
scala篩選460億條記錄的hive表
- 背景:
接到任務,需要在一個一天資料量在460億條記錄的hive表中,篩選出某些host為特定的值時才解析該條記錄的http_content中的經緯度:
解析規則譬如:
| 1 2 3 4 |
需要解析host:
api.map.baidu.com
需要解析的規則:"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},
"confidence":25
需要解析http_conent:renderReverse&&renderReverse({"status":0,"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},"formatted_address":"???????????????????????????????????????","business":"","addressComponent":{"country":"??????","country_code":0,"province":"?????????","city":"?????????","district":"?????????","adcode":"330104","street":"????????????","street_number":"","direction":"","distance":""},"pois":[{"addr":"????????????5277???","cp":"
","direction":"???","distance":"68","name":"????????????????????????????????????","poiType":"????????????","point":{"x":120.25084961536486,"y":30.3112150 |
- Scala程式碼實現“訪問hive,並儲存結果到hive表”的spark任務:
開發工具為IDEA16,開發語言為scala,開發包有了spark對應叢集版本下的很多個jar包,和對應叢集版本下的很多個jar包,引入jar包:
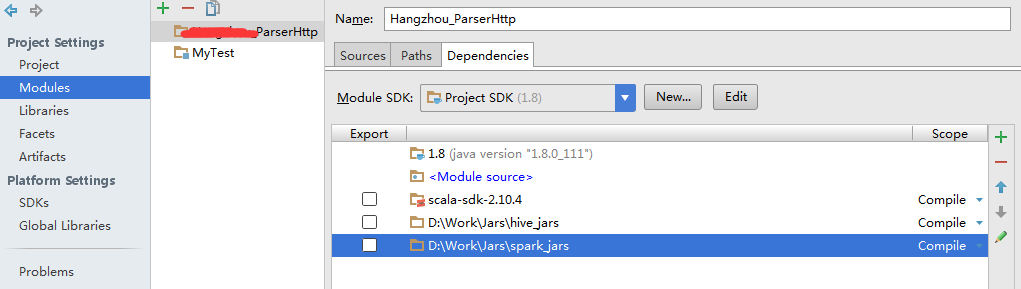
scala程式碼:

import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp} import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.hive.HiveContextimport java.util import java.util.{UUID, Calendar, Properties} import org.apache.spark.rdd.JdbcRDD import org.apache.spark.sql.{Row, SaveMode, SQLContext} import org.apache.spark.storage.StorageLevel import org.apache.spark.{sql, SparkContext, SparkConf} import org.apache.spark.sql.DataFrameHolder/** * temp http_content **/ case class Temp_Http_Content_ParserResult(success: String, lnglatType: String, longitude: String, Latitude: String, radius: String) /** * Created by Administrator on 2016/11/15. */ object ParserMain { def main(args: Array[String]): Unit = { val conf = new SparkConf() //.setAppName("XXX_ParserHttp").setMaster("local[1]").setMaster("spark://172.21.7.10:7077").setJars(List("xxx.jar")) //.set("spark.executor.memory", "10g") val sc = new SparkContext(conf) val hiveContext = new HiveContext(sc) // use abc_hive_db; hiveContext.sql("use abc_hive_db") // error date format:2016-11-15,date format must be 20161115 val rdd = hiveContext.sql("select host,http_content from default.http where hour>='20161115' and hour<'20161116'") // toDF() method need this line... import hiveContext.implicits._ // (success, lnglatType, longitude, latitude, radius) val rdd2 = rdd.map(s => parse_http_context(s.getAs[String]("host"), s.getAs[String]("http_content"))).filter(s => s._1).map(s => Temp_Http_Content_ParserResult(s._1.toString(), s._2, s._3, s._4, s._5)).toDF() rdd2.registerTempTable("Temp_Http_Content_ParserResult_20161115") hiveContext.sql("create table Temp_Http_Content_ParserResult20161115 as select * from Temp_Http_Content_ParserResult_20161115") sc.stop() } /** * @ summary: 解析http_context欄位資訊 * @ param http_context 引數資訊 * @ result 1:是否匹配成功; * @ result 2:匹配出的是什麼經緯度的格式: * @ result 3:經度; * @ result 4:緯度, * @ result 5:radius **/ def parse_http_context(host: String, http_context: String): (Boolean, String, String, String, String) = { if (host == null || http_context == null) { return (false, "", "", "", "") } // val result2 = parse_http_context(“api.map.baidu.com”,"renderReverse&&renderReverse({\"status\":0,\"result\":{\"location\":{\"lng\":120.25088311933617,\"lat\":30.310684375444877},\"formatted_address\":\"???????????????????????????????????????\",\"business\":\"\",\"addressComponent\":{\"country\":\"??????\",\"country_code\":0,\"province\":\"?????????\",\"city\":\"?????????\",\"district\":\"?????????\",\"adcode\":\"330104\",\"street\":\"????????????\",\"street_number\":\"\",\"direction\":\"\",\"distance\":\"\"},\"pois\":[{\"addr\":\"????????????5277???\",\"cp\":\" \",\"direction\":\"???\",\"distance\":\"68\",\"name\":\"????????????????????????????????????\",\"poiType\":\"????????????\",\"point\":{\"x\":120.25084961536486,\"y\":30.3112150") // println(result2._1 + ":" + result2._2 + ":" + result2._3 + ":" + result2._4 + ":" + result2._5) var success = false var lnglatType = "" var longitude = "" var latitude = "" var radius = "" var lowerCaseHost = host.toLowerCase().trim(); val lowerCaseHttp_Content = http_context.toLowerCase() // api.map.baidu.com // "result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877}, // "confidence":25 // --renderReverse&&renderReverse({"status":0,"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},"formatted_address":"???????????????????????????????????????","business":"","addressComponent":{"country":"??????","country_code":0,"province":"?????????","city":"?????????","district":"?????????","adcode":"330104","street":"????????????","street_number":"","direction":"","distance":""},"pois":[{"addr":"????????????5277???","cp":" ","direction":"???","distance":"68","name":"????????????????????????????????????","poiType":"????????????","point":{"x":120.25084961536486,"y":30.3112150 if (lowerCaseHost.equals("api.map.baidu.com")) { val indexLng = lowerCaseHttp_Content.indexOf("\"lng\"") val indexLat = lowerCaseHttp_Content.indexOf("\"lat\"") if (lowerCaseHttp_Content.indexOf("\"location\"") != -1 && indexLng != -1 && indexLat != -1) { var splitstr: String = "\\,|\\{|\\}" var uriItems: Array[String] = lowerCaseHttp_Content.split(splitstr) var tempItem: String = "" lnglatType = "BD" success = true for (uriItem <- uriItems) { tempItem = uriItem.trim() if (tempItem.startsWith("\"lng\":")) { longitude = tempItem.replace("\"lng\":", "").trim() } else if (tempItem.startsWith("\"lat\":")) { latitude = tempItem.replace("\"lat\":", "").trim() } else if (tempItem.startsWith("\"confidence\":")) { radius = tempItem.replace("\"confidence\":", "").trim() } } } } else if (lowerCaseHost.equals("loc.map.baidu.com")) { 。。。 } longitude = longitude.replace("\"", "") latitude = latitude.replace("\"", "") radius = radius.replace("\"", "") (success, lnglatType, longitude, latitude, radius) } }
打包,注意應為我們使用的hadoop&hive&spark on yarn的叢集,我們這裡並不需要想spark&hadoop一樣還需要在執行spark-submit時將spark-hadoop-xx.jar打包進來,也不需要在submit-spark指令碼.sh中制定jars引數,yarn會自動診斷我們需要哪些集群系統包;但是,如果你應用的是第三方的包,比如ab.jar,那打包時可以打包進來,也可以在spark-submit 引數jars後邊指定特定的包。
- 寫spark-submit提交指令碼.sh:

- 當執行spark-submit指令碼出現錯誤時,怎麼應對呢?
注意,我們這裡不是spark而是spark on yarn,當我們使用yarn-cluster方式提交時,介面是看不到任何日誌新的。我們需要藉助yarn管理系統來檢視日誌:
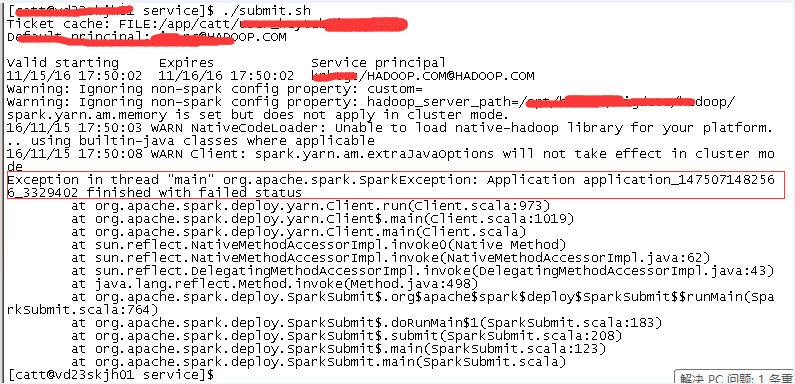
yarn logs -applicationId application_1475071482566_3329402
2、yarn頁面檢視日誌
https://xx.xx.xx.xx:xxxxx/Yarn/ResourceManager/xxxx/cluster 使用者名稱/密碼:user/password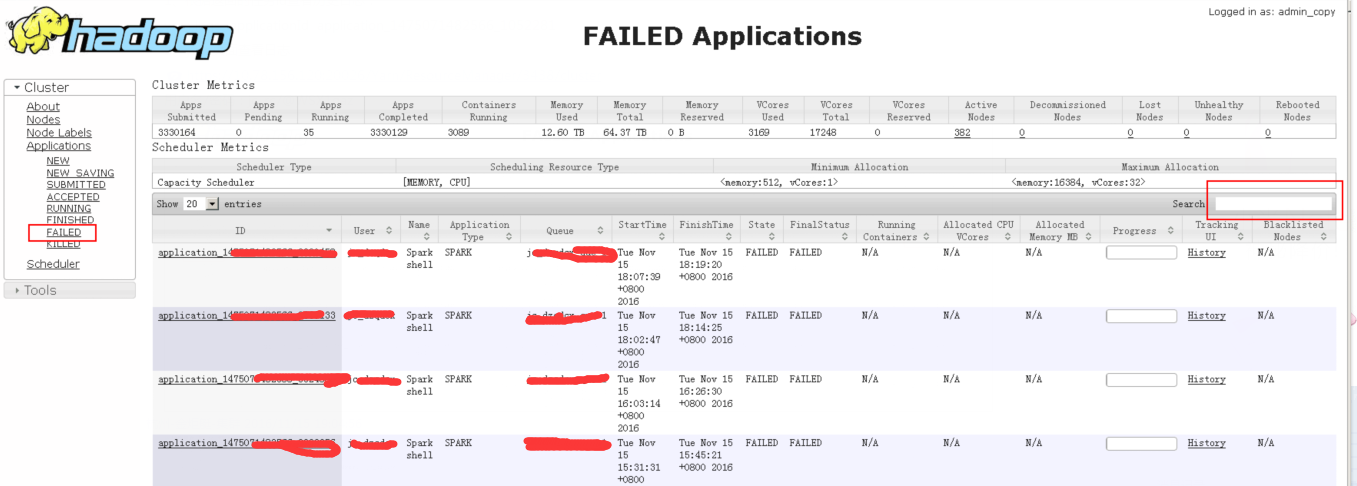 3、yarn關閉application:
從yarn resourcemanger介面中,可以檢視到具體的applicationId,使用命令來殺掉該任務:
更多命令可以參考:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YarnCommands.html
3、yarn關閉application:
從yarn resourcemanger介面中,可以檢視到具體的applicationId,使用命令來殺掉該任務:
更多命令可以參考:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YarnCommands.html
yarn application -kill application_1475071482566_3807023
或者從介面進入spark作業進度管理介面,進行檢視作業具體執行進度,也可以kill application

Spark On YARN記憶體分配:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool
相關推薦
scala篩選460億條記錄的hive表
背景: 接到任務,需要在一個一天資料量在460億條記錄的hive表中,篩選出某些host為特定的值時才解析該條記錄的http_content中的經緯度: 解析規則譬如: 1 2 3 4 需要解析host: api.map.baidu.com 需要
oracle上億條記錄大表delete
delete /*+ use_hash(a,b) parallel(a,15)*/ from tabacca where exists (select 1 from temptablea b where a.id=b.id and b.type='1'); 可以試試多個j
如何在十分鐘內插入1億條記錄到Oracle資料庫?
這裡提供一種方法,使用 APPEND 提示,使得十分鐘內插入上億資料成為可能。 -- Create table create table TMP_TEST_CHAS_LEE ( f01 VARCHAR2(20), f02 NUMBER(10) not null
有一個擁有1億條資料的表,只需要保留其中的5條,其他刪除,如何做?
DELETE語句可以通過WHERE對要刪除的記錄進行選擇。而使用TRUNCATE TABLE將刪除表中的所有記錄。因此,DELETE語句更靈活。如果DELETE不加WHERE子句, DELETE可以返回被刪除的記錄數,而TRUNCATE TABLE返回的是0。如果一個表中有自增欄位,使用TRUNCATE T
Sqoop分批匯入Mysql上億條資料的表到HDFS
因資料量過大,執行sqoop跑不動或者卡記憶體,於是通過寫指令碼分批匯入到HDFS,然後再載入到Hive表中。 shell指令碼如下: #!/bin/bash source /etc/profi
用JAVA如何實現每天1億條記錄的資料儲存,資料庫方面怎麼設計?
一天秒數:60*60*24=86,400秒每天寫入資料量:100,000,000條平均每秒寫入資料量:100,000,000/86,400=1157.5條峰值每秒估算寫入數:1157.5*10=11575條因此建議從以下幾個層面處理1、資料庫伺服器磁碟採用高速SSD磁碟2、資
PostgreSQL 規模參考:400G+容量,N億條記錄
400G容量,N億條記錄 With our previous solution, we found it difficult to support databases over 50GB. Now, because of PostgreSQL, we are easily working with dat
表A中一條記錄的兩個字段都對應於表B的同一個字段 如何查詢?SQL, thinkphp[5]
username 如何 sel 表名 admin clas team ech field 表 A=approval_order, B=admin, 表A中technician_username, salesman_username 都是id號,中文名保存在admin表的
Hive分組取第一條記錄
des 分享圖片 num -m partition 分組排序 -c 時間 每天 需求 交易系統,財務要求維護每個用戶首個交易完成的訂單數據(首單表,可取每個用戶交易完成時間最老的訂單數據)。舉例: 簡寫版的表結構: 表數據: 則 財務希望匯總記錄如下: uid o
取得left join的第二表中符合條件的第一條記錄
sele 公司 color txt nbsp time from txt記錄 order 問題描述 有表一 tableA tid username title 1 lily 我公司將進行xx培訓 2 angus
mybatis 關聯查詢時,從表只返回第一條記錄解決辦法
bean mod 第一條 solid ews 解決辦法 prop ica 元素 如果兩表聯查,主表和明細表的主鍵都是id的話,明細表的多條只能查詢出來第一條。 造成以上情況可能的
更新表中的最早一條記錄
一次 字符串 時間 TE max cas sqlit 整數 select (1)同一張表中可能存在多輛車的皮重記錄,想更新最早的一條記錄,即更新其皮重。在sqlite3中,如下:update CarNoTable set TareWeight ='9080'
從資料庫表中隨機獲取N條記錄的SQL語句
Oracle: select * from (select * from tableName order by dbms_random.value) where rownum < N; M
前端之路:sql語句,表中隨機獲取一條記錄(資料)。(或者獲取隨機獲取多條(記錄)資料)
<!--表中獲取隨機一條title 耗時0.01s id==隨機欄位,最好為表id--> SELECT * FROM `tableName` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `ta
給出n個學生的考試成績表,每條記錄由學號、姓名和分數和名次組成,設計演算法完成下列操作: (1)設計一個顯示對學生資訊操作的選單函式如下所示: *************************
給出n個學生的考試成績表,每條記錄由學號、姓名和分數和名次組成,設計演算法完成下列操作: (1)設計一個顯示對學生資訊操作的選單函式如下所示: ************************* 1、錄
UPDATE SET a.id = (select) 關聯多張表更新多條記錄
UPDATE wallet_account_trade_record A SET A.shop_id =( SELECT c.shop_id FROM mob_checkout_counter.payment_data_info B,mob_checkout_counter.c
sql 刪除表中多餘的重複記錄(多個欄位),只保留一條記錄
在網上呢~自己收集了一些關於這方面的知識~ 自己整理一下 1.查詢重複記錄 select * from 表名 where 重複欄位 in (select 重複欄位 from 表名 group
如何查詢oracle資料庫一個表中的多條記錄是否有重複
原文連結:http://blog.chinaunix.net/uid-16175364-id-2752272.html如何查詢oracle資料庫一個表中的很多條記錄是否有重複?重複的判斷標準是指定為幾個欄位中只要有任意的一個欄位中有重複就將重複的記錄列出來。Select
從表中隨機取5條記錄
select * from (select * from (select level from dual connect by level < 50) order by dbms_random.value) whe
一個表單同時提交多條記錄
//將表單序列化成json格式的資料(但不適用於含有控制元件的表單,例如複選框、多選的select) (function($){ $.fn.serializeJson = function(){ var jsonData