
理解 OpenStack 高可用(HA)(1):OpenStack 高可用和災備方案 [OpenStack HA and DR]
本系列會分析OpenStack 的高可用性(HA)概念和解決方案:
1. 基礎知識
1.1 高可用 (High Availability,簡稱 HA)
高可用性是指提供在本地系統單個元件故障情況下,能繼續訪問應用的能力,無論這個故障是業務流程、物理設施、IT軟/硬體的故障。最好的可用性, 就是你的一臺機器宕機了,但是使用你的服務的使用者完全感覺不到。你的機器宕機了,在該機器上執行的服務肯定得做故障切換(failover),切換有兩個維度的成本:RTO (Recovery Time Objective)和 RPO(Recovery Point Objective)。RTO 是服務恢復的時間,最佳的情況是 0,這意味著服務立即恢復;最壞是無窮大意味著服務永遠恢復不了;RPO 是切換時向前恢復的資料的時間長度,0 意味著使用同步的資料,大於 0 意味著有資料丟失,比如 ” RPO = 1 天“ 意味著恢復時使用一天前的資料,那麼一天之內的資料就丟失了。因此,恢復的最佳結果是 RTO = RPO = 0,但是這個太理想,或者要實現的話成本太高,全球估計 Visa 等少數幾個公司能實現,或者幾乎實現。
對 HA 來說,往往使用共享儲存,這樣的話,RPO =0 ;同時往往使用 Active/Active (雙活叢集) HA 模式來使得 RTO 幾乎0,如果使用 Active/Passive 模式的 HA 的話,則需要將 RTO 減少到最小限度。HA 的計算公式是[ 1 - (宕機時間)/(宕機時間 + 執行時間)],我們常常用幾個 9 表示可用性:
- 2 個9:99% = 1% * 365 = 3.65 * 24 小時/年 = 87.6 小時/年的宕機時間
- 4 個9: 99.99% = 0.01% * 365 * 24 * 60 = 52.56 分鐘/年
- 5 個9:99.999% = 0.001% * 365 = 5.265 分鐘/年的宕機時間,也就意味著每次停機時間在一到兩分鐘。
- 11 個 9:幾乎就是幾年才宕機幾分鐘。 據說 AWS S3 的設計高可用性就是 11 個 9。
1.1.1 服務的分類
HA 將服務分為兩類:
- 有狀態服務:後續對服務的請求依賴於之前對服務的請求。
- 無狀態服務:對服務的請求之間沒有依賴關係,是完全獨立的。
1.1.2 HA 的種類
HA 需要使用冗餘的伺服器組成叢集來執行負載,包括應用和服務。這種冗餘性也可以將 HA 分為兩類:
- Active/Passive HA:叢集只包括兩個節點簡稱主備。在這種配置下,系統採用主和備用機器來提供服務,系統只在主裝置上提供服務。在主裝置故障時,備裝置上的服務被啟動來替代主裝置提供的服務。典型地,可以採用 CRM 軟體比如 Pacemaker 來控制主備裝置之間的切換,並提供一個虛機 IP 來提供服務。
- Active/Active HA:叢集只包括兩個節點時簡稱雙活,包括多節點時成為多主(Multi-master)。在這種配置下,系統在叢集內所有伺服器上運行同樣的負載。以資料庫為例,對一個例項的更新,會被同步到所有例項上。這種配置下往往採用負載均衡軟體比如 HAProxy 來提供服務的虛擬 IP。
1.1.3 雲環境的 HA
雲環境包括一個廣泛的系統,包括硬體基礎設施、IaaS層、虛機和應用。以 OpenStack 云為例:

雲環境的 HA 將包括:
- 應用的 HA
- 虛機的 HA
- 雲控制服務的 HA
- 物理IT層:包括網路裝置比如交換機和路由器,儲存裝置等
- 基礎設施,比如電力、空調和防火設施等
本文的重點是討論 OpenStack 作為 IaaS 的 HA。
1.2 災難恢復 (Disaster Recovery)
幾個概念:
- 災難(Disaster)是由於人為或自然的原因,造成一個數據中心內的資訊系統執行嚴重故障或癱瘓,使資訊系統支援的業務功能停頓或服務水平不可接受、達到特定的時間的突發性事件,通常導致資訊系統需要切換到備用場地執行。
- 災難恢復(Diaster Recovery)是指當災難破壞生產中心時在不同地點的資料中心內恢復資料、應用或者業務的能力。
- 容災是指,除了生產站點以外,使用者另外建立的冗餘站點,當災難發生,生產站點受到破壞時,冗餘站點可以接管使用者正常的業務,達到業務不間斷的目的。為了達到更高的可用性,許多使用者甚至建立多個冗餘站點。
- 衡量容災系統有兩個主要指標:RPO(Recovery Point Objective)和 RTO(Recovery Time Object),其中 RPO代表 了當災難發生時允許丟失的資料量,而 RTO 則代表了系統恢復的時間。RPO 與 RTO 越小,系統的可用性就越高,當然使用者需要的投資也越大。

大體上講,容災可以分為3個級別:資料級別、應用級別以及業務級別。
| 級別 | 定義 | RTO | CTO |
| 資料級 |
指通過建立異地容災中心,做資料的遠端備份,在災難發生之後要確保原有的資料不會丟失或者遭到破壞。但在資料級容災這個級別,發生災難時應用是會中斷的。 在資料級容災方式下,所建立的異地容災中心可以簡單地把它理解成一個遠端的資料備份中心。資料級容災的恢復時間比較長,但是相比其他容災級別來講它的費用比較低,而且構建實施也相對簡單。 但是,“資料來源是一切關鍵性業務系統的生命源泉”,因此資料級容災必不可少。 |
RTO 最長(若干天) ,因為災難發生時,需要重新部署機器,利用備份資料恢復業務。 | 最低 |
| 應用級 | 在資料級容災的基礎之上,在備份站點同樣構建一套相同的應用系統,通過同步或非同步複製技術,這樣可以保證關鍵應用在允許的時間範圍內恢復執行,儘可能減少災難帶來的損失,讓使用者基本感受不到災難的發生,這樣就使系統所提供的服務是完整的、可靠的和安全的。 | RTO 中等(若干小時) | 中等。異地可以搭建一樣的系統,或者小些的系統。 |
| 業務級 | 全業務的災備,除了必要的 IT 相關技術,還要求具備全部的基礎設施。其大部分內容是非IT系統(如電話、辦公地點等),當大災難發生後,原有的辦公場所都會受到破壞,除了資料和應用的恢復,更需要一個備份的工作場所能夠正常的開展業務。 | RTO 最小(若干分鐘或者秒) | 最高 |
1.3 HA 和 DR 的關係
兩者相互關聯,互相補充,互有交叉,同時又有顯著的區別:
- HA 往往指本地的高可用系統,表示在多個伺服器執行一個或多種應用的情況下,應確保任意伺服器出現任何故障時,其執行的應用不能中斷,應用程式和系統應能迅速切換到其它伺服器上執行,即本地系統叢集和熱備份。HA 往往是用共享儲存,因此往往不會有資料丟失(RPO = 0),更多的是切換時間長度考慮即 RTO。
- DR 是指異地(同城或者異地)的高可用系統,表示在災害發生時,資料、應用以及業務的恢復能力。異地災備的資料災備部分是使用資料複製,根據使用的不同資料複製技術(同步、非同步、Strectched Cluster 等),資料往往有損失導致 RPO >0;而異地的應用切換往往需要更長的時間,這樣 RT0 >0。 因此,需要結合特定的業務需求,來定製所需要的 RTO 和 RPO,以實現最優的 CTO。
也可以從別的角度上看待兩者的區別:
- 從故障角度,HA 主要處理單元件的故障導致負載在叢集內的伺服器之間的切換,DR 則是應對大規模的故障導致負載在資料中心之間做切換。
- 從網路角度,LAN 尺度的任務是 HA 的範疇,WAN 尺度的任務是 DR 的範圍。
- 從雲的角度看,HA 是一個雲環境內保障業務持續性的機制,DR 是多個雲環境間保障業務持續性的機制。
- 從目標角度,HA 主要是保證業務高可用,DR 是保證資料可靠的基礎上的業務可用。
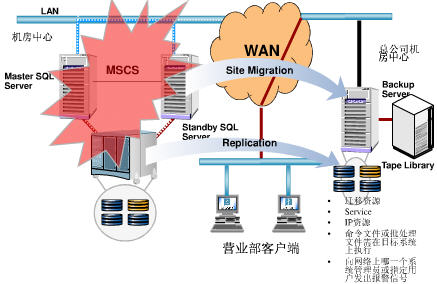
一個異地容災系統,往往包括本地的 HA 叢集和異地的 DR 資料中心。一個示例如下(來源:百度文庫):
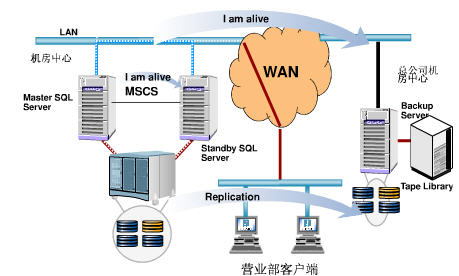
Master SQL Server 發生故障時,切換到 Standby SQL Server,繼續提供資料庫服務:

在主機房中心發生災難時,切換到備份機房(總公司機房中心)上,恢復應用和服務:
2. OpenStack HA
OpenStack 部署環境中,各節點可以分為幾類:
- Cloud Controller Node (雲控制節點):安裝各種 API 服務和內部工作元件(worker process)。同時,往往將共享的 DB 和 MQ 安裝在該節點上。
- Neutron Controller Node (網路控制節點):安裝 Neutron L3 Agent,L2 Agent,LBaas,VPNaas,FWaas,Metadata Agent 等 Neutron 元件。
- Storage Controller Node (儲存控制節點):安裝 Cinder volume 以及 Swift 元件。
- Compute node (計算節點):安裝 Nova-compute 和 Neutron L2 Agent,在該節點上建立虛機。
要實現 OpenStack HA,一個最基本的要求是這些節點都是冗餘的。根據每個節點上部署的軟體特點和要求,每個節點可以採用不同的 HA 模式。但是,選擇 HA 模式有個基本的原則:
- 能 A/A 儘量 A/A,不能的話則 A/P (RedHat 認為 A/P HA 是 No HA)
- 有原生(內在實現的)HA方案儘量選用原生方案,沒有的話則使用額外的HA 軟體比如 Pacemaker 等
- 需要考慮負載均衡
- 方案儘可能簡單,不要太複雜
OpenStack 官方認為,在滿足其 HA 要求的情況下,可以實現 IaaS 的 99.99% HA,但是,這不包括單個客戶機的 HA。
2.1 雲控制節點 HA
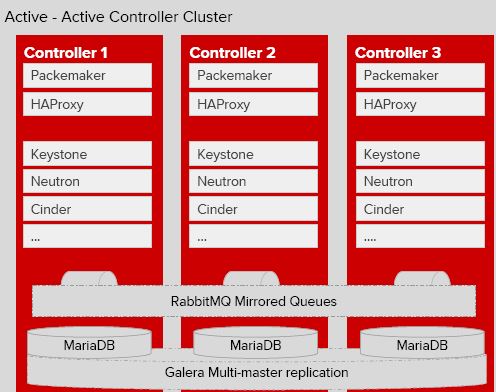
雲控制節點上執行的服務中,API 服務和內部工作元件都是無狀態的,因此很容易就可以實現 A/A HA;這樣就要求 Mysql 和 RabbitMQ 也實現 A/A HA,而它們各自都有 A/A 方案。但是,Mysql Gelera 方案要求三臺伺服器。如果只想用兩臺伺服器的話,則只能實現 A/P HA,或者引入一個 Arbiter 來做 A/A HA。
2.1.1 雲控制節點的 A/A HA 方案
該方案至少需要三臺伺服器。以 RDO 提供的案例為例,它由三臺機器搭建成一個 Pacemaker A/A叢集,在該叢集的每個節點上執行:
- API 服務:包括 *-api, neutron-server,glance-registry, nova-novncproxy,keystone,httpd 等。由 HAProxy 提供負載均衡,將請求按照一定的演算法轉到某個節點上的 API 服務。由 Pacemaker 提供 VIP。
- 內部元件:包括 *-scheduler,nova-conductor,nova-cert 等。它們都是無狀態的,因此可以在多個節點上部署,它們會使用 HA 的 MQ 和 DB。
- RabbitMQ:跨三個節點部署 RabbitMQ 叢集和映象訊息佇列。可以使用 HAProxy 提供負載均衡,或者將 RabbitMQ host list 配置給 OpenStack 元件(使用 rabbit_hosts 和 rabbit_ha_queues 配置項)。
- MariaDB:跨三個階段部署 Gelera MariaDB 多主複製叢集。由 HAProxy 提供負載均衡。
- HAProxy:向 API,RabbitMQ 和 MariaDB 多活服務提供負載均衡,其自身由 Pacemaker 實現 A/P HA,提供 VIP,某一時刻只由一個HAProxy提供服務。在部署中,也可以部署單獨的 HAProxy 叢集。
- Memcached:它原生支援 A/A,只需要在 OpenStack 中配置它所有節點的名稱即可,比如,memcached_servers = controller1:11211,controller2:11211。當 controller1:11211 失效時,OpenStack 元件會自動使用controller2:11211。
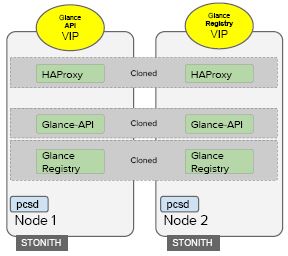
從每個 API 服務來看:


關於共享 DB 的幾個說明 (主要來自 這篇文章):
(1)根據該文章中的一個調查,被調查的 220 多個使用者中,200 個在用 Mysql Galera,20 多個在用單 Mysql,只有一個用 PostgreSQL。
(2)以 Nova 為例,Mysql 使用 機制來保證多個連線同時訪問資料庫中的同一條記錄時的互斥。以給新建虛機分配 IP 地址為例,該鎖機制保證了一個 IP 不會分給兩個使用者。
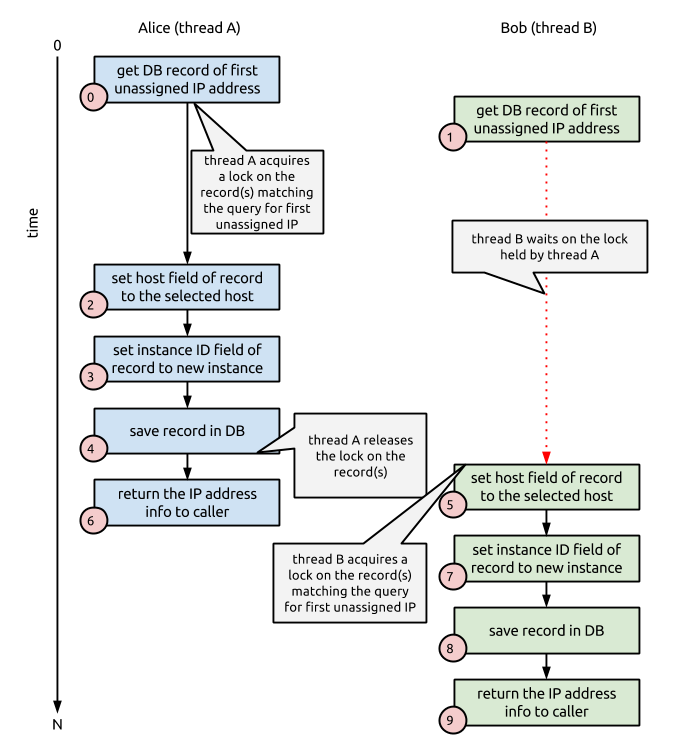
(3)使用 Mysql Galera 時,所有節點都是 Master 節點,都可以接受服務,但是這裡有個問題,Mysql Galera 不會複製 Write-intent locks。兩個使用者可以在不同節點上獲取到同一條記錄,但是隻有一個能夠修改成功,另一個會得到一個 Deadlock 錯誤。對於這種情況,Nova 使用 retry_on_deadlock 機制來重試,比如@oslo_db_api.wrap_db_retry(max_retries=5, retry_on_deadlock=True)。預設都是重試 5 次。但是,這種機制效率不高,文章作者提供了一種新的機制。
該 HA 方案具有以下優點:
- 多主,零切換,方便地實現負載均衡
- 將 API 服務和 DB, MQ 服務無縫整合在一起
2.1.2 雲控制節點的 A/P HA方案
需要的話,可以使用 Pacemaker + Corosync 搭建兩節點叢集實現 A/P HA 方案。由主伺服器實際提供服務,在其故障時由 Pacemaker 將服務切換到被伺服器。OpenStack 給其元件提供了各種Pacemaker RA。對 Mysql 和 RabbitMQ 來說,可以使用 Pacemaker + Corosync + DRBD 實現 A/P HA。具體請參考 理解 OpenStack 高可用(HA)(4):RabbitMQ 和 Mysql HA。具體配置請參考 OpenStack High Availability Guide。
該 HA 方案的問題是:
- 主備切換需要較長的時間
- 只有主提供服務,在使用兩個節點的情況下不能做負載均衡
- DRBD 腦裂會導致資料丟失的風險。A/P 模式的 Mysql 的可靠性沒有 Mysql Galera 高。
因此,可以看到實際部署中,這種方案用得較少,只看到 Oracel 在使用這種方案。
2.2 Neutron HA
Neutron 包括很多的元件,比如 L3 Agent,L2 Agent,LBaas,VPNaas,FWaas,Metadata Agent 等 Neutron 元件,其中部分元件提供了原生的HA 支援。這些元件之間的聯絡和區別:

2.2.1 原生 HA 方案
Neutron 提供了多種原生的 HA 方案:
(1)L2 Agent HA: L2 agent 只在所在的網路或者計算節點上提供服務,因此它是不需要HA的。
(2)L3 Agent HA
L3 Agent 比較特殊,因為它是所有 openstack (core)services 中唯一一個有狀態的,因此,不能使用傳統的在多個節點上部署多個例項使用LB來做HA。Neutron 本身的排程器(scheduler)支援在多個網路節點上部署多個L3 Agent,但是,由 L3 Agent 管理的 Virtual Router 自身需要有HA的實現。它的HA的Neutron 原生實現包括如下幾種方式:
(a)Juno 中引入的 Automatic L3 Agent Failover (當 VR 所在的 L3 Agent 失效的時候,Neutron 自動將它 failover 到其它某個 L3 Agent 上)
該方案增加了一個配置項 allow_automatic_l3agent_failover。當它的值為 True 時,L3 plugin 去週期性地檢查所有有管理 Virtual Router 的 L3 Agent 的狀態。如果某 L3 Agent 死了,受它管理的 Router 會重新被 schedule 到別的 L3 Agent 上。 Neutron L3 Plugin 通過判斷該 L3 Agent 是否在規定時間(agent_down_time)內有發回心跳訊息來判斷它是否活著。存在多種 L3 Agent 未能及時上報心跳但是 router 依然在轉發網路包的可能。因此這種實現可能會存在 L3 Agent 被認為死了但是其 router namespace 依然在轉發網路包和響應 ARP 請求而導致的問題。如果網路後端不阻止死掉了的 agent 使用 route 的 IP 地址,那新老 namespace 就可能存在衝突。這種衝突不會斷掉 E-W 網路,因為新老 namespace 中的一個都可以承擔無狀態網路包的轉發任務。然後,南-北網路可能會受影響,因為 NAT 只存在於一個router 上。而且,reschedule 後,浮動 IP 也會無法工作,因為它們與 router 的 外部埠的繫結關係不會被設定到新的router 上。
這種方案要求使用多個網路控制節點,每個節點上執行一個 L3 Agent。在某個 Agent 死了時,Router 會被部署到別的 Agent 上。這種方案,除了上述的問題外,切換時間過長是其主要問題。
(b)Juno 中引入的 VRRP (Virtual Router Redundancy Protocol)方案 (由 VRRP/Keepalived 控制 VR 的 VIP 和 VMAC 的 failover)

(c)Juno 引入的 DVR
該方案將 NAT 和 L3 Agent 部署到虛機所在的計算節點,在網路控制節點上只部署 DHCP 和 SNAT。該方案解決了 L3 Agent 和 Metadata Agent 的 H/A 問題。目前,將 DHCP Agent 改成分散式,VPNaas 以及 FWaas 的修改工作已經在進行中。使用者需要使用第三方軟體提供 SNAT 的 HA 方案。可以參考 理解 OpenStack 高可用(HA)(3):Neutron 分散式虛擬路由(Neutron Distributed Virtual Routing)。
(3)DHCP Agent 的 HA
DHCP 協議自身就支援多個 DHCP 伺服器,因此,只需要在多個網絡卡控制節點上,通過修改配置,為每個租戶網路建立多個 DHCP Agent,就能實現 DHCP 的 HA 了。
(4)Metadata agent 和 proxy 的 HA
跟 metadata service 相關的元件包括:
- neutron-ns-metadata-proxy:作為一個獨立的程序執行在 master virtual router 的 network namespace 中。它接受由 qrouter 通過 iptables 控制轉交的 instance 訪問 metadata service 的 request。
- neutron-metadata-agent:Neutorn 的元件之一,執行在Neutorn 網路節點上,通過本地 socket 和 neutron-ns-metadata-proxy 程序通訊,其配置檔案是 /etc/neutron/metadata_agent.ini;它會通過 http(s) 和 Nova metadata service 通訊;它通過 RPC 和 neutron-server 通訊。你還可以通過配置 metadata_workers 的值來執行多個獨立的程序。
- nova metadata api:這個和 nova api 類似,是 nova 的 API 的一部分,通常使用的埠是 8775。它接收neutron-metadata-agent 的request。
從 HA 角度來講:
- neutron-ns-metadata-proxy 的 HA 不需要單獨考慮,因為它受 Virtual router 控制。
- neutron-metadata-agent:需要和 neutron-ns-metadata-proxy 通過soket 通訊,因此,簡單地,可以在所有 neutron network 節點上都執行該 agent,只有 virtual router 所在的L3 Agent 上的 neutron-metadata-agent 才起作用,別的都standby。你可以在多個網路節點上啟用該服務。
- nova metadata api:同 nova api 一樣是無狀態服務,可以部署在那個階段上,使用 HAProxy 做 A/A HA。
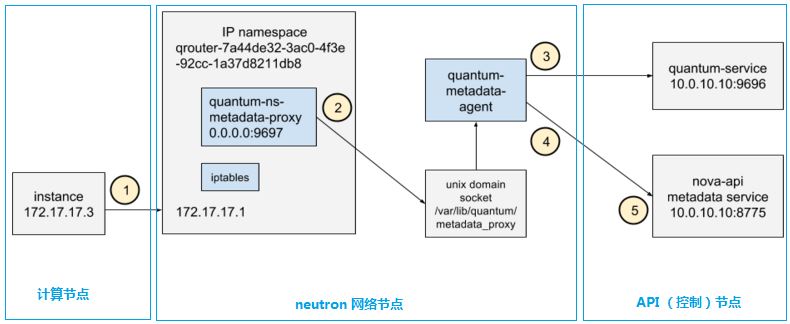
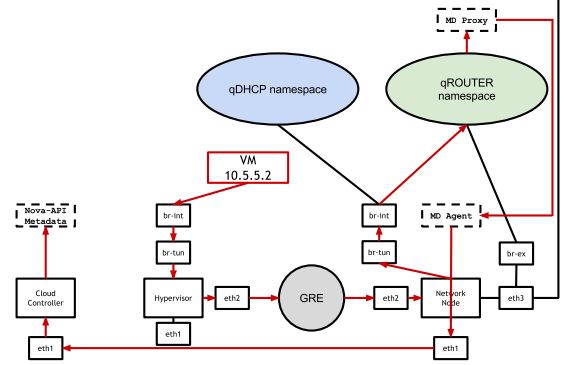
(注意,因為虛機在啟動過程中需要訪問 qrouter,這也就是說,要求虛機所在的子網必須已經新增到了一個 Virtual router 上,否則,它是無法通過 qrouter 走的,除非走 qdhcp)
或者更詳細地看出完整的路徑(圖中紅色線條,從VM開始,到 NOVA-API Metadata 結束):
(5)LBaas Agent HA
目前 Neutron LBaaS 代理服務是無法通過其自帶的 HAProxy 外掛 實現高可用的。實現 HAProxy 高可用常見的方案是使用 VRRP (Virtual Router Redundancy Protocol ,虛擬路由冗餘協議),不過 LBaaS HAProxy 外掛目前還不支援該協議。因此,只能使用 Pacemaker + 共享儲存(放置 /var/lib/neutron/lbaas/ 目錄) 的方式來部署 A/P 方式的 LBaas Agent HA,具體請參考 這篇文章 中描述的方法。
2.2.2 使用 Pacemaker 實現 A/P HA
使用 Pacemaker + Corosync 搭建兩節點(或者多節點) A/P 叢集。在主節點上,由 Pacemaker 啟動 Neutron 的各種服務。
2.2.3 小結
從上面可以看出,除了 DHCP Agent 天生就通過配置可以實現 A/A HA 以及 L3 HA 以外,其它的元件的 HA 都是 A/P 的,而且實現的技術可以是原生的,也可以使用 Pacemaker,也可以結合起來使用。比如 RDO 的方案:
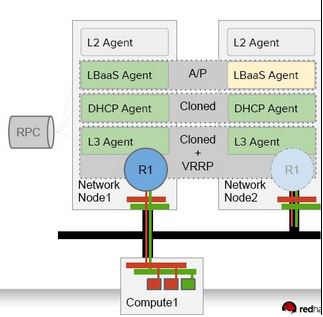
2.3 儲存控制節點 HA
這裡只討論 cinder-volume。
(1)在使用非共享儲存時,cinder-volume 程序受 Pacemaker 監控,在其停止的時候重啟。這種方案下,儲存控制節點宕機的話,上面的所有卷都會損失掉。因此,在生產環境中,必須使用下一種方案。
(2)在使用共享儲存時,考慮到目前程式碼中存在的資源競爭(參考這裡),該服務只能實現為 A/P HA 方式,也就是說在某個時刻,只有主節點上的 cinder-volume 在執行。RedHat 這個 ticket 中有具體的分析。目前,cinder-volume 還沒有內在的 HA 實現,只能藉助第三方軟體比如 Pacemaker。A/A 的實現在 Liberty 中正在進行,請 參見 和 這個。
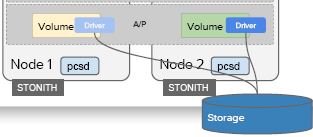
2.4 計算節點和虛機 HA
在測試環境中,我們常常將虛機建立在本地磁碟上,那麼,在機器宕機的話,這些虛機將永遠也回不來了。因此,在生產環境中,需要將虛機部署在 cinder-volume 或者共享的儲存比如 RDB 或者 NFS 上。這樣的話,在虛機損壞時,可以從共享儲存上將其恢復(使用 nova evacuate 功能)。 使用 Pacemaker 部署 A/P 方案(類似 2.3 中 cinder-volume A/P HA)的話,生產環境中計算節點的資料往往遠遠超過 Corosync 叢集中節點數目的限制。
業界有幾個解決方案:
(1)Controller 節點通過管理網 Ping 所有 Compute 節點,Controller 節點檢查nova service-list,對出問題的節點 Evacuate
特徵:太簡單粗暴,容易引起誤殺和資料損壞
(2)Pacemaker-remote: 突破Corosync的叢集規模限制,
特徵:啟用多個心跳網時,處理策略單一,引起使用者業務不必要的中斷
(3)集中式檢查

(4)分散式健康檢查

(以上資料來自 基於Fuel的超融合一體機 by 周徵晟 / 2015-06-27)
OpenStack 的各提供商中,就該需求,RadHat 使用的是上述的第二種方案,具體方案在 計算節點HA 方案:
部署方式如下:
- 使用 Pacemaker 叢集作為控制平面
- 將計算節點做為 Partial members 加入到 Pacemaker 叢集中,受其管理和監控。這時候,其數目不受 Corosync 叢集內節點總數的限制。
HA 實現細節:
- Pacemaker 通過 pacemaker_remote 按照順序(neutron-ovs-agent -> ceilometer-compute -> nova-compute) 來啟動計算節點上的各種服務。前面的服務啟動失敗,後面的服務不會被啟動。
- Pacemaker 監控和每個計算節點上的 pacemaker_remote 的連線,來檢查該節點是否處於活動狀態。發現它不可以連線的話,啟動恢復(recovery)過程。
- Pacemaker 監控每個服務的狀態,如果狀態失效,該服務會被重啟。重啟失敗則觸發防護行為(fencing action);當所有服務都被啟動後,虛機的網路會被恢復,因此,網路只會短時間受影響。
當一個節點失效時,恢復(recovery)過程會被觸發,Pacemaker 會依次:
- 執行 'nova service-disable'
- 將該節點關機
- 等待 nova 發現該節點失效了
- 將該節點開機
- 如果節點啟動成功,執行 'nova service-enable'
- 如果節點啟動失敗,則執行 ‘nova evacuate’ 把該節點上的虛機移到別的可用計算節點上。
其中:
- 步驟(1)和 (5)是可選的,其主要目的是防止 nova-scheduler 將新的虛機分配到該節點。
- 步驟(2)保證機器肯定會關機。
- 步驟(3)中目前 nova 需要等待一段較長的超時時間才能判斷節點 down 了。Liberty 中有個 Blueprint 來新增一個 Nova API 將節點狀態直接設定為 down。
其餘一些前提條件:
- 虛機必須部署在 cinder-volume 或者共享的臨時儲存比如 RBD 或者 NFS 上,這樣虛機 evaculation 將不會造成資料丟失。
- 如果虛機不使用共享儲存,則必須週期性地建立虛機的快照並儲存到 Glance 中。在虛機損壞後,可以從 Glance 快照上恢復。但是,這可能會導致狀態或者資料丟失。
- 控制和計算節點需要安裝 RHEL 7.1+
- 計算節點需要有防護機制,比如 IPMI,硬體狗 等
小結: OpenStack 雲/網路/儲存 控制節點 HA 叢集
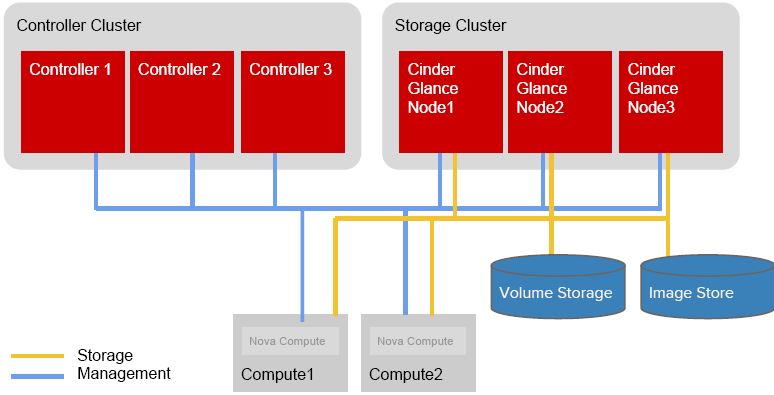

3. 部分 OpenStack 方案提供者的 HA 方案
3.1 RDO HA
這裡 有完整的 RDO HA 部署方案:
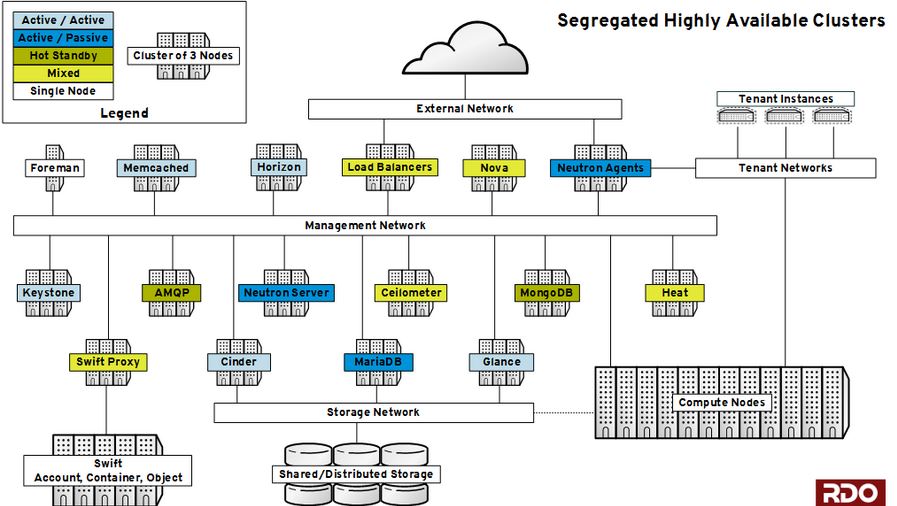
該配置最少需要五臺機器:
- 一臺(物理或者虛擬)伺服器部署 nfs server,dhcp,dns
- 一臺物理伺服器來作為計算節點
- 三臺物理伺服器組成 pacemaker 叢集,建立多個虛機,安裝各種應用
特徵:
- 每個叢集使用三個節點,全部採用 A/A 模式,除了 cinder-volume 和 LBaas。RedHat 不認為 A/P 模式是真正的 HA。
- 提供使用 Pacemaker 或者 Keepalived 兩套方案。
- 將 API 和內部無狀態元件按功能組分佈到各個專有叢集,而不是放在一個叢集上。
- Cinder 這裡標識為 A/A HA,但是不包括 cinder-volume。
- 計算節點 HA 使用 2.4 部分描述的 HA 方式。
| Service | Process | Mode | HA stragegy |
|---|---|---|---|
| Support services | MariaDB - Galera | A/A | HAProxy / app cluster |
| Support services | RabbitMQ | A/A | App cluster / service config |
| Support services | HAProxy | A/A | Keepalived |
| Support services | MongoDB | A/A | App cluster (ceilometer 和 heat 會使用) |
| Support services | Memcached | A/A | Service configuration |
| Keystone | openstack-keystone | A/A | HAProxy |
| Glance | openstack-glance-api | A/A | HAProxy |
| Glance | openstack-glance-registry | A/A | HAProxy (向 glance-api 提供 REST API) |
| Nova | openstack-nova-api | A/A | HAProxy |
| Nova | openstack-nova-cert | A/A | |
| Nova | openstack-nova-compute | A/A | 參見 2.4 部分描述 |
| Nova | openstack-nova-scheduler | A/A | |
| Nova | openstack-nova-conductor | A/A | |
| Nova | openstack-nova-novncproxy | A/A | HAProxy |
| Cinder | openstack-cinder-api | A/A | HAProxy |
| Cinder | openstack-cinder-scheduler | A/A | |
| Cinder | openstack-cinder-volume | A/P | No HA (RH 不把 A/P HA 當作HA!)。參考這裡 |
| Cinder | openstack-cinder-backup | A/A | |
| Neutron | neutron-server | A/A | HAProxy |
| Neutron | neutron-dhcp-agent | A/A | Multiple DHCP agents |
| Neutron | neutron-l3-agent | A/A | L3 HA |
| Neutron | neutron-metadata-agent | A/A | |
| Neutron | neutron-lbaas-agent | A/P | 目前的設計不允許 A/A |
| Neutron | neutron-openvswitch-agent | A/A | |
| Neutron | neutron-metering-agent | A/A | |
| Horizon | httpd | A/A | HAProxy |
| Ceilometer | openstack-ceilometer-api | A/A | HAProxy |
| Ceilometer | openstack-ceilometer-central | A/A | Workload partitioning: tooz + Redis |
| Ceilometer | openstack-ceilometer-compute | A/A | |
| Ceilometer | openstack-ceilometer-alarm-notifier | A/A | |
| Ceilometer | openstack-ceilometer-evaluator | A/A | |
| Ceilometer | openstack-ceilometer-notification | A/A | |
| Heat | openstack-heat-api | A/A | HAProxy |
關於 MariaDB:
- 它是資料庫管理系統 MySQL 的一個分支,主要由開源社群在維護,採用 GPL 授權許可。開發這個分支的原因之一是:甲骨文公司收購了 MySQL 後,有將 MySQL 閉源的潛在風險,因此社群採用分支的方式來避開這個風險。
- MariaDB 的目的是完全相容MySQL,包括 API 和命令列,使之能輕鬆成為 MySQL 的代替品。除了作為一個Mysql的“向下替代品”,MariaDB包括的一些新特性使它優於MySQL。這篇文章 有 Mysql 和 MariaDB 對比分析。
不由得贊一下 RDO 的文件!想起來之前去拜訪一個 OpenStack 初創公司,CTO 說他們基本上是參考 RDO 做方案,看起來是很有道理的。
3.2 Mirantis OpenStack 6.0 HA 方案:A/A 方案
Mirantis 推薦在生產環境中使用帶至少三個控制節點的 HA:
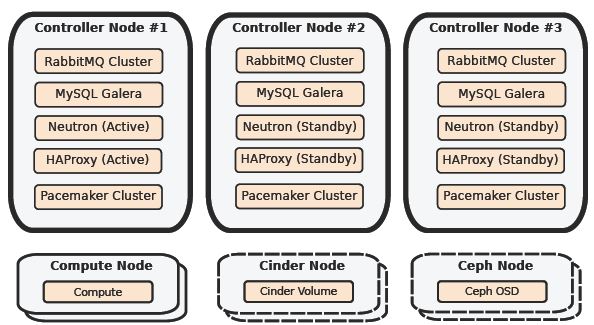
其中:
- 使用 Pacemaker 控制 Neutron Agent,實現 A/P HA
- API 服務執行在多個節點上,使用 HAProxy 實現負載均衡,提供 VIP
- RabbitMQ A/A
- Mysql A/A
各 HA 元件之間的關係:
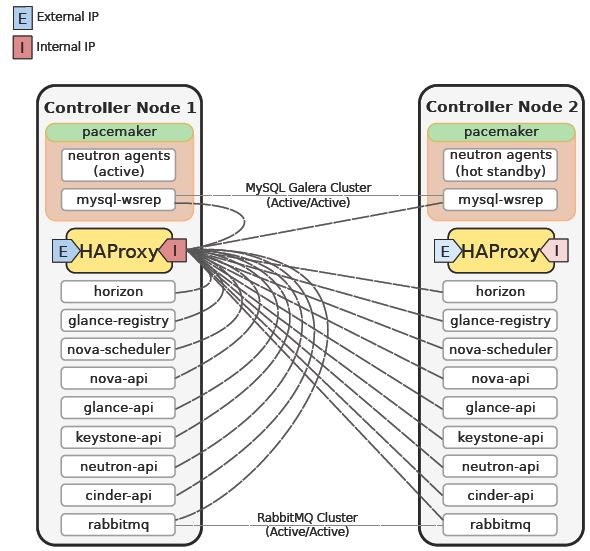
各元件被呼叫的方式:
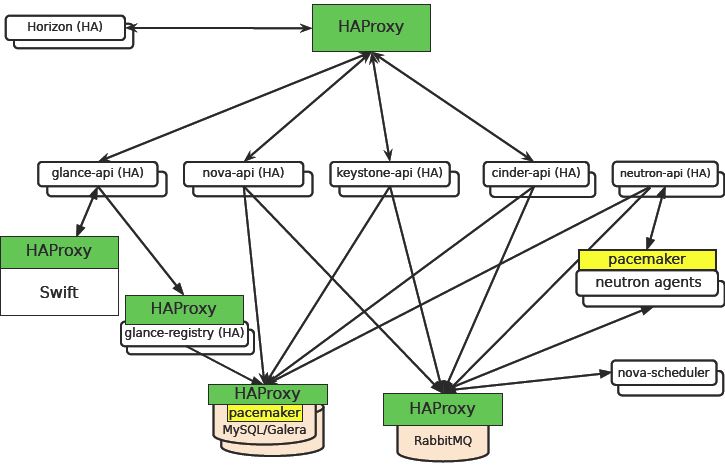
點評:與 RDO 方案一樣,該 HA 也是一個徹底的 HA 方案,消除了整個系統的 SPOF。但是,與 RDO 相比分散式控制節點相比,Mirantis 的集中式控制節點上執行的服務較多,可能會影響其效能,但是在小規模雲環境中節省了硬體成本。
3.3 HP Helion 的 HA 方案:A/A方案
系統組成:(兩節點 HAProxy + Keepalived 叢集) + 第三個控制節點 +(RabbitMQ Cluster + Queue 映象)+(Galera + Mysql)
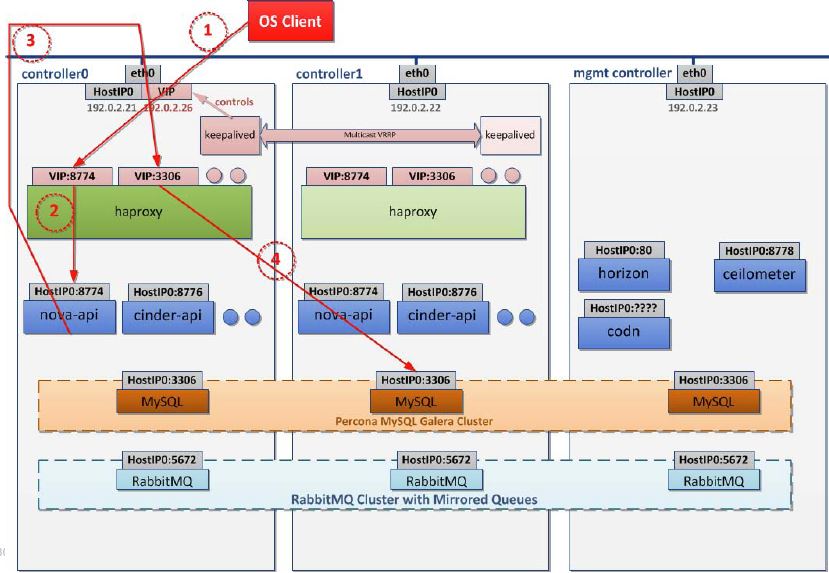
- OpenStack 客戶端通過 VIP:8774 訪問 nova-api
- HAProxy 將請求轉到 controller 0 上的 nova-api
- nova-api 通過 VIP:3306 訪問 Mysql DB
- HAProxy 將請求轉到 controller 1 上的 Mysql 例項
點評:HP 的 A/A 方案是不徹底的,甚至是有些怪異(為什麼不三個控制節點做一個A/A 叢集呢?),因為至少 Horizon、 Ceilomter 和 Neutron Agents 沒有實現 HA,它只實現了 API,DB 和 MQ 的 HA。
3.4 TCP Cloud OpenStack HA

特徵:
- 系統組成:Pacemaker, Corosync, HAProxy, Galera + IBM 硬體比如 Storwize V7000
- 使用三階段叢集 A/A 叢集
- 提供 99.99% 的服務可靠性
- 沒看到虛機 HA
來源:TCP 官網
3.5 Paypal OpenStack 生產系統 HA
特徵:
- 使用硬體負載均衡 F5
- 使用商業 SDN
- 使用 Monit 監控和重啟各服務
- 使用 Pacemaker
- 用在生成系統,優化進行中
3.6 Oracel OpenStack HA:A/P HA
CRM:Oracel Clusterware(Oracle Grid Infrastructure Release 12c Release 1 or later)
組成:兩個控制節點 + 兩個網路節點組成的叢集。除了網路節點上的元件外,別的元件都部署在控制節點上。
 (來源)
(來源)
結論:該方案比不上前面幾個公司的方案,因為:
- 只提供兩節點 A/P 方案,可靠性和 CTO 比不上三節點方案
- 需要使用共享儲存比如 NFS 來實現 A/P HA 模式的 DB 和 MQ,容易腦裂
- 不使用免費的 Pacemaker,部署成本增加。
3.7 網易 OpenStack 雲的 HA 方案
好不容易找到一個國內公司的方案,來源在 這裡:
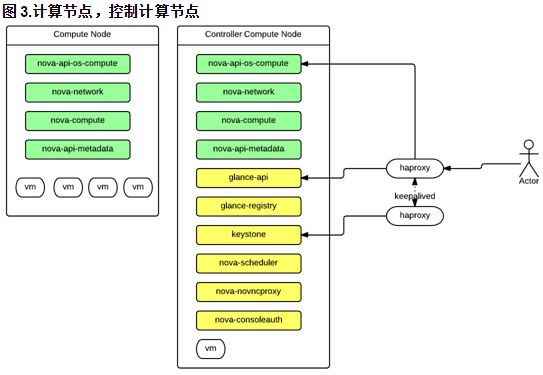
特徵:
- 使用 keepalived 管理的 HAProxy
- 控制節點應該是 A/A HA 方案
- 沒有看到計算節點和網路控制節點的 HA 方案,似乎沒有用 neutron,而是用 nova-network
- 高可用 RabbitMQ 叢集和主備 MySQL,以及 memcache 叢集是額外部署的
3.5 小結
- RDO > Mirantis > HP >> Oracel
- HA 是生產環境中的部署必須有的
- HA 模式方面,A/A HA 方案為主流
- 資料庫方面,Mysql Galera 為主流
- MQ 方面,RabbitMQ 叢集 + 映象訊息佇列為主流
- CRM 方面,Pacemaker 三節點叢集是主流
- 負載均衡方面,HAProxy 是主流
- 網路方面,Neutron 新的 HA 方案包括 VRRP 和 DVR 還未成熟,尚未真正進入生產環境 (2016/10: RedHat OpenStack platform 從Kilo版本就已經正式支援 VRRP,這意味著它已經成熟;但是DVR依然處於 tech preview 狀態)
- 儲存方面,OpenStack 需要解決 cinder-volume 的 A/A 實現
- 計算方面,OpenStack 需要原生的虛機 HA 實現
2016/10/23 一些更新:
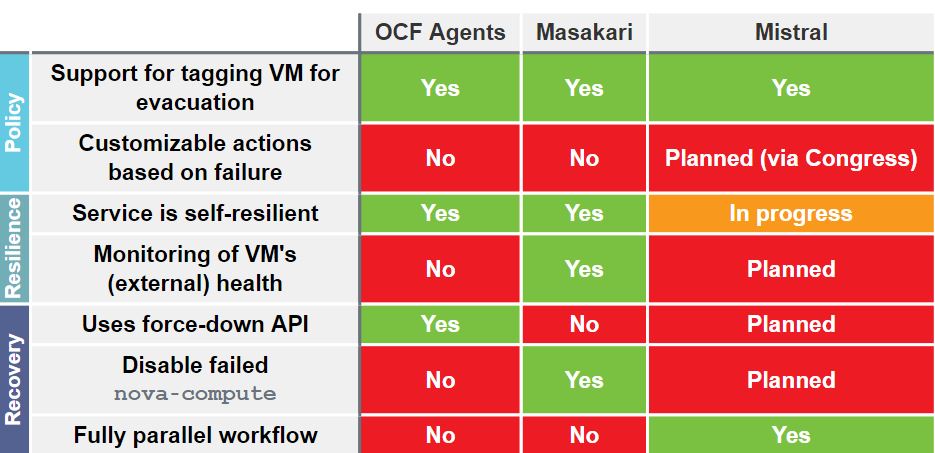
這些方案之間的對比:
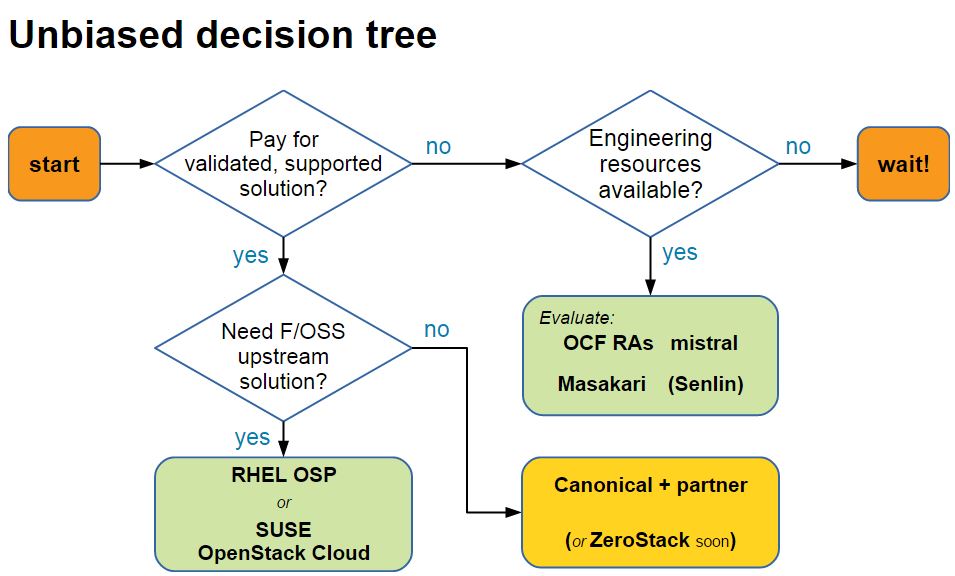
選擇樹:
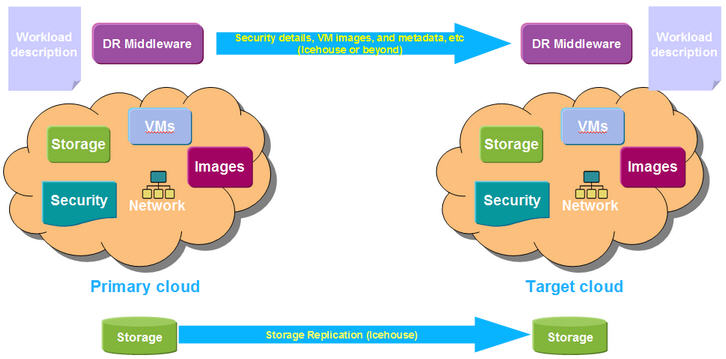
4. OpenStack DR
狀態:
- 目前沒有詳細的方案,只有一個概要設計,還處於 Gap 識別和補齊階段。
- 具體的實現主要集中在cinder 側元資料(Juno IBM 實現了部分的 Volume Replication 功能)、業務資料同步相關,但是目前進展不樂觀。
參考連結和文件:
- deepdiveintohighlyavailableopenstackarchitecture-openstacksummitvancouver2015-150520154718-lva1-app6891.pdf
- RDO 官網
- OpenStack 官網
- Mirantis-OpenStack-6.0-ReferenceArchitecture (1).pdf
歡迎大家關注我的個人公眾號:

相關推薦
理解 OpenStack 高可用(HA)(1):OpenStack 高可用和災備方案 [OpenStack HA and DR]
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: 1. 基礎知識 1.1 高可用 (High Availability,簡稱 HA) 高可用性是指提供在本地系統單個元件故障情況下,能繼續訪問應用的能力,無論這個故障是業務流程、物理設施、IT軟/硬體的
OpenStack 高可用和災備方案(下)
3. 部分 OpenStack 方案提供者的 HA 方案 3.1 RDO HA 這裡 有完整的 RDO HA 部署方案: 該配置最少需要五臺機器: 一臺(物理或者虛擬)伺服器部署 nfs server,dhcp,dns一臺物理伺服器來作為計算節點三臺物理伺服器組成 pac
linux 安裝hadoop 的四大執行模式——HA高可用分佈模式(版本2.9.1)
hadoop的HA高可用配置:hadoop的名稱節點部署在不同的伺服器上(簡單理解),具體定義請自行查詢 備註:簡述過程如果前面步驟按步驟進行,後續的步驟就不做詳細解釋 準備:建立h105作為高可用的名稱節點(namenode),一般會再建議一個數據節點(及配置4個數據節點,兩個名稱節點),
走入計算機的第四十天(數據庫1)
數據庫表 sql creat images character def 計算 rst sqlit 一 什麽是數據庫 數據庫故名思意就是存放數據的地方,是指長期存儲在計算機內有組織可以共享的數據的集合。 數據庫的數據按照一定的數學模型組織,描述和儲存的,具有較小的
弱題(循環矩陣1)
submit 操作 多少 sub nbsp 要求 printf cheng 輸出 問題 D: 弱題 時間限制: 1 Sec 內存限制: 128 MB提交: 46 解決: 28[提交][狀態][討論版] 題目描述 有M個球,一開始每個球均有一個初始標號,標號範圍為1~
(6)第1部分:C++基礎的尾巴~
區別 nbsp 自己 字符串處理函數 處理 com bsp 操作 串處理 這篇文章有問題!!!待改 2.6.3編寫自己的頭文件P67中提到:“庫類型string在名為string的頭文件中定義。又如,我們應該把Sales_data類定義在名為Sales_data.h的頭
(基礎篇)第1課:C#程序設計基礎——動起來的Label控件
創建 文本編輯器 ble 知識 項目 pac too cli 雙擊 參考:學通C#的24堂課(羊皮卷系列) 1. Tool:VS2017(VS2008 VS2010 都可以) 2. 新建項目:C# -> Windows應用窗體程序 3. 在彈出的Form窗口中添加L
異步社區本周(3.26-4.1)半價電子書
C語言 VR Python 點擊關註 異步圖書,置頂公眾號每天與你分享 IT好書 技術幹貨 職場知識 《精通Python自然語言處理》Iti Mathur, Nisheeth Joshi, 【印度】Deepti Chopra 著點擊封面購買紙書自然語言處理(NLP)是有關計算語言學與人工智能的研究
不同版本(2.3-3.1)web.xml文件的schema頭部聲明
xml1. Servlet 3.1Java EE 7 XML schema,命名空間是 http://xmlns.jcp.org/xml/ns/javaee<?xml version="1.0" encoding="UTF-8"?> <web-ap
理解高可用和災備
其他 進行 帶來 有一個 16px 包括 提供服務 復數 備份 1.高可用 (High Availability,簡稱 HA) 高可用性是指提供在本地系統單個組件故障情況下,能繼續訪問應用的能力,無論這個故障是業務流程、物理設施、IT軟/硬件的故障。最好的可用性, 就是你的
多線程(二)啟動線程:需要傳參和不需要傳參兩種情況
void ise tel 線程 reg val adl 方法 委托 1、不需要傳參: class Program7 { private static void ExecuteInForeground() {
C++檔案輸入和輸出(C++學習筆記 1)
為了開啟一個檔案供輸入或輸出,標頭檔案需要包括 #include<iostream> 和#include<fstream> iostream庫除了支援終端輸入輸出,也支援檔案的輸入和輸出。 1. 開啟一個輸出檔案 必須宣告一個ofstream型別的物件,來
總想自己動動手系列·3·如何讓微信公眾號和外網服務交互之通過TOKEN驗證(準備篇·1)
utf-8 url new 加密 token alt oct ans 官方 一、準備工作 (1)準備一個微信公眾號(對私的訂閱號或者對公的服務號)。 (2)準備一臺部署了web應用,並且已經發布出去的Linux服務器(需要說明的是:微信公眾號強烈建議使用80端口,使用其他自
Windows 64位下安裝php的redis擴充套件(php7.2+redis3.1)
近來因為php環境升級到php7.x,所以也對redis進行了升級 1下載redis3.0 : https://github.com/MSOpenTech/redis/releases 2 將下載的檔案解壓到電腦中(D:\redis),安裝完成。 3 開啟redis
Error:1045, "Access denied for user 'root'@'localhost' (using password: YES) (Phon3.6+Mysql8.1 )
哇,鬧了一個大烏龍,昨天,寫了個指令碼給之前移植的mysql新增資料,結果一個小問題困了我0.75天。 指令碼程式碼如下:(期間有個小插曲,我把port=“3306”,報錯了,但是很快排查到,去除可雙引號) from pymysql import cursors, connect #
React成長路之踩坑路:react-router4路由傳參(@react-router4.3.1)
在[email protected]中傳參有三種方式 一、通過params傳參: 1、在路由表中: <Route path="/search/:type/:keyword?" component={Search} /> 2、Link處使用: <Li
Go 語言的下一個大版本:Go 2.0 被安排上了(全面兼容1.X,改進錯誤處理和泛型這兩大主題)
.org leader utf8 驅動 cleanup 周期 一份 早期 下一個 今年 8 月 Go 開發團隊公布了 Go 2.0 的設計草案,包括錯誤處理和泛型這兩大主題。現在備受矚目的 Go 2.0 又有了新動向 —— 昨日 Go 開發團隊在其官
22(多執行緒1)
1 多執行緒 2 多執行緒的原理 3 並行和併發的區別 4 java是多執行緒嗎 5 多執行緒的實現方式一(繼承Thread) 6 多執行緒的實現方式二(實現Runnable) 7 兩種方式的區別 8 匿名內部類實現執行
qt glut 和 qt opengl (qt 5.11.1) 超詳細的qt opengl環境搭建
作者: 飛劍神 網址:www.feijianshen.com 郵箱: [email protected] 本人:百度雲:wrzfeijianshen 本部落格共開下載部落格和其中用到的工具連結地址: 課件在這裡哦: https://github.com/wrzfe
POJ 3278 Catch That Cow(Pu1 2018.10.1)
演算法:bfs 難度:NOIP- 題意:從N走到K, 開始輸入N,K。 有三種移動方法:1、向前走一步,耗時一分鐘。