
Python3.5學習之旅——day2
一、模組初識
由day1的學習我們知道,Python有一個很重要的優點——具有強大的標準庫和第三方庫,這裡的“模組”指的就是存放在標準庫或者第三方庫中的可以實現某種特定的功能的“程式包”。
下面我們先來學習兩個簡單的標準庫中的模組:sys模組和os模組。
1、sys
我們練習使用一下‘sys'模組,模組名為“sys_mod2.py”
__author__ = 'Sunny Han' import sys print(sys.path)#打印出sys模組所在路徑
執行結果如下:

可以看到這段程式打印出了sys所在的路徑。
再加一段程式碼:
__author__= 'Sunny Han' import sys print(sys.path)#打印出sys模組所在路徑 print(sys.argv)#列印相對路徑
也打印出了相對路徑。如下:

也就是說,若想匯入sys模組,電腦就是在這個路徑下去尋找。其次我們要知道的是,Python的標準庫都存放在E:\\program\\python\\lib這個路徑下(硬碟的選擇因人而異,在這裡我存的是E盤),Python的第三方庫都存放在 'E:\\program\\python\\lib\\site-packages'這個路徑下。
此外,我們若是在執行‘sys_mod2.py’時,再在其後加三個引數‘1’,‘2’,‘3’,執行結果如下:
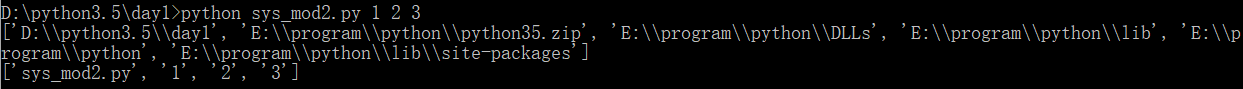
若是想只讀取三個引數中的‘2’,由上述執行結果我們可以看到‘2’為第2個引數(計算機從0開始計數),如下圖所示:
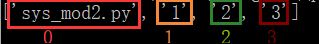
故程式碼可以改為:
__author__ = 'Sunny Han' import sys print(sys.path)#打印出sys模組所在路徑 print(sys.argv[2])#列印相對路徑
執行結果為:

2、os
os模組的作用是和本機操作繫系統進行互動,下面通過兩個例子來說明:
(1)dir功能
__author__ = 'Sunny Han' import os os.system("dir")#"dir"在Windows作業系統中的作用是開啟當前目錄下的檔案
執行結果如下:
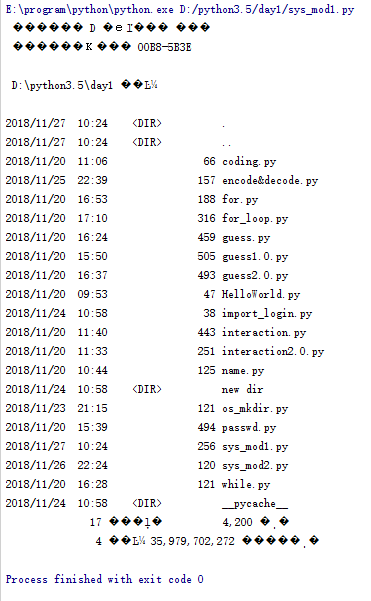
我們在這裡可以先忽略掉執行結果出現的亂碼,這是由於Windows的輸出的字元編碼和我們這裡使用的utf-8不一致導致的。我們可以看出上述結果即是“dir”的執行結果這就是os模組的作用。
接下來我們試一下是否可以將上述的輸出結果存到一個變數中去,實驗如下:
__author__ = 'Sunny Han' import os os.system("dir")#"dir"在Windows作業系統中的作用是開啟當前目錄下的檔案 cmd_res=os.system("dir") print("-->",cmd_res)#為了比較清楚的看到我們的變數值,故在變數前加“-->”來明示。
執行結果如下:
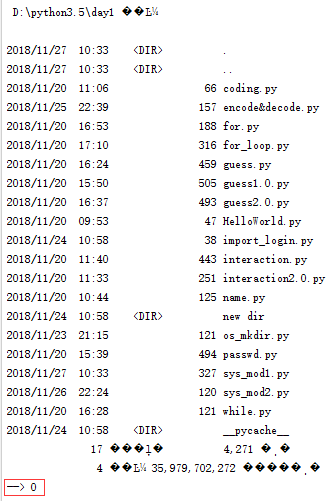
我們可以看到這次的執行結果相較上次的僅多了一個"-->”(紅框中的內容),也就是說最後變數值為0!而不是之前輸出的結果,這是為什麼呢?這是因為“os.system("dir")”這條指令只執行命令,而並不儲存結果,也就是說它輸出了就沒了,所以不能存在變數中。那如果我們想將這個輸出結果存在變數中應該怎麼做呢?請看下面的實驗:
__author__ = 'Sunny Han' import os cmd_res1=os.popen("dir") #這時列印的是記憶體物件地址,而不是我們的結果 cmd_res=os.popen("dir").read()#這裡加一個“read”就可以從上述的記憶體物件地址中將結果取出來 print("-->",cmd_res1) print(">>>",cmd_res)
執行結果如下:
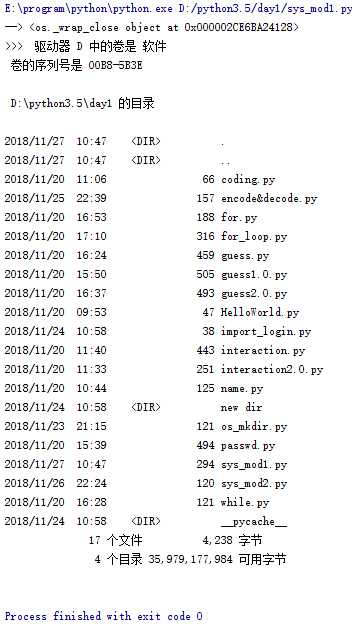
在這裡我們就將輸出的結果存入變數中了,而且也沒有之前的亂碼,全變成可以看懂的中文內容了。在這裡我們要注意一下加“read()”和不加的區別,因已在上文程式碼中解釋到,這裡不再贅述。
(2)mkdir功能
我們要是想在當前目錄下建立一個新的目錄,程式碼如下:
__author__ = 'Sunny Han' import os os.mkdir("new dir") #在當前目錄下建立一個新的名為“new dir"的目錄
執行結果如下:

就在當前的‘day1’目錄下建立了一個名為'new dir'的新目錄。
3、自己寫一個模組
我們可以練習自己寫一個模組,以使用者輸入使用者名稱和密碼為例,檔名為‘login.py’。
程式碼如下:
__author__ = 'Sunny Han' import getpass username='han' password='123456' user=input('請輸入使用者名稱:') pwd=getpass.getpass('請輸入密碼:') if user==username and pwd==password: print("welcome user %s login..."%user) else: print("invalid username or password!")
然後再寫一個指令碼,直接呼叫‘login.py’即可,檔名為‘import_login.py’如下:
__author__ = 'Sunny Han' import login
執行結果與‘login.py’的結果一樣,都為使用者登入介面。
但是,在這裡我們尤其要注意的是,如果我們所寫的模組檔案(例如‘login.py’)與呼叫此模組的檔案不在同一目錄下,那麼將會出現報錯的情況,即無法呼叫此模組,所以我們要求這兩個檔案應該放在同一目錄下。這是因為電腦若想呼叫某模組,首先會在當前目錄下尋找該模組,若在當前目錄下找不到該模組,則在全域性環境變數下尋找。
若我們想呼叫某不在同一目錄下的模組,我們有兩種方法:
(1)將此模組copy到我們之前提到過的用於存放第三方庫的site-package檔案中,這樣就可呼叫成功。
(2)修改環境變數(之後再詳細講解)。
二、.pyc是什麼?
1. Python是一門解釋型語言?
我初學Python時,聽到的關於Python的第一句話就是,Python是一門解釋性語言,我就這樣一直相信下去,直到發現了*.pyc檔案的存在。如果是解釋型語言,那麼生成的*.pyc檔案是什麼呢?c應該是compiled的縮寫才對啊!
為了防止其他學習Python的人也被這句話誤解,那麼我們就在文中來澄清下這個問題,並且把一些基礎概念給理清。
2. 解釋型語言和編譯型語言
計算機是不能夠識別高階語言的,所以當我們執行一個高階語言程式的時候,就需要一個“翻譯機”來從事把高階語言轉變成計算機能讀懂的機器語言的過程。這個過程分成兩類,第一種是編譯,第二種是解釋。
編譯型語言在程式執行之前,先會通過編譯器對程式執行一個編譯的過程,把程式轉變成機器語言。執行時就不需要翻譯,而直接執行就可以了。最典型的例子就是C語言。
解釋型語言就沒有這個編譯的過程,而是在程式執行的時候,通過直譯器對程式逐行作出解釋,然後直接執行,最典型的例子是Ruby。
通過以上的例子,我們可以來總結一下解釋型語言和編譯型語言的優缺點,因為編譯型語言在程式執行之前就已經對程式做出了“翻譯”,所以在執行時就少掉了“翻譯”的過程,所以效率比較高。但是我們也不能一概而論,一些解釋型語言也可以通過直譯器的優化來在對程式做出翻譯時對整個程式做出優化,從而在效率上超過編譯型語言。
此外,隨著Java等基於虛擬機器的語言的興起,我們又不能把語言純粹地分成解釋型和編譯型這兩種。
用Java來舉例,Java首先是通過編譯器編譯成位元組碼檔案,然後在執行時通過直譯器給解釋成機器檔案。所以我們說Java是一種先編譯後解釋的語言。
3. Python到底是什麼
其實Python和Java/C#一樣,也是一門基於虛擬機器的語言,我們先來從表面上簡單地瞭解一下Python程式的執行過程吧。
當我們在命令列中輸入python hello.py時,其實是激活了Python的“直譯器”,告訴“直譯器”:你要開始工作了。可是在“解釋”之前,其實執行的第一項工作和Java一樣,是編譯。
熟悉Java的同學可以想一下我們在命令列中如何執行一個Java的程式:
javac hello.java
java hello
只是我們在用Eclipse之類的IDE時,將這兩部給融合成了一部而已。其實Python也一樣,當我們執行python hello.py時,他也一樣執行了這麼一個過程,所以我們應該這樣來描述Python,Python是一門先編譯後解釋的語言。
4. 簡述Python的執行過程
在說這個問題之前,我們先來說兩個概念,PyCodeObject和pyc檔案。
我們在硬碟上看到的pyc自然不必多說,而其實PyCodeObject則是Python編譯器真正編譯成的結果。我們先簡單知道就可以了,繼續向下看。
當python程式執行時,編譯的結果則是儲存在位於記憶體中的PyCodeObject中,當Python程式執行結束時,Python直譯器則將PyCodeObject寫回到pyc檔案中。
當python程式第二次執行時,首先程式會在硬碟中尋找pyc檔案,如果找到,則直接載入,否則就重複上面的過程。
所以我們應該這樣來定位PyCodeObject和pyc檔案,我們說pyc檔案其實是PyCodeObject的一種持久化儲存方式。
三、Python的資料型別
1、數字
數字分為整型、浮點型和複數。
(1)首先關於整型我們這裡要說明的一點是,在Python2中,整型分為int和long兩種形式,但是在Python3中則沒有了long這個概念,即不論整數值有多大都為int型別,如下:

可以看出不論值多大都為int型別。
(2)其次關於浮點型,浮點數是屬於有理數中某特定子集的數的數字表示,在計算機中用以近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次冪得到,這種表示方法類似於基數為10的科學計數法。例如1.9E13表示1.9×10^13。
(3)複數是指能寫成如下形式的數a+bj,這裡a和b是實數,j是虛數單位(即-1開根)。在複數a+bj中,a稱為複數的實部,b稱為複數的虛部,j稱為虛數單位。當虛部等於零時,這個複數就是實數;當虛部不等於零時,這個複數稱為虛數。
2、布林值
真或假 1 或 03、字串
字串一般放在兩個雙引號或者單引號之間,這裡我們要注意雙引號和單引號同時使用時的規範問題。如下:
__author__ = 'Sunny Han' print("my name is "jake"")
如果像這樣使用雙引號的話會造成混亂,機器不能識別出這個輸出的字串到底是哪個,故會報錯,修改如下:
__author__ = 'Sunny Han' print("my name is 'jake'")
這樣就可以執行了。
此外再簡單介紹一下字串格式化輸出,程式碼如下:
__author__ = 'Sunny Han' name='jake' print("my name is %s"%name)#注意這裡的%name應放在括號內,自己之前總是放在括號外,以此提醒大家。
PS: 字串是 %s;整數 %d;浮點數%f
字串常用功能:- 移除空白
- 分割
- 長度
- 索引
- 切片
四、三元運算
三元運算是一個相對更為簡便的寫法,舉例如下:
a,b,c=1,2,3 d=a if a>b else c
即如果a>b,則d=a=1,否則d=c=5,那麼這裡我們可以知道d=5。上述程式碼可以換成if-else語句,但它比if-else語句更為簡潔。
三元運算格式:result=值1 if 條件 else 值2.
五、進位制
這裡我們介紹四種計算機學習中常用到的進位制:二進位制、八進位制、十進位制和十六進位制。
- 二進位制,01
- 八進位制,01234567
- 十進位制,0123456789
- 十六進位制,0123456789ABCDEF
這幾種進位制間的相互轉換讀者可以自行百度,這裡不再贅述,不過我仍要說明強調一點的是通常三位二進位制數對應一位八進位制數,四位二進位制數對應一位十六進位制數。
下面是關於十六進位制在計算機中的應用的簡單介紹:
計算機記憶體地址和為什麼用16進位制? 1、計算機硬體是0101二進位制的,16進位制剛好是2的倍數,更容易表達一個命令或者資料。十六進位制更簡短,因為換算的時候一位16進位制數可以頂4位2進位制數,也就是一個位元組(8位進位制可以用兩個16進製表示)。 2、最早規定ASCII字符集採用的就是8bit(後期擴充套件了,但是基礎單位還是8bit),8bit用2個16進位制直接就能表達出來,不管閱讀還是儲存都比其他進位制要方便。 3、計算機中CPU運算也是遵照ASCII字符集,以16、32、64的這樣的方式在發展,因此資料交換的時候16進位制也顯得更好。 4、為了統一規範,CPU、記憶體、硬碟我們看到都是採用的16進位制計算。 16進位制用在哪裡 1、網路程式設計,資料交換的時候需要對位元組進行解析都是一個byte一個byte的處理,1個byte可以用0xFF兩個16進位制來表達。通過網路抓包,可以看到資料是通過16進位制傳輸的。 2、資料儲存,儲存到硬體中是0101的方式,儲存到系統中的表達方式都是byte方式。 3、一些常用值的定義,比如:我們經常用到的html中color表達,就是用的16進位制方式,4個16進位制位可以表達好幾百萬的顏色資訊。
六、byte型別
Python 3最重要的新特性大概要算是對文字和二進位制資料作了更為清晰的區分。文字總是Unicode,由str型別表示,二進位制資料則由bytes型別表示。Python 3不會以任意隱式的方式混用str和bytes,正是這使得兩者的區分特別清晰。你不能拼接字串和位元組包,也無法在位元組包裡搜尋字串(反之亦然),也不能將字串傳入引數為位元組包的函式(反之亦然)。這是件好事。
不管怎樣,字串和位元組包之間的界線是必然的,下面的圖解非常重要,務請牢記於心:
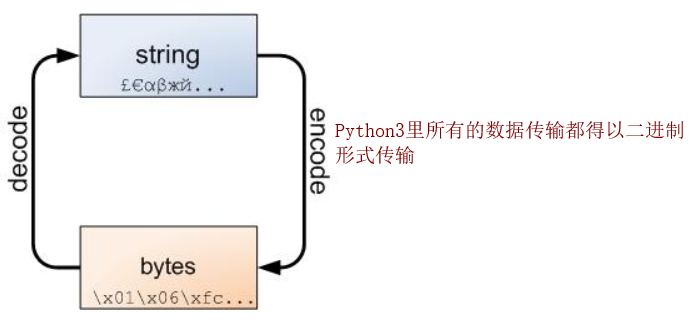
下面以一個例子來說明:
__author__ = 'Sunny Han' msg='我愛中國' print(msg) print (msg.encode(encoding='utf-8')) print (msg.encode(encoding='utf-8').decode(encoding='utf-8'))
執行結果為:

這個問題要這麼來看:字串是文字的抽象表示。字串由字元組成,字元則是與任何特定二進位制表示無關的抽象實體。在操作字串時,我們生活在幸福的無知之中。我們可以對字串進行分割和分片,可以拼接和搜尋字串。我們並不關心它們內部是怎麼表示的,字串裡的每個字元要用幾個位元組儲存。只有在將字串編碼成位元組包(例如,為了在通道上傳送它們)或從位元組包解碼字串(反向操作)時,我們才會開始關注這點。
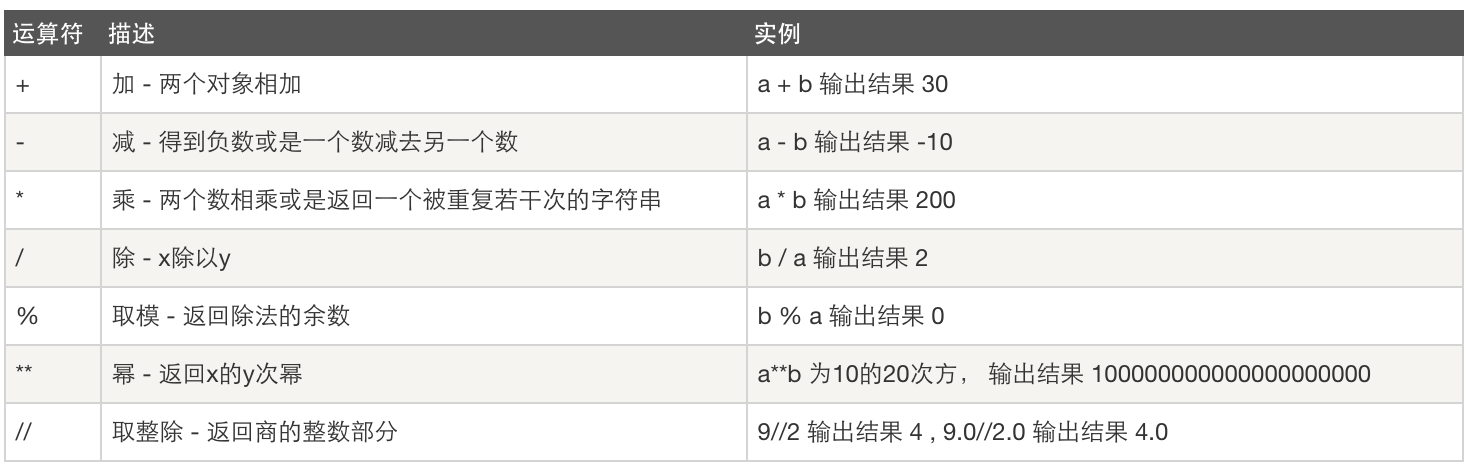
七、資料運算
算數運算:
比較運算:

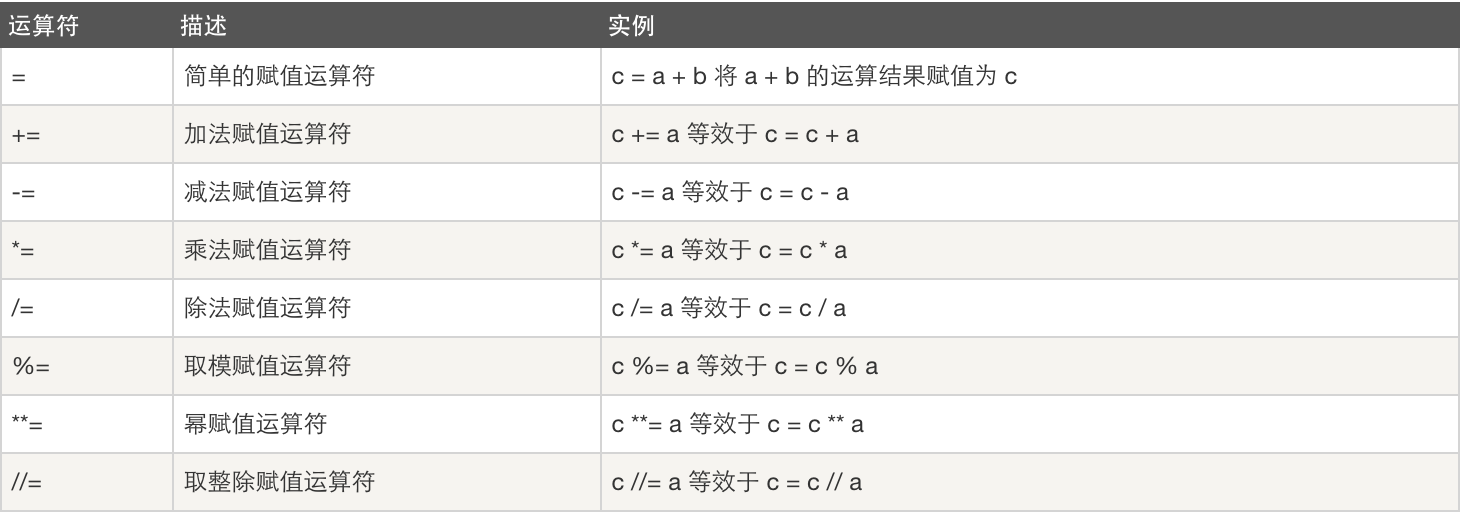
賦值運算:
邏輯運算:

成員運算:

身份運算:

位運算:

八、列表
1、列表的建立和讀取
在這裡我們建立一個包含城市名字的列表,並以此為例學習如何進行讀取,檔名為“name.py”。
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] print(names)
這樣就建立了一個包含五個城市名字的列表。執行結果如下:

接下來嘗試將其中的幾個元素提取出來,程式碼如下:
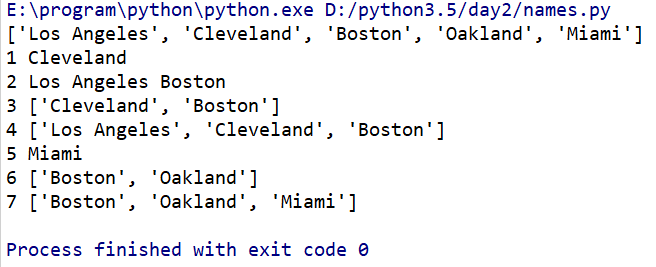
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] print(names) print('1',names[1]) #將列表中第二個元素(Cleveland)提取出來,需要注意的是,列表元素的計數從0開始而不是1. print('2',names[0],names[2])#將列表中的第一個和第三個個元素一併提取出來。 print('3',names[1:3])#將列表中的從第二個到第四個元素(但取不到第四個,即顧頭不顧尾)讀取出來 print('4',names[:3])#相當於print('4',names[0:3]),即這裡的0可以省略 print('5',names[-1])#將列表中最後一個元素提取出來 print('6',names[-3:-1])#由顧頭不顧尾原則,我們可以知道這裡取得是“-3”和“-2”位置上的元素 #這裡也要注意不能寫成[-1:-3],也即冒號左邊的數要比右邊的小 print('7',names[-3:])#取出列表的最後三個元素
上面的註釋已經介紹了相關的用法,這裡不再贅述。
程式碼執行如下:
2、列表的基本操作
(1)增加列表元素
在列表末尾加一個元素,程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] names.append('Chicago')#在列表的末尾位置加一行元素"Chicago" print(names)
程式碼執行結果如下:

若要在列表任意位置加元素,示例程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami',]
names.append('Chicago')#在列表的末尾位置加一行元素"Chicago"
names.insert(2,'Orlando')#將'Orlando'插入到位置2上
print(names)
程式碼執行結果如下:

(2)修改列表元素
若想修改列表中部分元素,舉例如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] names[3]='The Golden State'#將列表中位置序號為3的元素改為'The Golden State' print(names)
程式碼執行結果如下:

可以看到我們將原列表中的位置序號為3的元素(Oakland)改為了‘The Golden State’。
(3)刪除列表元素
在這裡我們介紹三種刪除列表元素的方法,程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] names.remove('Cleveland')#刪除列表中的元素‘Cleveland’ print(names)
在這裡我使用remove來將列表中某元素移除,注意這裡的括號裡面寫的是元素名稱,而不是元素位置序號。
程式碼執行結果如下:

接下來介紹第二種方法,程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] del names[2]#刪除處在位置2上的元素 print(names)
在這裡我使用的是del,可直接將位置2上的元素刪除。
程式碼執行結果如下:

最後介紹第三種方法,程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] names.pop()#刪除列表中最後一個元素 print(names)
在這裡我們使用pop可直接刪除列表中的最後一個元素,當然也可以在括號中寫想要刪除的元素的位置序號。
程式碼執行結果如下:


(4)查詢列表元素序號
若有一個元素數量龐大的列表,元素的序號不能很方便快捷的看出來時怎麼辦呢,這裡我們為大家介紹一種方法,程式碼如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Miami'] print(names.index('Boston'))
執行結果如下:

這裡我們的列表數目較少,體會不到太大的優勢,但若列表元素數目很大的話用這個方法會很快捷。我們要注意的是在查詢時要注意別寫錯元素內容,不然會提示列表(list)內沒有此元素。
(5)統計元素個數
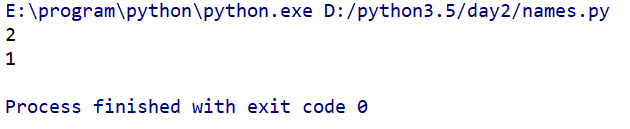
若想統計列表中某元素的個數,程式碼實現如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] print(names.count('Boston'))#統計元素‘Boston’的個數 print(names.count('Miami'))#統計元素‘Miami’的個數
程式碼執行結果如下:
(6)列表元素順序翻轉
若想將列表內的元素倒序列印,程式碼實現如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] names.reverse() print(names)
程式碼執行結果如下:

(7)列表拓展
若想將列表擴充套件一下,將另一個列表的元素放進此列表,舉例如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] name2=['Nanjing','Seatle'] names.extend(name2)#將列表‘name2’的元素放進列表‘names'中 print(names)
程式碼執行如下:

(8)列表列印
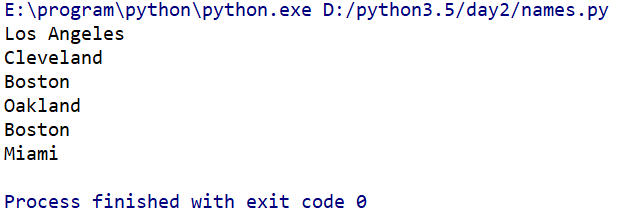
- 若想將列表逐個迴圈打印出來,我們可以使用for迴圈:
names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] for i in names: print(i)
程式碼執行結果如下:
- 若想每隔幾個元素列印一個,舉例如下:
names=['Los Angeles','Cleveland','Boston','Oakland','Orlando','Miami'] print(names[0:-1:2])#從第一個(0)元素每隔一個列印到最後一個(-1)元素 print(names[::2])#相當於print(names[0:-1:2]),也就是說0和-1可以省略
程式碼執行結果如下:

3、copy的用法
copy的使用在列表中極為重要,在這裡為大家詳細的講解一下。
首先,copy的一個最簡單的作用就是複製列表,即將一個列表複製到另一個列表,舉例如下:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] name2=names.copy() print(names) print(name2)
程式碼執行結果如下:

可以看到列表name2是從列表names複製過來的。
但是,這裡有一個問題,假入我們把初始列表names中的元素稍加改動,copy的列表name2會不會也做出相應的變化呢?我們一試便知:
__author__ = 'Sunny Han' names=['Los Angeles','Cleveland','Boston','Oakland','Boston','Miami'] name2=names.copy() names[1]='Nanjing'#將列表names中的第二個元素改為‘Nanjing’ print(names) print(name2)
程式碼執行結果如下:

根據上面的結果我們可以看到,若改變names列表中的某個元素,copy得到的列表name2並不會做出相應的改變,我們稱之為“淺copy”。
接下來我們再來看一個有趣的例子:假如說初始列表names中有一個子列表,若我們改動子列表中的元素時,情況會不會和之前一樣呢,示例如下:
names=['Los Angeles',['Utah','Boston'],'Oakland','Miami'] name2=names.copy() print('->',names) print('->',name2) names[0]='Nanjing'#將列表names中的第一個元素改為“Nanjing” names[1][0]='Phoenix'#將列表names中的子列表的第一個元素改為“Phoenix” print(names) print(name2)
程式碼執行結果如下:

我們可以看到若改動列表names中子列表元素內容時,copy的列表name2也會做出相應的改變,這是為什麼呢?
這是因為第一層列表中的第二層列表(子列表)['Utah','Boston'] 存的只是一個列表指標,而並不是元素本身,當使用copy指令時,複製的是第二層列表的記憶體地址,所以,若第一層做出改變,第二層也會根據記憶體地址去察覺到相應的變化,並進一步做出改動。同樣的,若在name2中改動第二層列表中的元素,則names中的元素也會做出相應改變。
那麼如果說我們想避免出現 這種子列表變化,copy列表也會相應變化的情況發生,我們應該怎麼辦呢?
接下來我為大家介紹一種方法,示例如下:
import copy names=['Los Angeles',['Utah','Boston'],'Oakland','Miami'] name2=copy.deepcopy(names) print('->',names) print('->',name2) names[0]='Nanjing'#將列表names中的第一個元素改為“Nanjing” names[1][0]='Phoenix'#將列表names中的子列表的第一個元素改為“Phoenix” print(names) print(name2)
程式碼執行結果如下:

也就是說,我們通過使用deepcopy就可以實現‘只打印一次’的功能。
九、元組
元組與列表類似,不同的是列表可以修改列表內容,但元組不能修改內容,舉個簡單的元組的例子,如下:
names=('Los Angeles','Cleveland','Boston','Oakland','Orlando','Miami') print(names)
程式碼執行結果如下:

在這裡要注意,元組使用小括號()括起來的,列表是用方括號[ ] 括起來的。
除此之外,元組的使用和列表類似,在這裡就不作詳細的介紹了。
十、課後練習
在本節我們嘗試編寫一個購物車程式,主要有以下幾個要求:
- 啟動程式後,讓使用者輸入工資,然後列印商品列表。
- 允許使用者根據商品列表編號購買商品。
- 使用者選擇商品後,檢測餘額是否足夠,夠就直接扣款,不夠就提醒。
- 可隨時退出,退出時列印已購買的商品和餘額。
在這之前,我們先向大家介紹一種可以直接將列表元素和下標一起打印出來的方法:enumerate
舉例如下:
__author__ = 'Sunny Han' a=[2,3,4] for i in enumerate(a): print(i)
程式碼執行結果如下:
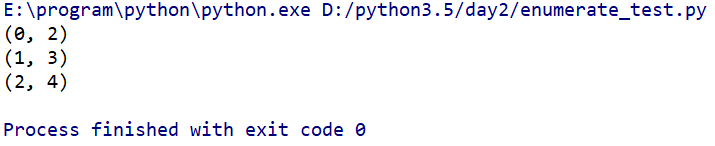
我們可以看到,這裡直接將列表中的元素及其下標一同列印了出來。這對我們寫購物車程式很有幫助。
接下來我們練習寫購物車程式,程式碼如下:
__author__ = 'Sunny Han' product_list=[ ('Iphone',5800),('Mac Pro',9800),('Bike',800),('Watch',10600),('coffee',31) ] shopping_list=[] salary=input('input your salary:')#輸入工資 if salary.isdigit(): salary=int(salary)#將salary轉為整型變數 while True: for index,item in enumerate(product_list): print(index,item) user_choice=input('請問要買什麼商品:>>>:') if user_choice.isdigit(): user_choice=int(user_choice) if user_choice>len(product_list)-1: print('商品 [%s] 不存在!'%user_choice) else: p_item=product_list[user_choice] #將使用者選擇的商品資訊值賦給p_item if p_item[1]<=salary: #如果餘額大於商品價格,則買得起 salary-=p_item[1] #salary=salary-p_item[1],即自動扣款 shopping_list.append(p_item) #將所購商品的資訊加進空列表shopping_list print('已將 %s 放入您的購物車,您的餘額為 %s'%(p_item,salary)) else: print('餘額不足。') elif user_choice=='q': #若使用者想要退出系統,輸入“q" print('----購物車----') for p in shopping_list: print(p) print('您的餘額為:',salary) exit() #注意這裡要有一個退出的部分,否則使用者輸入"q"後會一直停留在商品列表介面 else: print('請輸入商品編號!') else: print('格式錯誤!')
程式碼寫好後,我們嘗試著執行一下,結果如下:

第一步會出現讓我們輸入自己工資的介面,假設輸入9999,如下:
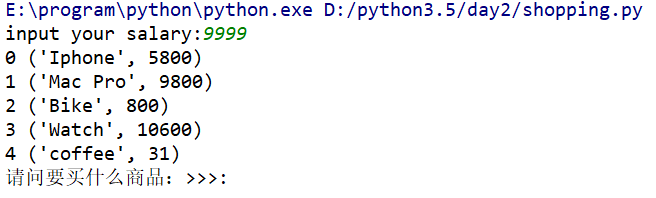
輸入後會顯示商品列表並詢問自己想要購買什麼商品,假設要購買IPhone,我們輸入商品的下標0,執行如下:
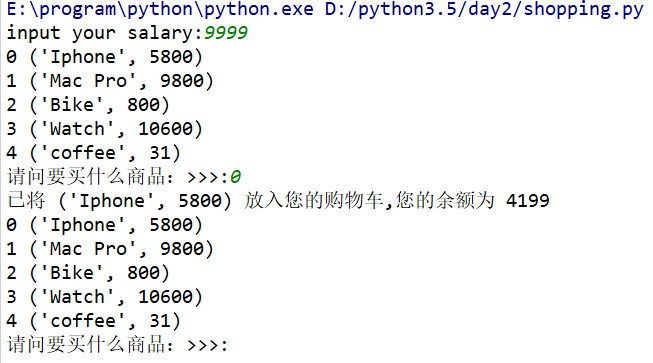
我們可以看到介面會給出我們的餘額和已購買商品資訊,假如再買一杯咖啡,執行如下:

我們可以看到與之前類似的介面,只不過餘額扣除了咖啡的價格,假如我們想買一個“Mac Pro”,我們看看會發生什麼情況:

我們可以看到會提示餘額不足,這時假若我們想退出購物系統,就輸入“q”,執行如下 :
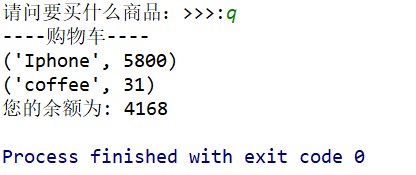
我們可以看到介面會顯示我們已購買的商品資訊和餘額。
以上就是我們本節課的練習內容。