
jeecms系統附件內容Lucene搜尋——二次開發
1 原有的針對文章的全文檢索方式
1.1文章提交
正常情況下,發表一篇文章時,點選“提交”的時候,如圖:
點選“提交”的時候是將文章所有欄位的資訊提交到後臺,其實就是將這篇文章對應的“內容模型”中的資料都提交到後臺了(“內容模型”的含義可以參考《jeecms系統使用介紹——jeecms中的內容、欄目、模型之間的關係》)。
這個過程比較重要的就是文章內容了,這裡是通過百度的ueditor編輯器編輯了內容,然後將其提交的,這部分內容正文的資料其實是儲存到了表:
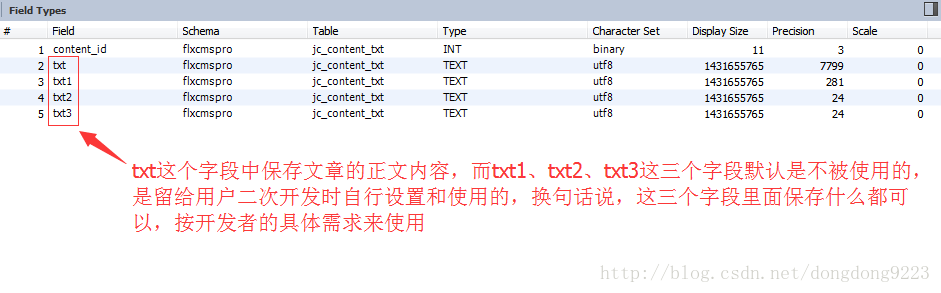
jc_content_txt- 1
的“txt”欄位之中,如圖:
而其它幾個欄位:
-
txt1 -
txt2 -
txt3
- 1
- 2
- 3
這些欄位中是沒有儲存內容的,它們是附加欄位,預設沒有被使用,留由使用者在二次開發時自行設定。這也為我們處理對附件檔案的全文檢索提供了可能。
文章內容的儲存是在包:
com.jeecms.cms.action.admin.main- 1
裡的類:
ContentAct- 1
-
@RequiresPermissions("content:o_save") -
@RequestMapping("/content/o_save.do") -
public String save(Content bean, ContentExt ext, ContentTxt txt, -
Boolean copyimg,Integer[] channelIds, Integer[] topicIds, -
Integer[] viewGroupIds, -
String[] attachmentPaths, String[] attachmentNames, -
String[] attachmentFilenames, String[] picPaths, String[] picDescs, -
Integer channelId, Integer typeId, String tagStr, Boolean draft, -
Integer cid, Integer modelId,Short charge,Double chargeAmount, -
Boolean rewardPattern,Double rewardRandomMin, -
Double rewardRandomMax,Double[] rewardFix, HttpServletRequest request,HttpServletResponse response, ModelMap model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.2 建立索引
文章在“ContentAct”類的“save”方法中儲存過程中,系統會單獨開啟一個執行緒,在類:
com.jeecms.cms.staticpage.ContentStatusChangeThread- 1
裡的方法:
public void run()- 1
中。逐層進入到類:
com.jeecms.cms.lucene.LuceneContent- 1
裡面的方法:
public static Document createDocument(Content c)- 1
在這個方法裡面,會把文章的相關資訊拿出來,包括文章的正文內容,存入Lucene索引裡面去。
2 對文章中上傳的附件進行全文檢索
2.1 實現思路
我們先來說一下實現的思路。有幾點我們是可以確認的:
-
1,在文章中上傳的附件是儲存在了伺服器的磁碟上,有一個磁碟路徑。
-
2,文章提交時,所有資訊都會傳給後臺伺服器。
-
3,後臺伺服器對文章內容有一個儲存的過程。
-
4,儲存過程中還會再單獨建一個執行緒,用來對文章內容建立索引。
那麼,根據我們的需求,要達到目的,我們完全可以這樣來實現:
-
1,在文章中上傳的附件時,將上傳到伺服器的附件路徑及檔名稱先在瀏覽器的前臺頁面儲存一下。
-
2,文章提交時,將附件路徑及名稱也傳遞到後臺伺服器。
-
3,在後臺伺服器儲存文章內容的過程中,將附件資訊也儲存一下,儲存到資料庫表“jc_content_txt”的欄位“txt1”裡面。這裡相當於使用了“txt1”這個預設欄位。
-
4,對文章內容建立索引時,除了對文章正文的html內容建立索引,還根據附件路徑及名稱,找到附件檔案並進行讀取,對這些附件的內容建立索引。
2.2 上傳時儲存附件路徑及名稱到文章頁面
編輯文章的頁面在:
{jeecms}/WebRoot/WEB-INF/jeecms_sys/content/add.html- 1
這個頁面,我們在其中加入一個區域,儲存上傳附件的伺服器路徑及其名稱。注意附件上傳並儲存到伺服器之後其名稱就變了,所以需要儲存一下。
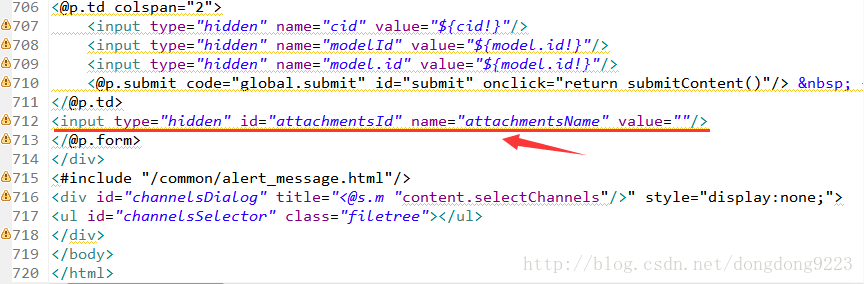
如圖所示“input”為新加入部分,“value”值會存放內容。每次上傳附件時會將資訊儲存的這個“input”的“value”裡面,那麼還要在上傳操作中加入儲存的方法。
在內容中上傳附件,如圖:
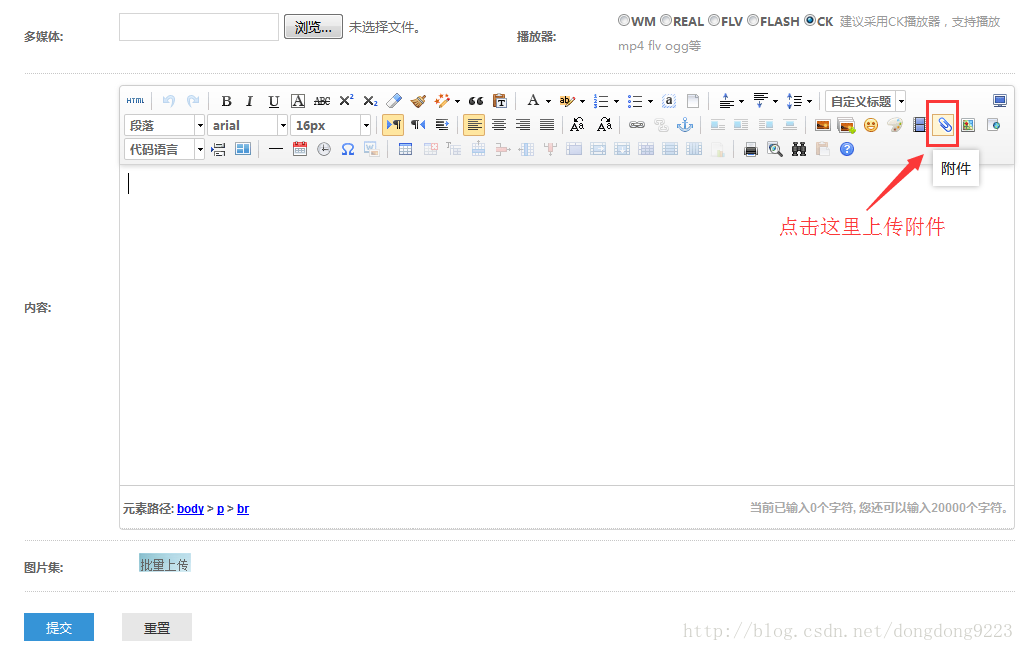
點選附件圖示,進入附件上傳介面,如圖:
先點選“點選選擇檔案”按鈕,選擇了附件,如圖:
然後點選“開始上傳”,這個過程會將檔案上傳到伺服器的磁碟檔案中。點選上傳時的操作在:
{jeecms}/WebRoot/thirdparty/ueditor/dialogs/attachment/attachment.js
中的方法:
uploader.on
裡面,這是百度“ueditor”編輯器,我們做些修改之後內容如下:
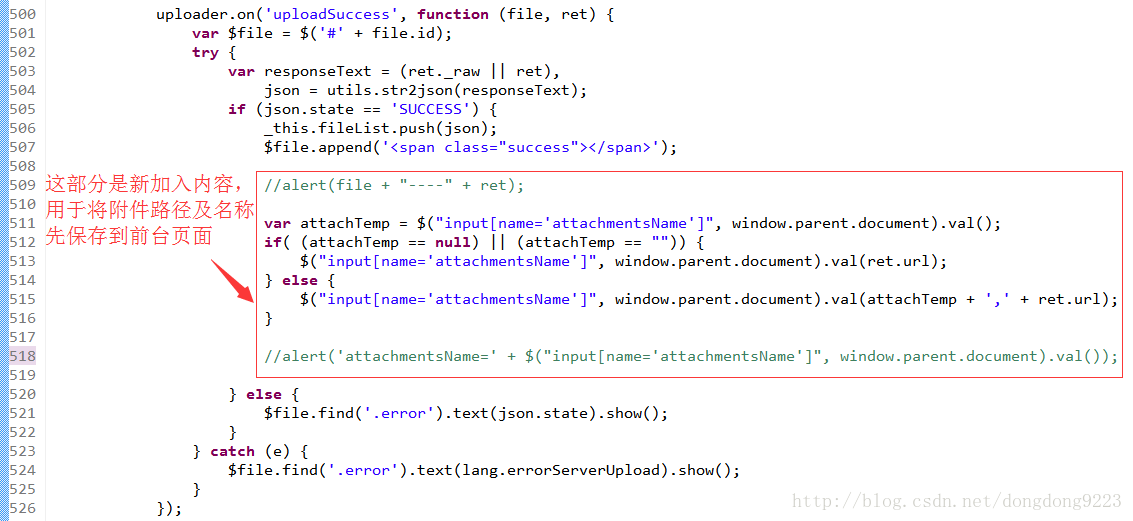
在原有內容裡,加入了每次上傳時先將所上傳的附件檔案的路徑及名稱儲存到前臺頁面的功能。詳細程式碼如下:
-
uploader.on('uploadSuccess', function (file, ret) { -
var $file = $('#' + file.id); -
try { -
var responseText = (ret._raw || ret), -
json = utils.str2json(responseText); -
if (json.state == 'SUCCESS') { -
_this.fileList.push(json); -
$file.append('<span class="success"></span>'); -
//alert(file + "----" + ret); -
var attachTemp = $("input[name='attachmentsName']", window.parent.document).val(); -
if( (attachTemp == null) || (attachTemp == "")) { -
$("input[name='attachmentsName']", window.parent.document).val(ret.url); -
} else { -
$("input[name='attachmentsName']", window.parent.document).val(attachTemp + ',' + ret.url); -
} -
//alert('attachmentsName=' + $("input[name='attachmentsName']", window.parent.document).val()); -
} else { -
$file.find('.error').text(json.state).show(); -
} -
} catch (e) { -
$file.find('.error').text(lang.errorServerUpload).show(); -
} -
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
可以把對alert的註釋刪除掉,然後看一下每次記錄的內容。這裡上傳三個檔案,看一下效果:
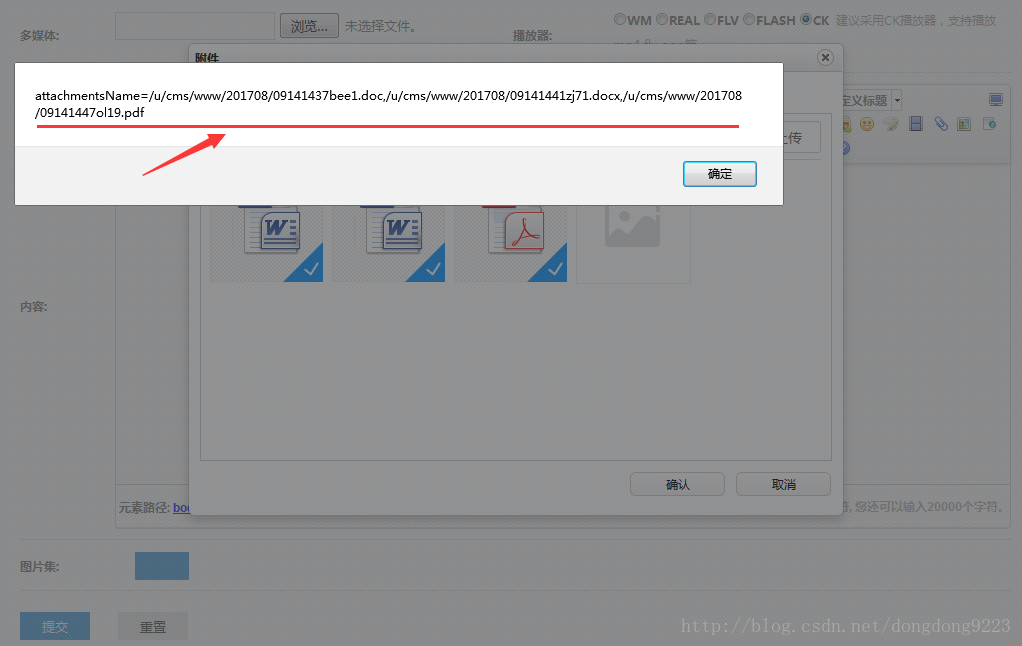
一個doc,一個docx,一個pdf,這3個上傳檔案的伺服器相對路徑及新名稱都得到了。
3 提交文章時將附件路徑傳到後臺
之前已經說了,點選了“提交”按鈕後,後臺對文章內容的儲存是在類:
com.jeecms.cms.action.admin.main.ContentAct- 1
的方法:
public String save- 1
中進行的,然後在對其建立索引。為了能夠對前臺傳過來的附件內容也能建立索引,要對“save”方法加點內容,如下:

4 對附件建立索引
萬事俱備,只欠東風。該得到的資訊都得到了,最後我就需要對上傳的附件建立索引了。之前講過建立索引是在類:
com.jeecms.cms.lucene.LuceneContent- 1
裡面的方法:
public static Document createDocument(Content c)- 1
進行的,這裡我們還在這裡面進行。
這裡面有一個預設處理模型項“txt1”的地方,如下:
-
if (!StringUtils.isBlank(c.getTxt1())) { -
doc.add(new Field(CONTENT1, c.getTxt1(), Field.Store.NO, -
Field.Index.ANALYZED)); -
}
- 1
- 2
- 3
- 4
我們對它進行修改,在這個區域裡面,將上傳的附件按照型別的不同分別建立索引,內容如下:
-
if (!StringUtils.isBlank(c.getTxt1())) { -
InputStream in = null; -
InputStreamReader reader = null; -
try { -
//讀取txt1中儲存的json串 -
JSONObject json = new JSONObject(c.getContentTxt().getTxt1()); -
//讀取json串中儲存的應用伺服器在作業系統上的絕對路徑 -
String realPath = json.getString("realPath"); -
//讀取json串中保村的上傳附件的相對路徑及名稱 -
String attachmentsNameArrays = json.getString("attachmentsNameArrays"); -
//得到索引檔案陣列 -
String []arr = attachmentsNameArrays.split(","); -
for (int j = 0; j < arr.length; j++) { -
//將要搜尋word檔案的地方 -
String dateDir = realPath + "\\" + arr[j]; -
//讀取當前這個附件檔案 -
File file = new File(dateDir); -
//輸出這個檔案是第幾個附件 -
System.out.println("j=" + j); -
//輸出這個檔案的路徑及名稱 -
System.out.println("file=" + file); -
//獲取檔名稱 -
String fileName = file.getName(); -
//獲取檔案字尾名 -
String fileType = fileName.substring(fileName.lastIndexOf(".") + 1, fileName.length()).toLowerCase(); -
//輸出檔名稱 -
System.out.println("fileName=" + fileName); -
//輸出檔名稱 -
System.out.println("fileType=" + fileType); -
//建立當前附件檔案的輸入流 -
in = new FileInputStream(file); -
//在當前附件檔案的字尾名不為空的情況下進行操作,建立索引的檔案包括doc、docx、pdf、txt -
if (fileType != null && !fileType.equals("")) { -
if (fileType.equals("doc")) { -
//建立斌儲存doc檔案索引 -
//讀取doc檔案 -
WordExtractor wordData = new WordExtractor(in); -
//建立Field物件,並放入lucene的document物件doc中 -
doc.add(new Field(CONTENT1, wordData.getText(), Field.Store.NO, -
Field.Index.ANALYZED)); -
//輸出當前操作的檔名稱 -
System.out.println("注意:已為檔案“" + fileName + "”建立了索引"); -
wordData.close(); -
} else if ( fileType.equals("docx")) { -
//建立斌儲存docx檔案索引 -
//讀取docx檔案 -
XWPFWordExtractor wordData = new XWPFWordExtractor(new XWPFDocument(in)); -
//建立Field物件,並放入lucene的document物件doc中 -
doc.add(new Field(CONTENT1, wordData.getText(), Field.Store.NO, -
Field.Index.ANALYZED)); -
//輸出當前操作的檔名稱 -
System.out.println("注意:已為檔案“" + fileName + "”建立了索引"); -
wordData.close(); -
}else if ( fileType.equals("pdf")) { -
//建立斌儲存pdf檔案索引 -
//讀取pdf檔案 -
PDFParser parser = new PDFParser(in); -
parser.parse(); -
PDDocument pdDocument = parser.getPDDocument(); -
PDFTextStripper stripper = new PDFTextStripper(); -
// String result = stripper.getText(pdDocument); -
//建立Field物件,並放入lucene的document物件doc中 -
doc.add(new Field(CONTENT1, stripper.getText(pdDocument), Field.Store.NO, -
Field.Index.ANALYZED)); -
//輸出當前操作的檔名稱 -
System.out.println("注意:已為檔案“" + fileName + "”建立了索引"); -
pdDocument.close(); -
} else if ( fileType.equals("txt") ) { -
//建立斌儲存txt檔案索引 -
//讀取txt檔案 -
//建立一個輸入流物件reader -
reader = new InputStreamReader(in); -
//建立一個物件,它把檔案內容轉成計算機能讀懂的語言 -
BufferedReader br = new BufferedReader(reader); -
String wordData = ""; -
String line = null; -
//一次讀入一行資料 -
while ((line = br.readLine()) != null) { -
wordData += line; -
} -
//建立Field物件,並放入lucene的document物件doc中 -
doc.add(new Field(CONTENT1, wordData, Field.Store.NO, -
Field.Index.ANALYZED)); -
//輸出當前操作的檔名稱 -
System.out.println("注意:已為檔案“" + fileName + "”建立了索引"); -
} else { -
} -
} -
} -
} catch (JSONException e) { -
e.printStackTrace(); -
} catch (FileNotFoundException e) { -
e.printStackTrace(); -
} catch (IOException e) { -
e.printStackTrace(); -
} finally { -
if (in != null) { -
try { -
in.close(); -
} catch (IOException e) { -
e.printStackTrace(); -
} -
} -
if (reader != null) { -
try { -
reader.close(); -
} catch (IOException e) { -
e.printStackTrace(); -
} -
} -
} -
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
這裡面對doc、docx、pdf、txt幾種型別的檔案分別建立了索引,具體的呼叫方式可以參考《使用Lucene對doc、docx、pdf、txt文件進行全文檢索功能的實現》這篇文章,此處就不贅述了。
5 搜尋
至此,功能事先就完成了。我們新建一篇文章,上傳一個附件進去。然後搜尋一個只在附件中才出現過的內容,進行搜尋。比如新建一篇文章,如圖:
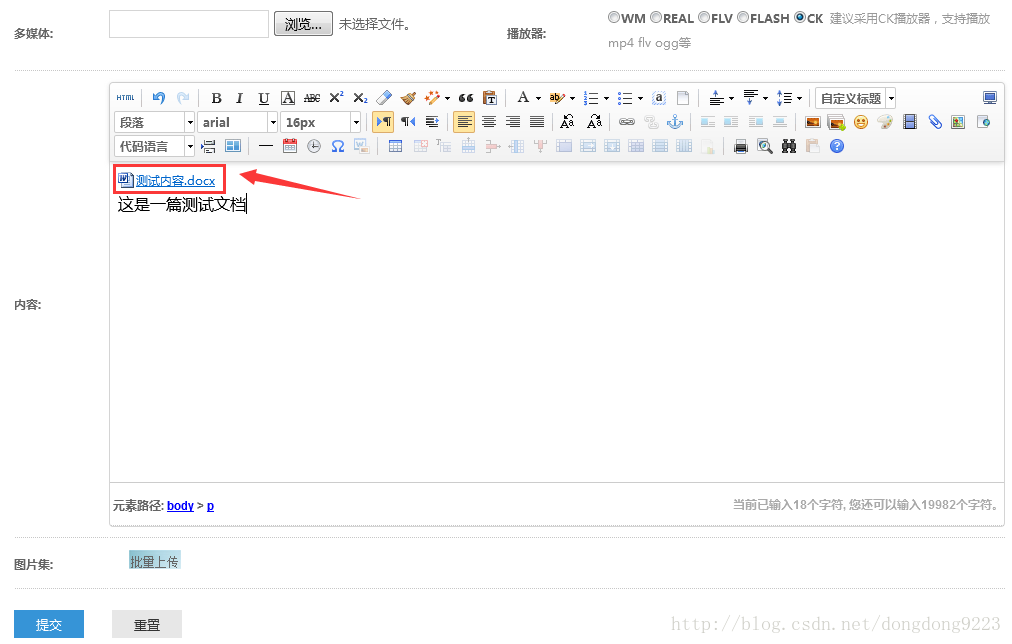
裡面上傳了一個附件,內容為:
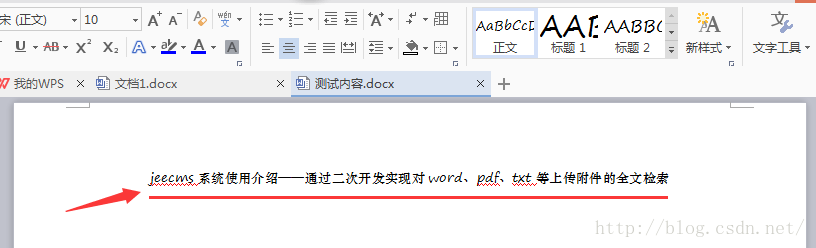
裡面的內容很簡單。現在我們在前臺頁面上搜索“上傳附件”這幾個漢字,比如輸入“使用介紹”,如圖:
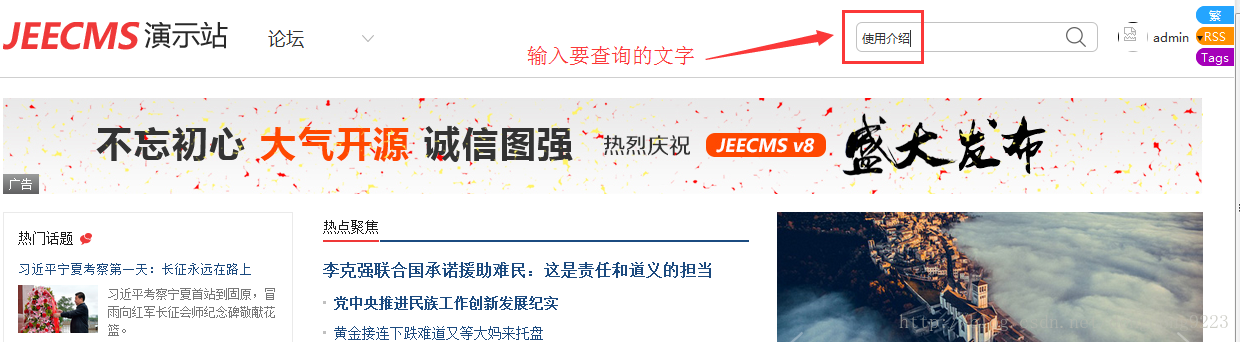
然後點選鍵盤迴車或滑鼠點選右側的搜尋按鈕,得到搜尋結果如下:
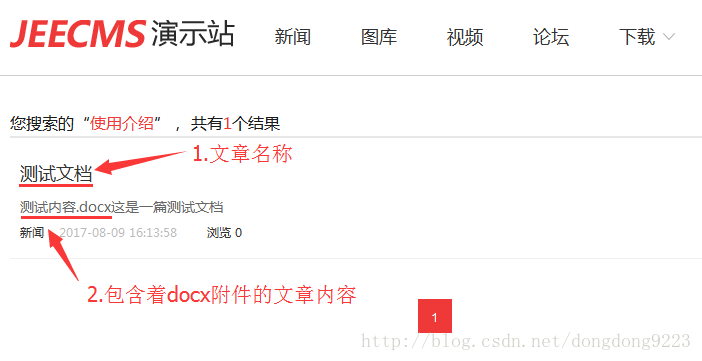
能夠看到,文章的正文內容裡直接看是沒有“使用介紹”這幾個字的,但搜尋這幾個字還是把這篇文章搜了出來,說明我們建立的索引生效了。