
[Python] 網路爬蟲和正則表示式學習總結
以前在學校做科研都是直接利用網上共享的一些資料,就像我們經常說的dataset、beachmark等等。但是,對於實際的工業需求來說,爬取網路的資料是必須的並且是首要的。最近在國內一家網際網路公司實習,我的mentor交給我的第一件事就是去網路上爬取資料,並對爬取的資料進行相關的分析和解析。
1.利用urllib2對指定的URL抓取網頁內容
網路爬蟲(Web Spider),顧名思義就是將龐大的網際網路看做是一張大網,而我們要做的就是用程式碼去構造一個類似於爬蟲的實體,在這張大網上爬取我們需要的資料。
所謂網頁抓取,就是把URL地址中指定的網絡資源從網路流中讀取出來,儲存到本地。
最簡單的抓取網路的Python程式碼,四行就可以搞定:
1 import urllib2 2 response = urllib2.urlopen('http://www.toutiao.com/') 3 html = response.read() 4 print html
顯示抓取的結果:
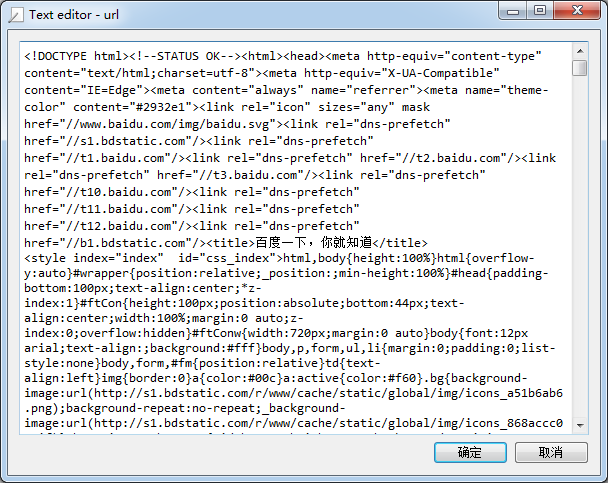
我們可以開啟百度主頁,右擊,選擇檢視原始碼(火狐OR谷歌瀏覽器均可),會發現也是完全一樣的內容。也就是說,上面這四行程式碼將我們訪問百度時瀏覽器收到的程式碼們全部列印了出來。這就是一個最簡單的利用urllib2進行網頁爬取的例子。
當然,有的網站為了防止爬蟲,可能會拒絕爬蟲的請求,這就需要我們來修改http中的Header項了。還有一些站點有所謂的反盜鏈設定,其實說穿了很簡單,就是檢查你傳送請求的header裡面,referer站點是不是他自己,所以我們只需要像把headers的referer改成該網站即可。有關Header項的修改請轉至下邊的連結檢視,裡邊詳細地介紹了Header的修改、Cookie和表單的處理,等等。
2. 使用正則表示式過濾抓取到的網頁資訊
如果說網頁爬蟲爬取的網頁資訊是資料大海的話,那麼正則表示式就是我們進行“大海撈針”的工具。
首先宣告一點,正則表示式不是Python的語法,並不屬於Python,其他的語言中也同樣支援正則表示式的使用。具體來說,它是一種強大的字串匹配和處理規則。
2.1 正則表示式介紹
下圖展示了使用正則表示式進行匹配的流程:

下圖列出了Python支援的正則表示式元字元和語法:
2.1.1 正則表示式元字元

2.1.2 數量詞的貪婪模式與非貪婪模式
正則表示式通常用於在文字中查詢匹配的字串。貪婪模式,總是嘗試匹配儘可能多的字元;非貪婪模式則相反,總是嘗試匹配儘可能少的字元。Python裡數量詞預設是貪婪的。
例如:正則表示式"ab*"如果用於查詢"abbbc",將找到"abbb"。而如果使用非貪婪的數量詞"ab*?",將找到"a"。
2.1.3 反斜槓的問題
與大多數程式語言相同,正則表示式裡使用"\"作為轉義字元,這就可能造成反斜槓困擾。假如你需要匹配文字中的字元"\",那麼使用程式語言表示的正則表示式裡將需要4個反斜槓"\\\\":第一個和第三個用於在程式語言裡將第二個和第四個轉義成反斜槓,轉換成兩個反斜槓\\後再在正則表示式裡轉義成一個反斜槓用來匹配反斜槓\。這樣顯然是非常麻煩的。
Python裡的原生字串很好地解決了這個問題,這個例子中的正則表示式可以使用r"\\"表示。同樣,匹配一個數字的"\\d"可以寫成r"\d"
2.2 Python的re模組
Python通過re模組提供對正則表示式的支援。
使用re的一般步驟是:
Step1:先將正則表示式的字串形式編譯為Pattern例項。
Step2:然後使用Pattern例項處理文字並獲得匹配結果(一個Match例項)。
Step3:最後使用Match例項獲得資訊,進行其他的操作。
一個使用Python的re模組進行正則表示式匹配的例子:
-
# -*- coding: utf-8 -*- #一個簡單的re例項,匹配字串中的hello字串 #匯入re模組 import re # 將正則表示式編譯成Pattern物件,注意hello前面的r的意思是“原生字串” pattern = re.compile(r'hello') # 使用Pattern匹配文字,獲得匹配結果,無法匹配時將返回None match1 = pattern.match('hello world!') match2 = pattern.match('helloo world!') match3 = pattern.match('helllo world!') #如果match1匹配成功 if match1: # 使用Match獲得分組資訊 print match1.group() else: print 'match1匹配失敗!' #如果match2匹配成功 if match2: # 使用Match獲得分組資訊 print match2.group() else: print 'match2匹配失敗!' #如果match3匹配成功 if match3: # 使用Match獲得分組資訊 print match3.group() else: print 'match3匹配失敗!'
輸出結果:
hello
hello
match3匹配失敗!
當然,也可以省略編譯pattern的過程,如下所示:
# -*- coding: utf-8 -*- #一個簡單的re例項,匹配字串中的hello字串 import re m = re.match(r'hello', 'hello world!') print m.group()
除了match以外,Python中還提供了其他的匹配模式,可以針對不同的環境和用途來選擇不同的匹配模式。
1)match:只從字串的開始與正則表示式匹配,匹配成功返回matchobject,否則返回none;
2)search:將字串的所有字串嘗試與正則表示式匹配,如果所有的字串都沒有匹配成功,返回none,否則返回matchobject;(re.search相當於perl中的預設行為)
3)findall:匹配所有匹配成功的結果。
詳細的使用細則,可以檢視下邊的內容:
當然,如果你覺得使用正則表示式太繁瑣的話,Python提供了BeautifulSoup外掛來取代正則表示式,進行網頁的解析。想了解有關BeautifulSoup方面的知識,請移至下邊連結:
2.3 Python正則表示式彙總
2.3.1 正則表示式模式
模式字串使用特殊的語法來表示一個正則表示式:
字母和數字表示他們自身。一個正則表示式模式中的字母和數字匹配同樣的字串。
多數字母和數字前加一個反斜槓時會擁有不同的含義。
標點符號只有被轉義時才匹配自身,否則它們表示特殊的含義。
反斜槓本身需要使用反斜槓轉義。
由於正則表示式通常都包含反斜槓,所以你最好使用原始字串來表示它們。模式元素(如 r'/t',等價於'//t')匹配相應的特殊字元。
下表列出了正則表示式模式語法中的特殊元素。如果你使用模式的同時提供了可選的標誌引數,某些模式元素的含義會改變。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字串的開頭 |
| $ | 匹配字串的末尾。 |
| . | 匹配任意字元,除了換行符,當re.DOTALL標記被指定時,則可以匹配包括換行符的任意字元。 |
| [...] | 用來表示一組字元,單獨列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字元:[^abc] 匹配除了a,b,c之外的字元。 |
| re* | 匹配0個或多個的表示式。 |
| re+ | 匹配1個或多個的表示式。 |
| re? | 匹配0個或1個由前面的正則表示式定義的片段,非貪婪方式 |
| re{ n} | |
| re{ n,} | 精確匹配n個前面表示式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正則表示式定義的片段,貪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括號內的表示式,也表示一個組 |
| (?imx) | 正則表示式包含三種可選標誌:i, m, 或 x 。隻影響括號中的區域。 |
| (?-imx) | 正則表示式關閉 i, m, 或 x 可選標誌。隻影響括號中的區域。 |
| (?: re) | 類似 (...), 但是不表示一個組 |
| (?imx: re) | 在括號中使用i, m, 或 x 可選標誌 |
| (?-imx: re) | 在括號中不使用i, m, 或 x 可選標誌 |
| (?#...) | 註釋. |
| (?= re) | 前向肯定界定符。如果所含正則表示式,以 ... 表示,在當前位置成功匹配時成功,否則失敗。但一旦所含表示式已經嘗試,匹配引擎根本沒有提高;模式的剩餘部分還要嘗試界定符的右邊。 |
| (?! re) | 前向否定界定符。與肯定界定符相反;當所含表示式不能在字串當前位置匹配時成功 |
| (?> re) | 匹配的獨立模式,省去回溯。 |
| \w | 匹配字母數字 |
| \W | 匹配非字母數字 |
| \s | 匹配任意空白字元,等價於 [\t\n\r\f]. |
| \S | 匹配任意非空字元 |
| \d | 匹配任意數字,等價於 [0-9]. |
| \D | 匹配任意非數字 |
| \A | 匹配字串開始 |
| \Z | 匹配字串結束,如果是存在換行,只匹配到換行前的結束字串。c |
| \z | 匹配字串結束 |
| \G | 匹配最後匹配完成的位置。 |
| \b | 匹配一個單詞邊界,也就是指單詞和空格間的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非單詞邊界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一個換行符。匹配一個製表符。等 |
| \1...\9 | 匹配第n個分組的子表示式。 |
| \10 | 匹配第n個分組的子表示式,如果它經匹配。否則指的是八進位制字元碼的表示式。 |
2.3.2 正則表示式例項
字元匹配:
| 例項 | 描述 |
|---|---|
| python | 匹配 "python". |
字元類:
| 例項 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括號內的任意一個字母 |
| [0-9] | 匹配任何數字。類似於 [0123456789] |
| [a-z] | 匹配任何小寫字母 |
| [A-Z] | 匹配任何大寫字母 |
| [a-zA-Z0-9] | 匹配任何字母及數字 |
| [^aeiou] | 除了aeiou字母以外的所有字元 |
| [^0-9] | 匹配除了數字外的字元 |
特殊字元類:
| 例項 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何單個字元。要匹配包括 '\n' 在內的任何字元,請使用象 '[.\n]' 的模式。 |
| \d | 匹配一個數字字元。等價於 [0-9]。 |
| \D | 匹配一個非數字字元。等價於 [^0-9]。 |
| \s | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字元。等價於 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下劃線的任何單詞字元。等價於'[A-Za-z0-9_]'。 |
| \W | 匹配任何非單詞字元。等價於 '[^A-Za-z0-9_]'。 |
更加詳細的正則表示式教程請見正則表示式手冊。
相關推薦
[Python] 網路爬蟲和正則表示式學習總結
以前在學校做科研都是直接利用網上共享的一些資料,就像我們經常說的dataset、beachmark等等。但是,對於實際的工業需求來說,爬取網路的資料是必須的並且是首要的。最近在國內一家網際網路公司實習,我的mentor交給我的第一件事就是去網路上爬取資料,並對爬取的資料進行相關的分析和解析。 1.利用u
python網路爬蟲及正則表示式
最簡單的爬取網頁內容 #coding=utf-8 import re import urllib # 讀取url內容 def getHtml(url): page = urllib.urlopen(url) html = page.read() r
python學習筆記之網路爬蟲(五)正則表示式
IT Xiao Ang Zai 9月13號 版本:python3.64 程式設計軟體:pycharm 今天我們來學習正則表示式,那麼什麼是正則表示式呢?我們發現,下載一個網頁是容易的,但是要在網頁中找到我們需要的內容,是比較困難的。直接用find()方法是根本不
Python 利用BeautifulSoup和正則表示式 來爬取旅遊網資料
import re import requests import time from bs4 import BeautifulSoup url = ‘http://www.cntour.cn/’ r = requests.get(url) print(r.encoding,len(r.t
python網路基礎之正則表示式
下面是我對正則表示式的一些簡單介紹,它多用於爬蟲,用來定製規則 # 正則表示式匯入模組 import re # match只匹配字串的頭 # re.match(正則表示式,需要處理的字串) re.match(r"hello", "hello world") # 大小寫的匹配 re.m
網路爬蟲的正則表示式
0x00 re正則表示式 正則表示式: 通用字串表達的框架 簡潔表達一組字串的表示式 針對字串表達“簡潔”和“特徵”思想的工具 正則表示式在文字處理中的作用: 表達文字型別 同時查詢和替換一組字串 匹配
網路爬蟲_re正則表示式
"""正則表示式re 概念 檢索符合某個規則的字串。 通用的字串表達框架。 簡潔表達一組字串。 常用 表達文字型別的特徵。 同時查詢或替換一組字串。 匹配字串全部或部分。""" # -------------------
android 開發--抓取網頁解析網頁內容的若干方法(網路爬蟲)(正則表示式)
網頁有兩種格式,一種是xml另一種是html,目前似乎好像大部分都是html格式的,檢視網頁格式的方法是在瀏覽器中右鍵-->檢視原始碼 一,XML解析的三大方法 (1) SAX: Simple API for XML SAX是一個解析速度快並且佔用記憶體少的XML解析
python爬蟲學習實踐(一):requests庫和正則表示式之淘寶爬蟲實戰
使用requests庫是需要安裝的,requests庫相比urllib 庫來說更高階方便一點,同時與scrapy相比較還是不夠強大,本文主要介紹利用requests庫和正則表示式完成一項簡單的爬蟲小專案----淘寶商品爬蟲。有關於更多requests庫的使用方法請參考:官方文件第一步:我們先開啟淘寶網頁然後搜
Python爬蟲實習筆記 | Week3 資料爬取和正則再學習
2018/10/29 1.所思所想:雖然自己的考試在即,但工作上不能有半點馬虎,要認真努力,不辜負期望。中午和他們去吃飯,算是吃飯創新吧。下午爬了雞西的網站,還有一些欄位沒爬出來,正則用的不熟悉,此時終於露出端倪,心情不是很好。。明天上午把正則好好看看。 2.工作: [1].哈爾濱:html p
python爬蟲裡資訊提取的核心方法: Beautifulsoup、Xpath和正則表示式
20170531 這幾天重新拾起了爬蟲,算起來有將近5個月不碰python爬蟲了。 對照著網上的程式和自己以前寫的抓圖的程式進行了重寫,發現了很多問題。總結和歸納和提高學習效果的有效手段,因此對於這些問題做個歸納和總結,一方面總結學習成果,使之成為自己的東西,另一方面
python爬蟲系列(1):使用python3和正則表示式獲取貓眼電影排行榜資料
簡述 這次打算寫一個爬蟲系列,一邊也想好好總結鞏固學習的知識,一邊做總結筆記,方便以後回憶。這次我們使用Python3和正則表示式來爬取一個簡單html頁面資訊,就從貓眼電影的排行榜單開始吧。如果讀到這篇文章的是位大神,期望您能不吝賜教,指正錯誤,如果您是小白,咋們可以一同
python正則表示式學習筆記
正則表示式 學習資源:https://github.com/EbookFoundation/free-programming-books/blob/master/free-programming-books-zh.md 正則表達例子: | A|B
Python爬蟲(正則表示式)
Python爬蟲(正則表示式) 最近接觸爬蟲比較多,下面我來展示一個剛爬取的成果,使用正則表示式的方法,希望對剛開始接觸爬蟲的小夥伴有所幫助,同時希望大佬們給予點評和指導 接下來,步入正題,使用正則表示式爬取資料是一種原始且有效的方法,正則表示式的作用即字元匹配,匹配出你想得到的
python爬蟲5——正則表示式
正則表示式很好用,之前沒有體會到它的強大,在寫原生的servlet程式,呼叫微服務時,要經常拼接字串,寫sql,需求轉換成程式碼,沒有個靈活的工具處理,真的是會被煩死的。就用sublime_txt +正則表示式,賊好用! 為什麼要學正則表示式 實際上爬蟲一共就四個主要步驟:
LINUX學習—grep和正則表示式(LINUX三劍客)
grep, egrep, fgrep grep(GLOBAL RESEARCH) 是一種強大的文字搜尋工具,它能使用正則表示式搜尋文字,並把匹配的行打印出來。根據模式,搜尋文字,並將符合模式的文字行顯示出來。只能使用基本正則表示式 要使用擴充套件正則表示式需要-E pattern
Python爬蟲之正則表示式(1)
廖雪峰正則表示式學習筆記 1:用\d可以匹配一個數字;用\w可以匹配一個字母或數字; '00\d' 可以匹配‘007’,但是無法匹配‘00A’; ‘\d\d\d’可以匹配‘010’; ‘\w\w\d’可以匹配‘py3’; 2:.可以匹配任意字元; 'py.'可以匹配'pyc'、
python 正則表示式學習
re.match()函式: 函式語法: re.mathch ( pattern , string , flags = 0) 引數說明: pattem 匹配的正則表示式
Python爬蟲與正則表示式
Python爬蟲與正則表示式 一.Python中萬用字元的使用 1.表示方式 表示 意義 * 匹配0到任意字元 ? 匹配單個字元
Python爬蟲-利用正則表示式爬取貓眼電影
利用正則來爬去貓眼電影 =================================== ===================================================== 1 ''' 2 利用正則來爬去貓眼電影 3 1. url: http://maoya