
60分鐘內從零起步駕馭Hive實戰學習筆記(Ubuntu裡安裝mysql)
本博文的主要內容是:
1. Hive本質解析
2. Hive安裝實戰
3. 使用Hive操作搜尋引擎資料實戰
SparkSQL前身是Shark,Shark強烈依賴於Hive。Spark原來沒有做SQL多維度資料查詢工具,後來開發了Shark,Shark依賴於Hive的解釋引擎,部分在Spark中執行,還有一部分在Hadoop中執行。所以講SparkSQL必須講Hive。
1. Hive本質解析
1. Hive是分散式資料倉庫,同時又是查詢引擎,所以SparkSQL取代的只是Hive的查詢引擎,在企業實際生產環境下,Hive+SparkSQL是目前最為經典的資料分析組合。
2. Hive本身就是一個簡單單機版本的軟體,主要負責:
a) 把HQL翻譯成Mapper(s)-Reducer-Mapper(s)的程式碼,並且可能產生很多MapReduce的Job。
b) 把生成的MapReduce程式碼及相關資源打包成jar併發布到Hadoop叢集中執行(這一切都是自動的)
3.Hive本身的架構如下所示:
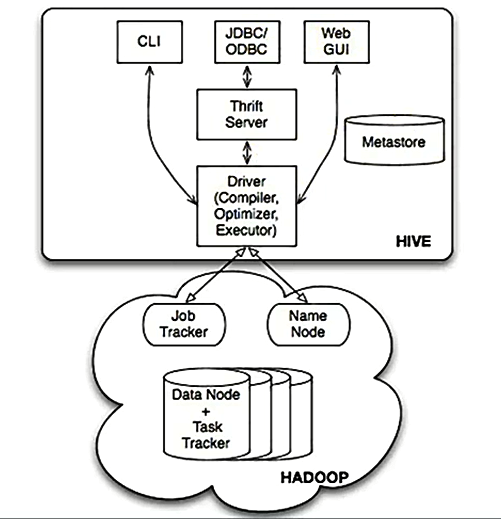
可以通過CLI(命令終端)、JDBC/ODBC、Web GUI訪問Hive。
JavaEE或.net程式可以通過Hive處理,再把處理的結果展示給使用者。
也可以直接通過Web頁面操作Hive。
※ Hive本身只是一個單機版本的的軟體,怎麼訪問HDFS的呢?
=> 在Hive用Table的方式插入資料、檢索資料等,這就需要知道資料放在HDFS的什麼地方以及什麼地方屬於什麼資料,Metastore就是儲存這些元資料資訊的。Hive通過訪問元資料資訊再去訪問HDFS上的資料。
可以看出HDFS不是一個真實的檔案系統,是虛擬的,是邏輯上的,HDFS只是一套軟體而已,它是管理不同機器上的資料的,所以需要NameNode去管理元資料。DataNode去管理資料。
Hive通過Metastore和NameNode打交道。
2、Hive安裝和配置實戰
由於,我這裡,Spark的版本是1.5.2。
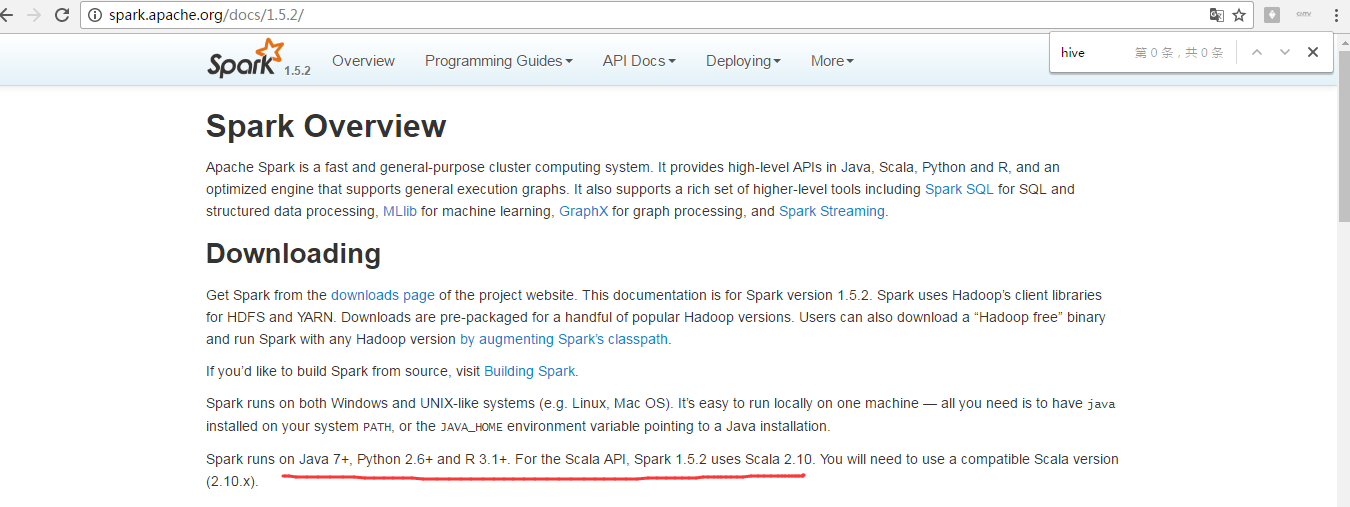
Spark1.5.2中SparkSQL可以指定具體的Hive的版本。
1. 從apache官網下載hive-1.2.1

2、apache-hive-1.2.1-bin.tar.gz的上傳

3、現在,新建/usr/loca/下的hive目錄

[email protected]:/usr/local# pwd
/usr/local
[email protected]:/usr/local# ls
bin etc games hadoop include jdk lib man sbin scala share spark src
[email protected]:/usr/local# mkdir -p /usr/local/hive
[email protected]:/usr/local# cd hive
[email protected]:/usr/local/hive# ls
[email protected]:/usr/local/hive#
4、將下載的hive檔案移到剛剛建立的/usr/local/hive下

[email protected]:/usr/local/hive# ls
[email protected]:/usr/local/hive# sudo cp /home/spark/Downloads/Spark_Cluster_Software/apache-hive-1.2.1-bin.tar.gz /usr/local/hive/
[email protected]:/usr/local/hive# ls
apache-hive-1.2.1-bin.tar.gz
[email protected]:/usr/local/hive#
最好用cp,不要輕易要mv
5、解壓hive檔案

[email protected]:/usr/local/hive# ls
apache-hive-1.2.1-bin.tar.gz
[email protected]:/usr/local/hive# tar -zxvf apache-hive-1.2.1-bin.tar.gz
6、刪除解壓包,留下解壓完成的檔案目錄,並修改許可權(這是最重要的!!!),其中,還重新命名

[email protected]:/usr/local/hive# ls
apache-hive-1.2.1-bin apache-hive-1.2.1-bin.tar.gz
[email protected]:/usr/local/hive# rm -rf apache-hive-1.2.1-bin.tar.gz
[email protected]:/usr/local/hive# ls
apache-hive-1.2.1-bin
[email protected]:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:39 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 root root 4096 10月 9 17:38 apache-hive-1.2.1-bin/
[email protected]:/usr/local/hive# mv apache-hive-1.2.1-bin/ apache-hive-1.2.1
[email protected]:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:40 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 root root 4096 10月 9 17:38 apache-hive-1.2.1/
[email protected]:/usr/local/hive# chown -R spark:spark apache-hive-1.2.1/
[email protected]:/usr/local/hive# ll
total 12
drwxr-xr-x 3 root root 4096 10月 9 17:40 ./
drwxr-xr-x 15 root root 4096 10月 9 17:35 ../
drwxr-xr-x 8 spark spark 4096 10月 9 17:38 apache-hive-1.2.1/
[email protected]:/usr/local/hive#
7、修改環境變數
vim ~./bash_profile 或 vim /etc/profile
配置在這個檔案~/.bash_profile,或者也可以,配置在那個全域性的檔案裡,也可以喲。/etc/profile。
這裡,我vim /etc/profile
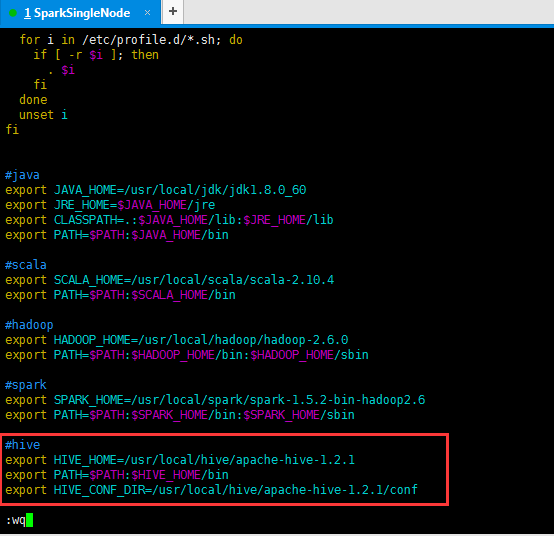
#hive
export HIVE_HOME=/usr/local/hive/apache-hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF_DIR=/usr/local/hive/apache-hive-1.2.1/conf

[email protected]:/usr/local/hive# vim /etc/profile
[email protected]:/usr/local/hive# source /etc/profile
8、配置hive
8.1 配置hive-env.sh檔案
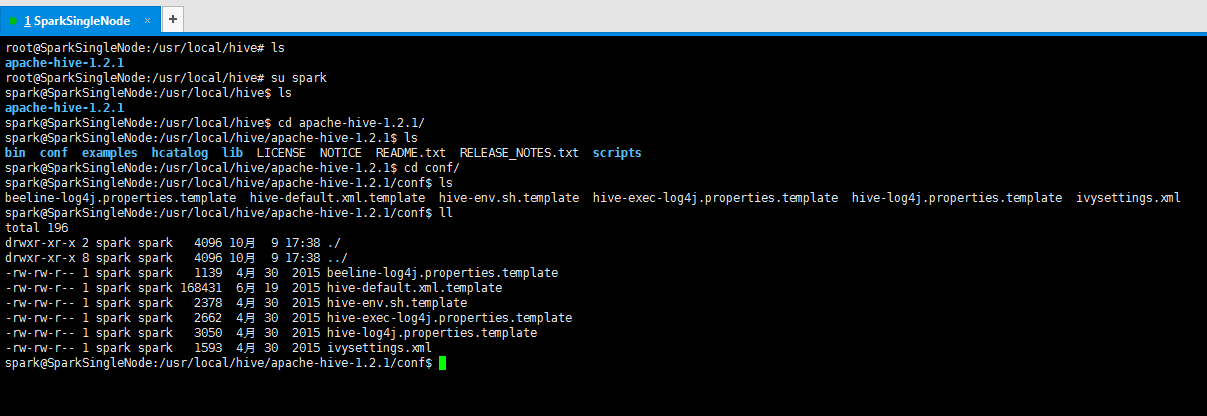
cp hive-env.sh.template hive-env.sh

[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ cp hive-env.sh.template hive-env.sh
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ rm hive-env.sh.template
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ vim hive-env.sh

export HIVE_HOME=/usr/local/hive/apache-hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF_DIR=/usr/local/hive/apache-hive-1.2.1/conf
8.2 配置hive-env.sh檔案

[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ cp hive-default.xml.template hive-site.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template hive-site.xml ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ rm hive-default.xml.template
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template hive-site.xml ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ vim hive-site.xml
Hive預設情況下放元資料的資料庫是Derby,遺憾的是Derby是單使用者,所以在生產環境下一般會採用支援多使用者的資料庫來進行MetaStore,且進行Master-Slaves主從讀寫分離和備份(一般Master節點負責寫資料,Slaves節點負責讀資料)。最常用的是MySQL。
於是,刪除它,在本地上寫好,上傳即可。
或者,
學個技巧,如何快速的搜尋。 先按Esc,再按Shift,再 . 鍵 + / 鍵

[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ vim hive-site.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template hive-site.xml ivysettings.xml
spar[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ rm hive-site.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ rz
rz waiting to receive.
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ ls
beeline-log4j.properties.template hive-env.sh hive-exec-log4j.properties.template hive-log4j.properties.template hive-site.xml ivysettings.xml
[email protected]:/usr/local/hive/apache-hive-1.2.1/conf$ vim hive-site.xml
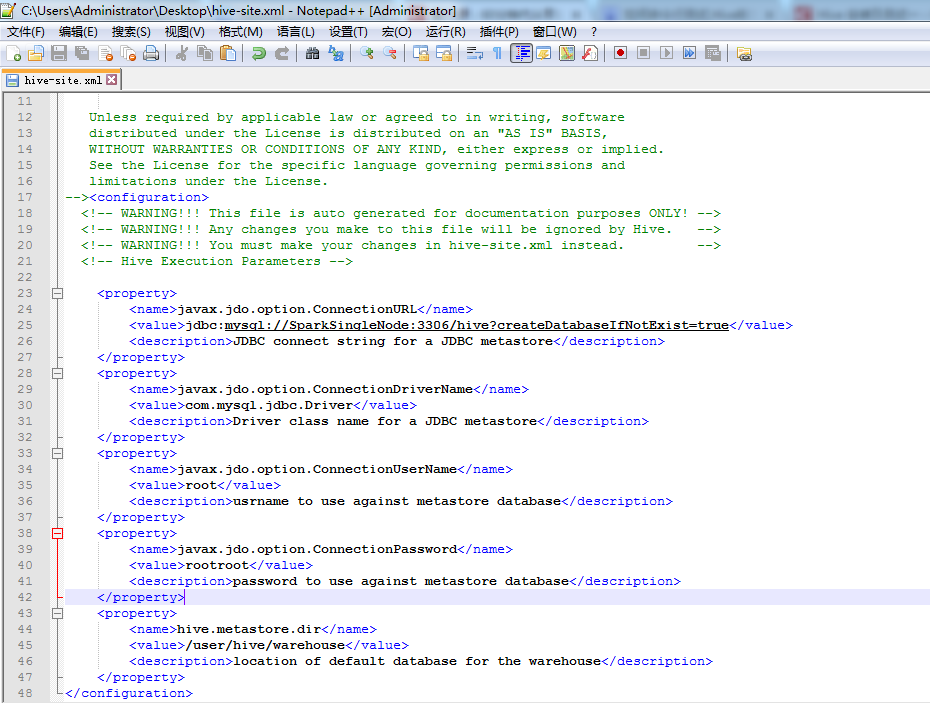
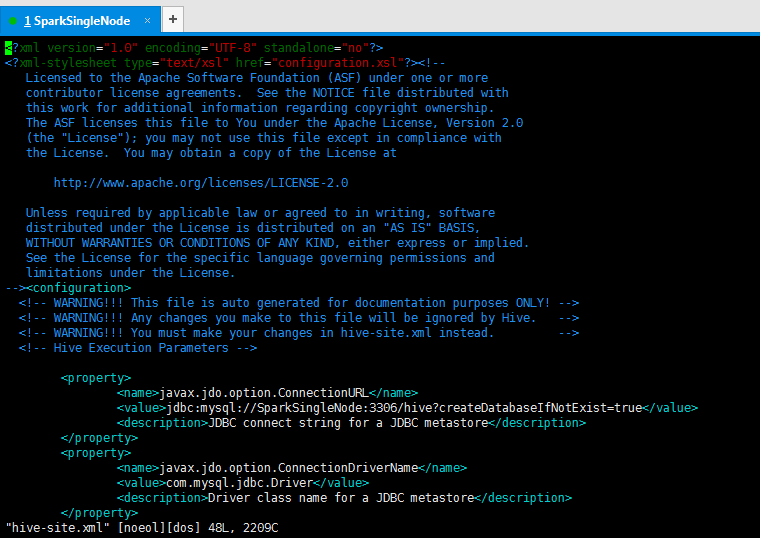
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://SparkSingleNode:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>rootroot</value>
</property>
<property>
<name>hive.metastore.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
當然,你也可以,專門,用一個hive使用者專門,見
[email protected]:/usr/local/hive/apache-hive-1.2.1/lib# pwd
/usr/local/hive/apache-hive-1.2.1/lib
[email protected]:/usr/local/hive/apache-hive-1.2.1/lib# ls
accumulo-core-1.6.0.jar commons-httpclient-3.0.1.jar hive-hbase-handler-1.2.1.jar libfb303-0.9.2.jar
accumulo-fate-1.6.0.jar commons-io-2.4.jar hive-hwi-1.2.1.jar libthrift-0.9.2.jar
accumulo-start-1.6.0.jar commons-lang-2.6.jar hive-jdbc-1.2.1.jar log4j-1.2.16.jar
accumulo-trace-1.6.0.jar commons-logging-1.1.3.jar hive-jdbc-1.2.1-standalone.jar mail-1.4.1.jar
activation-1.1.jar commons-math-2.1.jar hive-metastore-1.2.1.jar maven-scm-api-1.4.jar
ant-1.9.1.jar commons-pool-1.5.4.jar hive-serde-1.2.1.jar maven-scm-provider-svn-commons-1.4.jar
ant-launcher-1.9.1.jar commons-vfs2-2.0.jar hive-service-1.2.1.jar maven-scm-provider-svnexe-1.4.jar
antlr-2.7.7.jar curator-client-2.6.0.jar hive-shims-0.20S-1.2.1.jar mysql-connector-java-5.1.21.jar
antlr-runtime-3.4.jar curator-framework-2.6.0.jar hive-shims-0.23-1.2.1.jar netty-3.7.0.Final.jar
apache-curator-2.6.0.pom curator-recipes-2.6.0.jar hive-shims-1.2.1.jar opencsv-2.3.jar
apache-log4j-extras-1.2.17.jar datanucleus-api-jdo-3.2.6.jar hive-shims-common-1.2.1.jar oro-2.0.8.jar
asm-commons-3.1.jar datanucleus-core-3.2.10.jar hive-shims-scheduler-1.2.1.jar paranamer-2.3.jar
asm-tree-3.1.jar datanucleus-rdbms-3.2.9.jar hive-testutils-1.2.1.jar parquet-hadoop-bundle-1.6.0.jar
avro-1.7.5.jar derby-10.10.2.0.jar httpclient-4.4.jar pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar
bonecp-0.8.0.RELEASE.jar eigenbase-properties-1.1.5.jar httpcore-4.4.jar php
calcite-avatica-1.2.0-incubating.jar geronimo-annotation_1.0_spec-1.1.1.jar ivy-2.4.0.jar plexus-utils-1.5.6.jar
calcite-core-1.2.0-incubating.jar geronimo-jaspic_1.0_spec-1.0.jar janino-2.7.6.jar py
calcite-linq4j-1.2.0-incubating.jar geronimo-jta_1.1_spec-1.1.1.jar jcommander-1.32.jar regexp-1.3.jar
commons-beanutils-1.7.0.jar groovy-all-2.1.6.jar jdo-api-3.0.1.jar servlet-api-2.5.jar
commons-beanutils-core-1.8.0.jar guava-14.0.1.jar jetty-all-7.6.0.v20120127.jar snappy-java-1.0.5.jar
commons-cli-1.2.jar hamcrest-core-1.1.jar jetty-all-server-7.6.0.v20120127.jar ST4-4.0.4.jar
commons-codec-1.4.jar hive-accumulo-handler-1.2.1.jar jline-2.12.jar stax-api-1.0.1.jar
commons-collections-3.2.1.jar hive-ant-1.2.1.jar joda-time-2.5.jar stringtemplate-3.2.1.jar
commons-compiler-2.7.6.jar hive-beeline-1.2.1.jar jpam-1.1.jar super-csv-2.2.0.jar
commons-compress-1.4.1.jar hive-cli-1.2.1.jar json-20090211.jar tempus-fugit-1.1.jar
commons-configuration-1.6.jar hive-common-1.2.1.jar jsr305-3.0.0.jar velocity-1.5.jar
commons-dbcp-1.4.jar hive-contrib-1.2.1.jar jta-1.1.jar xz-1.0.jar
commons-digester-1.8.jar hive-exec-1.2.1.jar junit-4.11.jar zookeeper-3.4.6.jar
[email protected]:/usr/local/hive/apache-hive-1.2.1/lib#

[email protected]:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -ls hdfs://SparkSingleNode:9000/user
Found 1 items
drwxr-xr-x - spark supergroup 0 2016-09-27 17:40 hdfs://SparkSingleNode:9000/user/spark
[email protected]:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -mkdir -p /user/hive/warehouse
[email protected]:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -ls /user
Found 2 items
drwxr-xr-x - root supergroup 0 2016-10-10 07:45 /user/hive
drwxr-xr-x - spark supergroup 0 2016-09-27 17:40 /user/spark
[email protected]:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -ls /user/hive
Found 1 items
drwxr-xr-x - root supergroup 0 2016-10-10 07:45 /user/hive/warehouse
[email protected]:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -chmod g+w /user/hive/warehouse
[email protected]leNode:/usr/local/hive/apache-hive-1.2.1# /usr/local/hadoop/hadoop-2.6.0/bin/hadoop fs -ls /user/hive
Found 1 items
drwxrwxr-x - root supergroup 0 2016-10-10 07:45 /user/hive/warehouse
[email protected]:/usr/local/hive/apache-hive-1.2.1#
參考博主:http://mars914.iteye.com/blog/1410035
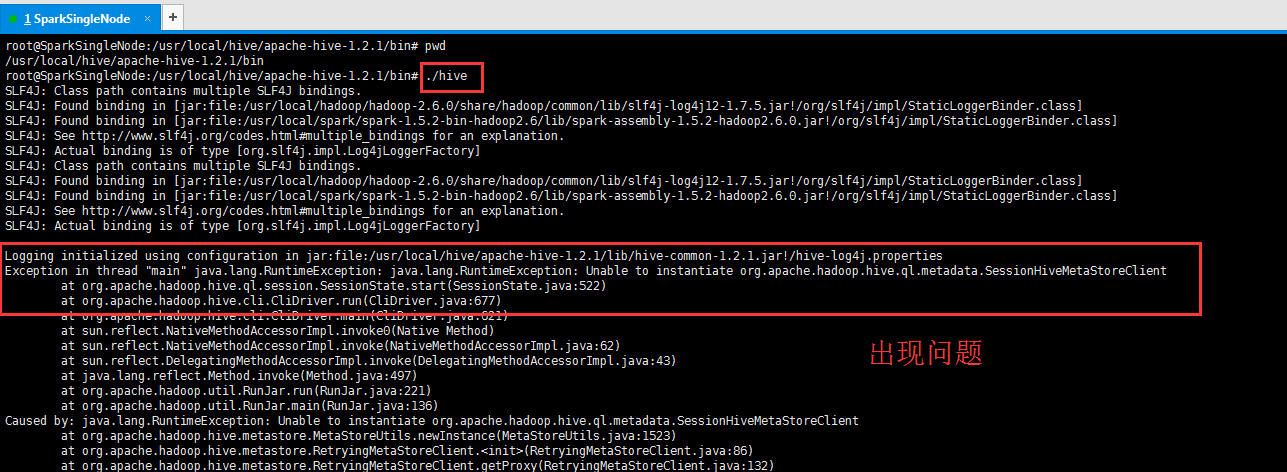
遇到問題:
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
解決辦法:
參考部落格:http://blog.csdn.net/freedomboy319/article/details/44828337
原因:因為沒有正常啟動Hive 的 Metastore Server服務程序。
解決方法:啟動Hive 的 Metastore Server服務程序,執行如下命令:
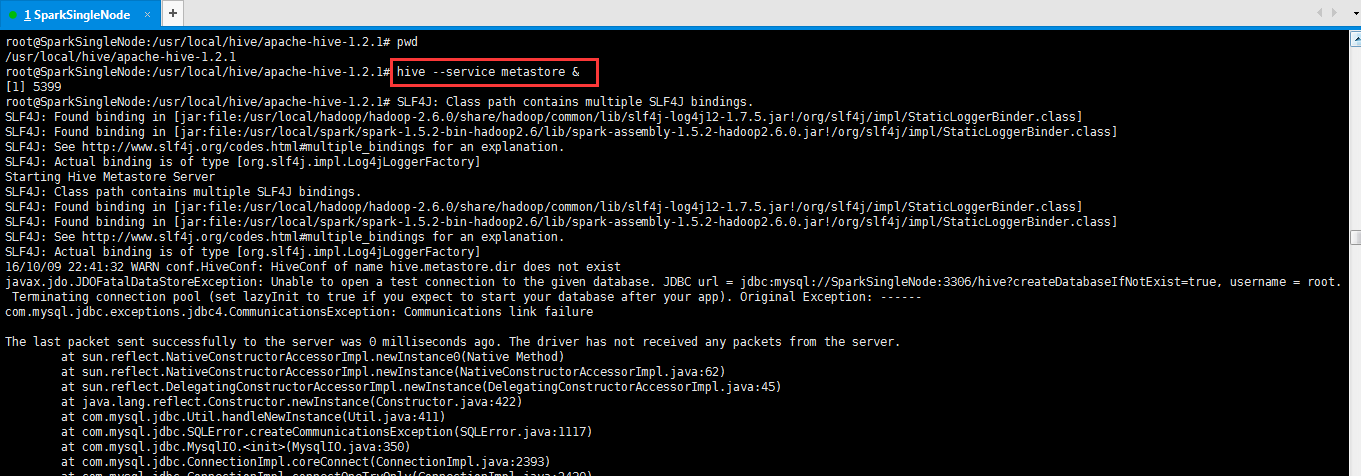
出現,另一個問題。
[email protected]:/usr/local/hive/apache-hive-1.2.1# pwd
/usr/local/hive/apache-hive-1.2.1
[email protected]:/usr/local/hive/apache-hive-1.2.1# hive --service metastore &
[1] 5399
[email protected]:/usr/local/hive/apache-hive-1.2.1# SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/lib/spark-assembly-1.5.2-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting Hive Metastore Server
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/lib/spark-assembly-1.5.2-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
16/10/09 22:41:32 WARN conf.HiveConf: HiveConf of name hive.metastore.dir does not exist
javax.jdo.JDOFatalDataStoreException: Unable to open a test connection to the given database. JDBC url = jdbc:mysql://SparkSingleNode:3306/hive?createDatabaseIfNotExist=true, username = root. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ------
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1117)
at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:350)
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2393)
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2430)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2215)
at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:813)
at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47)
參考:
http://blog.csdn.net/xiaoshunzi111/article/details/48827775
方案一:許可權問題
可能由於root的許可權不夠,可以進行如下操作
1) 以root進入mysql
[email protected]:/usr/local/hive/apache-hive-1.2.1# mysql -uroot -prootroot

[email protected]:/usr/local/hive/apache-hive-1.2.1# mysql -uroot -prootroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 45
Server version: 5.5.52-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
2) 賦予root許可權:
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'SparkSingleNode' WITH GRANT OPTION;
//本地操作的許可權
mysql> GRANT ALL PRIVILEGES ON *.* TO ' root '@'%' WITH GRANT OPTION;
//遠端操作的許可權
3) 重新整理:
mysql> flush privileges;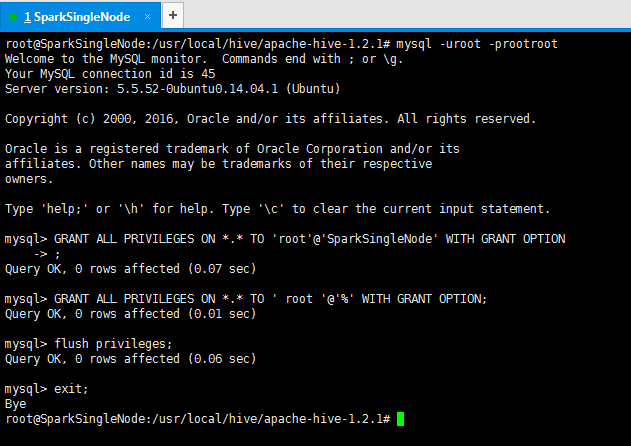
[email protected]:/usr/local/hive/apache-hive-1.2.1# mysql -uroot -prootroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 45
Server version: 5.5.52-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'SparkSingleNode' WITH GRANT OPTION
-> ;
Query OK, 0 rows affected (0.07 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO ' root '@'%' WITH GRANT OPTION;
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.06 sec)
mysql> exit;
Bye
[email protected]:/usr/local/hive/apache-hive-1.2.1#
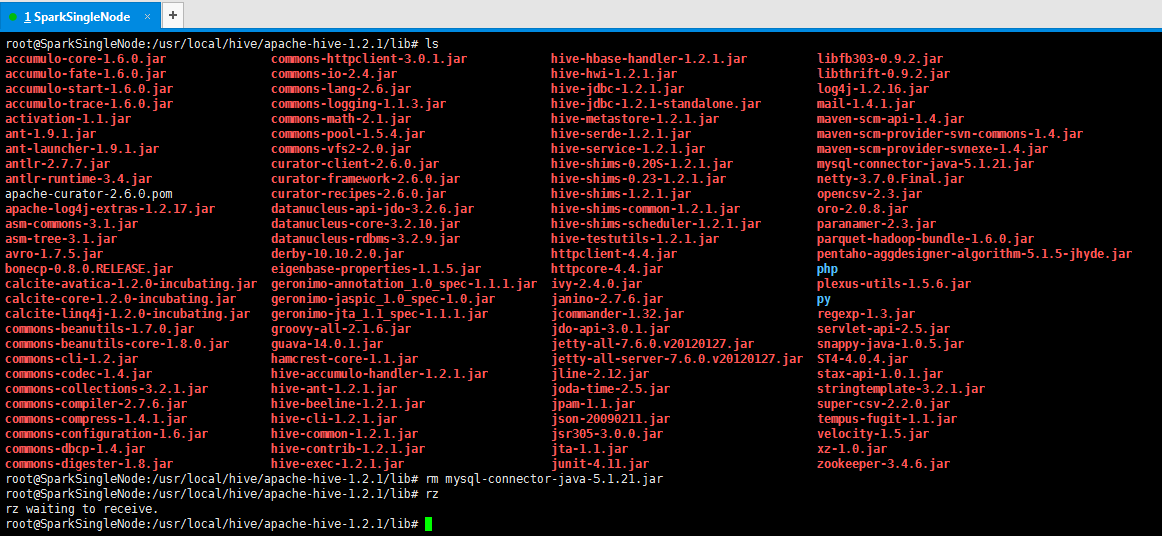
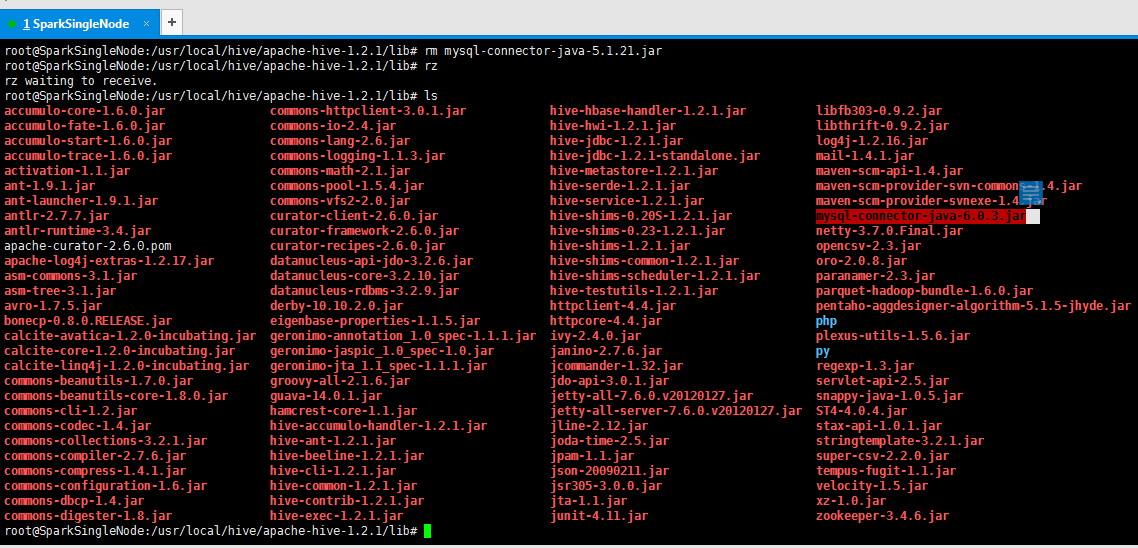
方案二:mysql驅動問題
mysql-connector-java-5.1.21-bin.jar換成較高版本的驅動如mysql-connector-java-6.0.3-bin.jar
下載路徑http://ftp.ntu.edu.tw/MySQL/Downloads/Connector-J/
Hive中的DataBase和表其實就是HDFS上的目錄和簡單的文字檔案。簡單的文字檔案中有幾列資料,每列資料的型別無法直接從文字檔案中得知。但當資料放入Hive中,Hive就把元資料放入Mysql中了,這樣就可以基於資料的表進行查詢了。
開啟hadoop叢集
[email protected]:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh
[email protected]:/usr/local/hadoop/hadoop-2.6.0$ jps
3569 Jps
[email protected]:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh
Starting namenodes on [SparkSingleNode]
SparkSingleNode: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-namenode-SparkSingleNode.out
SparkSingleNode: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-datanode-SparkSingleNode.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-secondarynamenode-SparkSingleNode.out
[email protected]:/usr/local/hadoop/hadoop-2.6.0$ jps
3829 DataNode
3990 SecondaryNameNode
4150 Jps
3709 NameNode
[email protected]:/usr/local/hadoop/hadoop-2.6.0$
開啟spark叢集
[email protected]:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.master.Master-1-SparkSingleNode.out
SparkSingleNode: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-SparkSingleNode.out
[email protected]:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ jps
4241 Master
3829 DataNode
4517 Jps
3990 SecondaryNameNode
4413 Worker
3709 NameNode
[email protected]:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$

'
9. MYSQL的安裝和配置 (路徑,沒要求)
root使用者下執行yum -y install mysql-server(CentOS版本)或apt-get install mysql-server(Ubuntu版本) 即可自動安裝
9.1 線上安裝mysql資料庫
[email protected]:/usr/local/hive/apache-hive-1.2.1# pwd
/usr/local/hive/apache-hive-1.2.1
[email protected]:/usr/local/hive/apache-hive-1.2.1# yum -y install mysql-server
The program 'yum' is currently not installed. You can install it by typing:
apt-get install yum
[email protected]:/usr/local/hive/apache-hive-1.2.1# apt-get install mysql-server
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following extra packages will be installed:
libaio1 libdbd-mysql-perl libdbi-perl libhtml-template-perl libmysqlclient18 libterm-readkey-perl mysql-client-5.5 mysql-client-core-5.5 mysql-common mysql-server-5.5
mysql-server-core-5.5
Suggested packages:
libmldbm-perl libnet-daemon-perl libplrpc-perl libsql-statement-perl libipc-sharedcache-perl tinyca mailx
The following NEW packages will be installed:
libaio1 libdbd-mysql-perl libdbi-perl libhtml-template-perl libmysqlclient18 libterm-readkey-perl mysql-client-5.5 mysql-client-core-5.5 mysql-common mysql-server mysql-server-5.5
mysql-server-core-5.5
0 upgraded, 12 newly installed, 0 to remove and 742 not upgraded.
Need to get 8,998 kB of archives.
After this operation, 97.1 MB of additional disk space will be used.
Do you want to continue? [Y/n] y
9.2 檢視mysql資料庫版本
[email protected]:/usr/local/hive/apache-hive-1.2.1# mysqladmin -u root -p version
Enter password: (rootroot)
mysqladmin Ver 8.42 Distrib 5.5.52, for debian-linux-gnu on x86_64
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Server version 5.5.52-0ubuntu0.14.04.1
Protocol version 10
Connection Localhost via UNIX socket
UNIX socket /var/run/mysqld/mysqld.sock
Uptime: 5 min 17 sec
Threads: 1 Questions: 579 Slow queries: 0 Opens: 189 Flush tables: 1 Open tables: 41 Queries per second avg: 1.826
[email protected]:/usr/local/hive/apache-hive-1.2.1#
9.2 檢視mysql服務狀態,若是關閉,則啟動mysql服務。

[email protected]:/usr/local/hive/apache-hive-1.2.1# service mysql status
mysql start/running, process 9868
[email protected]:/usr/local/hive/apache-hive-1.2.1# sudo /etc/init.d/mysql start
* Starting MySQL database server mysqld [ OK ]
[email protected]:/usr/local/hive/apache-hive-1.2.1# sudo /etc/init.d/mysql stop
* Stopping MySQL database server mysqld [ OK ]
[email protected]:/usr/local/hive/apache-hive-1.2.1# sudo /etc/init.d/mysql restart
* Stopping MySQL database server mysqld [ OK ]
* Starting MySQL database server mysqld [ OK ]
* Checking for tables which need an upgrade, are corrupt or were
not closed cleanly.
[email protected]:/usr/local/hive/apache-hive-1.2.1# service mysql status
mysql start/running, process 10330
[email protected]:/usr/local/hive/apache-hive-1.2.1#

9.3 設定MySQL的root使用者設定密碼,這一步,就不需要做了,在CentOS版本里,需要做。在Ubuntu版本,在安裝時,就已經設定了。
9.4 以root使用者,登入mysql看看。
[email protected]:/usr/local/hive/apache-hive-1.2.1# mysql -u root -p
Enter password: (rootroot)
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 39
Server version: 5.5.52-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SHOW databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.04 sec)
mysql> quit;
Bye
[email protected]:/usr/local/hive/apache-hive-1.2.1#
或者

[email protected]:/usr/local/hive/apache-hive-1.2.1# mysql -uroot -prootroot
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 44
Server version: 5.5.52-0ubuntu0.14.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.00 sec)
mysql> quit;
Bye
[email protected]:/usr/local/hive/apache-hive-1.2.1#
更多,可以,參考
由此,說明mysql資料庫,安裝成功!
5. Hive的表有兩種基本型別:一種是內部表(這種表資料屬於Hive本身,即如果原來的資料在HDFS的其他地方,此時資料會通過HDFS移動到Hive所在目錄,如果刪除Hive中的該表的話資料和元資料均會被刪除),一種是外部表(這種表資料不屬於Hive資料倉庫,元資料中會表達具體資料在哪裡,使用時和內部表的使用一樣,只是如果通過Hive去刪除的話,刪除的只是元資料,並沒有刪除資料本身)
三. 使用Hive分析搜尋資料
啟動HDFS/Yarn。注意如果要使用Hive進行查詢就需要啟動Yarn。
啟動Hive。
通過show databases;可以檢視資料庫。預設database只有default。
creeate database hive;
use hive;
create table person(name String,age int);
insert into person values(‘richard’,’34’);
select * from person;即可查詢。
感謝下面的博主:
http://blog.csdn.net/slq1023/article/details/50988267
http://blog.csdn.net/gujinjinseu/article/details/38307685
http://blog.csdn.net/zhu_tianwei/article/details/48972833
http://blog.csdn.net/jim110/article/details/44907745
相關推薦
60分鐘內從零起步駕馭Hive實戰學習筆記(Ubuntu裡安裝mysql)
本博文的主要內容是: 1. Hive本質解析 2. Hive安裝實戰 3. 使用Hive操作搜尋引擎資料實戰 SparkSQL前身是Shark,Shark強烈依賴於Hive。Spark原來沒有做SQL多維度資料查詢工具,後來開發了Shark,Shark依賴於Hive的解釋引擎,部分
第55課:60分鐘內從零起步駕馭Hive實戰學習筆記
內容: Hive本質解析 Hive安裝實戰 使用Hive操作搜尋引擎資料實戰 SparkSQL前身是Shark,Shark強烈依賴於Hive。Spark原來沒有做SQL多維度資料查詢工具,後來開發了Shark,Shark依賴於Hiv
《從零開始學Swift》學習筆記(Day67)——Cocoa Touch設計模式及應用之MVC模式
table control sdn rate term targe rac uitabbar bsp 原創文章,歡迎轉載。轉載請註明:關東升的博客 MVC(Model-View-Controller,模型-視圖-控制器)模式是相當古老的設計模式之中的一個,它最早出如今
《從零開始學Swift》學習筆記(Day60)——Core Foundation框架
類型轉換 字符 sso grid blog spa www water 轉載 創文章,歡迎轉載。轉載請註明:關東升的博客 Core Foundation框架是蘋果公司提供一套概念來源於Foundation框架,編程接口面向C語言風格的API。盡管在Swift中調用這樣
《從零開始學Swift》學習筆記(Day 55)——使用try?和try!差別
移動設計 ani ecb pcl mva fde 成了 lms 官方 原創文章。歡迎轉載。轉載請註明:關東升的博客 在使用try進行錯誤處理的時候,常常會看到try後面跟有問號(?)或感嘆號(!),他們有什麽差別呢?1.使用try? try?會將錯誤轉換為可選值,當調
《從零開始學Swift》學習筆記(Day 57)——Swift編碼規範之凝視規範:文件凝視、文檔凝視、代碼凝視、使用地標凝視
精品 -type mil 顯示 clas ber ansi tex text 原創文章。歡迎轉載。轉載請註明:關東升的博客 前面說到Swift凝視的語法有兩種:單行凝視(//)和多行凝視(/*...*/)。這裏來介紹一下他們的使用規範。 1、文件凝視文件凝視就在每個文
《從零開始學Swift》學習筆記(Day 19)——函式引數傳遞
原創文章,歡迎轉載。轉載請註明:關東昇的部落格函式的語法格式如下:func 函式名(引數列表) -> 返回值型別 {語句組return 返回值}關鍵字是func。多個引數列表之間可以用逗號(,
《從零開始學Swift》學習筆記(Day 44)——重寫屬性
原創文章,歡迎轉載。轉載請註明:關東昇的部落格重寫例項屬性我們可以在子類中重寫從父類繼承來的屬性,屬性有例項屬性和靜態屬性之分,他們在具體實現也是不同的。例項屬性的重寫一方面可以重寫getter和set
前端之路從零開始——第二週第二天筆記(盒子模型)
目錄 1.盒子模型的初步瞭解 2.盒子模型型別:標準盒子模型和IE盒子模型 盒子模型的計算公式 3.標準模式下的盒模型 4.怪異模式下的盒模型 5.padding詳解 6.border詳解 利用border屬性製作三角形 7.marg
學習:從零玩轉HTML5前端+跨平臺開發(表單練習(理解))
單選框:radio,通過name屬性進行互斥;checked預設選中多選框:checkbox,通過name屬性進行互斥;checked預設選中下拉選中框:select除了按鈕型別的input標籤以外,其他的型別的標籤都可以通過一個value屬性來指定將來提交到伺服器的值提交:
學習:從零玩轉HTML5前端+跨平臺開發(伺服器和瀏覽器 瞭解)
https://www.jianshu.com/p/f6da3875834b1、什麼是瀏覽器主流有5款瀏覽器;都有不同的核心;使用份額最高;處理相容問題,主要處理5種瀏覽器;Google國內國外使用份額最高;2、什麼是伺服器可以理解為超級計算機;伺服器也是一臺電腦,但是配置比
【Y分鐘內迅速學會python3系列】 python學習記錄 (一)
原網頁 https://learnxinyminutes.com/docs/python3/ 今天主要看了最開始的運算子的那一部分,感覺和C++差不多,很快就過去了 # 單行註釋 """ 多行註釋 """ ####################### ##
架構探險-從零開始寫Javaweb框架讀書筆記(5)
AOP實現 AOP(Aspect Oriented Programming,面向切面程式設計);用來不改變程式碼的情況下在方法前後加入效能監控,日誌列印等等。 依照慣例,有時spring aop的實現過程 advice 直譯為通知 黃勇老師
從零開始,SpreadJS新人學習筆記【第5周】
複製貼上、單元格格式和單元格型別 本週,讓我們一起來學習SpreadJS 的複製貼上、單元格格式和單元格型別,希
學習筆記(11月10日)--python常用內置模塊的使用(logging, os, command)
學習筆記 python培訓 四周五次課(11月10日)一、 logging日誌是我們排查問題的關鍵利器,寫好日誌記錄,當我們發生問題時,可以快速定位代碼範圍進行修改。Python給我們開發者們提供了好的日誌模塊,下面我們就來介紹一下logging模塊:首先,我們先來看一個例子:import loggi
從零起步做到Linux運維經理,你必須管好的23個細節
不想成為將軍的士兵,不是好士兵-拿破崙 如何成為運維經理?成為運維經理需要什麼樣的能力?我想很多運維工程師都會有這樣的思考和問題。 如何成為運維經理。一般來說,運維經理大概有兩種出身,一種是從底層最基礎的維護做起,通過出色的維護工作,讓公司領導對這個人非常認可,同時對Linux運維工作也比較重視,逐步走向
2018年終:一次從零起步的產品搭建的思考
在我整個職業生涯裡,運營依舊是主要內容,無論是活動運營,內容運營,抑或是產品運營都沒有特別能讓我有多少成就感的地方,或者是想讓運營有成就感的事情辦起來其實太難了。在更多人的眼裡運營就是一個釘子,只要保證負責的模組不出問題那就是最好了,但是往往對運營的要求遠比當個產品和技術要來的高。 坊間說天下運營是一家,無
從零起步到Linux運維經理,你必須管好的23個細節
來自:馬哥Linux運維 的整合文章不想成為將軍的士兵,不是好士兵-拿破崙如何成為運維經理?成為運維經理需要什麼樣的能力?我想很多運維工程師都會有這樣的思考和問題。如何成為運維經理。一般來說,運維經理大概有兩種出身,一種是從底層最基礎的維護做起,通過出色的維護工作,讓公司領導
從零起步CMFCToolBar用法詳解
CMFCToolBar是vs08sp1以後引入的新的工具欄控制元件,和Ribbon主題結合的很好,不同與CToolBar,它是從CPane派生出來的,用法跟CToolbar 有一些不同,研究了幾天,記錄在下面。 首先給出工具欄四種狀態圖示BMP檔案,這4個檔案分別為圖示
從零開始理解JAVA事件處理機制(2)
extend nds 接下來 htm ref param 簡單 tostring ansi 第一節中的示例過於簡單《從零開始理解JAVA事件處理機制(1)》,簡單到讓大家覺得這樣的代碼簡直毫無用處。但是沒辦法,我們要繼續寫這毫無用處的代碼,然後引出下一階段真正有益的代碼。