
Spark程式設計環境搭建(基於Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主強烈推薦)
為什麼,我要在這裡提出要用Ultimate版本。
基於Intellij IDEA搭建Spark開發環境搭——參考文件
操作步驟
a)建立maven 專案
b)引入依賴(Spark 依賴、打包外掛等等)
基於Intellij IDEA搭建Spark開發環境—maven vs sbt
a)哪個熟悉用哪個
b)Maven也可以構建scala專案
基於Intellij IDEA搭建Spark開發環境搭—maven構建scala專案
操作步驟
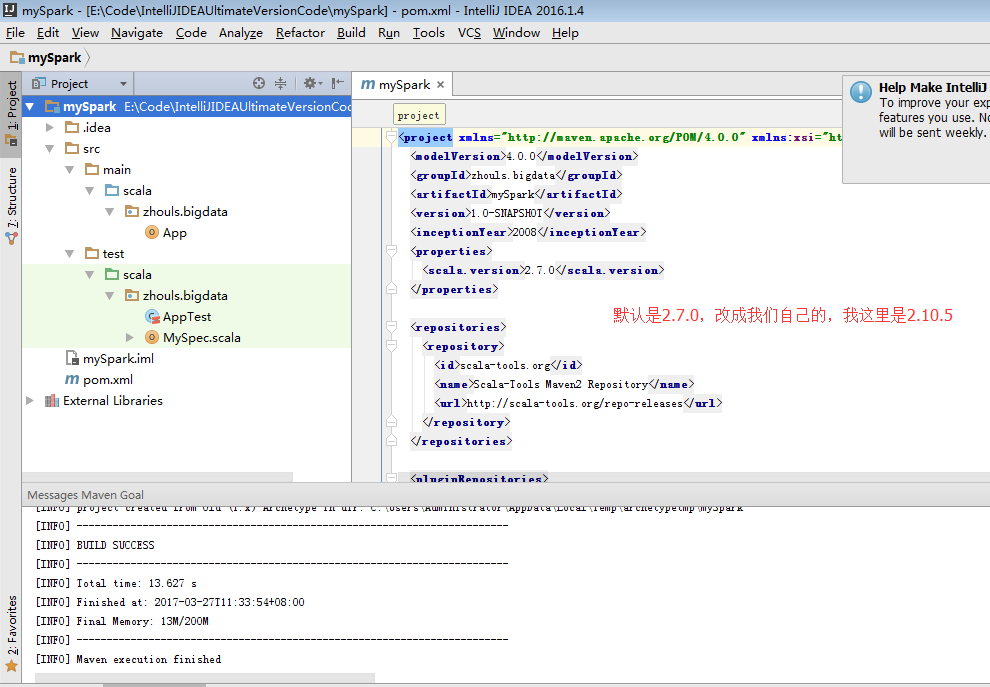
a) 用maven構建scala專案(基於net.alchim31.maven:scala-archetype-simple)
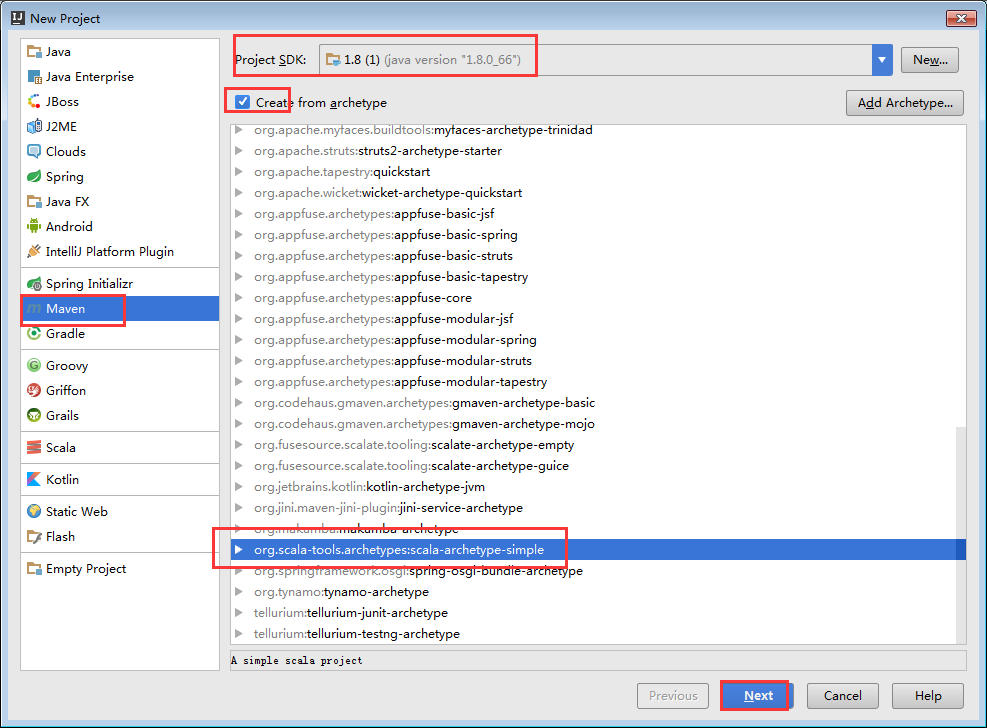

GroupId:zhouls.bigdata
ArtifactId:mySpark
Version:1.0-SNAPSHOT
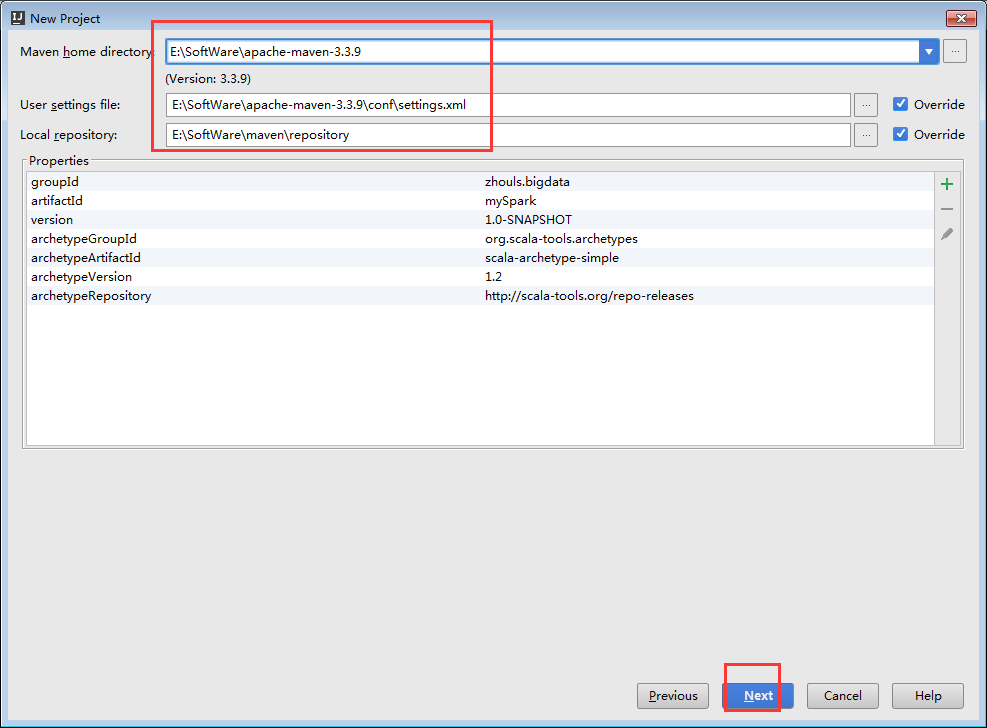

mySpark
E:\Code\IntelliJIDEAUltimateVersionCode\mySpark
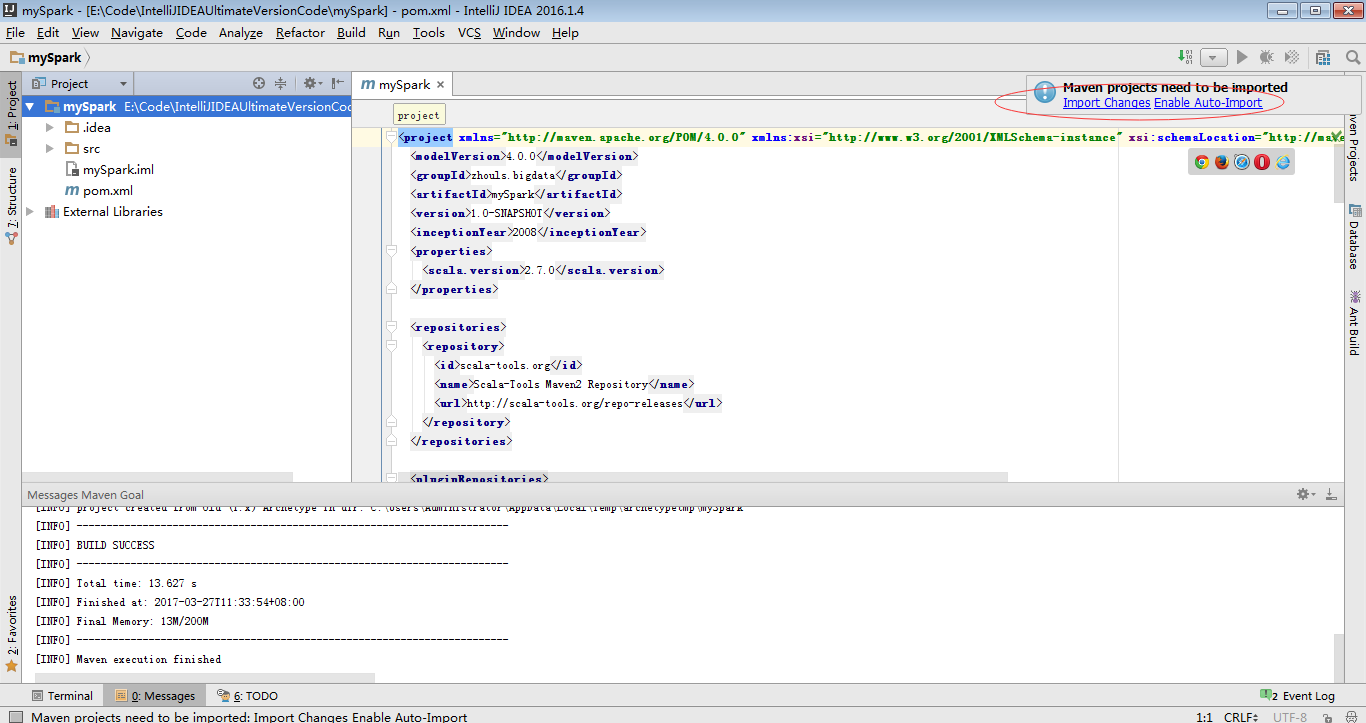
因為,我本地的scala版本是2.10.5
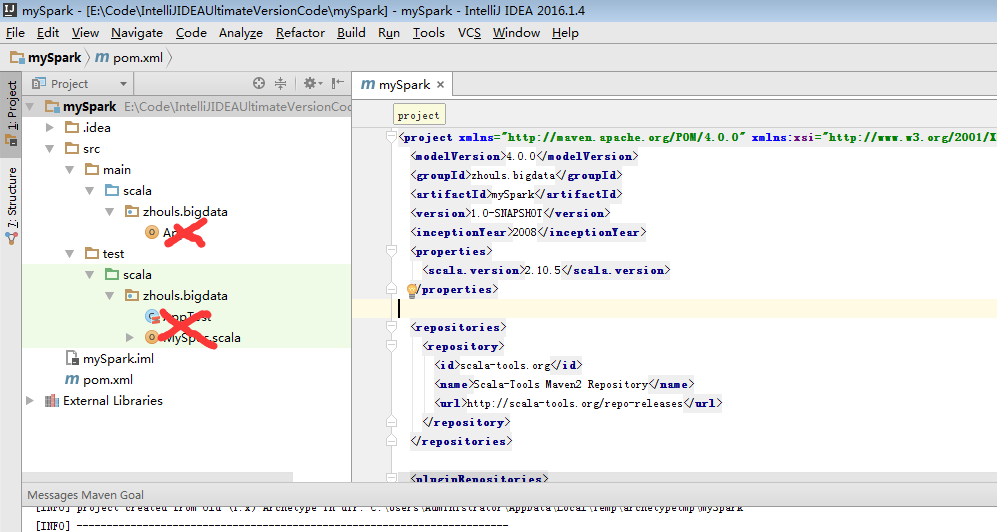
選中,delete就好。

其實,這個就是windows裡的cmd終端,只是IDEA它把這個cmd終端整合到這了。
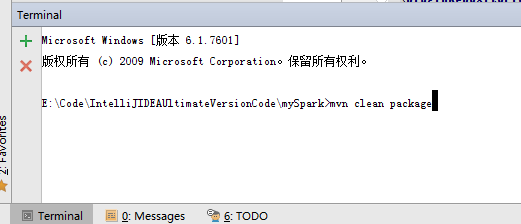
mvn clean package
這只是做個測試而已。
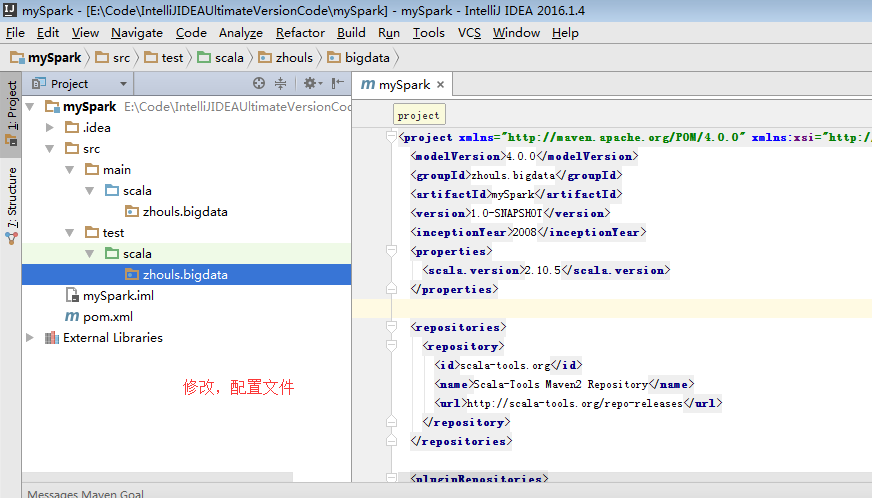
b)pom.xml引入依賴(spark依賴、打包外掛等等)
注意:scala與java版本的相容性
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>zhouls.bigdata</groupId> <artifactId>mySpark</artifactId> <version>1.0-SNAPSHOT</version> <name>mySpark</name> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.10.5</scala.version> <spark.version>1.6.1</spark.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> <!--spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> </dependencies> <build> <!-- <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> --> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <configuration> <downloadSources>true</downloadSources> <buildcommands> <buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand> </buildcommands> <additionalProjectnatures> <projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature> </additionalProjectnatures> <classpathContainers> <classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer> <classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer> </classpathContainers> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.1</version> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <!-- add Main-Class to manifest file --> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <!--<mainClass>com.dajiang.MyDriver</mainClass>--> </transformer> </transformers> <createDependencyReducedPom>false</createDependencyReducedPom> </configuration> </execution> </executions> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>
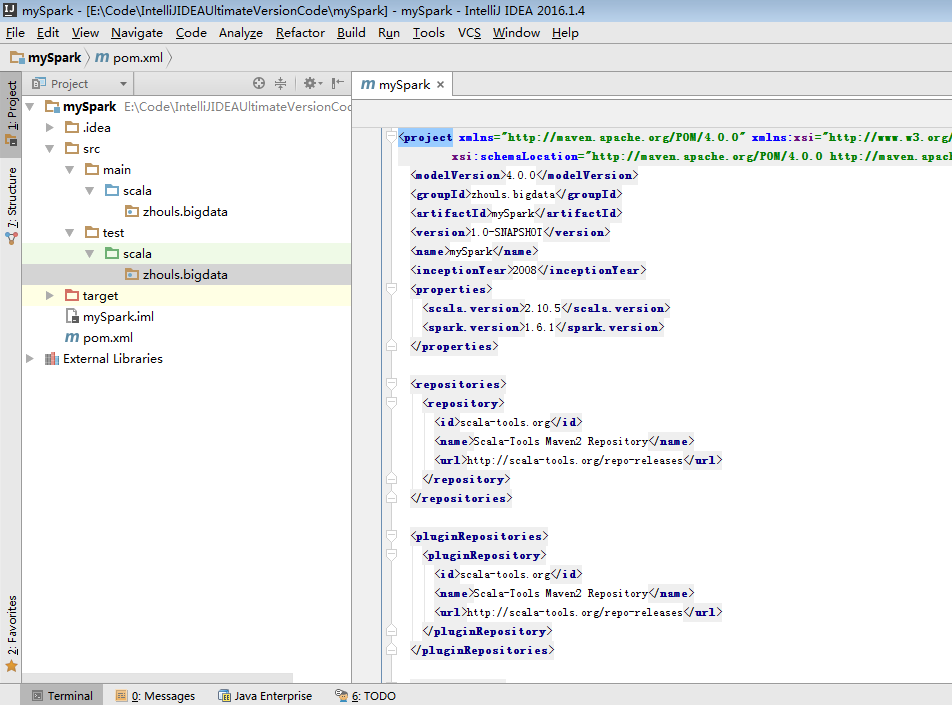
為了養成,開發規範。
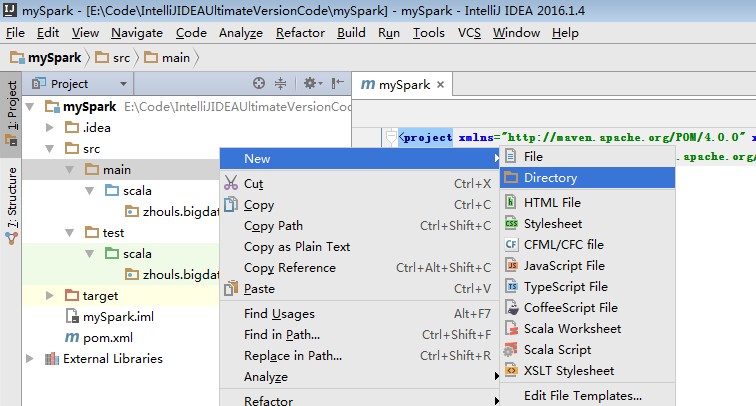
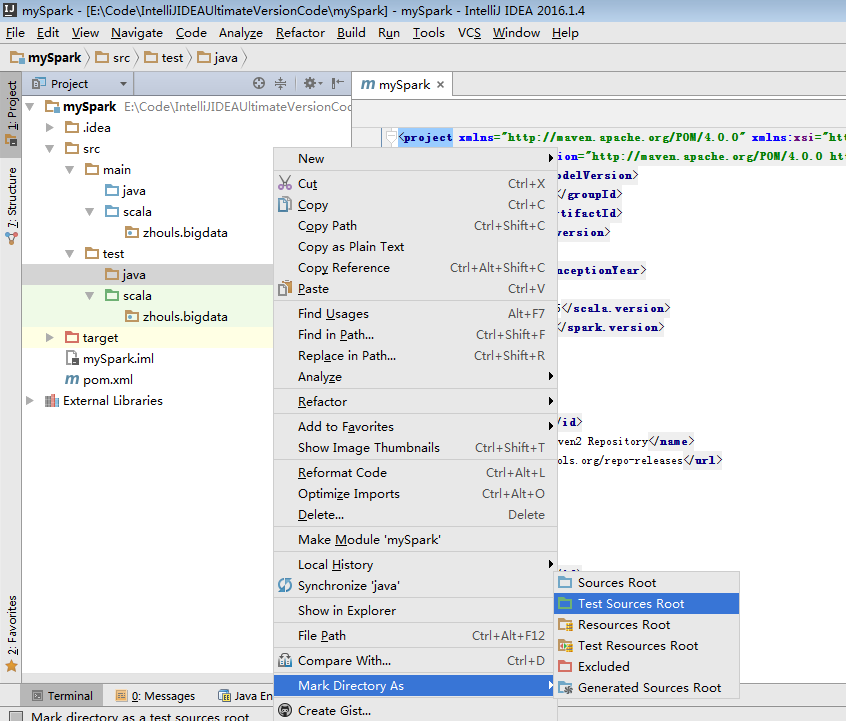
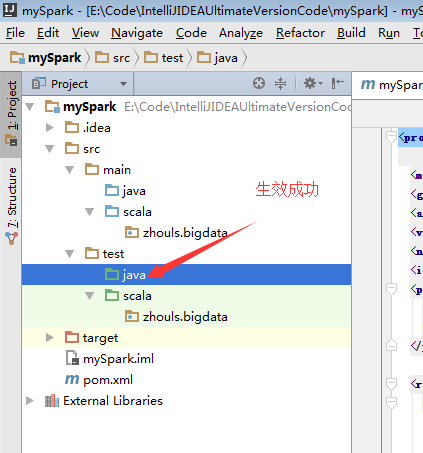
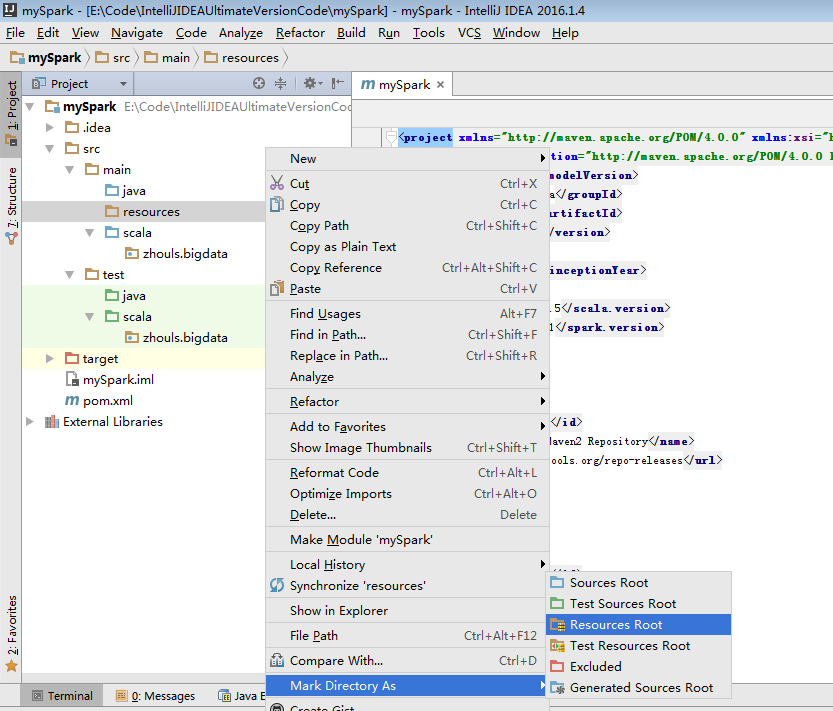
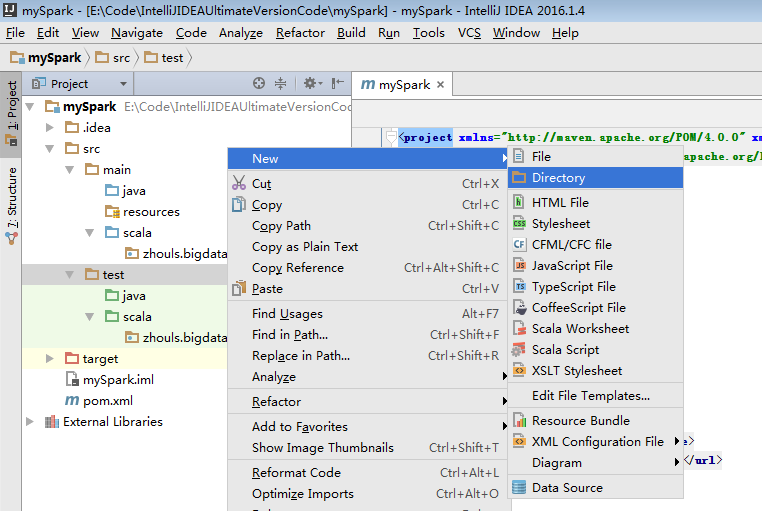
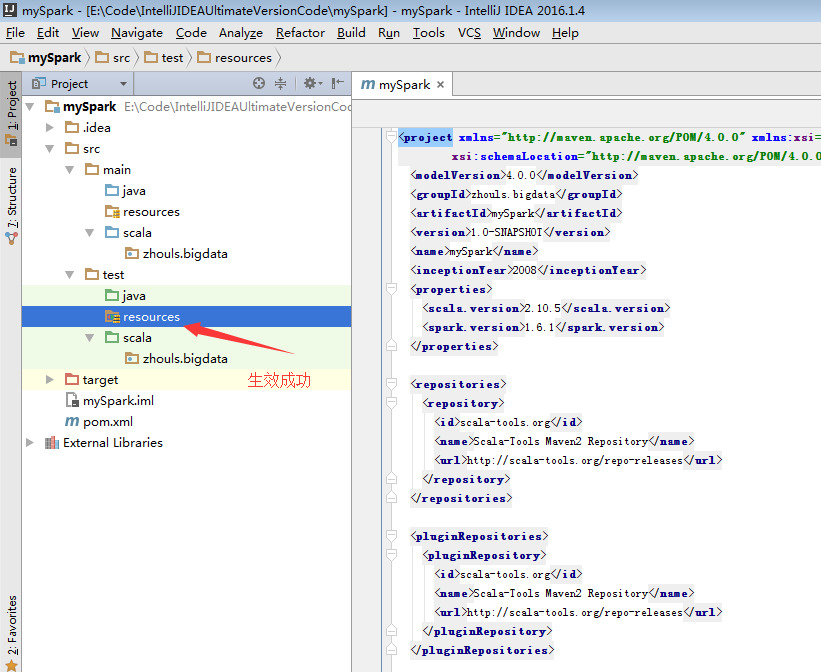
預設,建立是沒有生效的,比如做如下,才能生效。
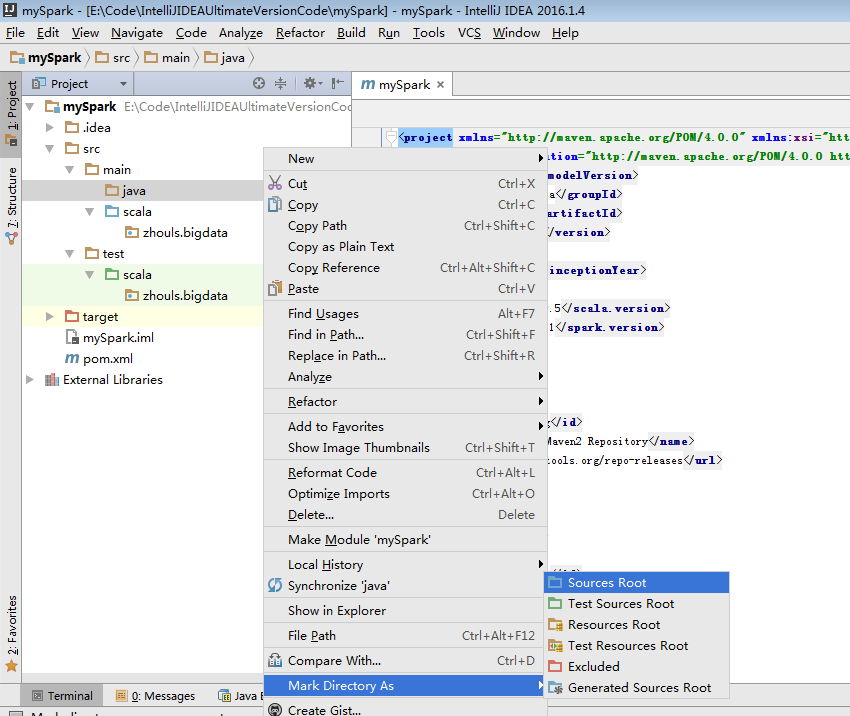
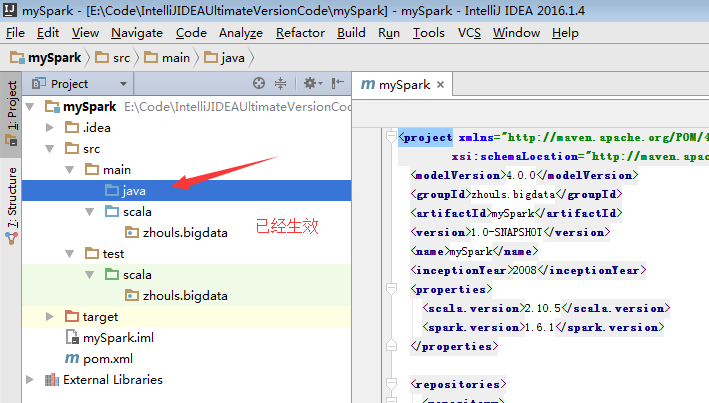
同樣,對於下面的單元測試,也是一樣

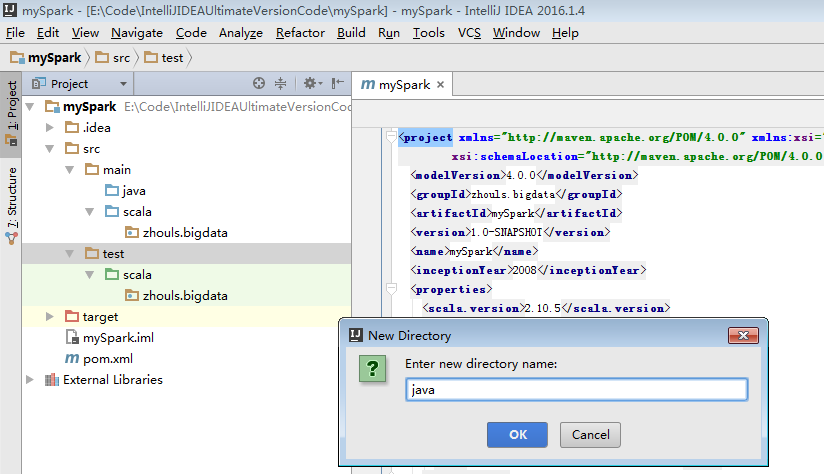
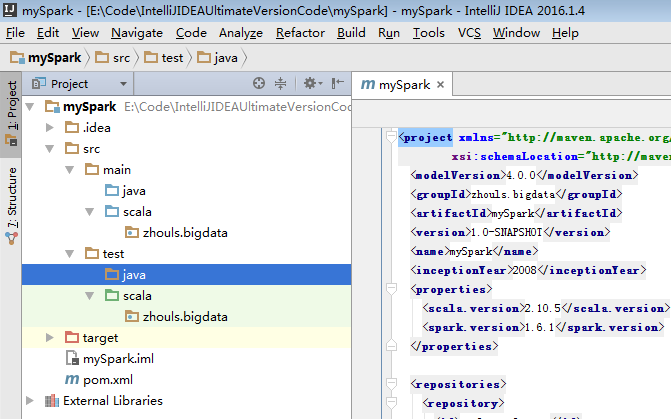
預設,也是沒有生效的。
必須做如下的動作,才能生效。


開發第一個Spark程式


a) 第一個Scala版本的spark程式


package zhouls.bigdata import org.apache.spark.{SparkConf, SparkContext} /** * Created by zhouls on 2016-6-19. */ object MyScalaWordCount { def main(args: Array[String]): Unit = { //引數檢查 if (args.length < 2) { System.err.println("Usage: MyScalaWordCout <input> <output> ") System.exit(1) } //獲取引數 val input=args(0) val output=args(1) //建立scala版本的SparkContext val conf=new SparkConf().setAppName("MyScalaWordCout ") val sc=new SparkContext(conf) //讀取資料 val lines=sc.textFile(input) //進行相關計算 val resultRdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) //儲存結果 resultRdd.saveAsTextFile(output) sc.stop() } }
b) 第一個Java版本的spark程式

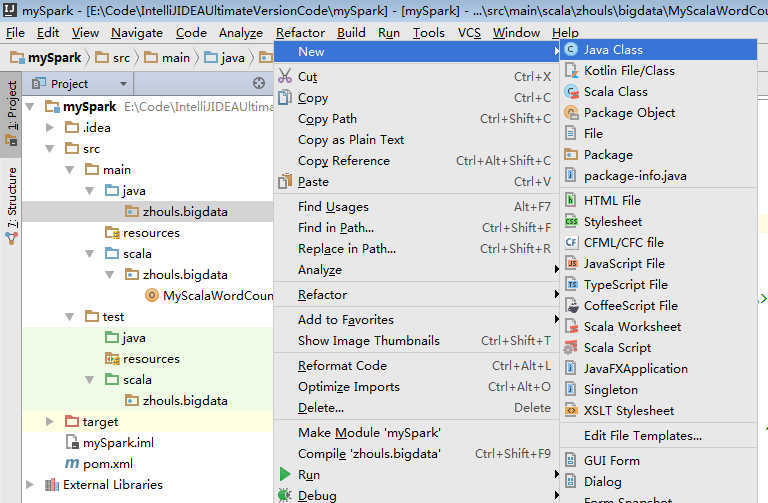
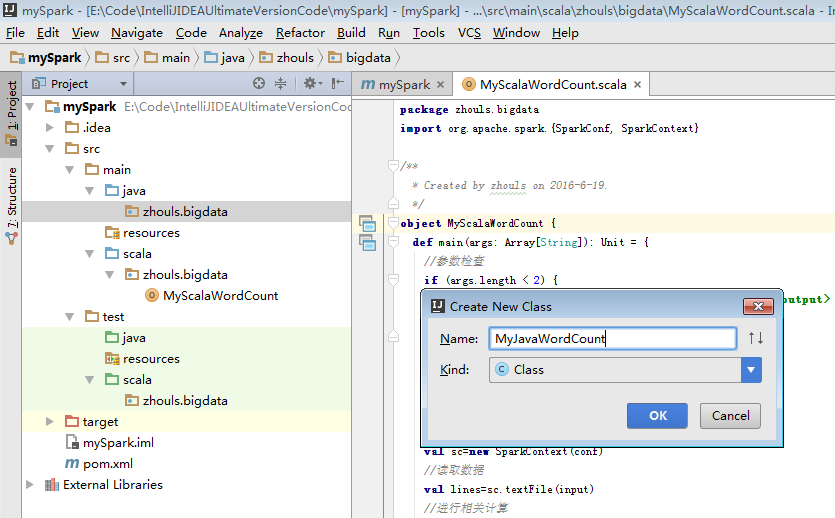
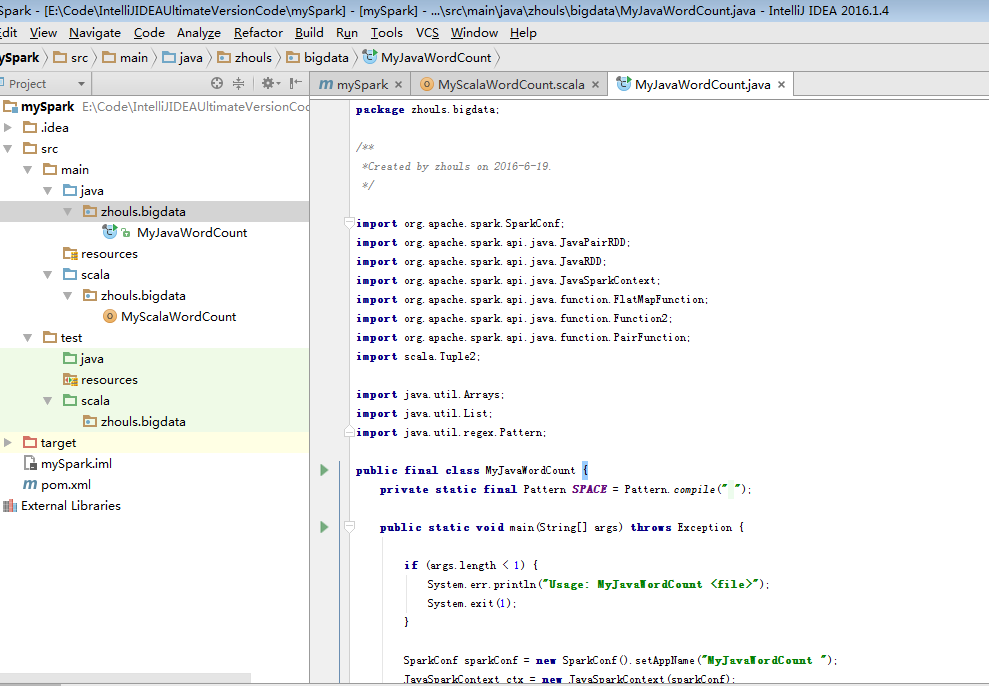
package zhouls.bigdata; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; /** * Created by zhouls on 2016-6-19. */ public class MyJavaWordCount { public static void main(String[] args) { //引數檢查 if(args.length<2){ System.err.println("Usage: MyJavaWordCount <input> <output> "); System.exit(1); } //獲取引數 String input=args[0]; String output=args[1]; //建立java版本的SparkContext SparkConf conf=new SparkConf().setAppName("MyJavaWordCount"); JavaSparkContext sc=new JavaSparkContext(conf); //讀取資料 JavaRDD inputRdd=sc.textFile(input); //進行相關計算 JavaRDD words=inputRdd.flatMap(new FlatMapFunction() { public Iterable call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); JavaPairRDD result=words.mapToPair(new PairFunction() { public Tuple2 call(String word) throws Exception { return new Tuple2(word,1); } }).reduceByKey(new Function2() { public Integer call(Integer x, Integer y) throws Exception { return x+y; } }); //儲存結果 result.saveAsTextFile(output); //關閉sc sc.stop(); } }
或者
package zhouls.bigdata; /** *Created by zhouls on 2016-6-19. */ import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; import java.util.List; import java.util.regex.Pattern; public final class MyJavaWordCount { private static final Pattern SPACE = Pattern.compile(" "); public static void main(String[] args) throws Exception { if (args.length < 1) { System.err.println("Usage: MyJavaWordCount <file>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("MyJavaWordCount "); JavaSparkContext ctx = new JavaSparkContext(sparkConf); JavaRDD<String> lines = ctx.textFile(args[0], 1); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String s) { return Arrays.asList(SPACE.split(s)); } }); JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer i1, Integer i2) { return i1 + i2; } }); List<Tuple2<String, Integer>> output = counts.collect(); for (Tuple2<?, ?> tuple : output) { System.out.println(tuple._1() + ": " + tuple._2()); } ctx.stop(); } }
執行自己開發第一個Spark程式
Spark maven 專案打包
推薦下面這種方式
1、先切換到此工程路徑下

預設,會到E:\Code\IntelliJIDEAUltimateVersionCode\mySpark>
mvn clean package
mvn package
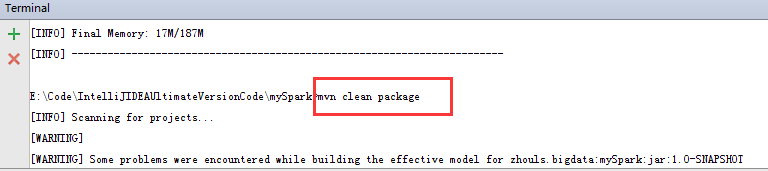
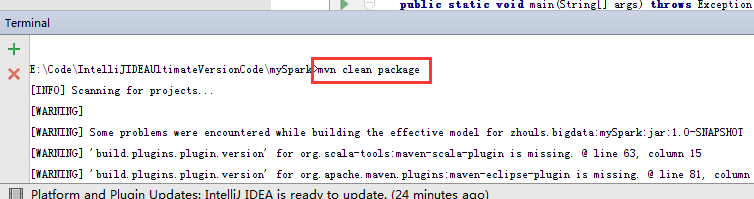

為了,更好的學習,其實,我們可以將它拷貝到桌面,去看看,是否真正打包進入。因為這裡,是需要包括MyJavaWordCount.java和MyScalaWordCout.scala


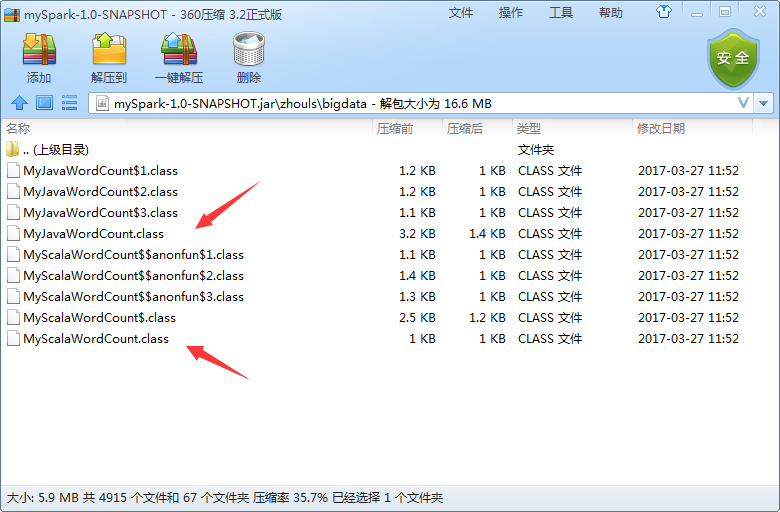
準備好資料

[[email protected] wordcount]$ pwd /home/spark/testspark/inputData/wordcount [[email protected] wordcount]$ ll total 4 -rw-rw-r-- 1 spark spark 92 Mar 24 18:45 wc.txt [[email protected] wordcount]$ cat wc.txt hadoop spark storm zookeeper scala java hive hbase mapreduce hive hadoop hbase spark hadoop [[email protected] wordcount]$
上傳好剛之前打好的jar包
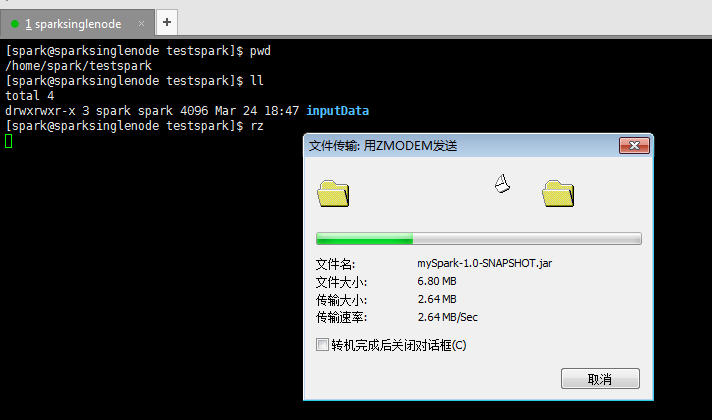
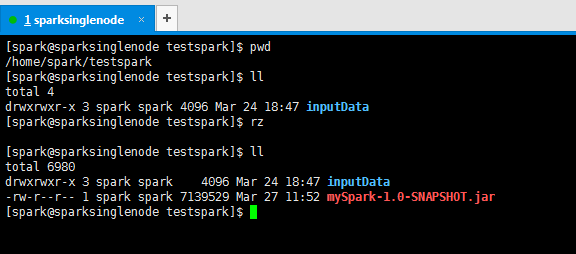
提交Spark 叢集執行
a) 提交Scala版本的Wordcount
到$SPARK_HOME安裝目錄下,去執行如下命令。

[[email protected] spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -mkdir -p hdfs://sparksinglenode:9000/testspark/inputData/wordcount
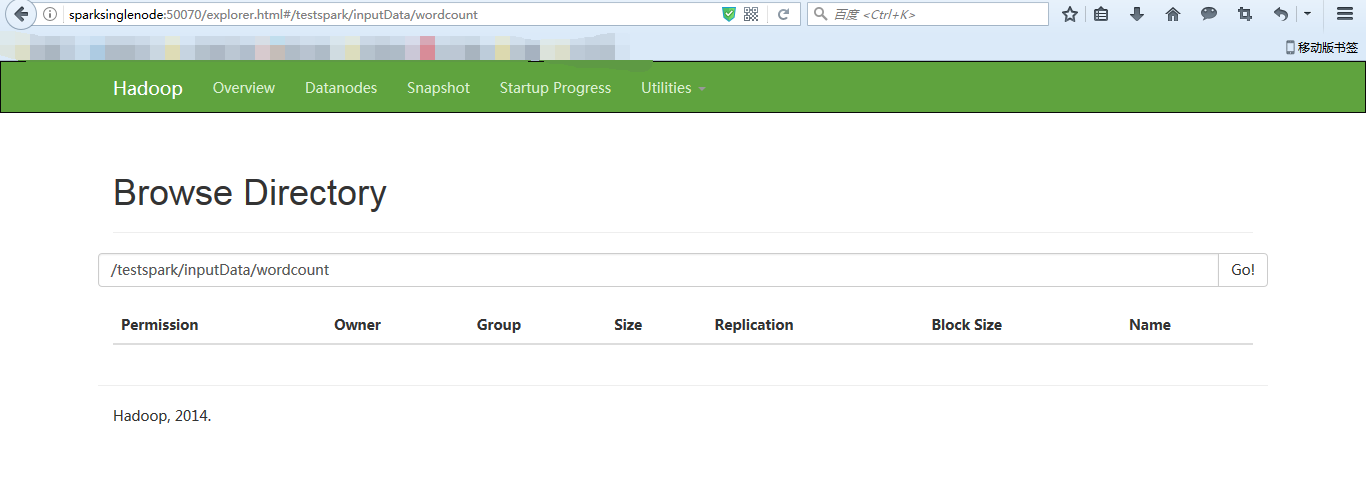

[[email protected] spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /home/spark/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/inputData/wordcount/


[[email protected] spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyScalaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar hdfs://sparksinglenode:9000/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/outData/MyScalaWordCount
注意,以上,是輸入路徑和輸出都要在叢集裡。因為我這裡的程式打包裡,制定是在叢集裡(即hdfs)。所以只能用這種方法。
成功!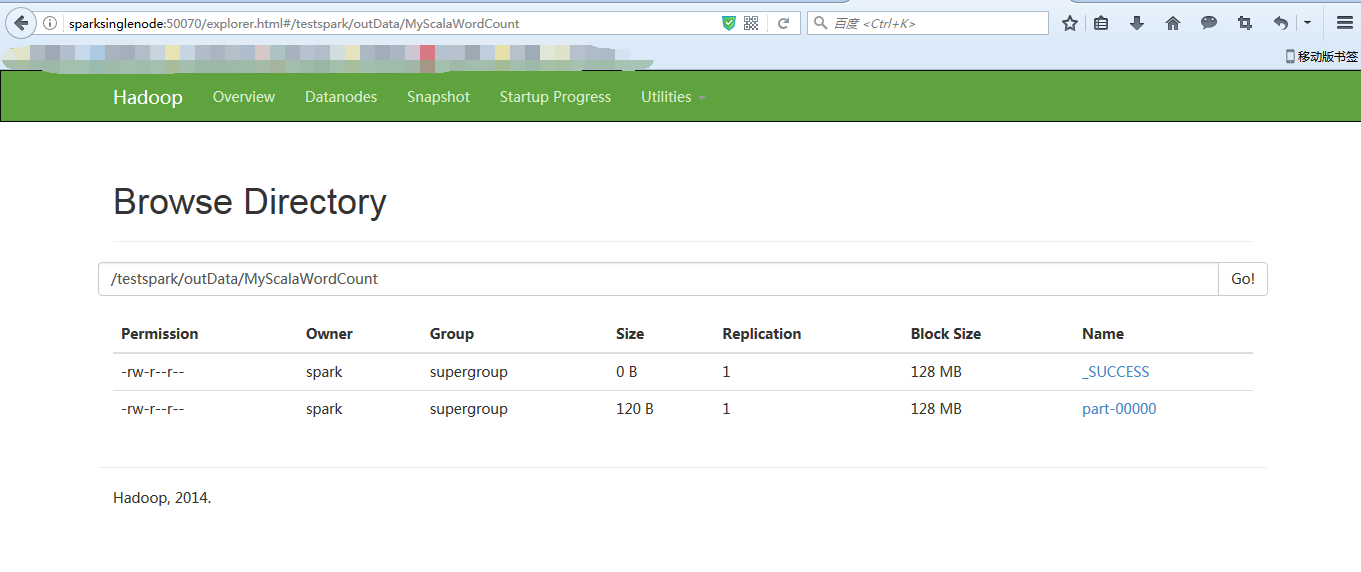

[[email protected] spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -cat hdfs://sparksinglenode:9000/testspark/outData/MyScalaWordCount/part-* 17/03/27 20:12:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable (storm zookeeper,1) (hadoop spark,1) (spark hadoop,1) (mapreduce hive,1) (scala java,1) (hive hbase,1) (hadoop hbase,1) [[email protected] spark-1.6.1-bin-hadoop2.6]$
注意:若想要在本地(即windows裡或linux裡能執行的話。則只需在程式程式碼裡。註明是local就好,這個很簡單。不多贅述,再打包。再執行就可以了。
[[email protected] spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyScalaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar /home/spark/testspark/inputData/wordcount/wc.txt /home/spark/testspark/outData/MyScalaWordCount
b) 提交Java版本的Wordcount

[[email protected] spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyJavaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar hdfs://sparksinglenode:9000/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/outData/MyJavaWordCount
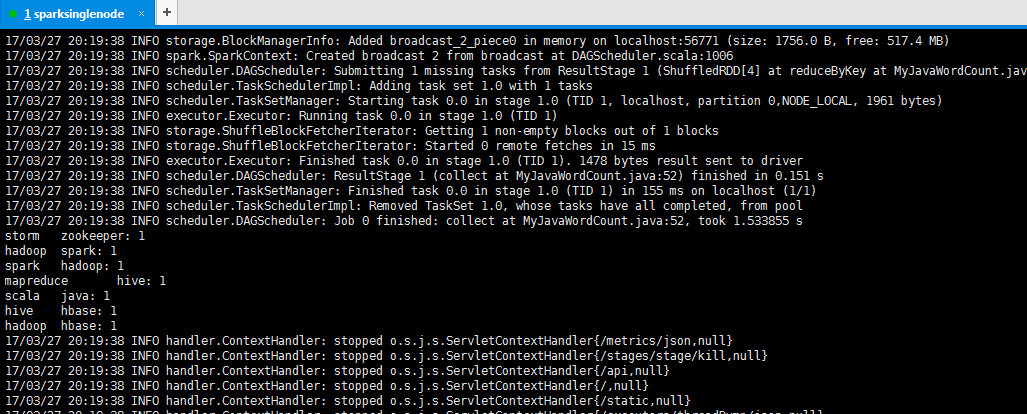
storm zookeeper: 1 hadoop spark: 1 spark hadoop: 1 mapreduce hive: 1 scala java: 1 hive hbase: 1 hadoop hbase: 1
注意:若想要在本地(即windows裡或linux裡能執行的話。則只需在程式程式碼裡。註明是local就好,這個很簡單。不多贅述,再打包。再執行就可以了。
bin/spark-submit --class com.zhouls.test.MyJavaWordCount /home/spark/testspark/mySpark-1.0.SNAPSHOT.jar /home/spark/testspark/inputData/wordcount/wc.txt /home/spark/testspark/outData/MyJavaWordCount
成功!
關於對pom.xml的進一步深入,見
推薦部落格
歡迎大家,加入我的微信公眾號:大資料躺過的坑 人工智慧躺過的坑同時,大家可以關注我的個人部落格:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
詳情請見:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我願分享。本公眾號將秉持活到老學到老學習無休止的交流分享開源精神,匯聚於網際網路和個人學習工作的精華乾貨知識,一切來於網際網路,反饋回網際網路。
目前研究領域:大資料、機器學習、深度學習、人工智慧、資料探勘、資料分析。 語言涉及:Java、Scala、Python、Shell、Linux等 。同時還涉及平常所使用的手機、電腦和網際網路上的使用技巧、問題和實用軟體。 只要你一直關注和呆在群裡,每天必須有收穫
對應本平臺的討論和答疑QQ群:大資料和人工智慧躺過的坑(總群)(161156071)![]()
![]()
![]()
![]()
![]()



相關推薦
Spark程式設計環境搭建(基於Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主強烈推薦)
為什麼,我要在這裡提出要用Ultimate版本。 基於Intellij IDEA搭建Spark開發環境搭——參考文件 操作步驟 a)建立maven 專案 b)引入依賴(Spark 依賴、打包外掛等等) 基於Intellij
使用 IntelliJ IDEA 匯入 Spark 最新原始碼及編譯 Spark 原始碼(博主強烈推薦)
前言 其實啊,無論你是初學者還是具備了有一定spark程式設計經驗,都需要對spark原始碼足夠重視起來。 本人,肺腑之己見,想要成為大資料的大牛和頂尖專家,多結合原始碼和操練程式設計。 準備工作 1、scala 2.10.4(本地的安裝) 2、Jdk1.
CentOS6.5下Cloudera安裝搭建部署大數據集群(圖文分五大步詳解)(博主強烈推薦)
centos6 數據 http 時間 log .com pos OS 客戶端 第一步: Cloudera Manager安裝之Cloudera Manager安裝前準備(CentOS6.5)(一) 第二步: Cloudera Manager安裝之時間服務器和
Ubuntu14.04下Ambari安裝搭建部署大資料叢集(圖文分五大步詳解)(博主強烈推薦)
不多說,直接上乾貨! 寫在前面的話 (1) 最近一段時間,因擔任我團隊實驗室的大資料環境叢集真實物理機器工作,至此,本人秉持負責、認真和細心的態度,先分別在虛擬機器上模擬搭建ambari(基於CentOS6.5版本)和cloudermanager(基於CentOS6.5或Ub
CentOS6.5下Ambari安裝搭建部署大資料叢集(圖文分五大步詳解)(博主強烈推薦)
第一步: 第二步: 第三步: 第四步: 第五步: 成功! 歡迎大家,加入我的微信公眾號:大資料躺過的坑 人工智慧躺過的坑 同時,大家可以關注我的個人部
全網最詳細的Eclipse和MyEclipse裏對於Java web項目發布到Tomcat上運行成功的對比事宜【博主強烈推薦】【適合普通的還是Maven方式創建的】(圖文詳解)
機器 安裝 同時 python 人生苦短 機器學習 dream png 改名 不多說,直接上幹貨! 首先,大家要明確,IDEA、Eclipse和MyEclipse等編輯器之間的新建和運行手法是不一樣的。
全網最詳細的IDEA、Eclipse和MyEclipse之間於Java web項目發布到Tomcat上運行成功的對比事宜【博主強烈推薦】【適合普通的還是Maven方式創建的】(圖文詳解)
led 交流 之間 精神 推薦 enter style images java web 不多說,直接上幹貨! IDEA 全網最詳細的IDEA裏如何正確新建
歡迎五湖四海博友來我園,查詢攻略(大資料躺過的坑:博主強烈推薦)
寫給來我園的各位博友們: 共同學習和交流,知識是討論和不斷主動自學、多思考出來的! 為了更方便大家對我部落格裡的精華博文的挖掘,快速查詢,我特,寫下此博文,來詳細圖文教程。 步驟二:輸入blog:zlslch CentOS 說明下,zlslch是我的部
Spark開發環境搭建(IDEA、Maven)
在搭建開發環境之前,請先安裝好scala開發環境和spark: scala:https://blog.csdn.net/qq_39429714/article/details/84332869 spark:https://blog.csdn.net/qq_39429714/article/d
spark開發環境搭建(基於idea 和maven)
轉載文章出自:http://blog.csdn.net/u012373815/article/details/53266301使用idea構建maven 管理的spark專案 ,預設已經裝好了idea 和Scala,mac安裝Scala 那麼使用idea 新建maven 管理
Hadoop+spark+jupyter環境搭建(三):Pyspark+jupyter部署在Linux
Hadoop+spark+jupyter環境搭建順序請參照: 我們已經實現了Spark on Yarn的搭建,但我們還希望有一個友好的開發介面,也便於展示成果,因此我們選擇了jupyter。他的本質就是一個 web app,也支援多種語言,完全滿足我們的要求。1.安裝
Spark之路:(一)Scala + Spark + Hadoop環境搭建
一、Spark 介紹 Spark是基於記憶體計算的大資料分散式計算框架。Spark基於記憶體計算,提高了在大資料環境下資料處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者將Spark部署在大量廉價硬體之上,形成叢集。 1.提供分散式計算功能,將分散式
基於eclipse的spark開發環境搭建
1、下載spark安裝包,然後直接解壓即可。 2、配置環境變數 SPARK_HOME F:\spark-2.1.0-bin-hadoop2.6 Path追加F:\spark-2.1.0-bin-hadoop2.6\bin; 3、建立maven工程。加
Maven專案管理(一) IntelliJ Idea+Maven環境搭建與基於命令列的基本使用
Maven MAVEN是一個強大的構建工具,ItelliJ Idea 是個強大的IDE,幫他們聯合起來使用,將會是多麼美妙的事情。但是IDE中整合的Maven總使習慣使用命令列的我們頭大,不想為了使用IDE重新學習如何使用怎麼辦,那麼就通過配置環境相容就好了。
Spark學習筆記:四、WordCount字頻統計入門程式(基於IntelliJ IDEA使用Scala+SBT)
一、環境準備: Ubuntu16.04 IDEA Ultimate(破解版、教育版) Java JDK 1.8 Hadoop2.7 (偽單機模式) Spark 2.1.0 Hadoop與Spark的安裝過程本文省略 二、IDEA + SBT
01_PC單機Spark開發環境搭建_JDK1.8+Spark2.3.1+Hadoop2.7.1
tor 環境 eve exe ring row test source 分享圖片 本文檔基於Windows搭建本地JAVA Spark開發環境。 1 JDK 1.8安裝 官網下載JDK。 註意JDK安裝目錄不可以包含空格,比如:C:\Java\jdk1.8.
spring系統學習-之最小化spirngMVC練習環境準備(基於IDEA的spring容器與外接tomcat容器的和平共處)
這個學期,我們系統的學了基於spring的內容。 前面已經從邏輯上分別記錄了ioc與aop的spring的兩大核心功能:spring的IOC容器練習以及IOC的優勢對比練習; AOP的優勢極其逐步推進練習。 之後整理了spr
Spark 開發環境搭建
1.建立maven工程 建立project--Java 建立module--maven 2.新增依賴 <dependencies> <!--spark依賴--> <dependency>
Hadoop+HBase+Spark+Hive環境搭建
eight 基礎 計算 oracle keygen 結構化 文字 l命令 密鑰 楊赟快跑 簡書作者 2018-09-24 10:24 打開App 摘要:大數據門檻較高,僅僅環境的搭建可能就要耗費我們大量的精力,本文總結了作者是如何搭建大數據環境的(單機版和集
【Spark核心原始碼】Spark原始碼環境搭建
目錄 準備條件 下載spark原始碼,並解壓 開啟spark原始碼下的pom.xml檔案,修改對應的java和intellij裡的maven版本 開啟intellij,Inport Project,將原始碼匯入intellij中 問題總結(十分重要) Maven編譯打包前的準