
Elasticsearch實現原理分析-1
介紹
本文是分析Elasticsearch系列文章中的一篇,是一個譯文。共有三篇,每篇講解部分Elasticsearch的實現原理。
在翻譯的過程中,也需要檢視對應部分的原始碼,來加深對實現原理的理解。但這裡並沒有對原始碼進行分析,原始碼的分析放到後面的系列文章進行介紹。
本文介紹了Elasticsearch的以下原理:
- 是Master/Slave架構,還是Master-less架構?
- 儲存模型是什麼?
- 寫入操作是如何工作的?
- 讀操作是如何工作的?
- 搜尋結果如何相關?
Elasticsearch介紹
Elasticsearch的index
Elasticsearch的索引(index)是用於組織資料的邏輯名稱空間(如資料庫)。Elasticsearch的索引有一個或多個分片(shard)(預設為5)。分片是實際儲存資料的Lucene索引,它本身就是一個搜尋引擎。每個分片可以有零個或多個副本(replicas)(預設為1)。Elasticsearch索引還具有“型別”(如資料庫中的表),允許您在索引中對資料進行邏輯分割槽。Elasticsearch索引中給定“型別”中的所有文件(documents)具有相同的屬性(如表的模式)。

圖a顯示了一個由三個主分片組成的Elasticsearch叢集,每個主分片分別有一個副本。所有這些分片一起形成一個Elasticsearch索引,每個分片是Lucene索引本身。
圖b演示了Elasticsearch索引,分片,Lucene索引和文件(document)之間的邏輯關係。
類比關係資料庫術語
- Elasticsearch Index ~ Database
- Types ~ Tables
- Mapping ~ Schema
Elasticsearch叢集的節點型別
Elasticsearch的一個例項是一個節點,一組節點形成一個叢集。Elasticsearch叢集中的節點可以通過三種不同的方式進行配置:
Master節點
- Master節點控制Elasticsearch叢集,並負責在叢集範圍內建立/刪除索引,跟蹤哪些節點是叢集的一部分,並將分片分配給這些節點。主節點一次處理一個叢集狀態,並將狀態廣播到所有其他節點,這些節點需要響應並確認主節點的資訊。
- 在elasticsearch.yml中,將nodes.master屬性設定為true(預設),可以將節點配置為有資格成為主節點的節點。
- 對於大型生產叢集,建議擁有一個專用主節點來控制叢集,並且不服務任何使用者請求。
Data節點
- 資料節點用來儲存資料和倒排索引。預設情況下,每個節點都配置為一個data節點,並且在elasticsearch.yml中將屬性node.data設定為true。如果您想要一個專用的master節點,那麼將node.data屬性更改為false。
Client節點
如果將node.master和node.data設定為false,則將節點配置為客戶端節點,並充當負載平衡器,將傳入的請求路由到叢集中的不同節點。
若你連線的是作為客戶端的節點,該節點稱為協調節點(coordinating node)。協調節點將客戶機請求路由到叢集中對應分片所在的節點。對於讀取請求,協調節點每次選擇不同的分片來提供請求以平衡負載。
在我們開始審查傳送到協調節點的CRUD請求如何通過叢集傳播並由引擎執行之前,讓我們看看Elasticsearch如何在內部儲存資料,以低延遲為全文搜尋提供結果。
儲存模型
Elasticsearch使用Apache Lucene,它是由Java編寫的全文搜尋庫,由Doug Cutting(Apache Hadoop的建立者)內部開發,它使用稱為倒排索引的資料結構,用於提供低延遲搜尋結果。
文件(document)是Elasticsearch中的資料單位,並通過對文件中的術語進行標記來建立倒排索引,建立所有唯一術語的排序列表,並將文件列表與可以找到該詞的位置相關聯。
它非常類似於一本書背面的索引,其中包含書中的所有獨特的單詞和可以找到該單詞的頁面列表。當我們說一個文件被索引時,我們引用倒排索引。我們來看看下面兩個文件的倒排索引如何看待:

如果我們想要找到包含術語“insight”的文件,我們可以掃描倒排的索引(在哪裡排序),找到“insight”這個詞,並返回包含這個單詞的文件ID,這在這種情況下將是文件1和Doc 2號檔案。
為了提高可搜尋性(例如,為小寫字母和小寫字提供相同的結果),首先分析文件並對其進行索引。
分析由兩部分組成:
- 將句子標記成單詞
- 將單詞規範化為標準表單
預設情況下,Elasticsearch使用標準分析器 - 標準標記器(Standard tokenizer),用於在單詞邊界上分割單詞
- 小寫令牌過濾器(Lowercase token filter)將單詞轉換為小寫
還有許多其他分析儀可用,您可以在文件中閱讀它們。
注意:標準分析儀也使用停止令牌過濾器,但預設情況下禁用。
實現原理分析
write(寫)/create(建立)操作實現原理
當您向協調節點發送請求以索引新文件時,將執行以下操作:
所有在Elasticsearch叢集中的節點都包含:有關哪個分片存在於哪個節點上的元資料。協調節點(coordinating node)使用文件ID(預設)將文件路由到對應的分片。Elasticsearch將文件ID以murmur3作為雜湊函式進行雜湊,並通過索引中的主分片數量進行取模運算,以確定文件應被索引到哪個分片。
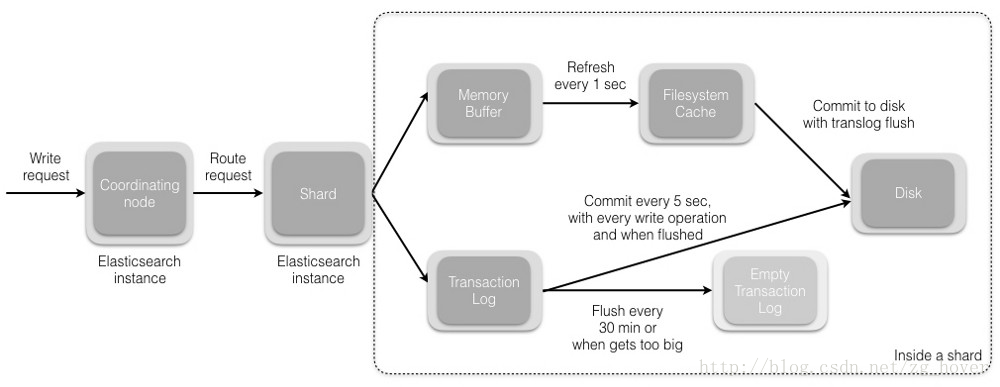
shard = hash(document_id) % (num_of_primary_shards)當節點接收到來自協調節點的請求時,請求被寫入到translog(我們將在後續的post中間講解translog),並將該文件新增到記憶體緩衝區。如果請求在主分片上成功,則請求將並行傳送到副本分片。只有在所有主分片和副本分片上的translog被fsync’ed後,客戶端才會收到該請求成功的確認。
- 記憶體緩衝區以固定的間隔重新整理(預設為1秒),並將內容寫入檔案系統快取中的新段。此分段的內容更尚未被fsync’ed(未被寫入檔案系統),分段是開啟的,內容可用於搜尋。
- translog被清空,並且檔案系統快取每隔30分鐘進行一次fsync,或者當translog變得太大時進行一次fsync。這個過程在Elasticsearch中稱為flush。在重新整理過程中,記憶體緩衝區被清除,內容被寫入新的檔案分段(segment)。當檔案分段被fsync’ed並重新整理到磁碟,會建立一個新的提交點(其實就是會更新檔案偏移量,檔案系統會自動做這個操作)。舊的translog被刪除,一個新的開始。
- 下圖顯示了寫入請求和資料流程:
Update和Delete實現原理
刪除和更新操作也是寫操作。但是,Elasticsearch中的文件是不可變的(immutable),因此不能刪除或修改。那麼,如何刪除/更新文件呢?
磁碟上的每個分段(segment)都有一個.del檔案與它相關聯。當傳送刪除請求時,該文件未被真正刪除,而是在.del檔案中標記為已刪除。此文件可能仍然能被搜尋到,但會從結果中過濾掉。當分段合併時(我們將在後續的帖子中包括段合併),在.del檔案中標記為已刪除的文件不會被包括在新的合併段中。
現在,我們來看看更新是如何工作的。建立新文件時,Elasticsearch將為該文件分配一個版本號。對文件的每次更改都會產生一個新的版本號。當執行更新時,舊版本在.del檔案中被標記為已刪除,並且新版本在新的分段中編入索引。舊版本可能仍然與搜尋查詢匹配,但是從結果中將其過濾掉。
indexed/updated文件後,我們希望執行搜尋請求。我們來看看如何在Elasticsearch中執行搜尋請求。
Read的實現原理
讀操作由兩個階段組成:
- 查詢階段(Query Phase)
- 獲取階段(Fetch Phase)
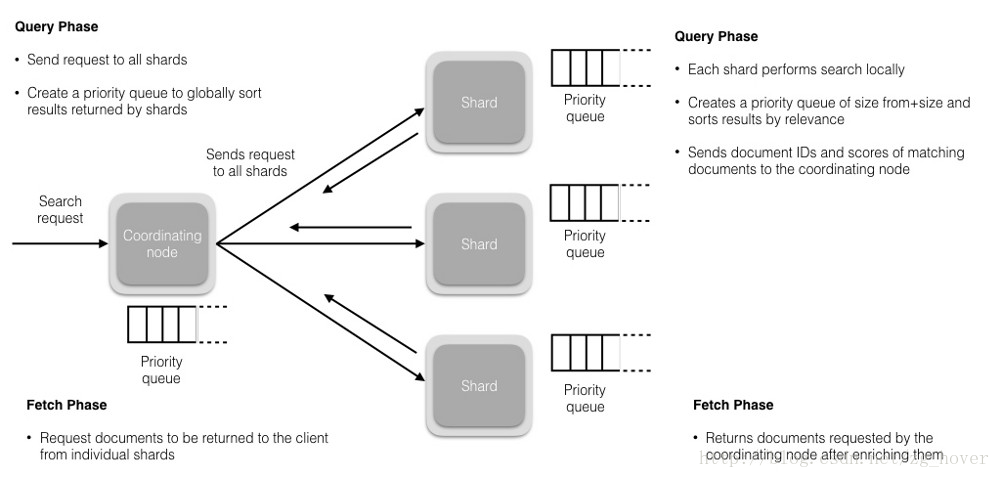
查詢階段(Query Phase)
在此階段,協調節點將搜尋請求路由到索引(index)中的所有分片(shards)(包括:主要或副本)。分片獨立執行搜尋,並根據相關性分數建立一個優先順序排序結果(稍後我們將介紹相關性分數)。所有分片將匹配的文件和相關分數的文件ID返回給協調節點。協調節點建立一個新的優先順序佇列,並對全域性結果進行排序。可以有很多文件匹配結果,但預設情況下,每個分片將前10個結果傳送到協調節點,協調建立優先順序佇列,從所有分片中分選結果並返回前10個匹配。
獲取階段(Fetch Phase)
在協調節點對所有結果進行排序,已生成全域性排序的文件列表後,它將從所有分片請求原始文件。
所有的分片都會豐富文件並將其返回到協調節點。
如上所述,搜尋結果按相關性排序。我們來回顧一下相關性的定義。
搜尋相關性(Search Relevance)
相關性由Elasticsearch給予搜尋結果中返回的每個文件的分數確定。用於評分的預設演算法為tf / idf(術語頻率/逆文件頻率)。該術語頻率測量術語出現在文件中的次數(更高頻率=更高的相關性),逆文件頻率測量術語在整個索引中出現的頻率佔索引中文件總數的百分比(更高的頻率
==較少的相關性)。最終得分是tf-idf分數與其他因素(如詞語鄰近度(短語查詢)),術語相似度(用於模糊查詢)等的組合。
參考
相關推薦
Elasticsearch實現原理分析-1
介紹 本文是分析Elasticsearch系列文章中的一篇,是一個譯文。共有三篇,每篇講解部分Elasticsearch的實現原理。 在翻譯的過程中,也需要檢視對應部分的原始碼,來加深對實現原理的理解。但這裡並沒有對原始碼進行分析,原始碼的分
Elasticsearch實現原理分析-2
介紹 第1部分分析了Elasticsearch基本的讀、寫、更新、儲存等方面的實現原理,本文件主要介紹Elasticsearch如何實現分散式系統的三個特性(consensus, concurrency和consistency),以及分片的內部概念,例
Spring3.1.0實現原理分析(十四).MVC之處理器對映
大家好,今天我們分析下處理器對映,這個功能是MVC框架所應具備的基本功能。那麼,什麼是處理器對映呢,是指根據一套規則獲取處理本次request請求的執行鏈物件,它是連線url請求和執行鏈物件的橋樑。執行鏈又是什麼東東呢?無論是spring mvc還是stru
Spring3.1.0實現原理分析(二十二).Dao事務分析之事務管理器DataSourceTransactionManager
大家好,開篇先來談談spring事務的優點吧,即spring事務的存在價值。首先它提供了非侵入式編碼的事務實現,這個是通過aop實現的,具體的實現過程之前也寫部落格分析了。 另外,spring還提供了一套標準的事務管理工作流程。簡單的說,事務管理
Semaphore實現原理分析
業務需求 err java並發 裏的 eas static 默認 rem lac synchronized的語義是互斥鎖,就是在同一時刻,只有一個線程能獲得執行代碼的鎖。但是現實生活中,有好多的場景,鎖不止一把。 比如說,又到了十一假期,買票是重點,必須圈起來。在購票大廳裏
php session實現原理分析
keep enc accep referer zip image time -s accept http://www.jb51.net/article/77726.htm 第一次會話時會有Set-Cookie響應頭返回,設置上PHPSESSID cookie Cache
Java原子類實現原理分析
upd hat 16px 檢查 () 過程 jvm api 處理 並發包中的原子類可以解決類似num++這樣的復合類操作的原子性問題,相比鎖機制,使用原子類更精巧輕量,性能開銷更小,下面就一起來分析下原子類的實現機理。 悲觀的解決方案(阻塞同步) 我們知道,num++看
Android系統的智能指針(輕量級指針、強指針和弱指針)的實現原理分析【轉】
其中 sin 類的定義 reason ava tab eas file 現在 Android系統的運行時庫層代碼是用C++來編寫的,用C++ 來寫代碼最容易出錯的地方就是指針了,一旦使用不當,輕則造成內存泄漏,重則造成系統崩潰。不過系統為我們提供了智能指針,避免出現上述問題
Tomcat 的 ErrorPage 實現原理分析
esp 轉發 isp ORC code compare on() sta ger https://www.cnblogs.com/softidea/p/5981766.html 使用Tomcat,一定見到過404,500的時候,見到過Tomcat提供的錯誤頁面,例如請求的資
轉:HashMap實現原理分析(面試問題:兩個hashcode相同 的對象怎麽存入hashmap的)
影響 strong 就會 怎麽 ash 地方 shm nbsp 擔心 原文地址:https://www.cnblogs.com/faunjoe88/p/7992319.html 主要內容: 1)put 疑問:如果兩個key通過hash%Entry[].length得到的
HashMap實現原理分析及簡單實現一個HashMap
HashMap實現原理分析及簡單實現一個HashMap 歡迎關注作者部落格 簡書傳送門 轉載@原文地址 HashMap的工作原理是近年來常見的Java面試題。幾乎每個Java程式設計師都知道HashMap,都知道哪裡要用HashMap,知道HashMap和
根據時間戳轉Date實現(Java)及實現原理分析
時間戳是指格林威治時間1970年01月01日00時00分00秒(北京時間1970年01月01日08時00分00秒)起至現在的總秒數。 本次實現跟根據Java.text.* 包中的工具類實現的,示例程式碼: import java.text.SimpleDateFormat; public
OkHttp3實現原理分析(二)
概述 前言:前一節https://mp.csdn.net/postedit/84941253,總結了一下OkHttp3的簡單使用教程。在專案中使用了這個網路框架,在看完基本的原始碼之後,還是想總結一下OkHttp的實現流程。在學習框架的過程中,從使用方法出發,首先是怎麼使用,其次是我們使
MySQL Order By實現原理分析和Filesort優化
. 目錄(?)[-] 在MySQL中的ORDER BY有兩種排序實現方式: 1、利用有序索引獲取有序資料 2、檔案排序 在使用explain分析查詢的時候,利用有序索引獲取有序資料顯示Using index。而檔案排序顯示Using filesort。 1.利
Java JDK 動態代理使用及實現原理分析
一、什麼是代理? 代理是一種常用的設計模式,其目的就是為其他物件提供一個代理以控制對某個物件的訪問。代理類負責為委託類預處理訊息,過濾訊息並轉發訊息,以及進行訊息被委託類執行後的後續處理。 代理模式 UML 圖: 簡單結構示意圖: 為了保持行為的一致性,代
Guava TreeMultiSet實現原理分析(2)
5 count,size AvlNode為資料統計提供了多個便利引數,不需要遍歷所有的子節點就可以獲得相關的個數資訊。 AvlNode的統計屬性: elemCount:統計key相同的元素個數。 distinctElements:統計子樹中所有節點的個數,即ke
Ribbon使用及其客戶端負載均衡實現原理分析
1、ribbon負載均衡測試 (1)consumer工程新增依賴 <dependency> <groupId>org.springframework.cloud</groupId> <artif
Android控制元件TextView的實現原理分析
在前面一個系列的文章中,我們以視窗為單位,分析了WindowManagerService服務的實現。同時,在再前面一個系列的文章中,我們又分析了視窗的組成。簡單來說,視窗就是由一系列的檢視按照一定的佈局組織起來的。實際上,每一個檢視都是一個控制元件,這些控制可以
聊聊併發(六)ConcurrentLinkedQueue的實現原理分析
1. 引言 在併發程式設計中我們有時候需要使用執行緒安全的佇列。如果我們要實現一個執行緒安全的佇列有兩種實現方式一種是使用阻塞演算法,另一種是使用非阻塞演算法。使用阻塞演算法的佇列可以用一個鎖(入隊和出隊用同一把鎖)或兩個鎖(入隊和出隊用不同的鎖)等方式來實現,而非阻塞的實現方式則可以
Spring Aop 原始碼實現原理分析
更新:2018/4/2 修改字型、新增引言。0 引言AOP是Aspect Oriented Programing的簡稱,面向切面程式設計。AOP適合於那些具有橫切邏輯的應用:如效能監測,訪問控制,事務管理、快取、物件池管理以及日誌記錄。AOP將這些分散在各個業務邏輯中的程