
15 Puzzle (4乘4謎題) IDA*(DFS策略與曼哈頓距離啟發) 的C語言實現
大家好!這是我的第一篇部落格,由於之前沒有撰寫部落格的經驗,並且也是初入計算機和人工智慧領域,可能有些表述或者理解不當,還請大家多多指教。
一、撰寫目的
由於這個學期在上演算法與資料結構課程的時候,其中一個大作業是用C語言和深度優先(DFS)的 IDA*(基於迭代加深的A*演算法)實現快速尋求15Puzzle(4乘4迷題)的解法的工具,同時儘可能地加入優化使得演算法儘可能快速、簡練。我發現網上很少有關於利用IDA*去解決15乃至24Puzzle的介紹,於是我就想跟大家分享一下自己的學習經驗和解決方法,文章中大多理念都是有我自己歸納總結的地方,只是為了給大家粗略地介紹一下並不能涵蓋這些知識的全部方面,希望能給大家一點幫助。
二、15Puzzle(4乘4迷題)及其一般演算法簡介
1. 15-Puzzle:15Puzzle(4乘4迷題)看似陌生,但其實肯定每個人都知道甚至玩過類似的衍生遊戲,在此我們以15Puzzle為例給大家介紹。15Puzzle是一個由16個宮格以4乘4方式排列的組成的圖案,通常是以益智類遊戲的方式出現,16個宮格中有15個具有數字編號或圖案,剩下一個為空格。當16個格子按照一定順序排列成為“最終狀態”時,其數字編號也會按照順序排列,或是其圖案會一個大的圖片,如下方就是數字形式的15Puzzle的“最終狀態”:
B 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
注:B代表空格子,B可位於任何一個角落,取決於不同的遊戲規則
在遊戲初始狀態時,所有宮格為亂序排列,如:
14 13 15 7
11 12 9 5
6 B 2 1
4 8 10 3
一次移動中,玩家只可以將空格(B)與其相鄰的某個格子互換位置,達到一個新的狀態。如上圖第一步只可能為將B與12,6,2,或8交換位置。玩家若通過多次移動,將全部宮格恢復到“最終形態”後,遊戲即結束,為了方便起見,在程式中我們採用0代替B。
為了直觀地說明演算法時間複雜度的差異,在這裡我採用了6組隨機但必有解的初始狀態,分別為:
| N | 初始狀態 |
| 1 | 14 13 15 7 11 12 9 5 6 0 2 1 4 8 10 3 |
| 2 | 13 5 4 10 9 12 8 14 2 3 7 1 0 15 11 6 |
| 3 | 14 7 8 2 13 11 10 4 9 12 5 0 3 6 1 15 |
| 4 | 5 12 10 7 15 11 14 0 8 2 1 13 3 4 9 6 |
| 5 | 7 6 8 1 11 5 14 10 3 4 9 13 15 2 0 12 |
| 6 | 15 2 12 11 14 13 9 5 1 3 8 7 0 10 6 4 |
注:每個初始狀態用數列表示,第一個代表最左上角格子,N1即為上方初始狀態例項的數列表示,0代表空格
2. 窮舉演算法:而所謂關於15-Puzzle的演算法,其目的無非就是用盡可能少的時間、嘗試儘可能少狀態,在解法存在的情況下,找到步數最少的最優解法。其中當然最簡單的即為窮舉法,我們由初始狀態出發,迭代嘗試所有可能的狀態,即窮舉出只移動一步可以達到的狀態、兩步可以達到的狀態...直到嘗試得到“最終狀態”,這裡的演算法可以嘗試廣度優先搜尋(Breath-first Search, BFS),以層(步數)為單位向外拓展搜尋直到達到最終狀態,實現既可以使用迭代也可以不使用,這裡就不詳細闡述了。窮舉演算法的複雜度相當之高(理論上最多會檢視1013個狀態,普通膝上型電腦可能會花費數十分鐘至數十小時來求解),在此由於時間關係我就沒有進行實驗,有興趣的朋友可以嘗試一下。
3. 最簡單的優化 - 不走回頭路:在最簡單的窮舉法中我們可以發現,在嘗試超過一步移動所達到的狀態時,程式常常會先將空格向左移(比如互換0和2),然後在下一步再將空格向右移(還是互換2和0),那這樣其實又回到了2步前的狀態,這樣子的兩步也有可能能解出答案,但並不是我們尋找最優解所需要的。所以為了避免這種“恢復原狀態的移動”的出現,我的做法是對於每個出現的狀態,記錄到達這個狀態所使用的移動方式(針對空格),比如當前狀態是由前一狀態將空格向右移產生的,表示狀態的資料結構中就會儲存“右移”的表示(比如一個巨集定義#define的數字),這樣在前往下一狀態時,程式只會去嘗試上、下、左三個方面的移動空格。由此一來,每一次的迭代從最多4種可能變為最多3種,時間複雜度進一步降低,但還是需要很多時間去窮舉,同樣由於時間限制我沒有進行實驗。
三、IDA*、啟發式演算法(曼哈頓距離)及DFS簡介
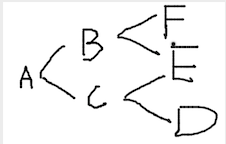
深度優先搜尋 (Depth-first Search, DFS) 是常用的圖演算法之一,假設圖由節點 (Node) 和連線節點的線段 (Edge) 構成,我們的目的是想從某一節點出發,通過一些線段到達另一個未知位置的節點,那麼DFS演算法會盡可能地深入地去搜索一條路徑,直到無法前往下一個沒有被訪問過的節點,然後才開始嘗試第二條路徑。如下圖所示,假設起點為A,目標點為F,向斜下方移動的優先順序高於向斜上方移動(在程式中具體表現為先向斜下方搜尋),那麼DFS會先向斜下方儘可能深入地去搜索,即嘗試ACD路線,在未找到目標節點時向上返回一步至C,向另一未搜過的方向即CE路徑嘗試,隨後再次返回C,由於C的子節點E,D都被搜尋過了,因此再向前返回至A,嘗試ABE路線,返回B嘗試BF路線,找到F返回成功搜尋。
曼哈頓距離在平面直角座標系中,並不是兩點之間的直線距離,而是兩點間X座標值之差和Y座標值之差的和,如下圖紅線和公式所示,左圖來源於百度:
直觀表示: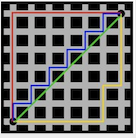 公式:
公式: 其中
其中 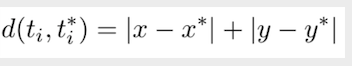
在15Puzzle問題中,曼哈頓主要用於估計當前狀態距離目標狀態的“距離”,也就是所需最少的移動步數,用來限制DFS搜尋的深度(不然DFS會沿著一條路徑一直搜尋下去,即使得到結果很有可能也不是最小步數),這裡的啟發距離是可容許的(admissible)的,即最終的實際最小距離會大於等於啟發距離。在所需移動步數較少時,往往兩者是相等的,在所需步數較多時,常常會出現較為複雜的移動,因此實際距離很可能會大於啟發距離,所以我們需要在啟發距離內無法找到目標的時候,更新增大距離,使得演算法往更深一層次搜尋,計算曼哈頓距離的核心程式碼如下:
int manhattan( int* state ) {
for (i = 0; i < NUM_STATES; i++) {
if (state[i]) {
sum += abs(state[i] / STATES_PERLINE - i / STATES_PERLINE) + abs(state[i] % STATES_PERLINE - i % STATES_PERLINE);
}
}
}
其中,sum為最後的曼哈頓距離返回值,state是包含全部方格的陣列,在15PUZZLE中NUM_STATES為16,STATES_PERLINE為4。
基於迭代加深的A*演算法 (IDA*) 是A* 演算法的優化,兩者雖然時間複雜度相似,但IDA* 採用深度優先搜尋(DFS)的策略,使得程式對記憶體空間的佔用由指數級增長降為線性增長 (程式使用記憶體與搜尋深度呈線性關係),大大減少了記憶體的使用。總的來說,IDA*演算法首先會根據一個啟發式方法(這裡我們採用曼哈頓距離),算出所謂的“啟發式評價” (即預估採用最優方案達到最終狀態所需要的步數),然後開始迴圈一定數量的DFS。每個DFS不僅會記錄其已經搜尋的深度(即距離初始狀態已移動的步數),還會在每移動一步到達一個新的狀態時,對該狀態重新計算“啟發式評價”得到屬於該狀態的評價步數。如果我們採用的是Admissible的啟發式評價演算法,那麼不難知道:
已搜尋的深度 + 當前啟發式評價步數 = 到達理想狀態所需的最小步數
若這個和大於最初的啟發式評價,我們便可以認為這個搜尋沒有必要再進行下去了,因為這個搜尋路徑的所需的最小步數已經高於我們預估的最佳方案了。所以,一個DFS終止的條件有二,一是它的已搜尋的深度與當前啟發式評價步數之和大於預估的步數了,二是它搜尋到了最終狀態,即找到了最優路徑。
當然,如上所述,預估的啟發式評價通常在最佳步數本身就比較少時比較準確,當需要完成的步數很多時,啟發式評價得到的預估步數往往會比真實值小上一些,這時候在預估步數的限制下,所有DFS都不會達到最終狀態。所以在所有DFS都進行完成但沒有最終狀態出現的時候,我們就需要更新總的預估步數,將步數增加使得DFS可以達到更深的深度。這裡更新預估步數值可以採用取之前一輪DFS中,所有超出預估步數的和 (已搜尋的深度+當前啟發式評價步數) 裡面,最小的那個值,這樣可以確保新的一輪DFS只會往更深的一層而不是多層去搜索。更新預估步數值後,即可開始新一輪的DFS,如此往復直到搜尋由於找到最終狀態而停止。
IDA* 核心程式碼主要由兩個部分構成,第一個部分為控制迴圈部分,該部分初始宮格、啟動啟發距離下的DFS,若未搜尋得到結果更新啟發距離再次啟動搜尋直到得到結果(因此這裡我們使用的所有測試都是有解得的,否則則會陷入死迴圈),其核心程式碼如下:
int IDA_control_loop( ){ /* compute initial threshold B */
initial_node.f = threshold = manhattan( initial_node.state );
while (!r) {
newThreshold = INT_MAX;
//assign initial node to n (注:程式碼中無該方法,為具體實現模組,省略原因只為簡潔起見)
init(&n, initial_node)//update threshold and recursively find path
r = ida(&n, threshold, &newThreshold);
//if can't find solution under current threshold, increase it and retry
if (!r) {
threshold = newThreshold;
}
}
}
其中,r是返回的節點,ida是DFS功能,若找到目標節點則返回該節點,否則返回null值,initial_node和n都是節點資料結構,包含state陣列(當前各方格內容)、f(當前節點的啟發評價)、a(前一節點到達該節點採用的移動)、g(距離初始狀態已走步數)。
第二個部分就是一個遞迴實現IDA*深度優先演算法的,每一次都會將空白方格與某個方向的臨近方格交換位置,得到更深一層的節點並更新相關記錄資料、重新計算啟發式評價。若評價大於初始評價 (遞迴開始前,在控制迴圈部分計算的評價),則不往更深的層次進行搜尋,退回上一層次並取消更新的資料,返回null值,值得注意的是,程式會記錄所有超出初始評價的值中的最小值,便於控制迴圈中的更新評價。若是評價小於初始評價,那麼程式就會往更深的一層遞迴搜尋,直到找到目標狀態並返回。核心程式碼如下:
node* ida(node* node, int threshold, int* newThreshold){
// check if reach end before moving
if (manhattan(node->state) == 0)
return node;
//for any action applicable in given state node->s
for (a = 0; a < 4; a++) {
//when the move is applicable and doesn't go back to previous state
if (applicable(a) && (a + node->a) % 4 != 1) {
apply(node, a);// pruning the node
if (node->f > threshold) {
*newThreshold = (*newThreshold < node->f ? *newThreshold : node->f);
// apply the oppsite movement of a to get back to parent node
reverse(node, a);
}
else {
if (manhattan(node->state) == 0)
return node;
// keep recursively generating
r = ida(node, threshold, newThreshold);
if (r) {
return r;
} else {
reverse(node, a);
}
}
}
}
return( NULL );
}
其中,a代表了四種空白方格的移動(上下左右),node為節點資料結構,applicable函式判斷該空白方格的移動方向是否可行 (全域性變數檢測空白格的位置,主要檢測不讓其移出邊界),apply函式對節點node執行某方向a的移動操作並返回新節點,newThreshold為記錄超出初始啟發式評價中的值的最小值,reverse函式對節點node執行a方向相反的移動,即返回上一層節點。
實驗結果:
採用上述6組隨機但必有解的初始狀態作為實驗,執行不走回頭路的IDA*深度優先演算法,我們可以得到:
| ID(N) | h(s0) | Threshold | Solution | Generated | Expanded | Time/sec | Expanded/Second |
| 1 | 41 | 41 43 45 47 49 51 53 55 57 | 57 | 499,911,606 | 253,079,560 | 17.81 | 14,211,627 |
| 2 | 43 | 43 45 47 49 51 53 55 | 55 | 18,983,862 | 9,777,810 | 0.71 | 13,751,593 |
| 3 | 41 | 41 43 45 47 49 51 53 55 57 59 | 59 | 455,125,298 | 229,658,354 | 16.09 | 14,276,552 |
| 4 | 42 | 42 44 46 48 50 52 54 56 | 56 | 82,631,583 | 41,689,053 | 3.14 | 13,260,319 |
| 5 | 41 | 41 43 45 47 49 51 53 55 57 59 | 59 | 937,956,626 | 475,109,930 | 35.09 | 13,540,551 |
| 6 | 43 | 43 45 47 49 51 53 55 57 59 61 63 65 | 65 | 6,195,467,140 | 3,176,234,868 | 218.86 | 14,512,743 |
其中, h(s0)代表了初始狀態的啟發式評價;Threshold代表了控制迴圈部分中啟發式評價更新的過程;Solution代表最終達到目標狀態所需的最少步數;Generated表示全過程產生的所有節點數量(包括重複計算的節點),如果用B+樹表示搜尋過程的話就是樹中所有的節點;Expanded表示全過程產生的、啟發式評價低於每輪迴圈初始評價的節點數量,在B+樹中就是所有的非葉節點;Time/sec就是在我個人電腦上執行演算法的時間;Expanded/Second代表了一個計算速率。
可以發現,對於這些較為複雜的不同例子,計算所進行的深度、廣度都會有很大差別,儘管他們可能有著相似的初始啟發式評價,在近似的計算速率下,有些例子僅需不到1秒就可以得到結果,而有些則需要接近四分鐘。
注:IDA* 和曼哈頓距離啟發是由Korf等於1985年第一次應用到15-Puzzle上的
四、補充
有關15或者24Puzzle的優化其實還有很多,我會在空餘時間繼續學習和理解,完成之後繼續分享到我的部落格上。
課程指導老師:Nir Lipovetzky([email protected]) 和 Grady Fitzpatrick([email protected])
五、相關連結:
程式碼github連結: https://github.com/Simon531/15Puzzle-Solver-C-IDAStar-DFS-Heuristic
本人郵箱:[email protected]
如有翻譯或理解有誤,或是程式碼不規範不簡潔的地方,還歡迎大家多多提出指正,謝謝!
2019年01月13日