
訓練一次得到多個模型做整合的方法
阿新 • • 發佈:2019-01-13
參考論文
SNAPSHOT ENSEMBLES: TRAIN 1, GET M FOR FREE
解決的問題
多個分類器整合可以獲得超過單個分類器的效果,但整合分類器就要求有多個分類器,在訓練速度和測試速度方面不佔優勢。本文提出的方法可以提高整合學習的訓練速度,通過一次訓練,獲得多個分類器,解決了整合學習訓練速度慢的問題。
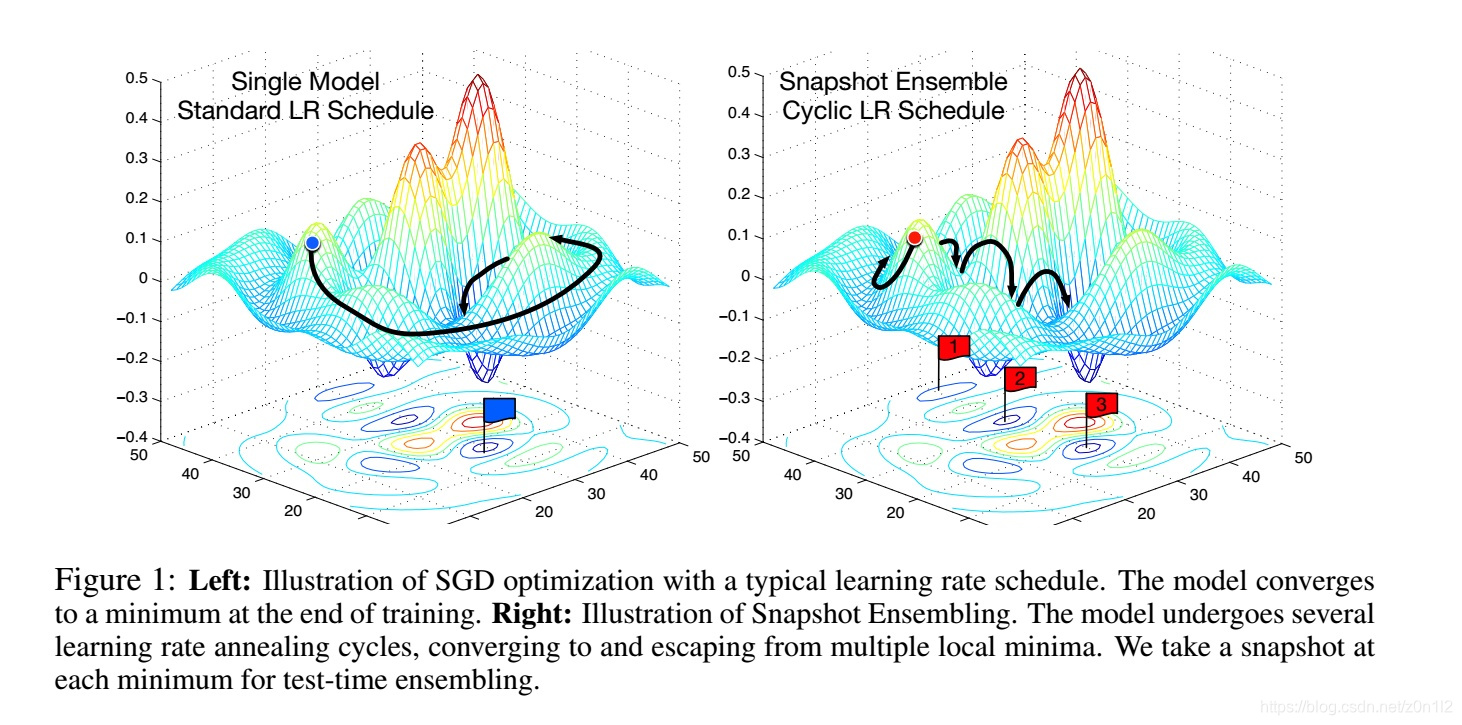
解決方法
深度學習訓練過程中,只有經歷足夠長的epoch後,test loss才會隨著lr的降低而降低,這說明loss空間中存在的區域性最小值點是穩定的,這些區域性最小值點的模型從不同方面描述了特徵空間,可以用於整合學習。本文提出的方法主要有以下兩點
-
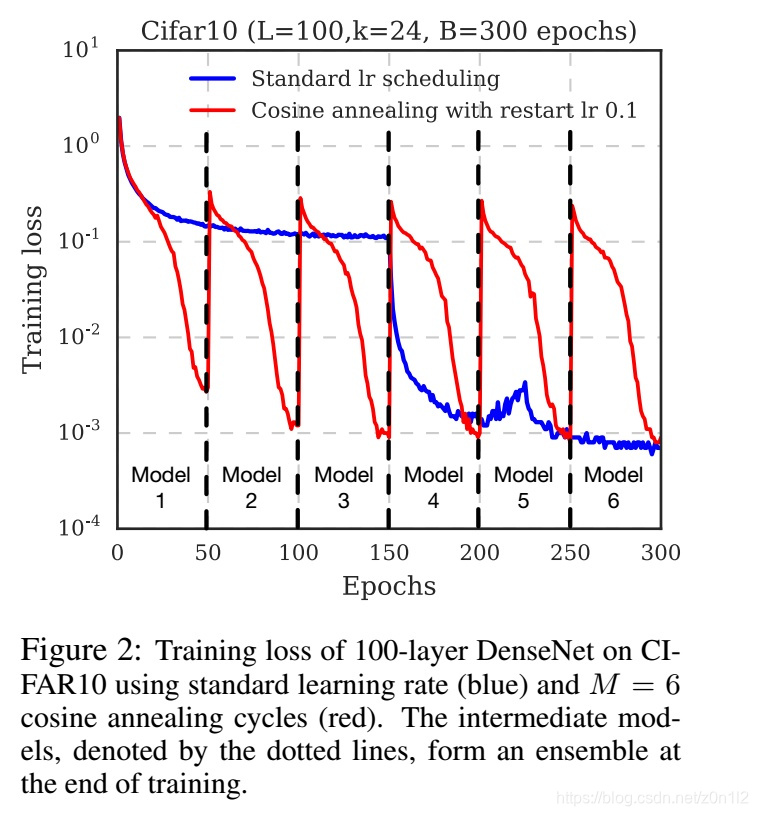
週期性學習率策略
和常規學習率策略不同,本文把整個訓練過程平均劃分成M個階段,每個階段內學習率lr都從一個固定初始值開始,逐步降低。每個階段結束後都保留一個snapshot,訓練結束後一共獲得M個snapshot,從後面抽取m個組成整合分類器。如此在一次訓練中,獲得M個模型,訓練速度和常規訓練方法一樣。
-
利用前一階段的結果初始化當前階段模型
對於簡單的模型而言,這一個步驟沒那麼重要,沒有這一步也可以得到不錯的結果。對於複雜的模型,這一步十分重要,因為複雜的模型需要較多的epoch才可以收斂到穩定的區域性極小值點,除非增加每個階段的epoch(同時也增大了整個訓練時間),否則很難得到較好的結果
實驗分析
對比實驗
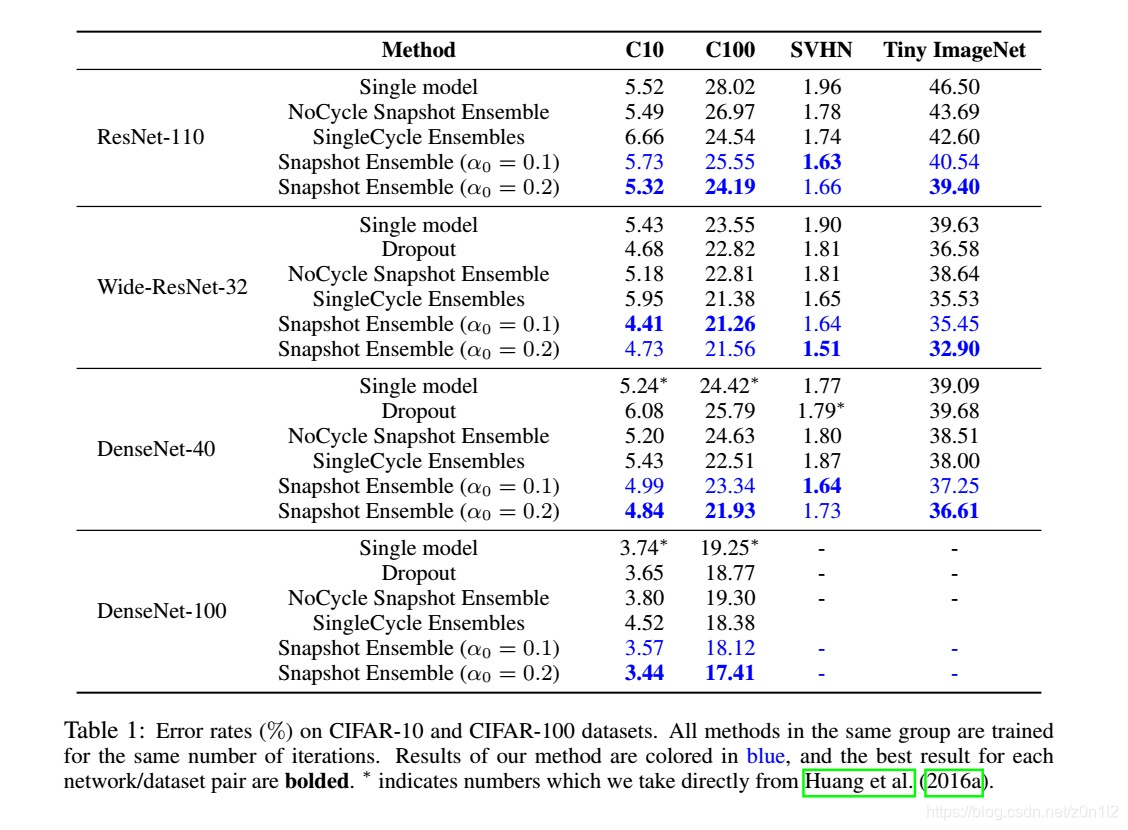
- single model: 採用常規lr更新策略,比如每經過1/4訓練epoch,學習速率降低一個數量級
- NoCycle Snapshot Ensemble:不使用週期性學習率更新策略,但依然每個相同epoch抽取一個模型,最後做整合
- SingleCycle Ensembles:採用週期性學習率更新策略,但是每個階段模型採用隨機初始化,而不是採用前一個階段的訓練結果,這種方式對於簡單的模型也可以產生不錯的結果,畢竟其遍歷了更大的引數空間。但如果模型複雜,則該方法效果變差。
整合需要的模型數量
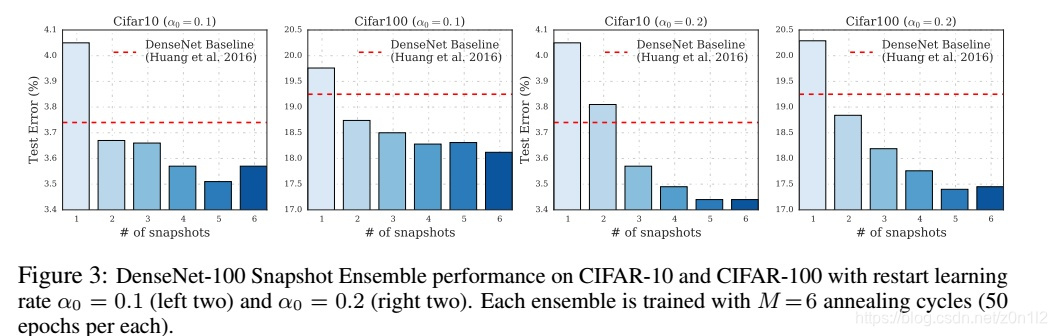
採用本文方法獲得的最後一個階段的模型的效能是低於常規訓練方法得到模型的,但是兩個snapshot整合後test loss就降低到baseline之下

一般隨著整合模型數量的提升,test loss會逐步降低(不一定成立,只是一個大的趨勢),但整合多個模型會降低預測速度
和標準整合學習的比較
和標準整合學習(採用不同初始化引數,使用常規學習率更新策略,完整訓練出多個模型做整合)對比,本文的方法效果是沒有標準整合學習好的,當然本文中的方法的訓練速度要快很多