【Scrapy框架持久化儲存】
基於終端指令的持久化儲存
前提:保證爬蟲檔案中的parse方法的返回值為可迭代資料型別(通常為list/dict)。
該返回值可以通過終端指令的形式寫入指定格式的檔案中進行持久化儲存。
執行如下命令進行持久化儲存:
scrapy crawl 應用名稱 -o xx.檔案格式
其支援的檔案格式有:‘json’, ‘jsonlines’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’,我們一般使用csv。
基於管道的持久化儲存
Scrapy框架為我們提供了高效、便捷的持久化操作功能,我們直接使用即可。
在使用之前,我們先來認識下這兩個檔案:
- items.py:資料結構模板檔案,用於定義資料屬性。
- pipelines.py:管道檔案,接收資料(items),進行持久化操作。
---------------------------↓
持久化流程:
- 應用檔案爬取到資料後,將資料封裝到items物件中,進行持久化操作。
- 使用yield關鍵字將items物件提交給pipelines管道進行持久化操作。
- 在管道檔案中的類中的process_item方法接收爬蟲檔案提交過來的item物件,
然後編寫持久化儲存的程式碼將item物件中儲存的資料進行持久化儲存。
注意:
- 在settings.py配置檔案中開啟管道配置的字典:ITEM_PIPELINES
- 在items.py資料結構模板檔案中定義好要持久化的欄位
---------------------------↑
示例
下面將爬取你的CSDN部落格中所有文章和URL的對應關係,並進行持久化儲存。
第一步,我們先寫好應用檔案blog.py:import scrapy from Test.items import TestItem class BlogSpider(scrapy.Spider): name = 'blog' # 應用名稱start_urls = ['https://blog.csdn.net/qq_41964425/article/list/1'] # 起始url page = 1 # 用於計算頁碼數 max_page = 7 # 你的CSDN部落格一共有多少頁博文 url = 'https://blog.csdn.net/qq_41964425/article/list/%d' # 用於定位頁碼的url def parse(self, response): """ 訪問起始url頁面並獲取結果後的回撥函式 一般情況下,你寫了多少個起始url,此方法就會被呼叫多少次 :param response: 向起始URL傳送請求後,獲取的響應物件 :return: 此方法的返回值必須為 可迭代物件(通常為list/dict) 或 None """ # 我們先例項化一個item型別的物件 item = TestItem() # 定位到當期頁面中所有博文的連結(a標籤) a_list = response.xpath('//div[@class="article-list"]/div/h4/a') # type: list # 每個人的部落格,每一頁的都有這篇文章,你開啟網頁原始碼看看就知道了 a_list.pop(0) # 帝都的凜冬 https://blog.csdn.net/yoyo_liyy/article/details/82762601 # 開始解析處理部落格資料 for a in a_list: title = a.xpath('.//text()')[-1].extract().strip() # 獲取文章標題 url = a.xpath('.//@href').extract_first() # 獲取文章url # 下面將解析到的資料儲存到item物件中 item['title'] = title item['url'] = url # 最後,將itme物件提交給管道進行持久化儲存 yield item # 開始爬取所有頁面 if self.page < self.max_page: self.page += 1 current_page = format(self.url % self.page) # 當前的要爬取的url頁面 # 手動傳送請求 yield scrapy.Request(url=current_page, callback=self.parse) # callback用於指定回撥函式,即指定解析的方法 # 1.如果頁面內容與起始url的內容一致,可使用同一個解析方法(self.parse) # 2.如果頁面的內容不一致,需手動建立新的解析方法,可見下面 def dem(self, response): """ 2.如果頁面的內容不一致,需手動建立新的解析方法 注意:解析方法必須接收response物件 """ pass第二步,在資料結構模板檔案items.py中準備好要儲存的欄位:
import scrapy class TestItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() # 文章標題 url = scrapy.Field() # 文章url第三步,在管道檔案pipelines.py中寫持久化的邏輯:
class TestPipeline(object): def process_item(self, item, spider): """應用檔案每提交一次item,該方法就會被呼叫一次""" # 儲存資料到檔案 self.fp.write(item['title'] + '\t' + item['url'] + '\n') # 你一定要注意: # 此方法一定要返回itme物件,用於傳遞給後面的(優先順序低的)管道類中的此方法 # 關於優先順序的高低,可在settings.py檔案中的ITEM_PIPELINES字典中定義 return item # 重寫父類方法,用於開啟檔案 def open_spider(self, spider): """此方法在執行應用時被執行,注意:只會被執行一次""" print('開始爬取') self.fp = open('text.txt', 'w', encoding='utf-8') # 重寫父類方法,用於關閉檔案 def close_spider(self, spider): """此方法結束應用時被執行,注意:只會被執行一次""" print('爬取結束') self.fp.close()第四步,在配置檔案settings.py中開啟如下配置項:
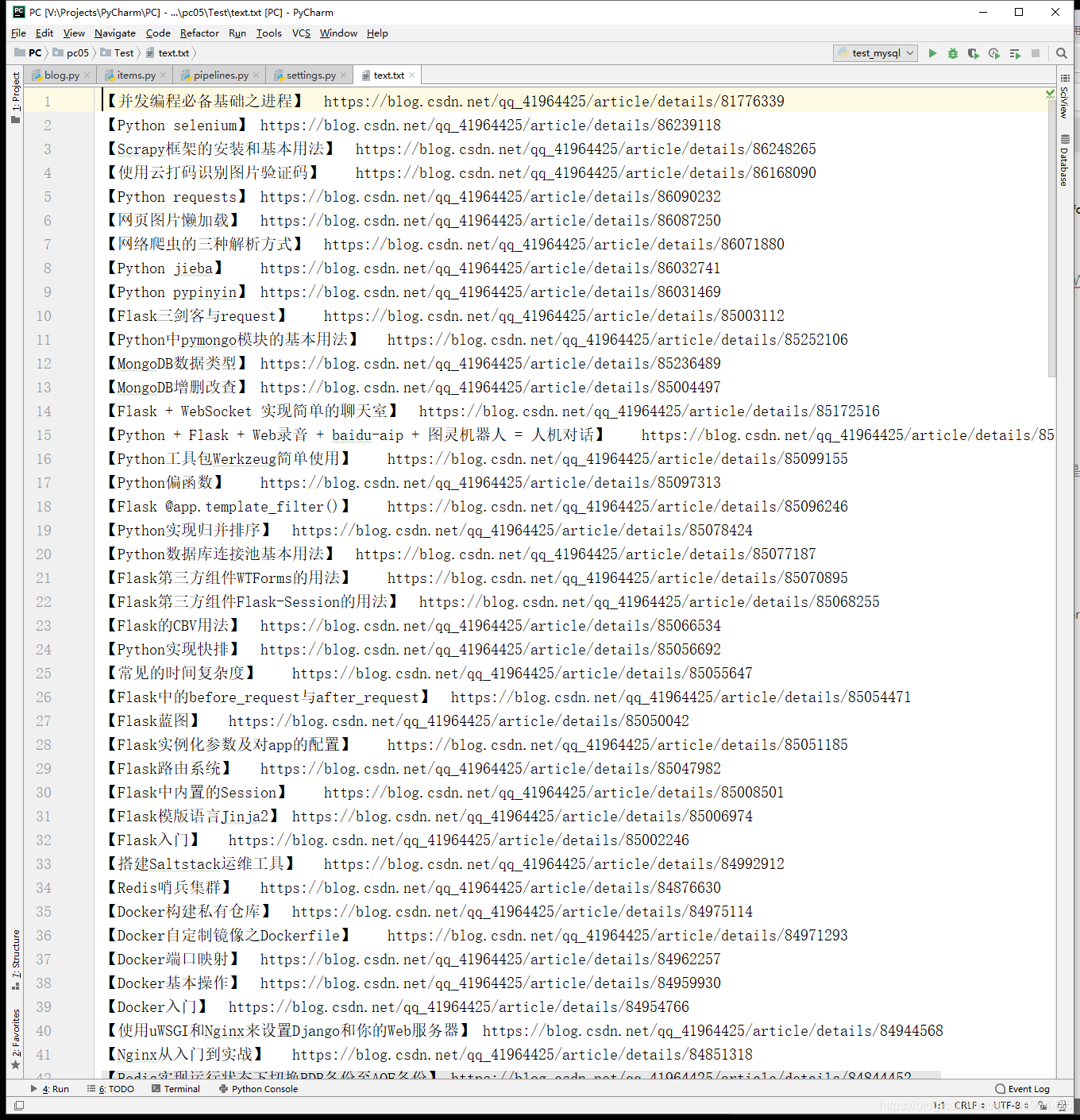
# 偽裝請求載體身份(User-Agent) USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # 是否遵守robots協議 ROBOTSTXT_OBEY = False # 開啟管道 ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是優先順序,數值越小優先順序越高,優先順序高的先執行 # 自定義的管道類新增到此字典時才會被呼叫 }第五步,在終端輸入執行命令:scrapy crawl blog,執行成功後,我們開啟檔案來看看:
怎麼樣,是不是像下面這樣。
哈哈哈。
不慌,我們不僅可以將資料持久化到檔案,還可以將資料持久化到資料庫中(比如下面的MySQL、Redis)。
---------------------------------------↓
持久化儲存到 MySQL# pipelines.py檔案 import pymysql # 自定義管道類,用於將資料寫入MySQL # 注意了: # 自定義的管道類需要在settings.py檔案中的ITEM_PIPELINES字典中註冊後才會被呼叫 # 而呼叫的順序取決於註冊時指定的優先順序 class TestPipeLineByMySQL(object): # 重寫父類方法,用於建立MySQL連結,並建立一個遊標 def open_spider(self, spider): """此方法在執行應用時被執行,注意:只會被執行一次""" self.conn = pymysql.connect( host='localhost', port=3306, user='zyk', password='[email protected]', db='blog', # 指定你要使用的資料庫 charset='utf8', # 指定資料庫的編碼 ) # 建立MySQL連結 self.cursor = self.conn.cursor() # 建立遊標 # 本人實測:這裡併發使用同一個遊標沒有出現問題 def process_item(self, item, spider): sql = 'insert into info(title, url) values (%s, %s)' # 要執行的sql語句 # 開始執行事務 try: self.cursor.execute(sql, (item['title'], item['url'])) # 增 self.conn.commit() # 提交 except Exception as e: print(e) self.conn.rollback() # 回滾 return item # 你一定要注意: # 此方法一定要返回itme物件,用於傳遞給後面的(優先順序低的)管道類中的此方法 # 關於優先順序的高低,可在settings.py檔案中的ITEM_PIPELINES字典中定義 # 重寫父類方法,用於關閉MySQL連結 def close_spider(self, spider): """此方法在結束應用時被執行,注意:只會被執行一次""" self.cursor.close() self.conn.close()寫完後別忘了在配置檔案settings.py中新增此管道類:
ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是優先順序,數值越小優先順序越高,優先順序高的先執行 'Test.pipelines.TestPipeLineByMySQL': 400, # 自定義的管道類新增到此字典時才會被呼叫 }
---------------------------------------↓
持久化儲存到 Redis# pipelines.py檔案 import redis import json # 自定義管道類,用於將資料寫入Redis # 注意了: # 自定義的管道類需要在settings.py檔案中的ITEM_PIPELINES字典中註冊後才會被呼叫 # 而呼叫的順序取決於註冊時指定的優先順序 class TestPipelineByRedis(object): # 重寫父類方法,用於建立Redis連線例項 def open_spider(self, spider): """此方法在執行應用時被執行,注意:只會被執行一次""" # 建立Redis連線例項 self.conn = conn = redis.Redis(host='localhost', port=6379, password='', decode_responses=True, db=15) # decode_responses=True 寫入的鍵值對中的value為字串型別,否則為位元組型別 # db=15 表示使用第15個數據庫 def process_item(self, item, spider): dct = { 'title': item['title'], 'url': item['url'] } # 將資料持久化至Redis self.conn.lpush('blog_info', json.dumps(dct, ensure_ascii=False)) # ensure_ascii=False 這樣可使取資料時顯示的為中文 return item # 你一定要注意: # 此方法一定要返回itme物件,用於傳遞給後面的(優先順序低的)管道類中的此方法 # 關於優先順序的高低,可在settings.py檔案中的ITEM_PIPELINES字典中定義跟上面一樣,在配置檔案settings.py中新增此管道類:
ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是優先順序,數值越小優先順序越高,優先順序高的先執行 'Test.pipelines.TestPipelineByMySQL': 400, # 自定義的管道類新增到此字典時才會被呼叫 'Test.pipelines.TestPipelineByRedis': 500, # 自定義的管道類新增到此字典時才會被呼叫 }在Redis中查詢持久化的資料:
lrange blog_info 0 -1