
Ambari安裝之Ambari安裝前準備(CentOS6.5)(一)
優秀部落格
Ambari安裝前準備
(一)機器準備
192.168.80.144 ambari01 (部署Ambari-server和Mirror server) (分配1G,我這裡只是體驗過程,當然你可以分配更多或更小)
192.168.80.145 ambari02 (部署Agent) (分配1G,我這裡只是體驗過程,當然你可以分配更多或更小)
192.168.80.146 ambari03 (部署Agent) (分配1G,我這裡只是體驗過程,當然你可以分配更多或更小)
192.168.80.147 ambari04 (部署Agent) (分配1G,我這裡只是體驗過程,當然你可以分配更多或更小)
說白了,就是在ambari01上安裝了ambari。
就是在ambari02上安裝了hdp單節點叢集。
就是在ambari02、ambari03和ambari04上安裝了hdp的3節點叢集。
(二)機器的部署配置
這裡我採用克隆的方式,當然大家也可以單獨搭建linux虛擬機器。
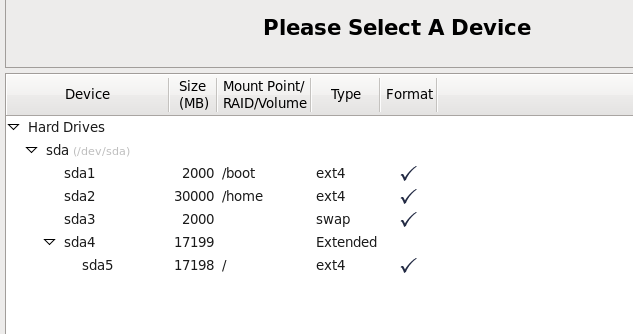
(1)修改主機名
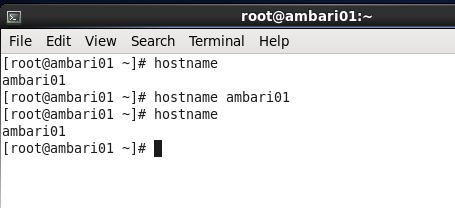
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。當然我也可以輸入命令來檢視一下主機名,我們輸入hostname,我們發現主機名就是ambari01,那麼接下來我們就來修改一下主機名。
常見的有三種方法,一種是臨時性的修改,但是當機器重啟之後就會恢復原來的值,比如我們試一下。
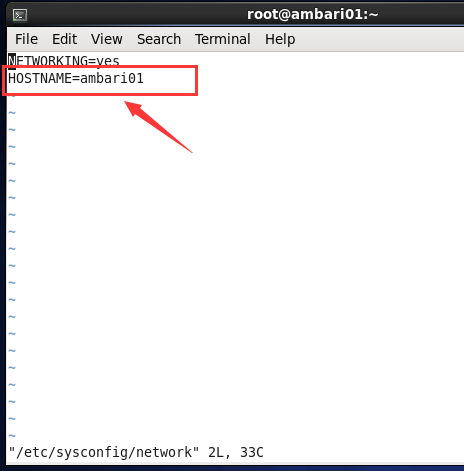
還有一種方法就是永久修改,我們直接修改配置檔案,我們直接修改/etc/sysconfig/network
實際上還有一種方法,修改/etc/hosts,他對網路中的主機名起作用,但是對系統本身(也就是本機)不起作用。他和第一種的效果是一樣的。實際上我們一般用這個來配置主機名和IP之間的對應關係。
我這裡採用第二種方法。改完之後沒有變化,我們使用reboot命令重啟一下機器就可以了。
(2)Linux虛擬機器的網路配置和系統配置
我這裡,僅拿ambari01來說,其他的ambari02、ambari03和ambari04是一樣的。
(1)ping迴環地址:能ping通,說明虛擬機器的網路協議是好的。
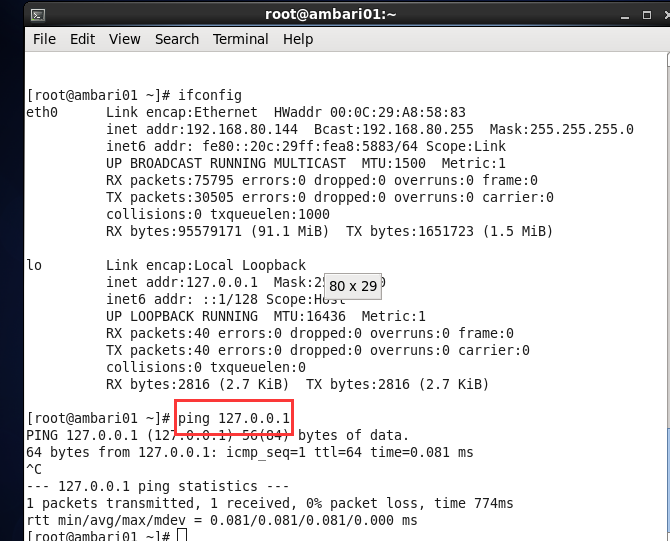
(2)ping閘道器
點選“編輯”——》“虛擬網路編輯器”
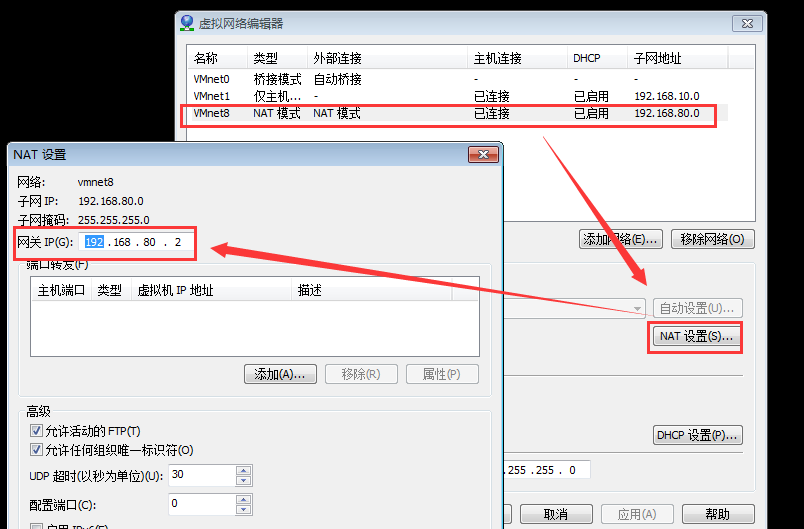
但是這裡邊要注意一個問題,因為我們是克隆的。所以我們還要改一下MAC地址(就是我們硬體的地址,用來定義網路裝置的位置),因為我們新的MAC地址和我們網絡卡配置裡的MAC地址不一致,所以會導致網路連線不上。
所以我們先來檢視一下我們新的MAC地址
我們輸入vi /etc/udev/rules.d/70-persistent-net.rules(如果你是完全克隆,這個檔案裡應該包含eth0和eth1,我們將eth0配置刪除,只保留eth1,記錄該配置對應的MAC地址,並將eth1改名為eth0
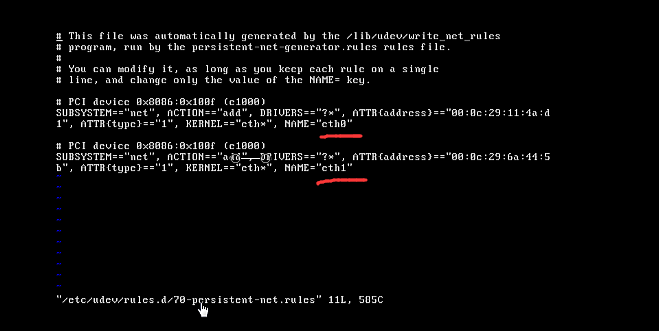
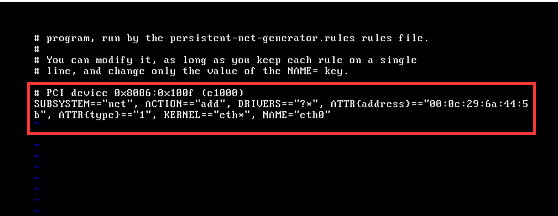
接下來修改網絡卡vi /etc/sysconfig/network-scripts/ifcfg-eth0
你要是新搭建的Linux虛擬機器的時候只需要把ONBOOT 的no改為yes就行,(開啟我們的網絡卡,我們才能夠看到我們的IP地址,BOOTPROTO=dhcp,指定獲取IP的方法,dhcp(動態主機配置協議)還有一種是static ,靜態的)
改回dhcp之後要重啟一下,否則還是檢視不到IP地址。(或者用service network restart命令)
OK,前面的修改完之後,下面我們就輸入ifconfig來檢視一下IP,然後我們ping IP
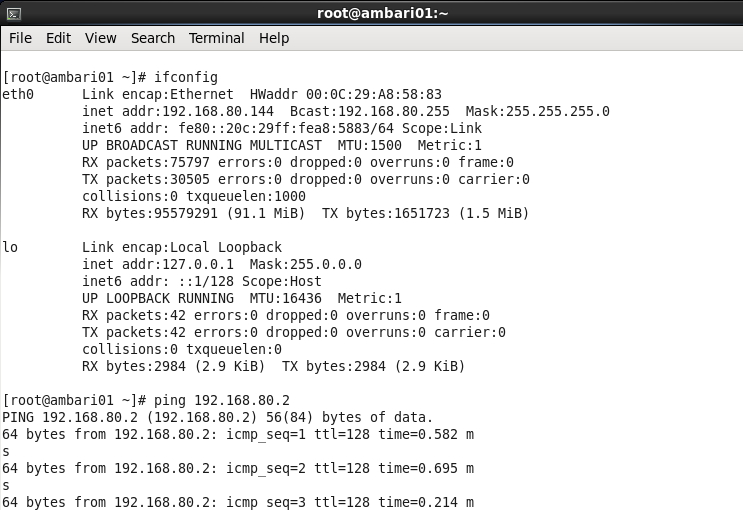
接下來我們再來ping www.baidu.com

OK,都能ping通,這就說明我們已經和外部網路打通了。
(3)X-shell遠端連線
(4)使用者設定:hadoop使用者
我這裡,是新建的hadoop使用者。

現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
(5)為hadoop使用者設定sudo許可權
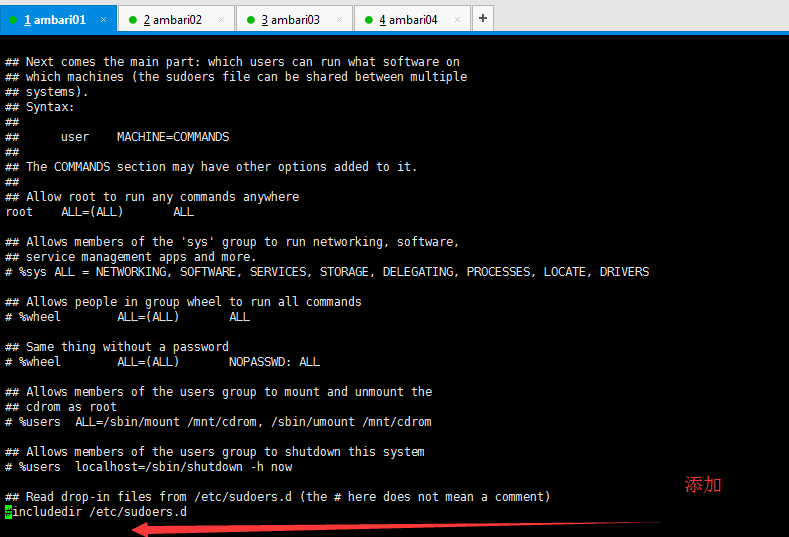
在root使用者下,輸入visudo開啟檔案
在檔案末尾(按快捷鍵,Shift + g)新增hadoop ALL=(ALL) NOPASSWD:ALL


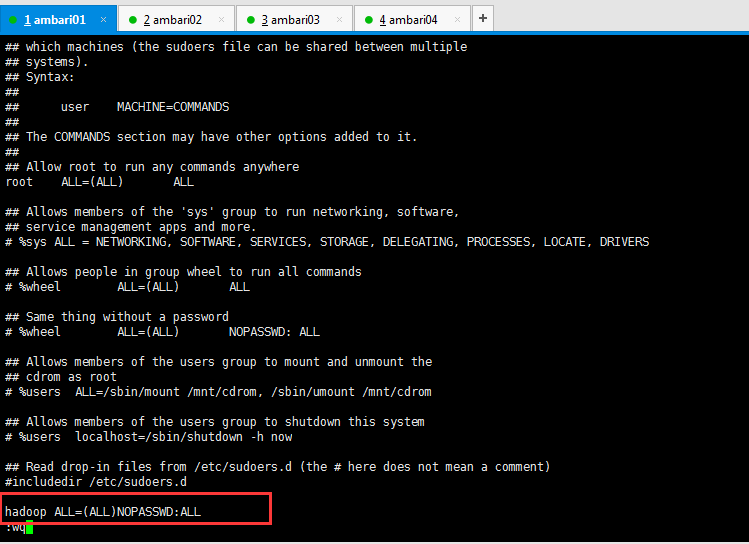
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
(6)配置靜態IP
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
vi /etc/sysconfig/network-scripts/ifcfg-eth0


(7)檢視並關閉防火牆
先檢視一下防火牆狀態
Service iptables status
如果防火牆在執行,就關閉,也有兩種方法。
一種是臨時關閉
service iptables stop
一種是永久關閉
chkconfig iptables off
這裡我採用永久性關閉。

同理,現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
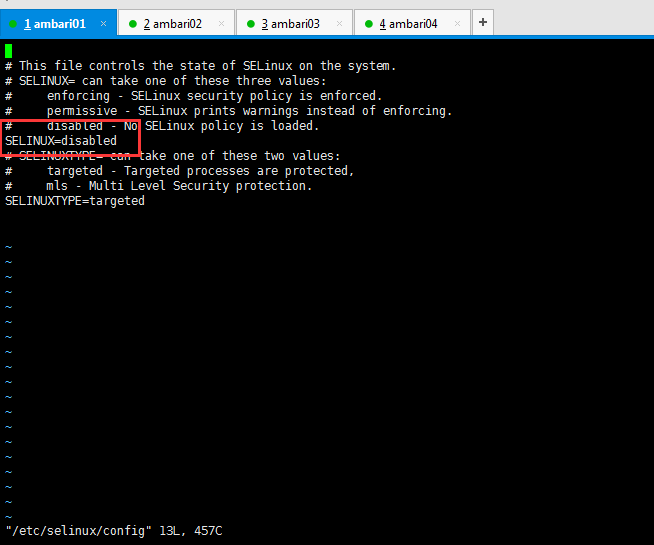
(8)關閉SELINUX
sudo vi /etc/selinux/config
把SELINUX改為disabled
然後重啟reboot。
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
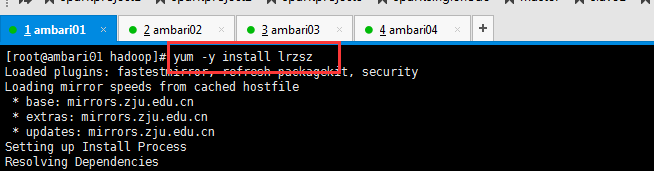
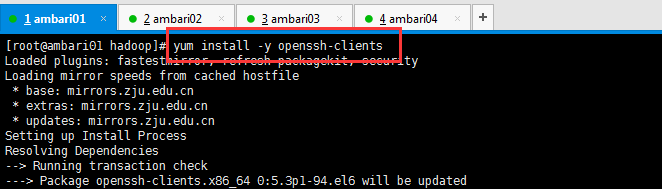
(9)相關服務的安裝
如果沒有安裝的話可以使用下面的命令安裝一下。
[[email protected] hadoop]# yum -y install lrzsz [[email protected] hadoop]# yum install -y openssh-clients
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
(10)時鐘同步
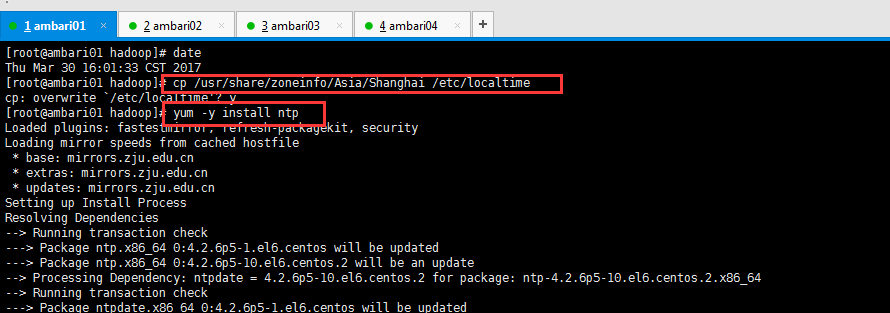
[[email protected] hadoop]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime cp: overwrite `/etc/localtime'? y [[email protected] hadoop]# yum -y install ntp
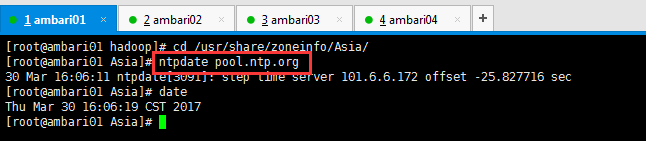
[[email protected] hadoop]# cd /usr/share/zoneinfo/Asia/ [[email protected] Asia]# ntpdate pool.ntp.org 30 Mar 16:06:11 ntpdate[3091]: step time server 101.6.6.172 offset -25.827716 sec [[email protected] Asia]# date Thu Mar 30 16:06:19 CST 2017 [[email protected] Asia]#
現在的主機名是ambari01,拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。
(11)修改hosts檔案
vi /etc/hosts
在裡面新增主機名和IP之間的對應關係
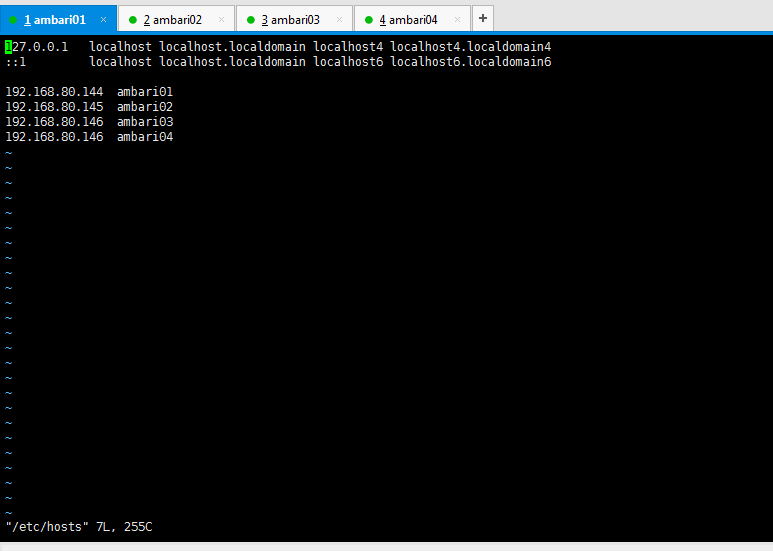
192.168.80.144 ambari01 192.168.80.145 ambari02 192.168.80.146 ambari03 192.168.80.147 ambari04
(注意,圖裡有錯誤,按這裡是對的)
注意:上面的所有步驟要在準備的四臺機器上都進行操作
(12)配置ssh免密碼登入
關於這一步,請移步,先看看再說,細加小心。
這裡我以ambari01為例來配置ssh。拿這個來說,其他的ambari02、ambari03和ambari04是一樣的。

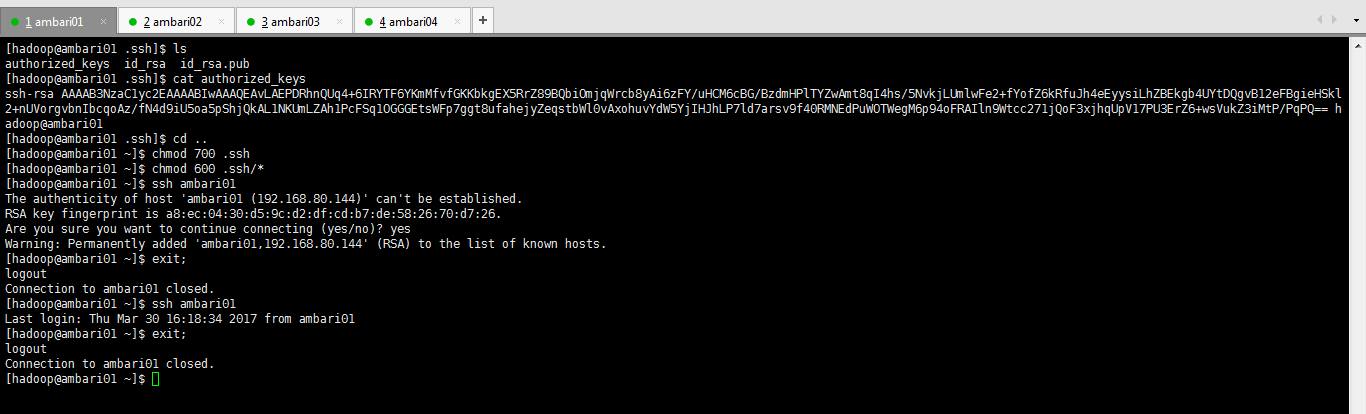
[[email protected]~]# su hadoop //切換到hadoop使用者下 [[email protected] root]$ cd //切換到hadoop使用者目錄 [[email protected] ~]$ mkdir .ssh [[email protected] ~]$ ssh-keygen -t rsa //執行命令一路回車,生成祕鑰 [[email protected] ~]$cd .ssh [[email protected] .ssh]$ ls id_rsa id_rsa.pub [[email protected]]$ cat id_rsa.pub >> authorized_keys //將公鑰儲存到authorized_keys認證檔案中 [[email protected]]$ ls authorized_keys id_rsa id_rsa.pub [[email protected] .ssh]$ cd .. [[email protected] ~]$ chmod 700 .ssh [[email protected] ~]$ chmod 600 .ssh/* [[email protected] ~]$ ssh ambari01//第一次執行需要輸入yes [[email protected] ~]$ ssh ambari01//第二次以後就可以直接訪問 [[email protected] ~]$ ssh ambari01//第二次以後就可以直接訪問
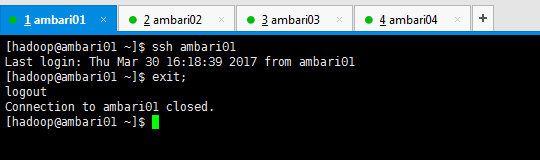

將所有節點(ambari02、ambari03和ambari04)中的共鑰id_ras.pub拷貝到ambari01中的authorized_keys檔案中。
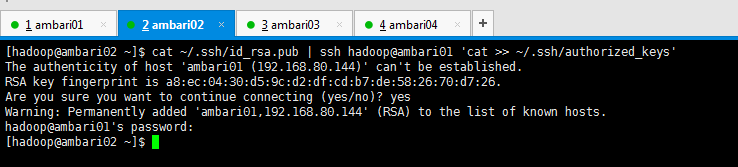
[[email protected] ~]$ cat ~/.ssh/id_rsa.pub | ssh [email protected] 'cat >> ~/.ssh/authorized_keys' The authenticity of host 'ambari01 (192.168.80.144)' can't be established. RSA key fingerprint is a8:ec:04:30:d5:9c:d2:df:cd:b7:de:58:26:70:d7:26. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari01,192.168.80.144' (RSA) to the list of known hosts. [email protected]'s password: [[email protected] ~]$
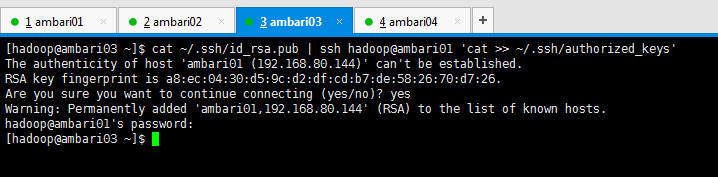
[[email protected] ~]$ cat ~/.ssh/id_rsa.pub | ssh [email protected] 'cat >> ~/.ssh/authorized_keys' The authenticity of host 'ambari01 (192.168.80.144)' can't be established. RSA key fingerprint is a8:ec:04:30:d5:9c:d2:df:cd:b7:de:58:26:70:d7:26. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari01,192.168.80.144' (RSA) to the list of known hosts. [email protected]'s password: [[email protected] ~]$
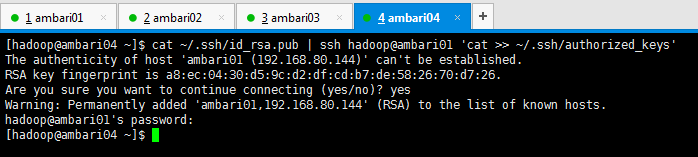
[[email protected] ~]$ cat ~/.ssh/id_rsa.pub | ssh [email protected] 'cat >> ~/.ssh/authorized_keys' The authenticity of host 'ambari01 (192.168.80.144)' can't be established. RSA key fingerprint is a8:ec:04:30:d5:9c:d2:df:cd:b7:de:58:26:70:d7:26. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari01,192.168.80.144' (RSA) to the list of known hosts. [email protected]'s password: [[email protected] ~]$
得到,
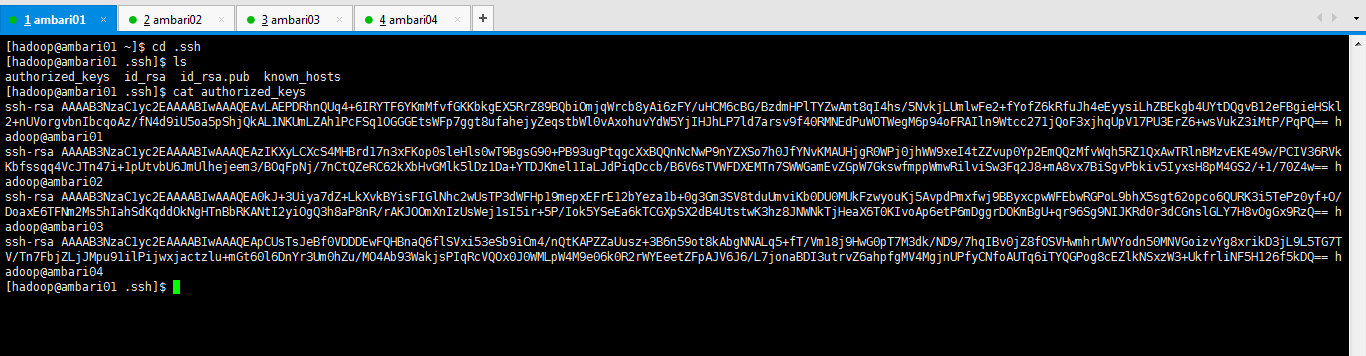
然後將中ambari01的authorized_keys檔案分發到所有節點上面。

[[email protected] .ssh]$ scp -r authorized_keys [email protected]:~/.ssh/ The authenticity of host 'ambari02 (192.168.80.145)' can't be established. RSA key fingerprint is e7:b4:58:e7:28:13:0c:2d:15:c5:fb:7c:2f:b3:b7:b7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari02,192.168.80.145' (RSA) to the list of known hosts. [email protected]'s password: authorized_keys 100% 1588 1.6KB/s 00:00 [[email protected] .ssh]$ scp -r authorized_keys [email protected]:~/.ssh/ The authenticity of host 'ambari03 (192.168.80.146)' can't be established. RSA key fingerprint is f5:17:e3:ac:26:53:74:4f:7e:d4:d2:ed:2a:49:4b:d2. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari03,192.168.80.146' (RSA) to the list of known hosts. [email protected]'s password: authorized_keys 100% 1588 1.6KB/s 00:00 [[email protected] .ssh]$ scp -r authorized_keys [email protected]:~/.ssh/ The authenticity of host 'ambari04 (192.168.80.147)' can't be established. RSA key fingerprint is 7e:87:00:80:44:70:cd:83:e6:f3:dc:cb:21:76:23:07. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ambari04,192.168.80.147' (RSA) to the list of known hosts. [email protected]'s password: authorized_keys 100% 1588 1.6KB/s 00:00 [[email protected] .ssh]$
大家通過ssh 相互訪問,如果都能無密碼訪問,代表ssh配置成功。這裡很簡單,我就不多贅述了。
(13)JDK的安裝(建議1.8)
用檔案上傳工具FileZila把jdk1.8的tar包上傳到我們指定的軟體安裝目錄下(比如:/home/hadoop/app或者/usr/local/jdk),或者使用rz命令上傳也行,但是要切換到root使用者下,或者在hadoop使用者下使用sudo rz
jdk-8u60-linux-x64.tar.gz
注意,先記得。
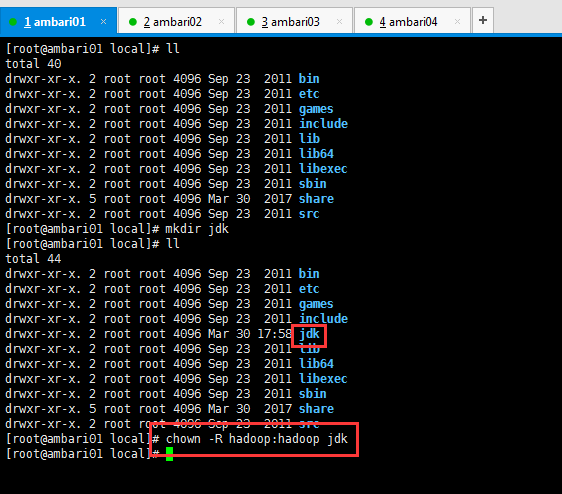
[[email protected] local]# mkdir jdk
[[email protected] local]# chown -R hadoop:hadoop jdk
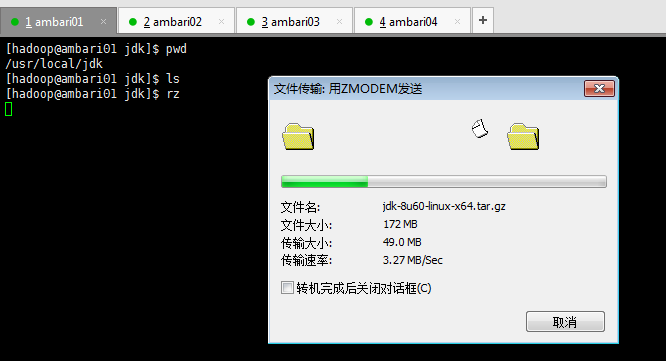
[[email protected] jdk]$ ll total 176992 -rw-r--r--. 1 hadoop hadoop 181238643 Sep 3 2016 jdk-8u60-linux-x64.tar.gz [[email protected] jdk]$ tar -zxvf jdk-8u60-linux-x64.tar.gz
解壓jdk
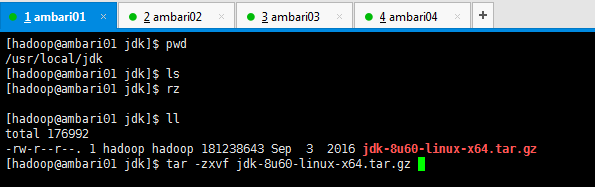
刪除jdk壓縮包,並賦予使用者和使用者組。

[[email protected] jdk]$ rm jdk-8u60-linux-x64.tar.gz [[email protected] jdk]$ ll total 4 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 [[email protected] jdk]$
配置jdk環境變數並使用source命令環境變數生效

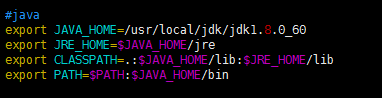
#java
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
使用java -version命令檢視JDK是否安裝成功

[[email protected] jdk]$ su root Password: [[email protected] jdk]# source /etc/profile [[email protected] jdk]# su hadoop [[email protected] jdk]$ clear [[email protected] jdk]$ pwd /usr/local/jdk [[email protected] jdk]$ ll total 4 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 [[email protected] jdk]$ java -version java version "1.8.0_60" Java(TM) SE Runtime Environment (build 1.8.0_60-b27) Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode) [[email protected] jdk]$
注意上面操作要在所有節點都執行
OK,到此為止我們的準備工作基本就都做好了,接下來我們就先來部署本地庫,就是部署一個映象伺服器。
歡迎大家,加入我的微信公眾號:大資料躺過的坑 人工智慧躺過的坑同時,大家可以關注我的個人部落格:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
詳情請見:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我願分享。本公眾號將秉持活到老學到老學習無休止的交流分享開源精神,匯聚於網際網路和個人學習工作的精華乾貨知識,一切來於網際網路,反饋回網際網路。
目前研究領域:大資料、機器學習、深度學習、人工智慧、資料探勘、資料分析。 語言涉及:Java、Scala、Python、Shell、Linux等 。同時還涉及平常所使用的手機、電腦和網際網路上的使用技巧、問題和實用軟體。 只要你一直關注和呆在群裡,每天必須有收穫
對應本平臺的討論和答疑QQ群:大資料和人工智慧躺過的坑(總群)(161156071)![]()
![]()
![]()
![]()
![]()



相關推薦
Ambari安裝之Ambari安裝前準備(CentOS6.5)(一)
優秀部落格 Ambari安裝前準備 (一)機器準備 192.168.80.144 ambari01 (部署Ambari-server和Mirror server) (分配1G,我這裡只是體驗過程,當然你可以分配更多或更小) 192.1
Cloudera Manager安裝之Cloudera Manager安裝前準備(CentOS6.5)(一)
Cloudera Manager安裝前準備 (一)機器準備 192.168.80.148 clouderamanager01 (部署ClouderaManager-server和Mirror server) (部署Agent) (分配1G,我這裡只是體驗
Cloudera Manager安裝之Cloudera Manager安裝前準備(Ubuntu14.04)(一)
其實,基本思路跟如下差不多,我就不多詳細說了,貼出主要圖。 博主,我是直接借鑑下面這位博主,來進行安裝的!(灰常感謝他們!) https://www.zybuluo.com/ncepuwanghui/note/474966 ClouderM
mongoDB學習之路,安裝、配置、啟動、命令、應用(一)
mongoDB初學 mongoDB學習了一段時間,今天整理一下,以便自己回顧,加深印象,同時讓更多mongo初學者有個好的資料。真好 在學習mongoDB之前,我們先了解什麼是mongoDB,以及相關概念 MongoDB 是一個基於分散式檔案儲存的資料庫。由 C++
用centOS 7安裝cadence搭建適合IC Design的科研環境(一)——相關知識準備
這篇部落格記錄我在用centOS搭建適合模擬積體電路設計的科研環境的過程,主要內容從我的OneNote筆記中整理,一是為了從雜亂的筆記中篩選出有價值的資訊,二是希望能幫助更多像我一樣的新手少走彎路。 過程中所需要的一些背景知識我儘量附上鍊接或參考,如有差錯,還
CentOS7.5利用Kubeadm安裝Kubernets(k8s)1.12.2(國內版)(一)
國內版 一、部署Kubernetes1.12.2(無dashboard) 1、所有節點部署docker-ce kubernetesyum源 阿里雲docker-ce地址 :https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo直接
Windows7下的Django環境、專案及工程搭建(包括anaconda安裝方法)(一)
我這也是邊學邊寫,大家一起吧。參考的資料有點多,但都不太完全,只能依據理解自己把它集合在一起。 首先,安裝python就不說了,我用的是anaconda,我在找了很久走了很多彎路之後才找到,這是一個python的科學環境,它很強大,集成了各種python所需要
ELK日誌系統開發(Logstash、Elasticsearch、Kibana安裝)(一)
一、安裝Logstash !注意,logstash至少要有1G記憶體才能執行 在安裝Logstash之前,確保已經安裝了Java的執行環境 3)下載完成之後,加壓(無須編譯),並複製到local目錄下,這個是我正式部署的目錄:/usr/local/logstash-
教你用Cocosdx匯出安卓安裝檔案(.apk)(一)
我也是剛弄出來,過程可能有點混亂和不詳細,我盡我所能寫完整。各位看官多多包涵 裝置環境: 我所用的是mac 10.8.5 64位 Cocosdx-3.0rc2 xcode 5.0 一、準備
linux驅動開發之蜂鳴器驅動源碼分析(一)
linux 蜂鳴器 驅動 蜂鳴器的驅動源碼在/driver/char/buzzer/x210-buzzer.c文件中,源碼如下#include <linux/module.h> #include <linux/kernel.h> #include <linux
硬件傳輸模塊系列之藍牙模塊無線上傳(一)
名稱 支持 藍牙連接 關閉 輸入 配對 藍牙 沒有 串口 藍牙模塊HC-06 知識點一:藍牙狀態 led指示藍牙連接狀態,閃爍表示沒有藍牙連接,常亮表藍牙已連接並打開串口(端口) 知識點二:相關參數 輸入電壓3.6v-6V,未配對時電流30mA,配對成功後為10mA。 未建
多線程編程之Linux環境下的多線程(一)
posix you host 說明 通過 常用 新的 變量 func 一、Linux環境下的線程 相對於其他操作系統,Linux系統內核只提供了輕量級進程的支持,並未實現線程模型。Linux是一種“多進程單線程”的操作系統,Linux本身只有進程的概念,而其所謂的“線程
13.Django之數據庫models&orm初探(一)
try api 示例 mar 叠代 交互 reverse 一行 gre 一、使用django orm的準備操作。django 默認支持sqlite,mysql, oracle,postgresql數據庫。在默認情況下django的項目中會默認使用sqlite數據庫,在打開s
吳恩達深度學習筆記(deeplearning.ai)之循環神經網絡(RNN)(一)
不同的 圖片 存在 最終 一個 har end markdown 輸入 1. RNN 首先思考這樣一個問題:在處理序列學習問題時,為什麽不使用標準的神經網絡(建立多個隱藏層得到最終的輸出)解決,而是提出了RNN這一新概念? 標準神經網絡如下圖所示: 標準神經網絡在解決序列
【數學之美筆記】自然語言處理部分(一).md
strip BE 模擬 ges arr 實驗 語句 次數 而不是 文字、數字、語言 、信息 數字、文字和自然語言一樣,都是信息的載體,他們的產生都是為了記錄和傳播信息。 但是貌似數學與語言學的關系不大,在很長一段時間內,數學主要用於天文學、力學。 本章,我們將回顧一下信息時
高並發與高可用實戰之基礎知識大型網站架構特征(一)
電商系統 保障系統 iptables ID 失敗重試 容量 設計原則 服務調用 冪等 大型網站架構特征: 1.高並發?(用戶訪問量比較大) 解決方案:拆分系統、服務化、消息中間件、緩存、並發化 高並發設計原則 系統設計不僅需要考慮實現業務功能,還要保證系統高並發、高
深入玩轉K8S之業務彈性伸縮和滾動更新操作(一)
nginx 副本 mil 容器 history 博客 limit 新的 ima 在實際應用場景中避免不了因為業務的壓力而增加容器數量以及業務應用版本叠代更新,那麽本篇文章我們來學習下簡單的業務彈性伸縮、滾動更新操作,滾動操作的好處在於零停機更新,也就是說每次更新一小部分副本
linux學習之多高並發服務器篇(一)
多線程 同步 https 進程調度 creat server side lis logs 高並發服務器 高並發服務器 並發服務器開發 1.多進程並發服務器 使用多進程並發服務器時要考慮以下幾點: 父最大文件描述個數(父進程中需要close關閉accept返回的新文件
資料新增非同步解析重新整理大資料量redis (——)(一)Java Collection之Queue佇列
Queue介面與List、Set同一級別,都是繼承了Collection介面。LinkedList實現了Queue接 口。Queue介面窄化了對LinkedList的方法的訪問許可權(即在方法中的引數型別如果是Queue時,就完全只能訪問Queue介面所定義的方法 了,而不能直接訪問 Linke
整合學習之boosting,Adaboost、GBDT 和 xgboost(一)
在前面的部落格(https://blog.csdn.net/qq_16608563/article/details/82878127) 介紹了整合學習的bagging方法及其代表性的隨機森林。此次接著介紹整合學習的另一個方法boosting以及boosting系列的一些演算法,具體包括 Ad