib import org.apache.spark.SparkContext import org.apache.spark.sql.SparkSession object UsefulRddOpts { def main(ar
【13】Caffe學習系列:資料視覺化環境(python介面)配置
caffe程式是由c++語言寫的,本身是不帶資料視覺化功能的。只能藉助其它的庫或介面,如opencv, python或matlab。更多人會使用python介面來進行視覺化,因為python出了個比較強大的東西:ipython notebook, 現在的最新版本改名叫jupyter notebook
【16】Caffe學習系列:caffemodel視覺化
同樣的程式碼部分可參考github。 net = caffe.Net(caffe_root + 'examples/cifar10/cifar10_full.prototxt', caffe_root + 'examples/cifar10/
Caffe學習系列——工具篇:神經網路模型結構視覺化
在Caffe中,目前有兩種視覺化prototxt格式網路結構的方法: 使用Netscope線上視覺化 使用Caffe提供的draw_net.py 本文將就這兩種方法加以介紹 1. Netscope:支援Caf
Caffe學習系列:模型各層資料和引數視覺化
從輸入的結果和圖示來看,最大的概率是7.17785358e-01,屬於第5類(標號從0開始)。與cifar10中的10種類型名稱進行對比: airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck 根據測試結果,判斷為dog。 測試無誤!
Caffe學習系列:資料視覺化環境(python介面)配置
caffe程式是由c++語言寫的,本身是不帶資料視覺化功能的。只能藉助其它的庫或介面,如opencv, Python或matlab。大部分人使用python介面來進行視覺化,因為python出了個比較強大的東西:ipython notebook, 現在的最新版本改名叫ju
【14】Caffe學習系列:計算圖片資料的均值
圖片減去均值後,再進行訓練和測試,會提高速度和精度。因此,一般在各種模型中都會有這個操作。 那麼這個均值怎麼來的呢,實際上就是計算所有訓練樣本的平均值,計算出來後,儲存為一個均值檔案,在以後的測試中,就可以直接使用這個均值來相減,而不需要對測試圖片重新計算。 一、二進位制格式的均值計算