
爬蟲專案:scrapy爬取暱圖網全站圖片
一、建立專案、spider,item以及配置setting
建立專案:scrapy startproject nitu
建立爬蟲:scrapy genspider -t basic nituwang nipic.com
寫個item:
# -*- coding: utf-8 -*-
import scrapy
class NituItem(scrapy.Item):
url = scrapy.Field()配置setting(重要!):
1.首先開啟User-Agent(反爬蟲策略):
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
2.ROBOTSTXT協議改為False(主要是為了順利獲取圖片)
3.開啟pipeline:
ITEM_PIPELINES = {
'nitu.pipelines.NituPipeline': 300,
}二、spider
(一)首先來分析暱圖網中的各個分層連結

找到這三個模組的連結比較簡單:

可以看出,只要找到a標籤下的三個href連結就行了,抓到的內容附在主網頁http://www.nipic.com後,例如http://www.nipic.com/media就可以進入這個模組的連結中,spider程式碼如下:
#第一層連結 def parse(self, response): Frist_url = response.xpath('//div[@class="newIndex-nav-condition fl"]/a/@href').extract() True_url = Frist_url[2:5] for i in range(len(True_url)): TrueTrue_url = "http://www.nipic.com/" + True_url[i] yield Request(url=TrueTrue_url,callback=self.next1)
(二)進入到第二層連結,如下圖:

同理,從審查元素中抓取連結:
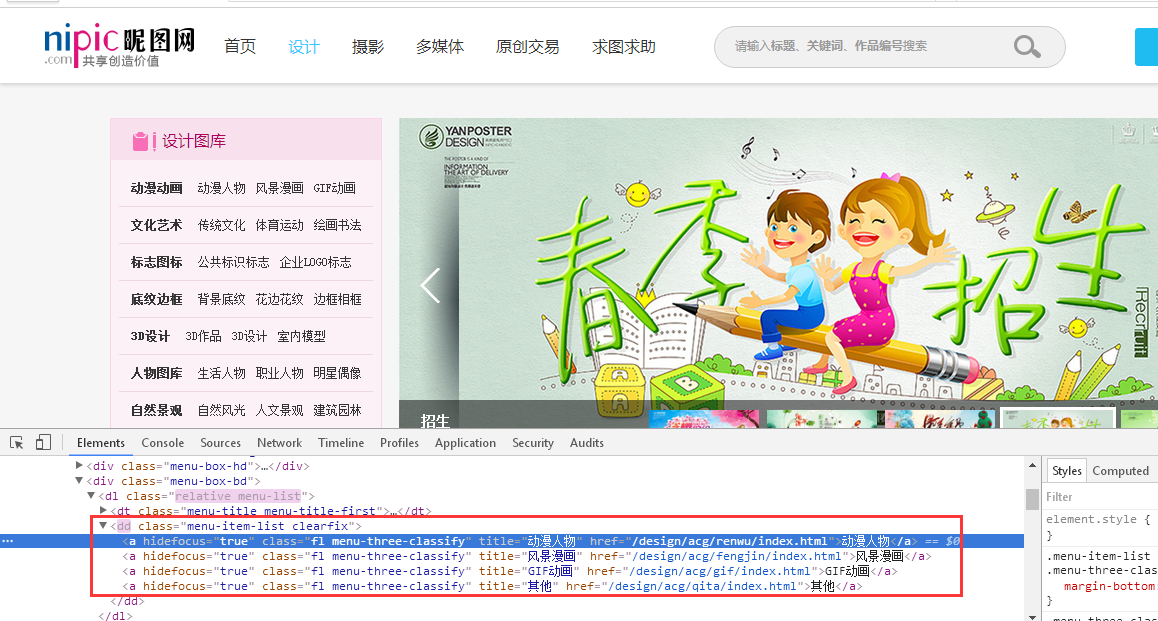
spider程式碼如下:
#第二層連結 def next1(self,response): Second_url = response.xpath('//dd[@class="menu-item-list clearfix"]//a/@href').extract() for m in range(len(Second_url)): Second_true_url = "http://www.nipic.com/" + Second_url[m] yield Request(url=Second_true_url,meta={'key':Second_true_url},callback=self.next2)
(三)進入到第二層連結之後,就直接出現了多頁存在圖片了,思路越來越清晰:

看到這裡,我們只需找到二層連結中的總頁數,由此建立一個函式:
def next2(self,response):
#查詢總頁數
page_num = response.xpath('//div[@class="common-page-box mt10 align-center"]/a/@href').extract()
page_true_num = page_num[-1].split('=')[-1]
for n in range(1,int(page_true_num)+1):
page_url = str(response.meta['key']) + "?page=" + str(n)
yield Request(url=page_url,callback=self.next3)(四)接下來就是查詢如何進入照片的第三層連結,以獲取清晰大圖:

二話不說,直接寫xpath來拿連結:
#第三層連結
def next3(self,response):
img_url = response.xpath('//li[@class="works-box mb17 fl"]/div[@class="search-works-info"]/a/@href').extract()
for k in range(len(img_url)):
yield Request(url=img_url[k],callback=self.next4)(五)最後一部,成敗於此,進入到大圖的連結:

拿下:
#獲取大圖的連結
def next4(self,response):
img_big_url = response.xpath('//div[@class="show-img-section overflow-hidden align-center"]/img/@src').extract()[0]
item = NituItem()
item['url'] = img_big_url
yield item三、PIPELINE:
使用urllib.request中的urlretrieve來下載圖片到本地當中
import urllib.request
class NituPipeline(object):
def process_item(self, item, spider):
filename = item["url"].split('/')[-1]
file = "F:/python/python專案/nitu_img/" + filename
urllib.request.urlretrieve(item["url"], filename=file)
return item
四、執行爬蟲
scrapy crawl nituwang --nolog
結果如下:
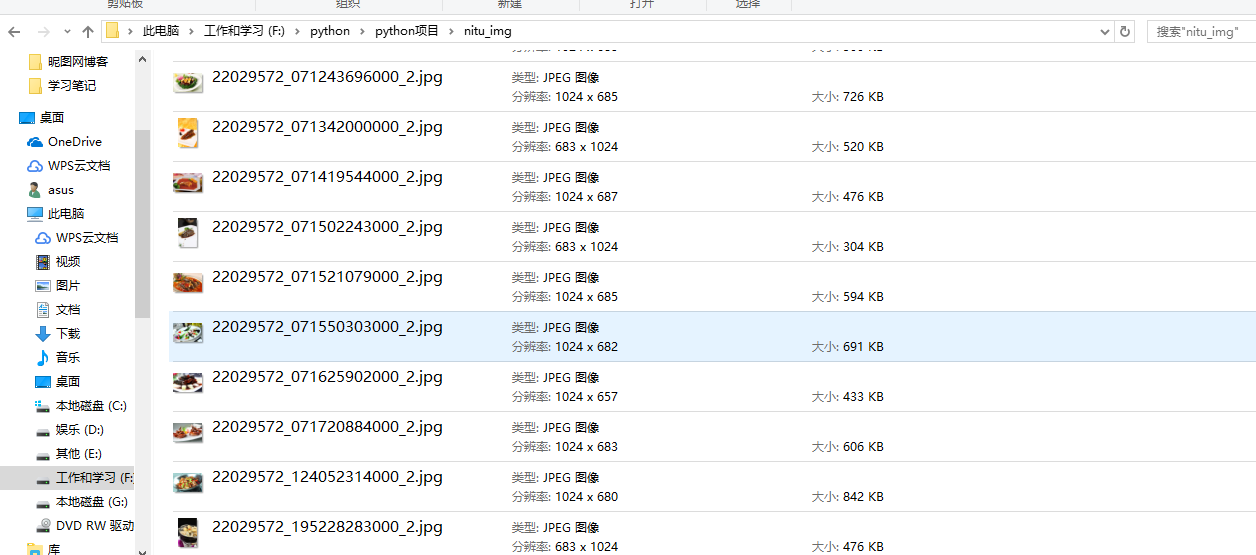
高清無碼大圖得到。完活
相關推薦
爬蟲專案:scrapy爬取暱圖網全站圖片
一、建立專案、spider,item以及配置setting建立專案:scrapy startproject nitu建立爬蟲:scrapy genspider -t basic nituwang nipic.com寫個item:# -*- coding: utf-8 -*-
Python爬蟲框架:Scrapy 爬取伯樂線上實戰
專案介紹 使用Scrapy框架進行爬取伯樂線上的所有技術文章 所用知識點 Scrapy專案的建立 Scrapy框架Shell命令的使用 Scrapy自帶的圖片下載管道 Scrapy自定義圖片下載管道(繼承自帶的管道) Scrapy框架ItemLoader
網路爬蟲-使用Scrapy爬取千圖網素材
話說好久好久好久沒寫過scrapy的demo了,已經快忘得差不多了,今天一個小老弟讓我幫他看看怎麼大量快速爬取千圖網的素材,我進網站看了看,一是沒有什麼反爬措施,二是沒有封ip的限制,那這種情況,鐵定用scrapy這個非同步框架最舒服了,於是花了十幾分鍾看了看自
爬蟲專案:requests爬取豆瓣電影TOP250存入excel中
這次爬取是爬取250部電影的相關內容,分別用了requests請求url,正則表示式re與BeautifulSoup作為內容過濾openpyxl作為excel的操作模組,本人為才學不久的新手,程式碼編寫有點無腦和囉嗦,希望有大神能多提建議 首先,程式碼清單如下:
Scrapy爬蟲(5)爬取當當網圖書暢銷榜
The log sdn detail iss 就是 pan 微信公眾號 打開 ??本次將會使用Scrapy來爬取當當網的圖書暢銷榜,其網頁截圖如下: ??我們的爬蟲將會把每本書的排名,書名,作者,出版社,價格以及評論數爬取出來,並保存為csv格式的文件。項目的具體創建就不
萌新爬蟲的動力就是爬取妹子圖!批量爬取妹子圖喲!
進群:960410445 即可獲取原始碼! 目錄 前言 Media Pipeline 啟用Media Pipeline 使用 ImgPipeline 抓取妹子圖 瞎比比與送書後話 前言 我們在抓取資料的過程中,除了要抓取
網路爬蟲之scrapy爬取某招聘網手機APP釋出資訊
1 引言 2 APP抓包分析 3 編寫爬蟲昂 4 總結 1 引言 過段時間要開始找新工作了,爬取一些崗位資訊來分析一下吧。目前主流的招聘網站包括前程無憂、智聯、BOSS直聘、拉勾等等。有
python爬蟲爬取鬥圖網 最新表情包(第二篇)
上一篇文章爬的表情包是套圖,發現還有一千多頁的最新表情包。兩者的網頁結構有點區別,程式碼需要整改下,看下頁面,規律也比較好找。 非常氣憤,上一個部落格被其他爬走了,還是一個培訓機構,插了自己的廣告! 所有的表情圖片都是在標籤下,數了一下每一頁都是17行,
【圖文詳解】scrapy爬蟲與動態頁面——爬取拉勾網職位資訊(1)
5-14更新 注意:目前拉勾網換了json結構,之前是content - result 現在改成了content- positionResult - result,所以大家寫程式碼的時候要特別注意加上
python爬蟲-使用多程序爬取美圖-人工智慧語言(高效爬蟲)
import os from multiprocessing.pool import Pool from urllib.parse import urlencode from hashlib import md5 import requests def loaDpage(fullurl):
文字分類(二):scrapy爬取網易新聞
文字分類的第一項應該就是獲取文字了吧。 在木有弄懂scrapy的情況下寫的,純應用,或許後續會補上scrapy的原理。 首先說一下我的環境:ubuntu14.10 scrapy安裝指南(肯定官網的最權威了):[傳送門](http://scrapy-chs.rea
學會用python網路爬蟲爬取鬥圖網的表情包,聊微信再也不怕鬥圖了
最近總是有人跟我鬥圖,想了想17年中旬時在網上看過一篇關於爬取鬥圖網表情包的py程式碼,但是剛想爬的時候發現網頁結構發生了變化,而且鬥圖網還插入了很多廣告,變化其實挺大的,所以臨時寫了一個爬蟲,簡單的爬取了鬥圖網的表情包。從這連結上看,page表示的是第幾頁,我
【圖文詳解】scrapy爬蟲與動態頁面——爬取拉勾網職位資訊(2)
上次挖了一個坑,今天終於填上了,還記得之前我們做的拉勾爬蟲嗎?那時我們實現了一頁的爬取,今天讓我們再接再厲,實現多頁爬取,順便實現職位和公司的關鍵詞搜尋功能。 之前的內容就不再介紹了,不熟悉的請一定要去看之前的文章,程式碼是在之前的基礎上修改的
Python3[爬蟲實戰] scrapy爬取汽車之家全站連結存json檔案
昨晚晚上一不小心學習了崔慶才,崔大神的部落格,試著嘗試一下爬取一個網站的全部內容,福利吧網站現在已經找不到了,然後一不小心逛到了汽車之家 (http://www.autohome.com.cn/beijing/) 很喜歡這個網站,女人都喜歡車,更何況男人呢。(
Python爬蟲——利用requests模組爬取妹子圖
近期學了下python爬蟲,利用requests模組爬取了妹子圖上的圖片,給單身狗們發波福利,哈哈!順便記錄一下第一次發部落格。 話不多說,進入正題 開發環境 python 3.6 涉及到的庫 requests lxml 先上一波爬取的截圖
Python資料爬蟲學習筆記(11)爬取千圖網圖片資料
需求:在千圖網http://www.58pic.com中的某一板塊中,將一定頁數的高清圖片素材爬取到一個指定的資料夾中。 分析:以數碼電器板塊為例 1.檢視該板塊的每一頁的URL: 注意到第一頁是“0-1.html”,第二頁是“0-2.html”,由
Scrapy爬取拉鉤網的爬蟲(爬取整站CrawlSpider)
經過我的測試,拉鉤網是一個不能直接進行爬取的網站,由於我的上一個網站是扒的介面,所以這次我使用的是scrapy的整站爬取,貼上當時的程式碼(程式碼是我買的視訊裡面的,但是當時是不需要登陸就可以爬取的): class LagouSpider(CrawlSpider):
Scrapy爬取慕課網(imooc)所有課程數據並存入MySQL數據庫
start table ise utf-8 action jpg yield star root 爬取目標:使用scrapy爬取所有課程數據,分別為 1.課程名 2.課程簡介 3.課程等級 4.學習人數 並存入MySQL數據庫 (目標網址 http://www.imoo
用Python多線程實現生產者消費者模式爬取鬥圖網的表情圖片
Python什麽是生產者消費者模式 某些模塊負責生產數據,這些數據由其他模塊來負責處理(此處的模塊可能是:函數、線程、進程等)。產生數據的模塊稱為生產者,而處理數據的模塊稱為消費者。在生產者與消費者之間的緩沖區稱之為倉庫。生產者負責往倉庫運輸商品,而消費者負責從倉庫裏取出商品,這就構成了生產者消費者模式。 生
scrapy爬取校花網圖片
xiaohua.py # -*- coding: utf-8 -*- import scrapy from pyquery import PyQuery from scrapy.http import Request from ..items import XiaohuarItem class