
關於大型網站技術演進的思考(十二)--網站靜態化處理—快取(4)
上篇我補充了下SSI的知識,SSI是一個十分常見的技術,記得多年前我看到很多入口網站頁面的字尾是.shtml,那麼這就說明很多入口網站都曾經使用過SSI技術,其實現在搜狐網站也還在用shtml,如下圖所示:

由此可見SSI在網際網路的應用還是非常廣泛的。其實網際網路很多網頁如果我們按照動靜分離策略拆分,絕大部分都是可以當做靜態資源處理,例如新聞網站,文學網站,這些網頁生成後,大部分的資源都是不變的,說白了這些網頁本質就是一個靜態頁面,我們開發他們時候也不需要服務端的參入,每一個網站都有自己固定的板式,假如每個新網頁都要完完整整的開發,重複性的工作實在太多了,出錯的概率也非常高,在本系列第二篇裡我曾經詳細介紹了velocity的佈局模板技術,其實SSI也可以製作出一套固定的模板,開發時候我們只需要在定義好的模板裡新增或者修改我們需要更改的內容就可以完成一個頁面的製作,可見SSI技術為了我們開發網頁提供了很大的便利。
與SSI相對應的還有ESI,這個技術不是太常用,在網上能收集到的資料也不是太多,網上有限的資料也基本都是和淘寶相關的,不過仔細研究下淘寶對ESI的運用,對於理解網站靜態化處理是非常有借鑑意義的,下面我將重點講講ESI的知識。首先看個場景啊。
我們登入支付寶網站,到了個人首頁我們發現在支付寶下面有一個條目,如下圖所示:

這是支付寶預設給我們顯示的【生活好助手】,右邊有個箭頭,我們點開它,如下圖所示:
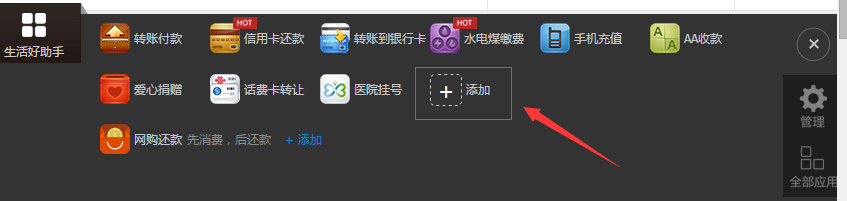
我們看到這裡有新增的按鈕,通過新增按鈕,我們可以新增其他常用的元件圖示。(注意:我這裡只是以支付寶這個功能為例,支付寶是否按照我說的設計,這個我就不清楚了)
如果我們按照自己個性化添加了自己的元件,不同的人新增的常用元件也會是不盡相同的,如果我們自己開發的網站也有這樣的功能,那麼我們該如何設計了?我們一般都會很直觀的把這個新增的元件資訊儲存在資料庫裡,使用者每次登入時候該資訊也會隨之從資料庫裡讀取,但是這個場景對於像支付寶這種使用者量極大,日均訪問量極高的大型網站,這種個性化又非核心的功能都從資料庫裡讀取,那麼它對資料庫造成的壓力一定是十分巨大的,在儲存的瓶頸裡我們講了那麼多優化資料庫的手段,其核心手段有一個就是減少對資料庫價值不高的操作,而這種個性化配置跟支付寶的支付操作相比起來,價值度實在太低,因此我們最好的選擇是避免資料庫承擔過多此類的操作。
不過像上面這個場景裡的功能,它所使用的資料又不是那種可有可無的,假如資料儲存的不可靠造成資料丟失還是會造成不必要的麻煩,所以我們還是會把這些資訊做持久化儲存。此外像上面的【生活好助手】條目還是頁面的一個重要組成部分,因此像SSI那種使用html註釋指令,當指令無法正常解析,就直接返回到瀏覽器,因為是註釋,所以頁面也不會顯示它,SSI的這種做法用在上面場景肯定是不太合適的。這樣的場景在電商網站裡是十分常見的,例如一個商品頁面,頁面裡會有商品的圖片,還有商品的詳細介紹,這些內容其實都是會用持久化系統進行儲存,同時它們本身也是網頁的重要做成部分,如果碰到問題就忽略最終會造成頁面顯示錯誤。
結合上面的場景我們來討論下ESI技術了,ESI技術和SSI技術類似,其實也和jsp裡的include指令類似,它也是在頁面裡使用一個指令標籤web容器解析這個標籤後將獲取的資料替換掉這個標籤。我們來看看ESI的使用方法,我們可以在velocity裡自定義一個esi標籤,velocity裡的使用如下所示:
esiTool.setTemplate('test.vm').addQueryData('id', 100)
velocity引擎解析vm模板,最終會把vm解析成html頁面,這個時候該頁面裡使用esi標籤的地方就被轉化為:
<esi:include src="test.vm.esi?id=100" />
當頁面到了服務端web容器之前的靜態web容器(該web容器要安裝好解析esi的模組),靜態web容器就會解析這個esi標籤,靜態web容器會以test.vm.esi?id=100 作為key,到快取系統裡查詢資訊,如果查到了資訊,快取伺服器就直接返回,用返回內容替換掉esi標籤,如果快取裡沒有找到則會直接請求持久化系統,持久化系統返回資訊後,快取系統將資訊快取起來,同時也將資訊返回至靜態web容器,那麼下次使用者再訪問同樣內容就會直接從快取裡讀取了。
ESI技術和SSI很像,只不過ESI技術是和快取技術配合起來的,同時ESI標籤也不像SSI標籤那樣使用註釋的形式,因此ESI標籤是一定要被解析的,如果僅僅是快取,ESI和SSI比較起來也沒顯得那麼有優勢和特別,但是對於電商這種場景而言ESI的現實意義非常大,電商網站也是一個由使用者產生內容的網站,每一個商家的店鋪雖然我們都知道它是屬於淘寶或天貓的,但是單獨一個商家的店鋪都是個性化很強的,與其他店鋪差異很大,為了買賣商品,商家會上傳自己商品的圖片,還會使用圖片和文字描述自己的商品,單個商品頁面我們做動靜分離分析,很容易分辨出動態內容和靜態內容,但是如果一個電商平臺擁有超乎想象數量的商家,那麼每個頁面的圖片,文字和商家頁面的關係就會變得有點微妙了。由於電商網站的圖片特別多,那麼電商網站系統一般都會設計一套管理這些小圖片的分散式儲存系統,例如淘寶的TFS檔案系統,它是專門針對圖片使用的分散式檔案系統,這些檔案系統裡儲存的圖片會和商家緊密關聯,這就讓圖片本身擁有了一定的動態屬性,但是對於每個商家頁面而言,商家自己的圖片資源都是可以靜態化的,也就是說圖片的讀取是要通過商家資訊進行計算的,計算出的結果對於商家而言又是靜態的,可以被快取的。但是這個靜態資源的處理時候就變得複雜了,而這些是SSI無法完成的。
首先我們直接從檔案系統讀取圖片,效率是非常低效,因此我們還是會把它們快取在記憶體裡,但是由於不同圖片和不同商戶是相關聯,那麼對於快取查詢時候是需要一定的條件,不同商戶對自己頁面的設計方案也會有所不同,一般商戶這些資源,儲存系統肯定會按照設計模板的維度儲存,不同商家由於商品和文化的不一樣,那麼使用的模板也不一樣,因此資源返回靜態web容器前還需要一個整合過程,這樣場景下的靜態資源獲取其實是需要一定邏輯計算的,那麼這個計算一般都會在開發時候由程式碼完成,所以從上面ESI使用的例子看到,開發人員會使用velocity的esi標籤,這個標籤開發人員可以設定引數,velocity引擎最終會將這個標籤解析成靜態web容器可以解析的esi標籤,標籤裡有這樣的程式碼test.vm.esi?id=100,檔案後面會帶上引數,那麼這個引數其實是動態的,那麼這個引數也就是快取系統獲取正確資訊的規則了。這樣我們就完成了靜態資源獲取的邏輯計算,計算完畢後這些資源會在一段時間裡長期有效,因此它就演變為靜態資源,可以被快取了。ESI比SSI強大多了,同時ESI也可以完成SSI的功能,所以使用了ESI也就沒必要用SSI了。
像我們平時做web開發時候可能沒有太留心一個問題,一般的web開發裡使用的靜態資源例如圖片,css檔案,js檔案我們都會放置在一個resource包裡,如果是企業開發,這個web應用上線時候也就直接打包在web工程裡,一些網際網路網站也只不過會將這些資源放置在單獨的靜態伺服器上,我平時開發時常聽到有人說,專案裡圖片太多了,應該合併下,css檔案和js檔案也太多了也要合併下,這個多到底多多少了,幾十個檔案,幾百個檔案,這個要和社交網站,電商網站這種使用者可以產生圖片的網站比起來那就是小巫見大巫了,因為使用者能產生內容的網站靜態資源會隨著時間推移檔案規模變得異乎尋常的大,所以此類網站的靜態資源已經沒法放置在專案下,它就要求我們需要有新的手段管理這些靜態資源,並且有新的手段使用這些靜態資源,那麼像TFS檔案儲存系統出現了,快取技術出現了,最後我們在應用裡使用ESI技術把它們整合到我們網頁裡,通過這個分析我們就能明白ESI適用的業務場景了。
網站靜態化處理我們首先要按規則拆分動靜資源,拆分出來的靜態資源該如何處理就是網站靜態化處理的關鍵所在,把靜態資源處理從服務端的web應用裡剝離出來,不讓服務端的web應用參入過多的靜態資源解析,這樣就可以為服務端的web應用減少不必要的處理操作,從而達到提升服務端web應用的執行效率,接著我們就把拆分出來的靜態資源處理操作往前推移到靜態web伺服器,前兩篇文章和今天的文章我著重講解了靜態web伺服器處理靜態資源的手段,那麼這裡有個問題了,這些處理可以再往前推到瀏覽器來完成嗎?答案當然是否定的,首先瀏覽器的快取是非常不可靠的,如果使用者把瀏覽器設定為不快取任何資料的模式,那麼瀏覽器就沒法快取資料了,而使用者的行為那是根本沒法控制的,其次瀏覽器快取的資料量是有限的,如果我們要在瀏覽器進行快取也是快取最有價值快取的資料,更重要的一點,為了做好網站靜態化處理我們對網頁的動靜資源做了拆分,但是拆分出的靜態資源也並不是完全不需要進行任何邏輯處理就能使用的,例如前面講到的ESI適用的場景我們就發現,有些靜態資源的獲取還是要很多條件的參入,而這些條件是由動態資料產生的,那麼這樣的靜態資料瀏覽器是沒法做快取的,這點也說明了拆分出來的靜態化資源絕大部分還是要停留在服務端的,居然只能停留在服務端,那麼最為高效的處理這些靜態資源的地方就是CDN和靜態web容器了。所以在本系列的第一篇裡我講到網站生產部署時候最好是在服務端web應用之前放置一個靜態web容器,如果有了這樣的靜態web容器做反向代理,那麼我們就可以讓它來完成靜態資源的相關操作,而且靜態web容器還能輔助完成一些邏輯上的處理,從而彌補了CDN的不足之處。當然這麼做的好處不僅僅只有這些,第二篇文章裡我曾經討論了反向代理的好處,可能大家印象還不是很深刻,我將會在後面文章裡對反向代理做更加深入的分析。
講完了ESI的妙用後,我下面將講講本篇的主題快取了。其實單獨講快取真的沒啥太多內容,不過在網站靜態化處理裡的快取還是和儲存裡講到的分散式快取有所不同,分散式快取的資料都是儲存在記憶體裡,而網站靜態處理的快取既有儲存在記憶體裡還有儲存在硬碟上,當然儲存在記憶體裡讀取速度會更快,但是網站的讀取效率還和資源距離使用者的遠近有關係,例如瀏覽器的快取其實是把靜態內容快取在硬碟上,但是因為不需要通過網路獲取資源,因此它的讀取效率就顯得特別高了,除了這個因素外還有個因素,我們前面做動靜拆分的目的就是想拆分出靜態資源,讓這些靜態資源遠離服務端的web應用,這樣可以減少服務端不必要的壓力,從而達到提升服務端web應用處理能力,而把靜態資源放置在靜態web容器處理,它的處理靜態資源效率又會高於在服務端web應用的處理,從而也達到提升靜態資源讀取的效率。不過如果靜態資源最終只能放置在服務端,那麼這個時候我們把靜態資源存入到快取裡即記憶體裡效率肯定比在硬碟上高,所以CDN的服務節點一般都是採取將靜態資源儲存在記憶體裡,就算是服務端web應用前的靜態web容器,如果我們讓靜態資源快取在記憶體裡,效率肯定也是比在硬碟上高。
好了,今天就寫到這裡,最後祝大家生活愉快,新年快樂。
相關推薦
關於大型網站技術演進的思考(十二)--網站靜態化處理—快取(4)
上篇我補充了下SSI的知識,SSI是一個十分常見的技術,記得多年前我看到很多入口網站頁面的字尾是.shtml,那麼這就說明很多入口網站都曾經使用過SSI技術,其實現在搜狐網站也還在用shtml,如下圖所示: 由此可見SSI在網際網路的應用還是非常廣泛的。其實網際網路很多網頁如果我們按照動靜分離
關於大型網站技術演進的思考(十三)--網站靜態化處理—CSI(5)
講完了SSI,ESI,下面就要講講CSI了 ,CSI是瀏覽器端的動靜整合方案,當我文章發表後有朋友就問我,CSI技術是不是就是通過ajax來載入資料啊,我當時的回答只是說你的理解有點片面,那麼到底什麼是CSI技術了?這個其實要和動靜資源整合的角度來定義。 CSI技術其實是在頁面進行動靜分離後,將頁面
Java程式設計思想第四版第十二章學習——通過異常處理錯誤(1)
使用異常帶來的好處: 它降低了錯誤處理程式碼的複雜度。使用異常後,不需要檢查特定的錯誤並在程式中的許多地方去處理它。因為異常機制將保證能夠捕獲這個錯誤且只需在一個地方處理錯誤,即異常處理程式中。 1、基本異常 異常情形:阻止當前方法或作用域繼續執行的問
spark學習記錄(十二、Spark UDF&UDAF&開窗函式)
一、UDF&UDAF public class JavaExample { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.
關於大型網站技術演進的思考(十四)--網站靜態化處理—前後端分離—上(6)
前文講到了CSI技術,這就說明網站靜態化技術的講述已經推進到了瀏覽器端了即真正到了web前端的範疇了,而時下web前端技術的前沿之一就是前後端分離技術了,那麼在這裡網站靜態化技術和前後端分離技術產生了交集,所以今天我將討論下前後端分離技術,前後端分離技術討論完後,下一篇文章我將會以網站靜態化技術的角度回過
關於大型網站技術演進的思考(十)--網站靜態化處理—動靜整合方案(2)
上篇文章我簡要的介紹了下網站靜態化的演進過程,有朋友可能認為這些知識有點過於稀鬆平常了,而且網站靜態化的技術基點也不是那麼高深和難以理解,因此它和時下日新月異的web前端技術相比,就顯得不倫不類了。其實當我打算寫本系列的之前我個人覺得web前端有一個點是很多人都知道重要,但是有常常低估它作用的,那就是we
關於大型網站技術演進的思考(二)--儲存的瓶頸(2)
上篇裡我講到某些網站在高併發下會報出503錯誤,503錯誤的含義是指網站服務端暫時無法提供服務的含義,503還表達了網站服務端現在有問題但是以後可能會提供正常的服務,對http協議熟悉的人都知道,5開頭的響應碼錶達了服務端出現了問題,在我們開發測試時候最為常見的是500錯誤,500代表的含義是服務端程式出
關於大型網站技術演進的思考(十五)--網站靜態化處理—前後端分離—中(7)
上篇裡我講到了一種前後端分離方案,這套方案放到服務端開發人員面前比放在web前端開發人員面前或許得到的掌聲會更多,我想很多資深前端工程師看到這樣的技術方案可能會有種說不出來的矛盾心情,當我的工作逐漸走向越來越專業化的前端開發後,我就時常被這套前後端分離方案所困惑,最近我終於明白了這個困惑的本源在哪裡了,那
關於大型網站技術演進的思考(十七)--網站靜態化處理—滿足靜態化的前後端分離(9)
前後端分離的主題雖然講完了,但是前後端分離的內容並沒有結束,本篇將繼續前後端分離的問題,只不過這次前後端分離的講述將會圍繞著本系列的主題網站靜態化進行。在講本篇主題之前,我需要糾正一下前後端分離主題講述中會讓朋友們產生誤導的地方,這種誤導就是對時下流行的一些前後端分離方案(沒有使用nodejs的前後端分離
關於大型網站技術演進的思考(十六)--網站靜態化處理—前後端分離—下(8)
我第一次聽說nodejs技術大概是在2009年年末,不過我真正認真在網路上進一步瞭解nodejs還是在2010年年中,當時對nodejs的認識和我現在對nodejs的認識有著天壤的區別,開始想了解nodejs我只是為了感慨谷歌公司開發的V8引擎居然如此強大,它不僅僅可以作為chrome瀏覽器的javasc
關於大型網站技術演進的思考(十九)--網站靜態化處理—web前端優化—上(11)
對於一個網路請求的處理,是由兩個不同型別的操作共同完成,這兩個操作是CPU的計算操作和IO操作,如果我們以處理效率角度來評判這兩個操作,CPU操作效率是光速的,而IO操作就不盡然了,計算機裡的IO操作就是對儲存資料介質的操作,計算機裡有如下幾個介質可以儲存資料,它們分別是:CPU的一級快取、二級快取、記憶
關於大型網站技術演進的思考(十一)--網站靜態化處理—動靜分離策略(3)
前文裡我講到了網站靜態化的關鍵點是動靜分離,動靜分離是讓動態網站裡的動態網頁根據一定規則把不變的資源和經常變的資源區分開來,動靜資源做好了拆分以後,我們就可以根據靜態資源的特點將其做快取操作,這就是網站靜態化處理的核心思路。由此可見,網站靜態化處理的核心就是動靜分離和快取兩大方面,上篇我簡單講述了動靜整合
關於大型網站技術演進的思考(十八)--網站靜態化處理—反向代理(10)
反向代理也是一種可以幫助實現網站靜態化的重要技術,今天我就來講講反向代理這個主題。那麼首先我們要了解下什麼是反向代理。和反向代理相對應的是正向代理,正向代理也就是我們常說的代理服務,正向代理是非常常見的,例如在某些公司裡我們想使用網際網路,那麼我們就得在瀏覽器裡設定一個代理伺服器,通過代理伺服器我們才能正
關於大型網站技術演進的思考(二):儲存的瓶頸(2)
上篇裡我講到某些網站在高併發下會報出503錯誤,503錯誤的含義是指網站服務端暫時無法提供服務的含義,503還表達了網站服務端現在有問題但是以後可能會提供正常的服務,對http協議熟悉的人都知道,5開頭的響應碼錶達了服務端出現了問題,在我們開發測試時候最為常見的是5
關於大型網站技術演進的思考(五)--存儲的瓶頸(5)
做了 技術分享 表數 例子 執行 同時 設備 系統重啟 拆分 原引:http://www.cnblogs.com/sharpxiajun/p/4265853.html 上文裏我遺留了兩個問題,一個問題是數據庫做了水平拆分以後,如果我們對主鍵的設計采取一種均勻分布的策略,那麽
關於大型網站技術演進的思考(九)--網站靜態化處理--總述(1)
在儲存瓶頸的開篇我提到像hao123這樣的導航網站只要它部署的web伺服器數量足夠,它可以承載超大規模的併發訪問量,如果是一個動態的網站,特別是使用到了資料庫的網站是很難做到通過增加web伺服器數量的方式來有效的增加網站併發訪問能力的。但是現實情況是像淘寶、京東這樣的大型動態網站在承擔高併發的情況下任然能
關於大型網站技術演進的思考(六)--儲存的瓶頸(6)
在講資料庫水平拆分時候,我列出了水平拆分資料庫需要解決的兩個難題,它們分別是主鍵的設計問題和單表查詢的問題,主鍵問題前文已經做了比較詳細的講述了,但是第二個問題我沒有講述,今天我將會講講如何解決資料表被水平拆分後的單表查詢問題。 要解決資料表被水平拆分後的單表查詢問題,我們首先要回到問題的源頭,我們
關於大型網站技術演進的思考(一)--儲存的瓶頸(1)
前不久公司請來了位網際網路界的技術大牛跟我們做了一次大型網站架構的培訓,兩天12個小時資訊量非常大,知識的廣度和難度也非常大,培訓完後我很難完整理出全部聽到的知識,今天我換了個思路是回味這次培訓,這個思路就是通過本人目前的經驗和技術水平來思考下大型網站技術演進的過程。 首先我們要思考一個問題,什麼樣
關於大型網站技術演進的思考(四)--儲存的瓶頸(4)
如果資料庫需要進行水平拆分,這其實是一件很開心的事情,因為它代表公司的業務正在迅猛的增長,對於開發人員而言那就是有不盡的專案可以做,雖然會感覺很忙,但是人過的充實,心裡也踏實。 資料庫水平拆分簡單說來就是先將原資料庫裡的一張表在做垂直拆分出來放置在單獨的資料庫和單獨的表裡後更進一步的把本來是一個整體
關於大型網站技術演進的思考(七)--儲存的瓶頸(7)
本文開篇提個問題給大家,關係資料庫的瓶頸有哪些?我想有些朋友看到這個問題肯定會說出自己平時開發中碰到了一個跟資料庫有關的什麼什麼問題,然後如何解決的等等,這樣的答案沒問題,但是卻沒有代表性,如果出現了一個新的儲存瓶頸問題,你在那個場景的處理經驗可以套用在這個新問題上嗎?這個真的很難說。 其實不管什麼