
DeepLearning (五) 基於Keras的CNN 訓練cifar-10 資料庫
注:新版本的keras使用時,可能會報max_pool_2d() got an unexpected keyword argument ‘mode 這個錯誤,這是舊版本的theano的一個bug,只需要到theano的官網下載最新原始碼重新編譯安裝即可
另:這份程式碼是舊版本的Keras,新版本的keras有較大改動,這份程式碼已經不能直接執行,可以根據模型自己編寫程式碼即可。
| 資料庫介紹 |
Cifar-10是由Hinton的兩個大弟子Alex Krizhevsky、Ilya Sutskever收集的一個用於普適物體識別的資料集。
Cifar-10由60000張32*32的RGB彩色圖片構成,共10個分類。50000張訓練,10000張測試(交叉驗證)。這個資料集最大的特點在於將識別遷移到了普適物體,而且應用於多分類(姊妹資料集Cifar-100達到100類,ILSVRC比賽則是1000類)。

同已經成熟的人臉識別相比,普適物體識別挑戰巨大,資料中含有大量特徵、噪聲,識別物體比例不一。
| 開發工具 |
現在流行的DeepLearning庫挺多的,現在 GitHub 上關注最火的應該是 caffe 。不過我個人覺得caffe封裝的太死了,很多東西都封裝成庫,要學習原理的話,還是得去看看 Theano 版本的。
我個人使用的庫是朋友推薦的 Keras ,是基於 Theano的,優點是使用方便,可以快速開發。
| 網路框架 |
網路框架參考 caffe 的cifar-10的框架,但自己做了修改。
框架如下:
layer1 Conv1:
kernel :32 ,kernel size : 5 , activation : relu ,dropout : 0.25
layer2 Conv2:
kernel: 32,kernel size: 5, activation : relu ,dropout : 0.25
layer3 MaxPooling1: poolsize:2
layer4 Conv3:
kernel: 64,kernel size: 3, activation : relu ,dropout : 0.25
layer5 MaxPooling2: poolsize:2
layer6: full connect 512 ,activation :tanh
layer7: softmax
| 訓練結果 |

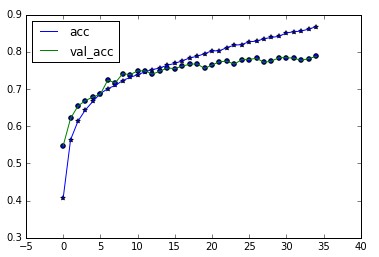
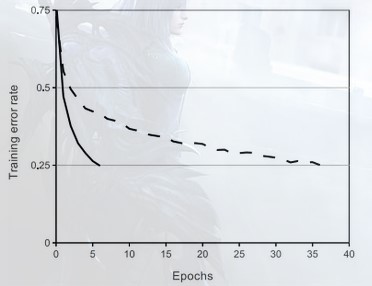
對比 Alex的論文裡 的訓練誤差圖走向,論文裡說,用 relu 替換 tanh 作為啟用函式可以使演算法快速收斂,不過實際中我並不感覺得出可以快多少。
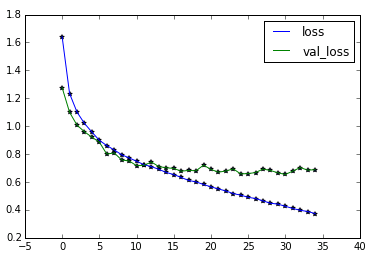
或者說,看loss的走向並沒有論文中的那麼好,當然我的框架跟作者的不完全相同。
進行 35 次迭代,最終訓練準確率為 0.86,交叉驗證準確率為: 0.78
感覺已經快過擬合了,於是沒有再增加迭代次數。
| 訓練要點 |
- 必須要做的,對cifar-10資料庫進行預處理,也就是去均值,歸一化以及做白化處理。
- 用 relu 替換 tanh 作為啟用函式之後,必須講learningrate 調低一個數量級,否則會出現過擬合。
- relu 應該使用在什麼layer呢?答案是除了最後一層的 softmax 要用tanh之外,其他層都可以。
- 關於Dropout的比例,論文中說是 0.5 ,但是我卻發現 0.25 效果更好,這可能需要根據資料進行調整
| 啟用函式 |
深度學習中的啟用函式有:sigmoid,tanh,ReLUs,Softplus
目前最好的是 rectified linear units (ReLUs)修正線性單元
多層的神經網路如果用sigmoid或tanh啟用函式也不做pre-training的話會因為 gradient vanishing problem 而會無法收斂。使用ReLU則這沒有這個問題。
預訓練的用處:規則化,防止過擬合;壓縮資料,去除冗餘;強化特徵,減小誤差;加快收斂速度。
標準的sigmoid輸出不具備稀疏性,需要用一些懲罰因子來訓練出一大堆接近0的冗餘資料來,從而產生稀疏資料,例如L1、L1/L2或Student-t作懲罰因子。因此需要進行無監督的預訓練。
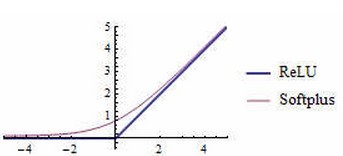
而ReLU是線性修正,公式為:g(x) = max(0, x),函式圖如下。它的作用是如果計算出的值小於0,就讓它等於0,否則保持原來的值不變。這是一種簡單粗暴地強制某些資料為0的方法,然而經實踐證明,訓練後的網路完全具備適度的稀疏性。而且訓練後的視覺化效果和傳統方式預訓練出的效果很相似,這也說明了ReLU具備引導適度稀疏的能力
 —
—
| Dropout 的作用 |
Dropout: 防止過擬合,做法:在訓練時,FP中隨機將Hidden layer 中的節點輸出值按照比例隨機設定為0,同時BP過程中相對應的被置為0的Hidden layer 節點的誤差也為0,稀疏化。這樣會使得神經元不得不去學習一些更加具備魯棒性以及更加抽象的features.
| 訓練程式碼 |
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 27 11:27:34 2015
@author: lab-liu.longpo
"""
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD, Adadelta, Adagrad
from keras.utils import np_utils, generic_utils
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
d = sio.loadmat('data.mat')
data = d['d']
label = d['l']
data = np.reshape(data,(50000,3,32,32))
label = np_utils.to_categorical(label, 10)
print ('finish loading data')
model = Sequential()
model.add(Convolution2D(32, 3, 5, 5, border_mode='valid'))
model.add(Activation('relu'))
#model.add(MaxPooling2D(poolsize=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(32, 32, 5, 5, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(poolsize=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, 32, 3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(poolsize=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64*5*5, 512, init='normal'))
model.add(Activation('tanh'))
model.add(Dense(512, 10, init='normal'))
model.add(Activation('softmax'))
sgd = SGD(l2=0.001,lr=0.0065, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd,class_mode="categorical")
#checkpointer = ModelCheckpoint(filepath="weight.hdf5",verbose=1,save_best_only=True)
#model.fit(data, label, batch_size=100,nb_epoch=10,shuffle=True,verbose=1,show_accuracy=True,validation_split=0.2,callbacks=[checkpointer])
result = model.fit(data, label, batch_size=50,nb_epoch=35,shuffle=True,verbose=1,show_accuracy=True,validation_split=0.2)
#model.save_weights(weights,accuracy=False)
# plot the result
plt.figure
plt.plot(result.epoch,result.history['acc'],label="acc")
plt.plot(result.epoch,result.history['val_acc'],label="val_acc")
plt.scatter(result.epoch,result.history['acc'],marker='*')
plt.scatter(result.epoch,result.history['val_acc'])
plt.legend(loc='under right')
plt.show()
plt.figure
plt.plot(result.epoch,result.history['loss'],label="loss")
plt.plot(result.epoch,result.history['val_loss'],label="val_loss")
plt.scatter(result.epoch,result.history['loss'],marker='*')
plt.scatter(result.epoch,result.history['val_loss'],marker='*')
plt.legend(loc='upper right')
plt.show()今天將自己以前實現的機器學習以及深度學習演算法放到 GitHub 上,本文的資料集以及資料預處理,訓練程式碼等也將會放到GitHub上,如果覺得有用就請給個star。
相關推薦
DeepLearning (五) 基於Keras的CNN 訓練cifar-10 資料庫
資料庫介紹 開發工具 網路框架 訓練結果 訓練要點 啟用函式 訓練程式碼 注:新版本的keras使用時,可能會報max_pool_2d() got an unexpected keyword argument ‘mode 這個錯誤,
基於Keras:CIFAR-10-分類
一、概述 CIFAR-10是一個比較經典的資料集,主要用於影象分類; 該資料集共有60000張彩色影象,這些影象是32*32,分為10個類,每類6000張圖。這裡面有50000張用於訓練,構成了5個訓練批,每一批10000張圖;另外10000用於測試,單獨構成
深度學習入門——利用卷積神經網路訓練CIFAR—10資料集
CIFAR-10資料集簡介 CIFAR-10是由Hinton的學生Alex Krizhevsky和Ilya Sutskever整理的一個用於普適物體的小型資料集。它一共包含10個類別的RGB彩色圖片:飛機、汽車、鳥類、貓、鹿、狗、蛙類、馬、船: 資料集包含50000張訓練圖片和1000
TensorFlow學習--卷積神經網路訓練CIFAR-10資料集
CIFAR-10資料集 CIFAR-10資料集包含10個類的60000張32x32的彩色影象,每個類有6000張影象。 有50000張訓練影象和10000張測試影象。 10個分類明細及對應的部分圖片: 卷積神經網路訓練CIFAR-10資料集
tensorflow vgg基於cifar-10進行訓練
最近接觸tf,想在cifar-10資料集上訓練下vgg網路。最開始想先跑vgg16,搜了一大圈,沒有一個可以直接跑的(我參考 【深度學習系列】用PaddlePaddle和Tensorflow實現經典CNN網路Vgg 跑出來的精度就10%),要麼是程式碼是針
TensorFlow學習筆記(九):CIFAR-10訓練例子報錯解決
以下報錯主要是由於TensorFlow升級1.0後與以前程式碼不相容所致。 1.AttributeError: 'module' object has noattribute 'random_crop' 解決方案: 將distorted_image= tf.ima
Tersorflow深度學習入門—— CIFAR-10 訓練示例報錯及解決方案
Tersorflow CIFAR-10 訓練示例報錯及解決方案 1.AttributeError: 'module' object has noattribute 'random_crop' 解
計算機視覺(五):使用SVM分類Cifar-10資料集
1 - 引言 之前我們使用了K-NN對Cifar-10資料集進行了圖片分類,正確率只有不到30%,但是還是比10%高的[手動滑稽],這次我們將學習使用SVM分類器來對Cafi-10資料集實現分類,但是正確率應該也不會很高 要想繼續提高正確率,就要對影象進行預處理和特徵的選取工作,而不
tensorflow、多GPU、多執行緒訓練VGG19來做cifar-10分類
背景:幾天前需要寫個多GPU訓練的演算法模型,翻來覆去在tensorflow的官網上看到cifar-10的官方程式碼,花了三天時間去掉程式碼的冗餘部分和改寫成自己的風格。程式碼共有6部分構成:1、data_input.py 由於cifar-10官方訓練集和驗證集都是.bin格
Pytorch打怪路(一)pytorch進行CIFAR-10分類(4)訓練
pytorch進行CIFAR-10分類(4)訓練 我的系列博文: 1、簡述 經過前面的資料載入和網路定義後,就可以開始訓練了,這裡會看到前面遇到的一些東西究竟在後面會有什麼用,所以這一
DeepLearning(基於caffe)實戰專案(4)--Matlab測試訓練好的model
好了,現在我們已經訓練好自己的model,如何用這個model去預測我們待測樣本的標籤,就成了一個需要解決的問題。 這裡我們主要說的是Matlab程式呼叫訓練好的model
Keras入門(五)搭建ResNet對CIFAR-10進行影象分類
本文將會介紹如何利用Keras來搭建著名的ResNet神經網路模型,在CIFAR-10資料集進行影象分類。 資料集介紹 CIFAR-10資料集是已經標註好的影象資料集,由Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton三人收集,其訪問網址為:https:
CARS: 華為提出基於進化演算法和權值共享的神經網路結構搜尋,CIFAR-10上僅需單卡半天 | CVPR 2020
為了優化進化演算法在神經網路結構搜尋時候選網路訓練過長的問題,參考ENAS和NSGA-III,論文提出連續進化結構搜尋方法(continuous evolution architecture search, CARS),最大化利用學習到的知識,如上一輪進化的結構和引數。首先構造用於引數共享的超網,從超網中產
SpringMVC 學習筆記(五) 基於RESTful的CRUD
super() ger select bsp ber ota his version pub 1.1. 概述 當提交的表單帶有_method字段時,通過HiddenHttpMethodFilter 將 POST 請求轉換成 DELETE、PUT請求,加上@Path
cifar-10 圖片可視化
adl odi 對象 shape ret plt rgb ray cnblogs 保存cifar-10 數據集 圖片 python3 #用於將cifar10的數據可視化 import pickle as p import numpy as np import matplo
日常訓練17-10-14
lan color pla 最短路 最短 pen hide 多少 queue Emptying the Baltic Kattis - emptyingbaltic 題意:問給定位置的抽水機需要排多少水。 類似最短路~ 1 /**************
日常訓練17-10-15
net editor space sort clu 朋友的朋友 ++ target c++ 題目鏈接:here Text Editor Gym - 101504F emmm...又是鏈表都寫不溜=_=|| 1 #include <bits/stdc++
日常訓練17-10-25
-1 style opened sed set int def log scan CF877 鏈接 D. Olya and Energy Drinks bfs 1 #include <bits/stdc++.h> 2 using namespace
2018上海高校金馬五校賽訓練日誌
ont target 水題 href 校賽 隊列 正數 distance com solve 5(A E F I L) rank 77 水題總體沒有很卡,但提升的題都沒有思路,實力差距還是有的。 個人感覺出了的題都是銅牌及以下的難度。 A Was
Linux20180416三周第五次課(4月10日)
磁盤格式化 掛載 以及 手動增加swap4.5/4.6 磁盤格式化4.7/4.8 磁盤掛載4.9 手動增加swap空間磁盤格式化分區後只有格式化後才可以使用可以查看文件系統 cat /etc/filesystems 可以查看centos7支持的文件格式centos7默認的是 xfs的文件格式centos6默