Spark-Unit2-Spark互動式命令列與SparkWordCount
一、Spark互動式命令列
啟動指令碼:spark-shell
先啟動spark:./start-all.sh
本地模式啟動命令:/bin/spark-shell
叢集模式啟動命令:/bin/spark-shell --master spark://spark-1:7077 --total-executor-cores 2 --executor-memory 500mb //註釋:spark叢集模式預設使用全部的核心數,預設使用記憶體大小為1024Mb
1.用shell的叢集模式去執行一個本地wordcount程式:
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
注意:1)當使用叢集模式對本地檔案進行wordcount時,會報找不到檔案的異常,在執行前要保證在每個節點上的對應路徑有被執行的檔案(將檔案從主節點分發到從節點即可)。
2)本地模式對本地檔案進行wordcount時就不需要,因為本地模式是使用master主節點跑任務,而叢集模式是使用workers去計算。
2.用shell的叢集模式去對一個hdfs上的檔案執行wordcount:
sc.textFile("hdfs://192.168.50.186:9000/words.txt").flatMap(_.split(" ")).map((_._)).reduceByKey(_+_).collect
二、用Idea寫Spark-WordCount
1.在Idea端建立maven工程,將pom檔案所需要的配置命令程式碼貼上到pom檔案,並自動匯入相關依賴包。
2.在main資料夾中建立scala資料夾(注意:要將其轉為可用的資料夾 ”source root“)
3.建立一個object單例物件,程式碼如下:
object SparkWordCount {
def main(args:Array[String]):Unit ={
//1.定義並設定配置資訊
val conf:SparkConf = new SparkConf().setAppName("SparkWordCount").setMaster("local[2]")
//2.定義spark程式入口sparkcontext,並接收配置conf
val sc:SparkContext = new SparkContext(conf)
//3.呼叫sc載入資料、處理資料、儲存資料
sc.textFile(args(0))
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
.saveAsTextFile(args(1))
//4.關閉資源
sc.stop()
}
}
4.新增配置資訊Add Configuration
分別新增主類名:Main class、 程式引數:Program arguments

確定然後執行程式。
注意:程式產生的結果檔案有兩個,而且結果可能隨機分佈在兩個檔案中,這是由於spark的自定義分割槽造成的(後面筆記會專門總結自定義分割槽)
***將寫好的程式打包提交到spark叢集中執行:
1.在maven工程中package打包,會出現兩個jar包(大的包含依賴包環境,小的只有程式碼);
2.將大的jar包上次到叢集,執行命令:
bin/spark-submit --master spark://spark-1:7077 \
--class SparkWordCount /root/SparkWC-1.0-SNAPSHOT.jar \
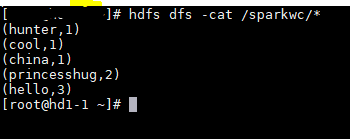
hdfs://192.168.50.186:9000/wc.txt hdfs://192.168.50.186:9000/sparkwc
3.執行完成後檢視hdfs端產生的結果檔案。