
【NLP】前戲:一起走進條件隨機場(一)
作者:白寧超
2016年8月2日13:59:46
【摘要】:條件隨機場用於序列標註,資料分割等自然語言處理中,表現出很好的效果。在中文分詞、中文人名識別和歧義消解等任務中都有應用。本文源於筆者做語句識別序列標註過程中,對條件隨機場的瞭解,逐步研究基於自然語言處理方面的應用。成文主要源於自然語言處理、機器學習、統計學習方法和部分網上資料對CRF介紹的相關的相關,最後進行大量研究整理彙總成體系知識。文章佈局如下:第一節介紹CRF相關的基礎統計知識;第二節介紹基於自然語言角度的CRF介紹;第三節基於機器學習角度對CRF介紹,第四節基於統計學習角度對相關知識介紹;第五節對統計學習深度介紹CRF,可以作為了解內容。(本文原創,轉載請註明出處
:漫步條件隨機場系列文章。)
目錄
【自然語言處理:漫步條件隨機場系列文章(一)】:
【自然語言處理:漫步條件隨機場系列文章(二)】:
【自然語言處理:漫步條件隨機場系列文章(三)】:
【自然語言處理:漫步條件隨機場系列文章(四)】:
【自然語言處理:漫步條件隨機場系列文章(五)】:
1 機器學習中的生產模型與判別模型
生產式模型與判別式模型簡述,條件隨機場是哪種模型?
有監督機器學習方法可以分為生成方法和判別方法:
1)生產式模型:直接對聯合分佈進行建模,如:混合高斯模型、隱馬爾科夫模型、馬爾科夫隨機場等
2)判別式模型:對條件分佈進行建模,如:條件隨機場、支援向量機、邏輯迴歸等。
生成模型優缺點介紹:
優點:
1)生成給出的是聯合分佈,不僅能夠由聯合分佈計算條件分佈(反之則不行),還可以給出其他資訊。如果一個輸入樣本的邊緣分佈很小的話,那麼可以認為學習出的這個模型可能不太適合對這個樣本進行分類,分類效果可能會不好。
2)生成模型收斂速度比較快,即當樣本數量較多時,生成模型能更快地收斂於真實模型。
3)生成模型能夠應付存在隱變數的情況,比如混合高斯模型就是含有隱變數的生成方法。
缺點:
1)天下沒有免費午餐,聯合分佈是能提供更多的資訊,但也需要更多的樣本和更多計算,尤其是為了更準確估計類別條件分佈,需要增加樣本的數目,而且類別條件概率的許多資訊是我們做分類用不到,因而如果我們只需要做分類任務,就浪費了計算資源。
2)另外,實踐中多數情況下判別模型效果更好。
判別模型優缺點介紹:
優點:
1)與生成模型缺點對應,首先是節省計算資源,另外,需要的樣本數量也少於生成模型。
2)準確率往往較生成模型高。
3)由於直接學習,而不需要求解類別條件概率,所以允許我們對輸入進行抽象(比如降維、構造等),從而能夠簡化學習問題。
缺點:
1)是沒有生成模型的上述優點。
2 簡單易懂的解釋條件隨機場
線性鏈的條件隨機場跟線性鏈的隱馬爾科夫模型一樣,一般推斷用的都是維特比演算法。這個演算法是一個最簡單的動態規劃。
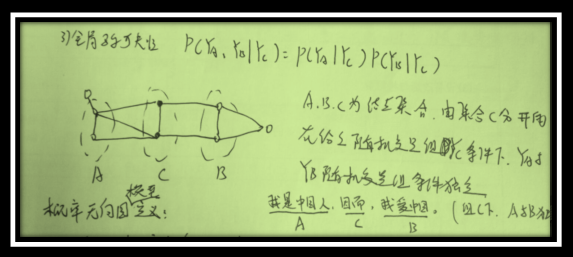
首先我們推斷的目標是給定一個X,找到使P(Y|X)最大的那個Y嘛。然後這個Z(X),一個X就對應一個Z,所以X固定的話這個項是常量,優化跟他沒關係(Y的取值不影響Z)。然後exp也是單調遞增的,也不帶他,直接優化exp裡面。所以最後優化目標就變成了裡面那個線性和的形式,就是對每個位置的每個特徵加權求和。比如說兩個狀態的話,它對應的概率就是從開始轉移到第一個狀態的概率加上從第一個轉移到第二個狀態的概率,這裡概率是隻exp裡面的加權和。那麼這種關係下就可以用維特比了,首先你算出第一個狀態取每個標籤的概率,然後你再計算到第二個狀態取每個標籤得概率的最大值,這個最大值是指從狀態一哪個標籤轉移到這個標籤的概率最大,值是多 少,並且記住這個轉移(也就是上一個標籤是啥)。然後你再計算第三個取哪個標籤概率最大,取最大的話上一個標籤應該是哪個。以此類推。整條鏈計算完之後, 你就知道最後一個詞去哪個標籤最可能,以及去這個標籤的話上一個狀態的標籤是什麼、取上一個標籤的話上上個狀態的標籤是什麼,醬。這裡我說的概率都是 exp裡面的加權和,因為兩個概率相乘其實就對應著兩個加權和相加,其他部分都沒有變。
學習
這是一個典型的無條件優化問題,基本上所有我知道的優化方法都是優化似然函式。典型的就是梯度下降及其升級版(牛頓、擬牛頓、BFGS、L-BFGS),這裡版本最高的就是L-BFGS了吧,所以一般都用L-BFGS。除此之外EM演算法也可以優化這個問題。
3 概率無向圖與馬爾科夫隨機場前世今生
概率無向圖模型又稱為馬爾科夫隨機場,是一個可以由無向圖表示的聯合概率分佈。
圖是由結點和連線結點的邊組成的集合,(這部分知識學過資料結構或者演算法的同學都比較瞭解,不作為深入講解。)
注意:無向圖是指邊上沒有方向的圖,既然邊沒有方向,其權值是有方向的,諸如轉移概率中,“我”到“愛”的轉移概率0.5.
概率圖模型是由圖表示的概率分佈,沒有聯合概率分佈P(Y),Y∈{y}是一組隨機變數由無向圖G=<V,E>表示概率分佈P(Y),即在圖G中,結點v∈V表示一個隨機變數  ;邊e∈E表示隨機變數之間的概率依賴關係,這點在第一章有詳細介紹。
;邊e∈E表示隨機變數之間的概率依賴關係,這點在第一章有詳細介紹。
給定一個聯合概率分佈P(Y)和表示它的無向圖G,無向圖表示的隨機變數之間的成對馬爾科夫性,區域性馬爾科夫性,全域性馬爾科夫性的如何區別?
1) 成對馬爾科夫性表示

2)區域性馬爾科夫性表示

3)全域性馬爾科夫性表示
概率無向圖模型的定義
設有聯合概率分佈P(Y),由無向圖G=<V,E>表示,在圖G中,結點表示隨機變數,邊表示隨機變數之間關係(加權概率),如果聯合概率分佈P(Y)滿足成對/區域性/全域性馬爾科夫性,就稱此聯合為概率無向圖模型或者馬爾科夫隨機場。
4 計算聯合概率分佈:概率無向圖模型的因子分解
對給定概率無向圖模型下,本質就是要求聯合概率可以將其改變成若干子聯合概率乘積的形式,也就是將聯合概率進行因子分解。首先介紹兩個概念:團與最大團。
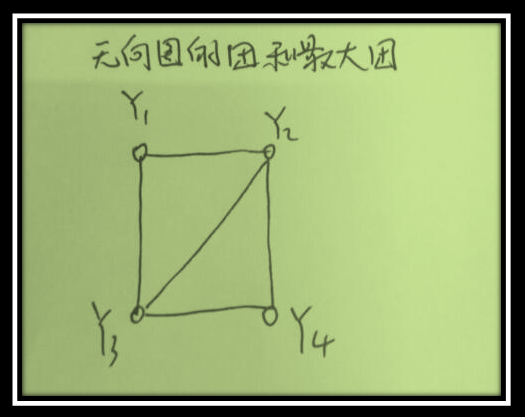
團:無向圖G中任何兩個結點均有邊連線的節點子整合為團。
最大團:若C是無向圖G的一個團,並且不能再加進任何一個G的節點使其成為一個更大的團,則稱此C為最大團。
注意:{y1,y2,y3,y4}不是一個團,因為y1與y4無邊相連
概率無向圖模型的因子分解:
將概率無向圖模型的聯合概率分佈表示,其最大團上的隨機變數的函式的乘積形式的操作,即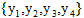 的聯合概率是
的聯合概率是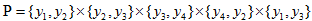 這樣不免太複雜,倘若
這樣不免太複雜,倘若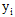 為10000個結點以上呢?(每個結點是一個漢字,假設最大團以是篇章,本書假設10章,則是十個最大團之積。)
為10000個結點以上呢?(每個結點是一個漢字,假設最大團以是篇章,本書假設10章,則是十個最大團之積。)
概率無向圖模型的聯合概率分佈P(Y)的公式化表示:
給定概率無向圖模型,設其無向圖為G,C為G上的最大團,YC表示C對應的隨機變數。那麼概率無向圖模型的聯合概率分佈P(Y)可寫作圖中所有最大團C上的函式ΨC(YC)的乘積形式,即:
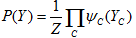
其中, 為勢函式,C為最大團,Z是規範化因子

規範化因子保證P(Y)構成一個概率分佈。
因為要求勢函式ΨC(YC)是嚴格正的,於是通常定義為指數函式:
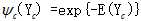
5 參考文獻
【1】 數學之美 吳軍 著
【2】 機器學習 周志華 著
【3】 統計自然語言處理 宗成慶 著(第二版)
【4】 統計學習方法(191---208) 李航
【5】 知乎 網路資源
6 自然語言相關係列文章
宣告:關於此文各個篇章,本人採取梳理扼要,順暢通明的寫作手法。系統閱讀相關書目和資料總結梳理而成,旨在技術分享,知識沉澱。在此感謝原著無私的將其匯聚成書,才得以引薦學習之用。其次,本人水平有限,權作知識理解積累之用,難免主觀理解不當,造成讀者不便,基於此類情況,望讀者留言反饋,便於及時更正。本文原創,轉載請註明出處:前戲:一起走進條件隨機場。
相關推薦
【NLP】前戲:一起走進條件隨機場(一)
作者:白寧超 2016年8月2日13:59:46 【摘要】:條件隨機場用於序列標註,資料分割等自然語言處理中,表現出很好的效果。在中文分詞、中文人名識別和歧義消解等任務中都有應用。本文源於筆者做語句識別序列標註過程中,對條件隨機場的瞭解,逐步研究基於自然語言處理方面的應用。成文主要源於自然語言處理
【問底】夏俊:深入站點服務端技術(一)——站點並發的問題
而是 思路 臨時 系統負載 表現 json article 不能 情況 摘要:本文來自擁有十年IT從業經驗、擅長站點架構設計、Web前端技術以及Java企業級開發的夏俊,此文也是《關於大型站點技術演進的思考》系列文章的最新出爐內容。首發於CSDN,各位技術人員不
【Java】【Flume】Flume-NG啟動過程源代碼分析(一)
code extends fix tar top 依據 oid article gif 從bin/flume 這個shell腳本能夠看到Flume的起始於org.apache.flume.node.Application類,這是flume的main函數所在。 m
【vue】vue根據不同環境(正式、測試)打包(一)
前提姿勢 獲取終端中輸入的命令 下面的這個在webpack中會有個process物件 ,看下面圖就知道使用 process.argv.splice() 就可以獲取輸入命令引數了 此處教程區分介面 這裡是通過不同命令將修改介面前部分的地址或者修改
【Python】打響2019年第一炮-Python爬蟲入門(一)
打響2019第一炮-Python爬蟲入門 2018年已經成為過去,還記得在2018年新年寫過一篇【Shell程式設計】打響2018第一炮-shell程式設計之for迴圈語句,那在此時此刻,也是寫一篇關於程式設計方面,不過要比18年的稍微高階點。 So,mark一下,也希望對
【更新】Essential Studio for Xamarin更新至2018 v4(一)
下載Essential Studio for Xamarin最新版本 Essential Studio for Xamarin是全面的Xamarin.iOS、Xamarin.Android和Xamarin.Forms元件套包,包含最快的圖表和網格。 COMMON 主題支援 現在,您可以使用預定義的
【Docker】centos7伺服器安裝docker想要的版本(一)
事無鉅細、人無完人! 1.Centos 7.X以上,核心版本高於3.10的64位系統支援Docker,通過uname -r檢視。 uname -r 2.查詢安裝過的包 yum list installed | grep docker 3.確認你要安裝docker的版本:
【Oracle】Oracle 12c DB In-Memory入門實驗手冊(一)
該手冊實驗基礎要在例項級別啟用IM column store,開啟方法參考上篇文章: 連結:http://blog.csdn.net/badly9/article/details/49724983 (一)基礎篇 1.對objects開啟IM column store 對於o
【轉】從零開始學習音視訊程式設計技術(一) 視訊格式講解
轉自:http://blog.yundiantech.com/?log=blog&id=4 所謂視訊,其實就是將一張一張的圖片連續的放出來,就像放幻燈片一樣,由於人眼的惰性,因此只要圖片的數量足夠多,就會覺得是連續的動作。 所以,只需要將一張一張的圖片儲存下來
【nowcoder】9.5 阿里巴巴2017實習生筆試題(一)
http://www.nowcoder.com/questionTerminal/0cd6af2fd4374df597b49e09302b1a5a - 使用 inline 關鍵字的函式只是使用者希望
【轉】硬碟損壞不能識別等相關知識(一)
硬碟修復真經 誤區、缺陷、引數與低格 ·跳出硬碟認識的誤區 ·修復需要弄明白的基本概念 ·深入瞭解硬碟引數 ·硬碟修復之低階格式化 跳出硬碟認識的誤區 1995年,偶然在同事那裡見到一個陌生的物件,好奇地問那是什麼,朋友答:“這是電腦用的硬碟!”這就是高朋第一次認識硬碟的經過。 幾年下來,單位的電腦
【PHP】高階面試題之十萬個為什麼?(一)
成功不是將來才有的,而是從決定去做的那一刻起,持續累積而成。 現在也已經工作三年時間了,PHP在平時工作中天天都會使用,但是內心總是感覺差點什麼,覺得自己對PHP這門語言瞭解的還不夠,故下定決心,整理了一下平時工作所學所用,提出各種各樣的問題,
【 FPGA 】組合邏輯中的競爭與險象問題(一)
針對單輸出的組合邏輯進行簡單分析,而多輸出的組合邏輯可分解為多個但輸出的組合邏輯。 單輸入的組合邏輯 對於一個簡單的非閘電路,它的輸出將永遠跟隨輸入變化,即使考慮到門延遲、線延遲的影響,輸出波形最多也就是比輸入波形在時間上滯後一些罷了,並不會出現非預期的現象。 但對於單
【震驚】手把手教你用python做繪圖工具(一)
在這篇部落格裡將為你介紹如何通過numpy和cv2進行結和去建立畫布,包括空白畫布、白色畫布和彩色畫布。建立畫布是製作繪圖工具的前提,有了畫布我們就可以在畫布上盡情的揮灑自己的藝術細胞。 還在為如何去繪圖煩惱的小夥伴趕緊看過來,這裡手把手教你解決問題~~~~ 當然還是講究一下規則:先點贊再看,尊重一下作者
【譯】如何實現一個現代化電子商城搜尋?(一)
原文《Implementing A Modern E-Commerce Search》,作者:Alexander Reelsen. 原文內容比較多,所以翻譯會分三篇發出: 第一篇:講述了好的搜尋功能由好的索引資料和好的查詢語句(即搜尋關鍵詞+特徵過濾器)組成。電子商務搜尋中的產品資
【NLP】Python例項:基於文字相似度對申報專案進行查重設計
作者:白寧超 2017年5月18日17:51:37 摘要:關於查重系統很多人並不陌生,無論本科還是碩博畢業都不可避免涉及論文查重問題,這也對學術不正之風起到一定糾正作用。單位主要針對科技專案申報稽核,傳統的方式人力物力比較大,且伴隨季度性的繁重工作,效率不高。基於此,單位覺得開發一款可以達到實用的
【NLP】驀然回首:談談學習模型的評估系列文章(三)
作者:白寧超 2016年7月19日19:04:51 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【NLP】驀然回首:談談學習模型的評估系列文章(二)
作者:白寧超 2016年7月19日10:24:24 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【NLP】驀然回首:談談學習模型的評估系列文章(一)
作者:白寧超 2016年7月18日17:18:43 摘要:寫本文的初衷源於基於HMM模型序列標註的一個實驗,實驗完成之後,迫切想知道採用的序列標註模型的好壞,有哪些指標可以度量。於是,就產生了對這一專題進度學習總結,這樣也便於其他人蔘考,節約大家的時間。本文依舊旨在簡明扼要梳理出模型評估核心指標,
【視頻】零基礎學Android開發:藍牙聊天室APP(一)
android入門 mod http 開發 org 薪資 get target 下載 零基礎學Android開發:藍牙聊天室APP第一講 1. Android介紹與環境搭建:史上最高效Android入門學習 1.1 Google的大小戰略 1.2 物聯網與雲計算 1.3