
Flink的流廣播(Broadcast State)
阿新 • • 發佈:2019-01-13
上一篇Flink的狀態管理中,我們提到了Operator state,本文介紹的廣播狀態(Broadcast State)是 Apache Flink 中支援的第三種類型的operator state。Broadcast State使得 Flink 使用者能夠以容錯、一致、可擴縮容地將來自廣播的低吞吐的事件流資料儲存下來,被廣播到某個 operator 的所有併發例項中,然後與另一條流資料連線進行計算。
廣播狀態與其他 operator state 之間有三個主要區別:
1、Map 的格式
2、有一條廣播的輸入流
3、operator 可以有多個不同名字的廣播狀態
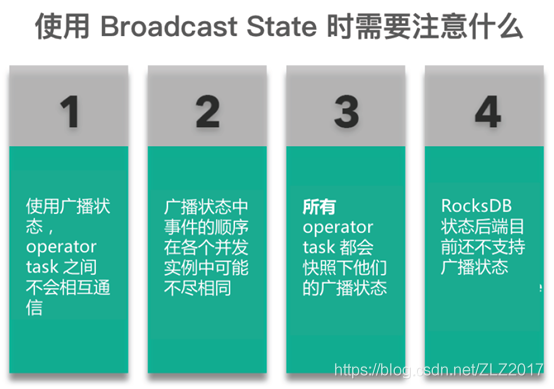
廣播狀態注意事項
Apache Flink 官方文件提供了廣播狀態的功能以及有關 API 的詳細指南。在使用廣播狀態時要記住以下4個重要事項:
- 使用廣播狀態,operator task 之間不會相互通訊
這也是為什麼(Keyed)-BroadcastProcessFunction上只有廣播的一邊可以修改廣播狀態的內容。使用者必須保證所有 operator 併發例項上對廣播狀態的修改行為都是一致的。或者說,如果不同的併發例項擁有不同的廣播狀態內容,將導致不一致的結果。 - 廣播狀態中事件的順序在各個併發例項中可能不盡相同。
雖然廣播流的元素保證了將所有元素(最終)都發給下游所有的併發例項,但是元素的到達的順序可能在併發例項之間並不相同。因此,對廣播狀態的修改不能依賴於輸入資料的順序。 - 所有 operator task 都會快照下他們的廣播狀態
在 checkpoint 時,所有的 task 都會 checkpoint 下它們的廣播狀態,並不僅僅是其中一個,即使所有 task 在廣播狀態中儲存的元素是一模一樣的。這是一個設計傾向,為了避免在恢復期間從單個檔案讀取而造成熱點。然而,隨著併發度的增加,checkpoint 的大小也會隨之增加,這裡會存在一個併發因子p的權衡。Flink保證了在恢復/擴縮容時不會出現重複資料和少資料。在以相同或更小並行度恢復時,每個 task 會讀取其對應的檢查點狀態。在已更大並行度恢復時,每個 task 讀取自己的狀態,剩餘的 task (p_newp_old)會以迴圈方式(round-robin)讀取檢查點的狀態。 - RocksDB 狀態後端目前還不支援廣播狀態
廣播狀態目前在執行時儲存在記憶體中。因為當前,RocksDB狀態後端還不適用於operator state。Flink 使用者應該相應地為其應用程式配置足夠的記憶體。
廣播狀態模式的應用
一般來說廣播狀態的主要應用場景如下:
1、動態規則:動態規則是一條事件流,要求吞吐量不能太高。例如,當一個報警規則時觸發報警資訊等。我們將這個規則廣播到計算的運算元的所有併發例項中。
2、資料豐富:例如,將使用者的詳細資訊作業廣播狀態進行廣播,對包含使用者ID的交易資料流進行資料豐富。